DEV01-GBase 8a MPP Cluster SQL 编码进阶篇
GBase 8a MPP Cluster SQL 编码进阶篇
-
-
-
- 一、概述:
- 二、常用内置函数
-
- (一)函数体系
- (二)内置函数的基本概念:
- (三)内置函数的使用位置:
- (四)内置函数概览
- (五)数学函数
- (六)日时函数
- (七)字符串处理函数
- (八)转换函数
- (九)控制流函数
- (十)正则函数
- (十一)信息函数
- (十二)函数与性能
- 三、DQL 进阶
-
- (一)什么是 DQL
- (二)SELECT 语句语法格式和执行顺序
- (三)WHERE 子句中的操作符
- (四)分组聚合 GROUP BY
- (五)条件分支
- (六)连接查询
- (七)Union 和 Union All
- (八)子查询
- (九)综合练习
- (十)CTE(公共表表达式)
- (十一)分层查询(Hierarchical Query)
- (十二)分区表查询
- (十三)DQL 编写注意事项
- 四、DDL 进阶
-
- (一)DDL 的基本概念:
- (二)DDL 的执行逻辑
- (三)数据库对象
- 五、DML 进阶
-
- (一)基本概念
- (二)INSERT
- (三)UPDATE
- (四)DELETE
- (五)Merge Into
-
-
一、概述:
GBase 8a MPP Cluster(以下简称 8a 集群)具有联邦构架、大规模并行计算、海量数据压缩、高效存储结构、智能索引、虚拟集群及镜像、灵活的数据分布、完善的资源管理、在线快速扩展、高并发、高可用性、高安全性、易维护、高效加载等技术特征,
其结构化查询语言符合SQL 92、99标准,支持十大类将近300个实用的内置函数,完整的 DDL(建库建表语句)、DQL(查询语句)、DCL(授权语句)、DML(写语句) 语法集;
丰富的正则匹配函数和关键字,支持分区表查询、分层查询、common table expression、MERGR INTO 等语法。
本章重点主题:
1、常用内置函数;
2、DQL 进阶;
3、DML 进阶;
二、常用内置函数
(一)函数体系
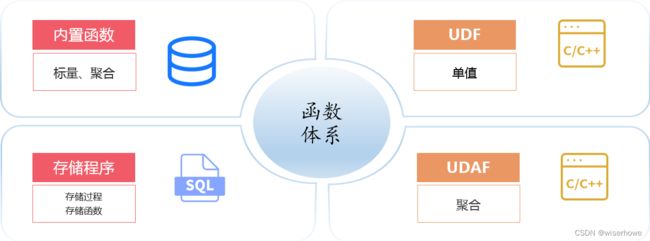
8a 集群有四大类函数:内置函数是内建在数据库引擎内的SQL类函数;存储程序是扩展的SQL类函数;UDF 和 UDAF 是 C/C++ 编写的扩展函数,其中 UDF 还可以使用 Python 语言编写。UDF 和 UDAF 函数最适合的开发人员是:对 GBASE 数据库非常熟悉的南大通用研发工程师。存储程序、内置函数是数据分析工程师需要掌握的。
(二)内置函数的基本概念:
内置函数是在 SQL 语句中使用的、内置(Built-In)在数据库引擎中的函数。
1、十大类、将近三百个内置函数,大大简化数据处理过程。
2、内置函数直接在SQL文中使用。
3、内置函数Built-In 在数据库引擎内部:支持多线程并行计算。
4、内置函数名称全局唯一,任何数据库标识符不能与之重名。
(三)内置函数的使用位置:
SELECT 的投影列,或在 WHERE 子句的条件表达式中。这里的 WHERE 子句可以从属于 Insert、Delete、Update 语句。
内置函数还可以出现在 GROUP BY子句、HAVING子句、JOIN条件中。在 GROUP BY 和 JOIN 条件中出现内置函数对于性能影响是比较明显的。HAVING子句中出现的内置函数一般是聚合函数,比如 HAVING SUM( {数值型的列} )>100。
(四)内置函数概览
| 函数分类 | 关键字 |
|---|---|
| 数学函数 | ABS、CEIL、FLOOR、MOD、POWER、ROUND…… |
| 日期和时间函数 | NOW、SYSDATE、DAY、ADD_MONTHS、LAST_DAY、NEXT_DAY…… |
| 字符串处理函数 | UPPER、REPLACE、CONCAT、SUBSTRING…… |
| 转换函数 | CAST、CONVERT、TO_NUMBER、TO_CHAR、TO_DATE…… |
| 控制流函数 | CASE…WHEN…ELSE…END、DECODE、IF、IFNULL、NULLIF |
| 正则表达式函数 | regexp_like、regexp_replace、regexp_instr、regexp_substr |
| 聚合函数 | AVG、COUNT、MAX、MIN、SUM、GROUP_CONCAT…… |
| OLAP 函数 | COUNT OVER,GROUP BY CUBE、SUM OVER、RANK… |
| 加密函数 | AES_ENCRYPT、ENCRYPT、MD5、SHA1、SHA |
| 信息函数 | CHARSET、COLLATION、CURRENT_USER、DATABASE、VERSION… |
OLAP 函数在专门的章节讲解。
(五)数学函数
1、ROUND(<数字>, <保留小数位数>)
功能:按位数四舍五入
| 示例 | 结果 | 解释 |
|---|---|---|
| round(456.789) | 457 | 第二个参数省略值为 0 |
| round(456.789,0) | 457 | 不保留小数 |
| round(456.789,-2) | 500 | 从十位数做四舍五入 |
2、TRUNCATE(<数字>, <截取的小数位数>) :
功能:按位数截取,没有四舍五入处理。
| 示例 | 结果 | 解释 |
|---|---|---|
| truncate(456.789,0) | 456 | 舍去所有小数 |
| truncate(456.789,-2) | 400 | 十位数向下清零 |
| truncate(456.789,2) | 456.78 | 保留两位小数 |
3、CEILING (<数字>):
功能:将数值向上舍入到整数,又称“天花板取整”。
| 示例 | 结果 | 解释 |
|---|---|---|
| CEILING(-456.5) | -456 | 比-456.5大的最小整数是-456 |
4、FLOOR (<数字>):
功能:将数值向下舍入到整数,又称“地板取整”。
| 示例 | 结果 | 解释 |
|---|---|---|
| FLOOR(-456.2) | -457 | 比-456.2小的最大整数是-457 |
5、POW (X, Y)
功能:返回 X 的 Y 次幂;若Y<0则相当于X的|Y|次幂再取倒数。
| 示例 | 结果 | 解释 |
|---|---|---|
| POW(16, -0.5) | 0.25 | 1 / √16 |
(六)日时函数
1、日时函数概览
| 函数 | 功能 |
|---|---|
| NOW, SYSDATE, CURRENT_DATE | 当前日时 |
| WEEK,WEEKOFYEAR | 日期的周数 |
| LAST_DAY | 日期月份的最后一天 |
| DATE_FORMAT | 日期格式化 |
| ADD_MONTHS 、DATE_ADD、DATE_SUB | 日期偏移 |
| DATEDIFF、TIMESTAMPDIFF | 日期差值 |
| YEAR,MONTH,DAY,WEEKDAY | 提取日时元素:年、月、日,星期等 |
| EXTRACT | 提取日时元素:年、月、日及其组合等 |
2、当前日时函数:
(1) 获得当前日期和时间:
NOW(), SYSDATE(), CURRENT_DATETIME()
(2) 获得当前日期:
CURRENT_DATE(), CURDATE()
(3) 获得当前时间(注意:输出结果不带日期):
CURRENT_TIME()
小贴士:NOW 和 SYSDATE 函数的区别
① SYSDATE 返回的是该函数执行时的日期时间。
② NOW 返回的是语句开始执行的日期时间,在语句执行结束前不会变化。
执行以下 SQL,我们就能很清晰理解 SYSDATE 和 NOW 函数的区别:
SELECT NOW(), SYSDATE(), SLEEP(3), NOW(), SYSDATE()
3、WEEK (date[,mode]):
功能:返回日期的周数。
参数:缺省参数 mode 值从 0 到 9。
| 模式 | 周的起始天 | 范围 | 说明 |
|---|---|---|---|
| 0 | Sunday | 0~53 | 遇到本年的第一个周日开始,是第一周。前面的计算为第0周 |
| 1 | Monday | 0~53 | 若第一周能超过3天,那么计算为本年的第一周。否则为第0周 |
| 2 | Sunday | 1~53 | 遇到本年的第一个周日开始,是第一周 |
| 3 | Monday | 1~53 | 假如第一周能超过3天,那么计算为本年的第一周。否则为上年度的第5x周 |
| 4 | Sunday | 0~53 | 若第一周能超过3天,那么计算为本年的第一周。否则为第0周 |
| 5 | Monday | 0~53 | 遇到本年的第一个星期一开始,是第一周 |
| 6 | Sunday | 1~53 | 假如第一周能超过3天,那么计算为本年的第一周。否则为上年度的第5x周 |
| 7 | Monday | 1~53 | 遇到本年的第一个星期一开始,是第一周 |
| 8 | Sunday | 1~54 | 周日算一周的开始,并且只要有一天就算一周 |
| 9 | Monday | 1~54 | 周一算一周的开始,并且只要有一天就算一周 |
这么多模式记住常用的一两个即可,未来使用时根据项目需求以本章作为手册查询。我们挑两个模式分析下 mode 的含义。
| 函数调用 | 返回值 | 注解 |
|---|---|---|
| WEEK(‘2022-1-1’, 3) | 52 | 模式 3:周一算一周的开始,这天是周六,第一周没有超过3天, 则结果为上年度的第52周 |
| WEEK(‘2022-1-1’, 9) | 1 | 模式 9:周一算一周的开始,按照规则只要有一天就算一周, 则结果为第1周 |
4、WEEKOFYEAR (date) :
功能:返回日期的周数:1 ~ 53,等价于 WEEK 函数的 mode 3
WEEKOFYEAR('2021-1-1') # 第 52 周
WEEK('2021-1-1', 3) # 第 52 周
5、LAST_DAY (date) :
功能:返回月份日期的最后一天。
| 函数调用 | 返回值 | 注解 |
|---|---|---|
| LAST_DAY(‘2019-2-10’) | 2019-02-28 | 可以用来判断平闰年 |
| LAST_DAY(‘2020-2-10 12:10:30’) | 2020-02-29 | 不会理会时间 |
| LAST_DAY(‘19-5-10’) | 2019-05-31 | 19被视作2019 |
| LAST_DAY(‘190510’) | 2019-05-31 | 19被视作2019 |
| LAST_DAY(‘2022-2-30’) | NULL | 不存在的日期 |
| LAST_DAY(‘0000-01-01’) | NULL | 不存在的年份 |
6、DATE_FORMAT(date, <格式符号>):
功能:日期类型数据的格式化。
以下是所有“格式符号”个描述——
| 格式 | 描述 |
|---|---|
| %a | 星期名的英文缩写形式(Sun…Sat) |
| %b | 月份的英文缩写形式(Jan…Dec) |
| %c | 月份的数字形式(0…12) |
| %D | 有英文后缀的某月的第几天(1st,2nd,3rd…) |
| %d | 月份中的天数,数字形式(00…31) |
| %e | 月份中的天数,数字形式(0…31) |
| %f | 微秒(000000…999999) |
| %H | 小时,24小时制(00…23) |
| %h | 小时,12小时制(0,1…12) |
| %I | 小时,12小时制,个位数字前加0(01…12) |
| %i | 分钟,数字形式(00…59) |
| %j | 一年中的天数(001…366) |
| %k | 小时,24小时制(0…23) |
| %l | 小时,12小时制(1…12) |
| %M | 月份,英文形式全拼(January…December) |
| %m | 月份,数字形式(00…12) |
| %p | AM或PM |
| %r | 时间,12小时制(HH:MI:SS后面紧跟AM或PM) |
| %S | 秒(00…59) |
| %s | 秒(00…59) |
| %T | 时间,24小时(HH:MI:SS) |
| %U | 星期(00…53),星期日是一个星期的第一天 |
| %u | 星期(00…53),星期一是一个星期的第一天 |
| %V | 星期(01…53),星期日是一周的第一天。与%X一起使用 |
| %v | 星期(01…53),星期一是一周的第一天。与%x一起使用 |
| %W | 星期名的英文全拼形式(Sunday…Saturday) |
| %w | 一星期中的哪一天(0=Sunday…6=Saturday) |
| %X | 以4位数字形式反映周所在的年份,星期日周的第一天 |
| %x | 同 %X |
| %Y | 4位数字形式表达的年份 |
| %y | 2位数字形式表达的年份 |
| %% | 一个 % |
示例:
| 函数调用 | 返回值 |
|---|---|
| DATE_FORMAT(NOW(), ‘%Y年%m月%d日’) | 2022年03月19日 |
| DATE_FORMAT(‘2022-03-11’, ‘%W %M %Y’) | Friday March 2022 |
| DATE_FORMAT(‘2021-03-19 10:38:59’, ‘%H:%i:%s’) | 10:38:59 |
实际应用中 DATE_FORMAT 函数的第一个参数一般是 datetime / date 类型的。格式符号记住几种常用的组合即可,项目上更多需要时可以查阅以上表格。
7、日期偏移函数:
ADD_MONTHS ( date, <月份数>) :
功能:在一个日期上加上指定的月份数。
| 函数调用 | 返回值 |
|---|---|
| ADD_MONTHS(‘2020-02-29 10:38:59’, 12) | 2021-02-28 10:38:59 |
上面例子做了一个边界测试。2020年是闰年,二月有29天,增加12个月后到2021年2月,平年只有28天。
DATE_ADD(date, INTERVAL <数值> type)
功能:日期加法操作 负值表示减法。
DATE_SUB(date, INTERVAL <数值> type)
功能:日期减法操作。
type 值可以为:MICROSECOND、SECOND、MINUTE、HOUR、DAY、WEEK、MONTH、QUARTER、YEAR
示例:
| 函数调用 | 返回值 | 解释 |
|---|---|---|
| NOW() | 2022-01-26 13:17:58 | 当前日期和时间 |
| DATE_ADD(INTERVAL 1 DAY) | 2022-01-27 13:17:58 | 一天后 |
| DATE_SUB(date(now()), INTERVAL 7 DAY) | 2022-01-19 | 7天前 |
| DATE_SUB(date(now()), INTERVAL 1 Month) | 2021-12-27 | 一个月前 |
8、日期比较
DATEDIFF(date1, date2)
功能:开始日期 date1 和结束日期 date2 之间的天数。
| 函数调用 | 返回值 |
|---|---|
| DATEDIFF(LAST_DAY(NOW()),NOW()) | 5 |
TIMESTAMPDIFF(< type >,开始日期, 结束日期): 取两日期的 type 相差数
type 可以为 YEAR、MONTH、DAY、WEEK、QUARTER 等。
| 函数调用 | 返回值 | 备注 |
|---|---|---|
| SELECT TIMESTAMPDIFF(MONTH,‘2022-11-30’, ‘2022-12-1’) | 0 | 实际天数差1天 |
| SELECT TIMESTAMPDIFF(MONTH,‘2022-11-30’, ‘2022-12-29’) | 0 | 实际天数差29天 |
| SELECT TIMESTAMPDIFF(MONTH,‘2022-11-30’, ‘2022-12-30’) | 1 | 实际天数差30天 |
注意:TIMESTAMPDIFF 返回值不是根据天数差计算月份差值的。规则是:1、以结束日期和开始日期月份差值为基数 BASE;2、如果结束日期的日值小于开始日期的日值则最后的结果为 BASE - 1;否则最后的结果就是 BASE。
PERIOD_DIFF(P1,P2)
功能:取两个日期之间的月份相差数。
注意:P1和P2不是日期类型,数值格式以YYMM或YYYYMM指定。
| 函数调用 | 返回值 |
|---|---|
| PERIOD_DIFF(‘202203’,‘202103’) | 12 |
| PERIOD_DIFF(2103,2203) | -12 |
9、获取日期和时间部分的函数:
YEAR(NOW()) --年
MONTH(NOW()) --月
DAY(NOW()) --日
WEEKDAY(NOW()) --星期索引(0=Monday,1=Tuesday,...6=Sunday);
QUARTER(NOW()); -- 季度
HOUR(NOW()); -- 小时
MINUTE(NOW()); -- 分钟
SECOND(NOW()); -- 秒
MICROSECOND(NOW()); -- 微秒
这些函数的参数是 date/datetime 类型的,或者能转换成 date 类型的字符串。例如:
select YEAR('2022-6-1 15:00'); # 返回结果:2022
10、EXTRACT(type FROM
功能:日时元素提取函数。
参数:type 有如下枚举值。
| type | 说明 |
|---|---|
| YEAR | 年 |
| MONTH | 月 |
| DAY | 日 |
| HOUR | 小时 |
| MINUTE | 分钟 |
| MICROSECOND | 微秒 |
| SECOND | 秒 |
| WEEK | 星期 |
| QUARTER | 季度 |
| 函数调用 | 返回值 |
|---|---|
| NOW() | 2021-03-19 18:17:28 |
| EXTRACT(WEEK FROM NOW()) | 11 |
| EXTRACT(YEAR_MONTH FROM NOW()) | 202103 |
11、日时函数综合练习
测试表 testDT 数据如下:
| ID | DT |
|---|---|
| 1 | 2021-03-22 14:20:17 |
| 2 | 2021-03-21 14:20:17 |
| 3 | 2021-01-01 00:00:00 |
| 4 | 2021-03-15 14:38:24 |
| 5 | 2021-02-22 14:41:58 |
| 6 | 2020-03-22 14:47:32 |
| 7 | 2022-01-25 00:00:00 |
== 以下示例仅为熟悉函数功能,不考虑性能 ==
# (e.g.1)查询本年月的数据
SELECT * FROM testDT
WHERE EXTRACT(YEAR_MONTH FROM DT)=EXTRACT(YEAR_MONTH FROM '2022-01-25 14:40');
| ID | DT |
|---|---|
| 7 | 2022-01-25 00:00:00 |
# (e.g.2)查询上一月信息
SELECT * FROM testDT
WHERE PERIOD_DIFF(DATE_FORMAT('2022-02-25 14:40', '%Y%m'), DATE_FORMAT(DT, '%Y%m')) = 1
| ID | DT |
|---|---|
| 7 | 2022-01-25 00:00:00 |
# (e.g.3)查询近7天信息
SELECT DT, DATE_SUB(DT, INTERVAL 7 DAY)七天前 FROM testDT
WHERE DT >= DATE_SUB('2022-01-25 14:40', INTERVAL 7 DAY)
| DT | 七天前 |
|---|---|
| 2022-01-25 00:00:00 | 2022-01-18 00:00:00 |
# (e.g.4)查询上年数据
SELECT * FROM testDT
WHERE YEAR(DT)=YEAR(date_sub('2022-01-25 14:40',INTERVAL 1 YEAR));
| ID | DT |
|---|---|
| 1 | 2021-03-22 14:20:17 |
| 2 | 2021-03-21 14:20:17 |
| 3 | 2021-01-01 00:00:00 |
| 4 | 2021-03-15 14:38:24 |
| 5 | 2021-02-22 14:41:58 |
(七)字符串处理函数
| 常用函数 | 基本功能 |
|---|---|
| LOWER,LCASE,UPPER | 转换字母大小写 |
| REPLACE | 替换字符串中指定的字符串 |
| ASCII | 取ASCII码 |
| CONCAT 或 || | 字符串连接 |
| SUBSTRING,LEFT,RIGHT | 字符串截取 |
| INSTR | 取字符串位置 |
| NVL | 替换NULL值 |
| TRIM,LTRIM,RTRIM | 去除字符串中空格 |
| LENGTH ,CHAR_LENGTH | 取字符串长度 |
1、LOWER, LCASE:全部字母转换为小写;UPPER, UCASE:全部字母转换为大写
| 函数调用 | 返回值 |
|---|---|
| UPPER(‘gb’) || LOWER(‘ASE’) || LCASE(’ 8A’) | GBase 8a |
2、REPLACE(String,fromStr,toStr) :替换字符串中指定的字符串
| 函数调用 | 返回值 |
|---|---|
| REPLACE(‘1234567’,‘23’,‘AB’) | 1AB4567 |
小贴士:REPLACE 第一个参数通常是一个字符型字段,执行 REPLACE 操作后,该字段的值是不会变化的。
3、ASCII
功能:返回字符串首字符的ASCII码值
| 函数调用 | 返回值 | 解释 |
|---|---|---|
| ASCII(‘A’) | 65 | |
| ASCII(‘Abc’) | 65 | 多个字符只取第一个 |
| ASCII(NULL) | NULL | 空指针做参数不会报错 |
4、CHAR
功能:返回ASCII码值对应的字符组成的字符串,忽略 NULL
| 函数调用 | 返回值 | 解释 |
|---|---|---|
| CHAR(65, 66, NULL, 67) | ABC | NULL 被忽略了 |
5、CONCAT 或 ||
功能:字符串连接,可将将数字隐形转换为字符串。
select CONCAT('GBASE公司', ceiling(datediff(now(), '2004-5-1')/365), '岁了') as RESULT;
| RESULT |
|---|
| GBASE公司19岁了 |
GBASE公司成立于2004-5-1,今天是2022-6-9,年头超过18年,由于ceiling是天花板整除函数,所以,最后的结果是19。
6、GROUP_CONCAT (<列名> separator <分隔符>)
功能:同一分组内聚集列字符串进行连接。
测试表 student Sname 列数据如下——
| Sname |
|---|
| 刘备 |
| 孙权 |
| 曹操 |
| 张辽 |
| 貂蝉 |
| 小乔 |
| 大乔 |
| 关羽 |
| 周瑜 |
| 张飞 |
| 陆逊 |
执行以下 SQL
select GROUP_CONCAT(Sname separator '\\\\') RESULT from student
| RESULT |
|---|
| 关羽\刘备\周瑜\大乔\孙权\小乔\张辽\张飞\曹操\貂蝉\陆逊 |
小贴士:
1、分隔符是“\”,需要转义,即"\"。
2、如果拼接后的字串超过 1024 个字节,SQL 将报错聚集数据越界的错误。此时可以考虑将系统参数 group_concat_max_len 放大一些。其默认值1024,最大32767。
3、GROUP_CONCAT 不能和 Order By 子句一起使用。
7、SUBSTRING_INDEX (<原始字符串>, ‘<分隔符>’, N)
功能:以指定分隔符将原始字符串分隔为子字符串序列,从第一个子字符串取到第 N 个子字符串。
| 函数调用 | 返回值 | 解释 |
|---|---|---|
| substring_index(‘www.baidu.com’, ‘.’, 2) | www.baidu | www.baidu.com 以 “.” 分割为 www、baidu、com 三个子字符串,取前两个子字符串然后再用分隔符连接起来 |
| substring_index(‘www.baidu.com’, ‘.’, 0) | 返回空串 |
小贴士:如果原始分隔符在字符串中不存在,则原始字符串只能是一个子字符串,只要 N > 0 该函数的返回值都是原始字串。
8、INSTR (源字符串,查找字符串,起始位置,第n次出现)
功能:返回查找字符串位置。查找到的位置索引从 1 开始。
| 函数调用 | 返回值 | 解释 |
|---|---|---|
| INSTR(‘wwerw.gbase.cerom’,‘er’) | 3 | |
| INSTR(‘wwerw.gbase.cerom’,‘er’,1,2) | 14 |
9、NVL (<字符串>,replace_with)
功能:若第一个参数是 NULL,函数返回 replace_with。
select cID, cName, nvl(cpno,'unknown') as CPNo from subject;
| cID | cName | CPNo |
|---|---|---|
| 1 | 数据库 | 5 |
| 2 | 数学 | unknown |
| 3 | 信息系统 | 1 |
| 4 | 操作系统 | 6 |
| 5 | 数据结构 | 7 |
| 6 | 数据处理 | unknown |
| 7 | Python语言 | 6 |
nvl 函数替换 cpno 列中 NULL 值为 “unknown” 字串。
10、LEFT / RIGHT
功能:从左/右截取指定位数的字符串。
下面的例子是数字格式化,统一成四位,不足四位左补零。
| 函数调用 | 返回值 | 解释 |
|---|---|---|
| RIGHT(concat(repeat(‘0’, 4), 12),4) | 0012 |
11、LENGTH(<字符串>):返回字节长度。
CHAR_LENGTH(<字符串>):返回字符长度。。
CHARACTER_LENGTH(<字符串>):返回字符长度。
GBase 8a 默认安装时字符集是UTF8,一个汉字占3个字节。
| 函数调用 | 返回值 | 解释 |
|---|---|---|
| LENGTH('南大通用GBase ') | 17 | 3个汉字和5个字母 |
| CHAR_LENGTH(‘南大通用GBase’); | 9 | 一个汉字都是一个字符 |
12、TRIM( [{BOTH | LEADING | TRAILING} [trim_char] FROM] <字符串> )
功能:移除<字符串>中所有的 trim_char 前缀或后缀。如果没有给出任何 BOTH、LEADING 或 TRAILING 修饰符,默认BOTH。如果没有指定 trim_char,将移除空格。
| 函数调用 | 返回值 | 解释 |
|---|---|---|
| TRIM(TRAILING ‘.pptx’ from ‘GBase 8a 集群核心技术.pptx’) | GBase 8a 集群核心技术 | 去掉 File Name 的扩展名 |
(八)转换函数
| 函数 | 功能 |
|---|---|
| CAST、CONVERT | 数据类型转换 |
| CONV | 不同数字进制间的转换 |
| TO_NUMBER | 字符串 string转化成数值 |
| TO_CHAR | 日期转化为字符串 |
| TO_DATE | 字符串 string 格式化成 format 类型的日期 |
TO_DATE 函数的功能不如 DATE_FORMAT 强大,所以本文没有该函数的示例。
1、CAST(expr AS type)、CONVERT(expr,type)
功能 :数据类型转换。
参数:type 可以是下列值之一:
CHAR、DATE、DATETIME、DECIMAL、TIME、NUMERIC、INT、SIGNED INT、SIGNED
| 函数调用 | 返回值 | 解释 |
|---|---|---|
| NOW() | 2019-06-07 04:10:02 | 当前日期时间 |
| CAST(NOW() AS DATE) | 2019-06-07 | 将 datetime 类型转换为 date 类型 |
- 隐式转换规则
(1) 若字符串是以数字开头,并且全部都是数字,则转换的数字结果是整个字符串;部分是数字,则转换的数字结果是截止到第一个不是数字的字符为止。
SELECT '122ABC' + 1; # 结果:123
(2) 若字符串不是以数字开头,则转换的数字结果是 0
SELECT 'AB33' + 100; # 结果:100
2、CONV (N,from_base,to_base)
功能:数字进制转换。
参数:将 N 由 from_base 进制转化为 to_base 进制的字符串,任意一个参数为 NULL,则返回值为 NULL。
| 函数调用 | 返回值 | 解释 |
|---|---|---|
| CONV(5,10,2) | 101 | 十进制转二进制 |
| CONV(‘FF’,16,10) | 255 | 十六进制转十进制 |
3、TO_CHAR (datetime,[FORMAT])
功能:将日期时间转换为字符串,并进行格式化输出。
TO_CHAR (number,[FORMAT])
功能:将数字转换为字符串,并进行格式化输出。
| 函数调用 | 返回值 | 解释 |
|---|---|---|
| NOW() | ||
| TO_CHAR(now(),‘YYYY/MM/DD’) | 2022/06/10 | 2022-06-10 15:30:50 |
| TO_CHAR(now(),‘YYYY"年"MM"月"DD"日"’) | 2022年06月10日 | 插入 FORMAT 以外的字符要使用双引号 |
| TO_CHAR(987654321,‘999,999,999’) | 987,654,321 | 千分位格式 |
4、TO_NUMBER
功能:将字串表达式中的数字转换为数值型。
| 函数调用 | 返回值 | 解释 |
|---|---|---|
| TO_NUMBER(‘3.14’)+3.14 | 6.28 | 依赖隐式转换、不用 TO_NUMBER 也是可以的 |
| SELECT TO_NUMBER(‘+000000123’) | 123 |
(九)控制流函数
1、IF (expr, value1, value2)
功能:expr 为 TRUE ,则 IF 的返回值为 value1;否则返回值为 value2;
【示例】
SELECT country1, country2, R1, R2, if( R1 > R2, '胜', if(R1=R2, '平', '负') )结果
FROM worldcup;
【执行结果】
| country1 | country2 | R1 | R2 | 结果 |
|---|---|---|---|---|
| 俄罗斯 | 沙特 | 5 | 0 | 胜 |
| 埃及 | 乌拉圭 | 0 | 1 | 负 |
| 摩洛哥 | 伊朗 | 0 | 1 | 负 |
| 葡萄牙 | 西班牙 | 3 | 3 | 平 |
| 法国 | 澳大利亚 | 2 | 1 | 胜 |
| 阿根廷 | 冰岛 | 1 | 1 | 平 |
| 秘鲁 | 丹麦 | 0 | 1 | 负 |
| 克罗地亚 | 尼日利亚 | 2 | 0 | 胜 |
| 哥斯达黎加 | 塞尔维亚 | 0 | 1 | 负 |
| 德国 | 墨西哥 | 0 | 1 | 负 |
2、IFNULL(expr1,expr2)
功能:如果 expr1 不为 NULL,返回值为 expr1,否则其返回值为 expr2;
SELECT IFNULL(country,'未知')RESULT FROM worldcup;
(1) 如果换成 CASE WHEN:
SELECT (CASE WHEN country IS NULL THEN‘未知’ELSE country END) FROM worldcup;
(2) 如果换成 NVL 函数:
SELECT NVL(country, '未知') FROM worldcup;
(3) 如果换成 IF 函数:
SELECT IF(country is null, '未知', country) FROM worldcup;
3、DECODE ( 字段名,值1,翻值1,值2,翻译值2,…值n,翻译值n,缺省值 )
功能:将查询结果翻译成其他值。类似于:CASE WHEN … THEN 表达式。字段值分别和值1到值n匹配,若没有匹配任何值,返回缺省值。
# 示例:统计世界杯国家胜负场次。result(积分)为3就是胜场,积分 0 就是负场
SELECT country1, sum(decode(result,3,1,0)) 胜, sum(decode(result,0,1,0)) 负
FROM worldcup GROUP BY country1 ORDER BY 胜 desc,负 asc;
执行结果:
| country1 | 胜 | 负 |
|---|---|---|
| 法国 | 5 | 0 |
| 比利时 | 4 | 0 |
| 克罗地亚 | 3 | 0 |
| 俄罗斯 | 3 | 2 |
| 巴西 | 2 | 1 |
| 瑞典 | 2 | 1 |
| 沙特 | 1 | 0 |
| 葡萄牙 | 1 | 0 |
| 德国 | 1 | 1 |
| 尼日利亚 | 1 | 1 |
(十)正则函数
使用正则表达式的内置函数叫做正则函数。在讲解正则函数之前需要熟悉正则表达式。
0、正则表达式
- 正则的功能
(1) 校验数据有效性
(2) 查找符合要求的文本内容
(3) 对文本进行切割,替换等操作 - 元字符的概念
(1) 正则表达式是由一系列元字符组成的匹配字串;
(2) 元字符是正则表达式中具有特殊意义的专用字符;
(3) 构成正则表达式的基本元件。 - 元字符的构成

(1) 特殊单字符
| 字符 | 描述 |
|---|---|
| . | 匹配除 “\n” 之外的任何单个字符。要匹配包括 ‘\n’ 在内的任何字符,请使用象 ‘[.\n]’ 的模式。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \w | 匹配包括下划线的任何单词字符。等价于’[A-Za-z0-9_]'。 |
| \W | 匹配任何非单词字符。等价于 ‘[^A-Za-z0-9_]’。 将下一个字符标记为一个特殊字符、或一个原义字符、或一个 后向引用、或一个八进制转义符。例如,‘n’ 匹配字符 “n”。‘\n’ 匹配一个换行符。序列 ‘\’ 匹配 “” |
| ^ | 匹配输入字符串的开始位置。 |
| $ | 匹配输入字符串的结束位置。 |
(2) 空白符
| 字符 | 描述 |
|---|---|
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如, ‘er\b’ 可以匹配"never" 中的 ‘er’,但不能匹配 “verb” 中的 ‘er’。 |
| \B | 匹配非单词边界。‘er\B’ 能匹配 “verb” 中的 ‘er’,但不能匹配 “never” 中的 ‘er’。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL。 |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM。 |
| \t | 匹配一个制表符。等价于 \x09 和 \cI。 |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK。 |
(3) 量词
| 字符 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 “z” 以及 “zoo”。 * 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,‘zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,“do(es)?” 可以匹配 “do” 或 “does” 中的"do" 。? 等价于 {0,1}。 |
| {n} | n 是自然数。匹配确定的 n 次。例如,‘o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o。 |
| {n,} | n 是自然数。至少匹配n 次。例如,‘o{2,}’ 不能匹配 “Bob” 中的 ‘o’,但能匹配 “foooood” 中的所有 o。‘o{1,}’ 等价于 ‘o+’。‘o{0,}’ 则等价于 ‘o*’。 |
| {n,m} | m 和 n 均为自然数,n <= m。最少匹配 n 次且最多匹配 m 次。刘, “o{1,3}” 将匹配 “fooooood” 中的前三个 o。‘o{0,1}’ 等价于 ‘o?’。请注意在逗号和两个数之间不能有空格。 |
(4) 范围
| 字符 | 描述 |
|---|---|
| | | 表示“或”的关系。比如 (http?|ftp):\/\/ |
| [a-z] | 表示匹配 26 个小写字母之一 |
| [^a-z] | 取反,匹配 26 个小写字母之外的某个字符 |
1、REGEXP_LIKE (source_char, pattern [, match_paramater])
功能:正则匹配,使用正则表达式匹配源字符串。
| 参数 | 说明 |
|---|---|
| source_char | 源字符串。该参数支持的数据类型与replace函数的src参数一致。 |
| pattern | 正则表达式。仅支持字符串,最多可包含512个字节 |
| match_paramater | i:大小写不敏感; c:大小写敏感; n:点号(.)匹配换行符号; m:多行模式; x:扩展模式,忽略正则表达式中的空白字符 |
- REGEXP_LIKE 练习
测试表 test_reg 的数据
| id | value |
|---|---|
| 1 | 1234560 |
| 2 | I can swim |
| 3 | 1b3b560 |
| 4 | abc |
| 5 | abcde |
| 6 | ADREasx |
| 7 | 123 45 |
| 8 | adc de |
| 9 | adc,.de |
| 10 | 1B |
| 10 | abcbvbnb |
| 11 | 11114560 |
| 11 | 11124560 |
(1) 查询value中以1开头60结束的记录并且长度是7位
select * from test_reg where value like '1____60'; # 使用 like,结果是正确的。每个“_”表示一个字符。
select * from test_reg where regexp_like(value,'1.{4}60'); # 贪婪模式造成多匹配出两个记录。贪婪模式是最大长度匹配,只要1到60之间找到4个字符,即为匹配。
select * from test_reg where regexp_like(value,'^1.{4}60$'); # 这是符合需求的最精确的正则。非贪婪模式,1到60之间存在且只有4个字符,才能匹配。“^”表示匹配开始,“$”表示匹配结束。
(2) 查询value中以1开头60结束的记录并且长度是7位并且全部是数字的记录;
select * from test_reg where regexp_like(value,'^1[0-9]{4}60$');
select * from test_reg where regexp_like(value,'^1[\\d]{4}60$'); # \d 匹配一个数字字符
select * from test_reg where regexp_like(value,'^1[[:digit:]]{4}60$');-- 也可以使用字符集
(3) 查询value中不是纯数字的记录
select * from test_reg where not regexp_like(value,'^[[:digit:]]+$');
# “[[:digit:]]” 是 PHP 正则表达式的通用字符簇,表示任何数字
(4) 查询value中不包含任何数字的记录
select * from test_reg where regexp_like(value,'^[^[:digit:]]+$');
# “[[:digit:]]” 是 PHP 正则表达式的通用字符簇,表示任何数字。该表达式匹配到不存在数字的源字串
(5) 查询以12或者1b开头的记录.不区分大小写
select * from test_reg where regexp_like(value,'^1[2b]','i'); # 不区分大小写
/*
id value
1 1234560
3 1b3b560
7 123 45
10 1B
*/
(6) 查询以12或者1b开头的记录.区分大小写
select * from test_reg where regexp_like(value,'^1[2B]');
/*
id value
1 1234560
7 123 45
10 1B
*/
(7) 查询数据中包含空白的记录
select * from test_reg where regexp_like(value,'[[:space:]]');
# “[[:space:]]” 是 PHP 正则表达式的通用字符簇,表示任意空白字符(空格、制表符、回车、换行)
(8) 查询所有包含小写字母或者数字的记录
select * from test_reg where regexp_like(value,'^([a-z]+|[0-9]+)$');
# 注意 “[a-z]+” 和 “[0-9]+” 之间 有 “|” 表示或的关系
(9) 查询任何包含标点符号的记录
select * from test_reg where regexp_like(value,'[[:punct:]]');
# “[[:punct:]]” 是 PHP 正则表达式的通用字符簇,表示任何标点符号
2、REGEXP_REPLACE (source_char,pattern[,replace_string[,position [,occurence[match_option]]]])
功能:正则替换,用指定的字符串替换源字符串中与指定正则表达式相匹配的字符串。
| 参数 | 说明 |
|---|---|
| source_char | 源字符串。该参数支持的数据类型与replace函数的src参数一致。 |
| pattern | 正则表达式。每个正则表达式最多可包含512个字节。 |
| replace_string | 替换字符串。替换字符串可以包含反向引用的数字表达式(\n,n的取值范围是[1,9]) |
| position | 开始匹配的位置,如果不指定默认为1,即从source_char的第一个字符开始匹配。position 为一个正整数。 |
| occurrence | 正则匹配的序数。是一个非负的整数,默认值为0。0,表示替换所有匹配到的出现;正整数,替换第n次匹配到的出现; |
| match_paramater | c:大小写敏感;n:点号(.)不匹配换行符号;m:多行模式;x:扩展模式,忽略正则表达式中的空白字符。 |
- REGEXP_REPLACE 练习
# 1、替换数字为字母 Q
select value, REGEXP_REPLACE (value,'[0-9]+','Q') AS Result from test_reg
# 2、替换第三个单词为 READ
#update test_reg set value='I can swim' where id=2
select value, REGEXP_REPLACE(value,'\\w+','READ', 1, 3) Result
from test_reg
where id=2
3、REGEXP_INSTR (source_char,pattern[,position[,occurence[,return_opt[,match_parameter[,subexpr]]]]])
功能:正则搜索,获得匹配字符串的位置。
| 参数 | 说明 |
|---|---|
| source_char | 源字符串。该参数支持的数据类型与replace函数的src参数一致。 |
| pattern | 正则表达式。仅支持字符串,每个正则表达式最多可包含512个字节。 |
| position | 开始匹配的位置。默认值为1,即从source_char的第一个字符开始匹配。 |
| occurrence | 正则匹配的序数。正整数,默认值为1,找到第N次匹配到的出现。 |
| return_opt | 返回值的类型,非负整数默认值为0。0,返回值为匹配位置的第一个字符的位置。n,返回匹配的字符串后紧跟着的第一个字符的位置。match_paramater |
| subexpr | 对于含有子表达式的正则表达式,表示正则表达式中的第几个子串是函数目标。该参数值域范围是0~9,超过9,函数返回0。默认为0。0,返回与正则表达式匹配的字符的位置,全匹配上返回1,不匹配返回0;大于0,返回指定的子串的位置。该值大于子串个数时,返回0;源字符串中有括号时,按照正则支持的转义处理。 |
subexpr 参数不常用,本文不在赘述。
- REGEXP_INSTR 练习
# 1、搜索数字第一次出现的位置
select value, REGEXP_INSTR (value,'[0-9]+') AS Result from test_reg
# 2、找数字(从第一个字母开始匹配,找第1个匹配项目的紧跟着的第一个字符的位置)
select value, REGEXP_INSTR (value,'[0-9]+', 1, 1, 1) AS Result from test_reg
# position=1 表示从 value 字符串的第一个位置开始搜索;occurrence=1 表示找到第一次出现的位置;return_opt=1 表示匹配字符的下一个位置
# 3、找到第三个单词的位置
select value, REGEXP_INSTR(value,'\\w+', 1, 3) Result
from test_reg
where id=2
4、REGEXP_SUBSTR (source_char,pattern[,position[,occurence]])
功能:获得匹配到的字符串。
| 参数 | 说明 |
|---|---|
| source_char | 源字符串。该参数支持的数据类型与replace函数的src参数一致。 |
| pattern | 正则表达式。仅支持字符串,每个正则表达式最多可包含512个字节。 |
| position | 开始匹配的位置。默认值为1,即从source_char的第一个字符开始匹配。 |
| occurrence | 正则匹配的序数。正整数,默认值为1,找到第N次匹配到的出现。 |
- REGEXP_SUBSTR 练习
# 1、搜索第一次出现的数字
select value, REGEXP_SUBSTR (value,'[0-9]+') AS Result from test_reg
# 2、找到第三个单词的内容
select value, REGEXP_SUBSTR(value,'\\w+', 1, 3) Result
from test_reg
where id=2
(十一)信息函数
1、Database():返回当前数据库名字,比如
courseware
2、User():返回当前用户名,比如
root@127.0.0.1
3、Version():返回当前系统版本,比如
9.5.2.39.126761
4、CHARSET(<字符串>):返回字符串参数使用的字符集
| 函数调用 | 返回值 |
|---|---|
| charset(‘南大通用’) | utf8 |
(十二)函数与性能
1、函数不要用在字段上:
【优化前】select Sid, Sname, Sage from Student
where to_char(Sage,‘YYYY’) >= 2013;
【优化后】select Sid, Sname, Sage from Student
where Sage >= ‘2013-01-01’;
小贴士:函数使用在字段上,每一行字段数据都会执行函数,智能索引失效;函数使用在值上,则只执行一次,还能利用智能索引。
2、避免使用无必要的转换函数:
【优化前】select Sid, Sname, Sage from Student
where Sage >= to_date(‘2010-08-06’, ‘YYYY-MM-DD’);
【优化后】select Sid, Sname, Sage from Student
where Sage >= ‘2010-08-06’;
小贴士:WHERE 子句中,表达式的比对数值能用隐式转换就不使用数据类型转换函数。
3、超大数据量不能使用 NOT EXISTS:
【优化前】select * from Student where NOT EXISTS(select 1 from
score where SId=Student.SId)
【优化后】select * from Student where SId not in(select SId from score where SId is not null)
小贴士:需要量表关联,但是关联表字段不同值很少,表数据量较大,NOT EXISTS 会导致产生大量临时文件。改成 not in 后效率会有较大提高,但是需要加上关联字段不为空的条件。
4、巧用 COUNT( DISTINCT):
【优化前】select count(CId),count(TId) from course;
【优化后】select * from(select count(CId) from course)T1
join (select count(TId) from course)T2;
小贴士:对多列去重计数,当前执行计划先在各节点对参与 count(distinct) 的列进行分组去重,结果再汇总到一个节点进行 count(distinct) 运算。当 count(distinct) 列很多时,参与 group by 运算的列也很多,去重效果不理想,导致大量数据要拉到一个节点进行 count(distinct) 运算,拉表和汇总计算耗时非常长。优化的方法是各列分别计算 count(distinct),提高去重效果,然后对结果集进行拼接。
5、简单的模糊匹配不要使用正则匹配函数:
【优化前】select * from test_reg where REGEXP_LIKE(value, ‘^1.{4}60$’);
【优化后】select * from test_reg where value LIKE ‘1____60’
小贴士:正则匹配函数应用场景是复杂的模糊匹配,功能强大的同时,资源耗费肯定高于原生的 LIKE。
三、DQL 进阶
(一)什么是 DQL
英文全称 Data Query Language,是执行数据查询功能的 SELECT 关键字引导的 SQL 语句。
(二)SELECT 语句语法格式和执行顺序
1、语法

- 投影列:从数据集中选择出来的列。
- 数据集:可以是单张实表,也可以是多张表的关联,或者视图(view)。
- 条件:WHERE 子句引导的数据集的过滤条件。
- 聚合:按照一个或多个维度字段分组聚合运算(求和、求平均、取最大值、取最小值、计数)。HAVING 子句是针对 GROUP BY 聚合后的结果做过滤的条件。
- 排序:对最终结果集按照一个或多个字段排序。
- 限制行数:limit offfset,row_count 中的 offset 表示要跳过行数,row_count 表示取多少行。例如,
select * from student limit 3; # 取前三行的数据
select * from student limit 1,3; # 从第二行开始取三行
select * from student limit 3 offset 1; # 从第二行开始取三行(和第二个 SQL 是一样的语法含义)
- 导出数据:
SELECT 语句查询到的数据集可以直接输出到 OUTFILE (外部文件)中。请参阅《GBase 8a MPP Cluster 数据导出》章节,本文不再赘述。
2、执行顺序
SELECT 语句的编写顺序:
select - from - where - group by - having - order by
执行顺序和编写顺序是不尽相同:
- from 圈定一张或多(JOIN)张表的数据;
- start with…connect by 执行分层查询;
- where 基于指定的条件对 from 数据集进行过滤;
- group by 结合聚合将以上结果集分组;
- 使用聚集函数进行计算;
- having 筛选聚合后的结果集;
- select 投影列、数据去重操作;
- order by 对最终结果集进行排序;
- into outfile 把最终结果集导出到数据库服务器。 。
3、基本算子的执行顺序

算子是数据库引擎运算的基本单元。上图中From算子是先执行的,然后是Scan用于定位数据库对象的算子,包括TableScan(顺序表扫面)和IndexScan(索引扫描)两种。Filter是将数据集做过滤的算子,对应 Where 关键字。Join算子用于连接表或视图。分组算子包括 Group 和 Having。Projection 是投影算子,一般是字段列表;在字段外包围标量函数则是 Scalar 算子,包围聚合函数就是 Aggregation 算子;OLAP 函数的开窗函数属于 Window 算子。还有复杂投影列就是子查询。Sort 算子对应 Order By 子句。Top N 算子对应 Limit Offset 等关键字。将结果输出给客户端是 Output 算子。
另外,Value 算子是作用于非投影列的标量函数。比如在 where join 条件中包围字段的标量函数。
最后,介绍 Exchage 算子,负责分布式执行计划,执行过程各个节点数据交换。
(三)WHERE 子句中的操作符
1、操作符一览:
| 类别 | 操作符 |
|---|---|
| 圆括号 | ( ) |
| 比较 | =, >, >=, <, <=, !=, <>, <=> |
| 范围 | BETWEEN…AND…, NOT BETWEEN…AND… |
| 集合 | IN, NOT IN |
| 空的判断 | IS NULL, IS NOT NULL |
| 字符匹配 | LIKE, NOT LIKE |
| 逻辑运算 | NOT (!),AND (&&), OR |
| 正则匹配 | RLIKE、REGEXP |
| BINARY | 在字符串前使用之,可区分大小写进行参数值的比较 |
正则匹配操作符和正则函数区别在于调用方式:函数参数放在函数名后面的圆括号中,正则匹配操作符的参数放在其右边,下面“正则匹配操作符”小节中将举例说明。
2、NULL
(1) 首先了解 WHERE 子句中 NULL 的基本用法:
【e.g.01】:查询学生表缺少生日信息的学生编号。
SELECT * FROM Student WHERE sage IS NULL OR sage='';
# 注意字段空的判断要用 “IS” 操作符,不能用 “=”
(2) 概念深入解析:
NULL 表示“没有数据”,值未知,值不确定,unkown,不占空间。NULL数据导出数据默认为 \N;
- NULL 是关键字,其拼写大小写无关;
- NULL 不同于数字类型的 0 字符串类型的空字符串。在进行hash分布时,NULL值的数据会分布到同一个节点上。
- 进行 NULL 判断,可使用 IS NULL、IS NOT NULL操作符以及 IFNULL、NVL 等函数。
- 聚合函数,COUNT、MIN和SUM,将忽略NULL值。
【e.g.02】:如果一个字段中含有null值,count(*) 和 count(该字段)的结果是不一样的!
select count(*), count(sage) from Student;
/* 结果:
+----------+--------------+
| count(*) | count(sage) |
+----------+--------------+
| 11 | 10 |
+----------+--------------+
*/
(3) 安全等于操作符 <=>
在SQL标准中, null和任何值都不相等,包括null自己。在GBase 8a中,可以通过安全等于操作符对null也可以进行相等判断。一般用于表关联查询场景。
<=> 类似 “=” 操作符。但在以下两种情况下,获得的结果与 “=” 不同:
- 如果所有的操作数是NULL,那么返回的是1 而不是NULL。
- 如果有且只有一个操作数是NULL,那么返回的是0 而不是NULL。
SELECT 1 = 1, NULL = NULL, 1 = NULL;
/* 没有使用安全等于操作符,发生错误时返回 [NULL]
+---------+---------------+-------------+
| 1 = 1 | NULL = NULL | 1 = NULL |
+---------+---------------+-------------+
| 1 | [NULL] | [NULL] |
+---------+---------------+-------------+
*/
SELECT 1 <=> 1, NULL <=> NULL, 1 <=> NULL;
/* 使用安全等于操作符
+---------+---------------+-------------+
| 1 <=> 1 | NULL <=> NULL | 1 <=> NULL |
+---------+---------------+-------------+
| 1 | 1 | 0 |
+---------+---------------+-------------+
*/
以下例子说明了表关联中使用安全等于操作符的必要性:
select * from testnull1;
/*
+------+-------+
| id | name |
+------+-------+
| 1 | First |
| 2 | NULL |
+------+-------+
*/
select * from testnull2;
/*
+-------+
| name |
+-------+
| NULL |
| First |
+-------+
*/
select a.* from testnull1 a inner join testnull2 b on a.name <=> b.name;
# 如果不使用安全等于操作符,则 a.name 为 NULL 和 b.name 为 NULL 对应的行数据就不会被匹配到
3、BINARY 操作符
# 大小写不敏感比较(假设数据库字符集不敏感)
select 'GBase'='GBASE';
结果:1
# 敏感比较,无论数据库字符集是否为敏感,以下执行结果不会变的
select binary 'GBase'='GBASE';
结果:0
4、正则匹配操作符
- 示例:
# 单个字符匹配(只要存在XYZ任意一个字母即为匹配;执行结果:1)
SELECT 'aXbc' REGEXP '[XYZ]';
# 范围(只要a到d或者A到Z的字母出现一次以上,即为匹配)
SELECT 'aXbc' REGEXP '^[a-dA-Z]+$';
# 取非(除了abcdXYZ之外的字母出现一次以上即为匹配)
SELECT 'gheis' REGEXP '^[^a-dXYZ]+$';
# 匹配特殊字符
SELECT '1+2' REGEXP '1\\+2';
# 匹配单词
SELECT 'fofo' REGEXP '^f.*$';
# 在 information_schema 系统库中执行
SELECT DISTINCT ROW_FORMAT FROM information_schema.tables
WHERE CREATE_TIME is not null AND
ROW_FORMAT REGEXP '.*ed' = 1
/*
ROW_FORMAT
---------------------
Fixed
Compressed
*/
(四)分组聚合 GROUP BY
1、 常用聚合函数:
| 聚合函数 | 描 述 |
|---|---|
| COUNT(*) | 计算所有行的个数 |
| COUNT(<列名>) | 计算一列中非NULL值的个数 |
| SUM(<列名>) | 计算一列值的总和,忽略 NULL |
| AVG(<列名>) | 计算一列值的平均值,忽略 NULL |
| MAX(<列名>) | 计算一列值中的最大值,忽略 NULL |
| MIN(<列名>) | 计算一列值中的最小值,忽略 NULL |
2、【e.g.01】:按课程号分组,求每门课程的选课人数
SELECT CId, COUNT(SId) FROM SCore GROUP BY CId ;
【e.g.02】:查询选修了2门以上课程的学生学号
SELECT SId, COUNT(distinct CId)
FROM Score
GROUP BY Sid
HAVING COUNT(*)>2 ORDER BY SId;
小贴士: group by子句有多列时,要将hash列放在最前面。这样可以避免哈希动态重分布带来的性能下降。
3、性能优化技巧
GROUP BY 替换 DISTINCT:
【原始】SELECT DISTINCT SName from student;
【优化】SELECT SName from student GROUP BY SName;
小贴士:对于百万级以上数据量,用 GROUP BY 替换 DISTINCT 性能提升明显。
4、WHERE 和 HAVING 的用法区别
WHERE 和 HAVING 子句中后面都可以跟条件表达式,但是区别是非常明显的:
(1) 应用的 SQL 类别不同
WHERE 可直接作用于select、update、delete 和 insert into table…select…from…where…)语句中。update、delete 和 insert 属于 DML,后文将会详细讲解。
HAVING 只能直接作用于select语句。
(2) 执行的顺序不同
WHERE 中的条件是在执行语句进行分组之前应用,筛选 FROM 数据集。
HAVING 中的过滤条件是在分组聚合之后起作用的。
(3) 子句中表达式的区别
WHERE 中不能出现聚合函数。
HAVING 子句可以用集合函数(sum、count、avg、max和min)。
(五)条件分支
DQL 中使用 CASE 表达式实现多条件组合判断。
1、两种语法格式
格式 1:
CASE columnName
WHEN [compare-value] THEN result
[WHEN [compare-value] THEN result …]
[ELSE result] END
格式 2:
CASE WHEN
[condition] THEN result
[WHEN [condition] THEN
result …]
[ELSE result] END
2、可以出现的位置:
CASE 表达式出现在 SELECT 中
SELECT Sname, Sage,
CASE Ssex
WHEN '男' THEN '帅哥'
WHEN '女' THEN '美女'
ELSE '不明'
END 昵称
FROM student;
CASE 表达式出现在 WHERE 中
SELECT * FROM student
WHERE
(CASE WHEN
YEAR(Sage)=1990 THEN 1 ELSE 0 END) = 1;
(六)连接查询
1、JOIN 的种类
(1) 内连接
将两张表连接在一起的条件称为连接谓词(Join Predicate)或连接条件,
内连接只返回两个表中与连接谓词匹配的行,不匹配的行不会被输出。
#【需求】:查询每个学生及其选修课程的情况
## SQL92 写法:
SELECT S.Sname, S.Sage, CId FROM Student S, SCore WHERE S.SId=SCore.SId;
## SQL99 写法一:
SELECT S.Sname, S.Sage, CId FROM Student S INNER JOIN SCore ON S.SId=SCore.SId;
## SQL99 写法二:
SELECT S.Sname, S.Sage, CId FROM Student S INNER JOIN SCore using(SID);
(2) 外连接
左外连接(Left Outer Join):保证左表的数据完整。
右外连接(Right Outer Join):保证右表的数据完整。
#【需求】:查询每个学生及其选修课程的情况(包括未选课学生)
#左外连接:
SELECT S.SId, S.Sname, S.Ssex, S.Sage, S.Sdept,
SC.CId, SC.GRADE FROM Student S LEFT OUTER JOIN Score SC
ON S.SId=SC.SId;
#右外连接:
SELECT S.SId, S.Sname, S.Ssex, S.Sage, S.Sdept,
SC.CId, SC.GRADE FROM Student S RIGHT OUTER JOIN Score SC
ON S.SId=SC.SId;
(3) 完全外连接(Full Outer Join):Inner Join、Left Join、Right Join 的结果的合集。
(4) 交叉连接(Cross Join):亦称笛卡尔积。仅在需要枚举多组维度值所有组合的场景下使用。
2、自关联:
【概念】内连接的一种用法, 本质是把一张表当成两张表来使用,用别名区分。
【示例】查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩
☆ score 表的数据(SId 学生编号;CId 课程标识号;SC 考试成绩)存储的是所有学生、所有科目的成绩 ==>
| SId | CId | SC |
|---|---|---|
| 01 | 01 | 81.0 |
| 01 | 02 | 90.0 |
| 01 | 03 | 99.0 |
| 02 | 01 | 70.0 |
| 02 | 02 | 60.0 |
| 02 | 03 | 80.0 |
| 03 | 01 | 80.0 |
| 03 | 02 | 80.0 |
| 03 | 03 | 80.0 |
| 04 | 01 | 50.0 |
| 04 | 02 | 30.0 |
| 04 | 03 | 20.0 |
| 05 | 01 | 76.0 |
| 05 | 02 | 87.0 |
| 06 | 01 | 31.0 |
| 06 | 03 | 34.0 |
| 07 | 02 | 89.0 |
| 07 | 03 | 98.0 |
select distinct A.cid 课程编号, A.sid 学生编号, A.sc 学生成绩
from score as A inner join score as B on A.sid = B.sid
and A.cid != B.cid
and A.sc = B.sc;
/* 执行结果
学生编号 课程编号 学生成绩
03 03 80.0
01 03 80.0
02 03 80.0
*/
3、Between Join
【概念】关联查询条件为一个区间范围。
【示例】显示分数和等级
grade 表是描述等级对应的分数区间范围,数据如下:
| min | max | grade |
|---|---|---|
| 70 | 79 | 中等 |
| 80 | 89 | 良好 |
| 90 | 100 | 优秀 |
| 0 | 59 | 不及格 |
| 60 | 79 | 及格 |
执行以下语句:
select S.SC 分数, G.grade 等级
from score S inner join grade G on S.SC between G.min and G.max;
结果为:
| 分数 | 等级 |
|---|---|
| 20.0 | 不及格 |
| 30.0 | 不及格 |
| 31.0 | 不及格 |
| 34.0 | 不及格 |
| 50.0 | 不及格 |
| 60.0 | 及格 |
| 70.0 | 及格 |
| 70.0 | 中等 |
| 76.0 | 及格 |
| 76.0 | 中等 |
| 80.0 | 良好 |
| 80.0 | 良好 |
| 80.0 | 良好 |
| 80.0 | 良好 |
| 81.0 | 良好 |
| 87.0 | 良好 |
| 89.0 | 良好 |
| 90.0 | 优秀 |
| 98.0 | 优秀 |
| 99.0 | 优秀 |
(七)Union 和 Union All
1、适用场景:如果两个或多个 SELECT 语句的结构相似,则可以用“Union”或“Union All”将其合并。
2、UNION 与 UNION ALL 的区别:
UNION :对两个结果集进行并集、去重操作;
Union All:对两个结果集进行并集操作,不去重,不排序;
小贴士:如果结果集没重复数据,建议使用Union All 代替UNION,性能更好。
3、保证各个select 集合的结果有相同个数的投影列,并且每列的大类型(字符、数字)是一样的。
(1) char 类型数据,会隐式转换成 varchar 类型。
(2) 小的数据类型向大的数据类型转换,如:INT -> BIGINT -> DECIMAL -> DOUBLE
(3) 若对应列名不相同,会将第一个 SELECT 结果的列名作为结果集的列名。
(八)子查询
1、概念:当一个查询是另一个查询的条件时,称之为子查询。
2、示例:
- 在相关子查询(correlated subquery)中,子查询涉及到父查询的数据列
SELECT * FROM student
WHERE EXISTS (SELECT 1 FROM score WHERE score.SId= student.SId);
- 在不相关子查询(non-correlated subquery)中,子查询不涉及到父查询的数据列
SELECT * from student
WHERE SId = ( SELECT StudentId FROM school limit 1);
3、DQL 中子查询可以出现的位置:SELECT、FROM、WHERE
(1) select (select …) as 别名 from table
第一种,在from前面的(select)子查询。这种子查询的结果只能是单行单列的,可以传递from后面表的参数进去,表示查询出来的每一行数据都是由这个查询当做一列的。
(2) select * from (select * …) table
第二种,在from后面,这种子查询会当做一个表来对待,可以有多行多列,行列没有强制要求,还可以与别的表连接查询,有一个强制要求,就是必须要写别名。不可以传递参数。
(3) select * from table where table.id = (select tab.id from tab.id)
第三种,在=,>,<,>=,<=,<>,!=关系运算符后面,这种子查询的结果只能是单行单列,与关系判断符前面的数据对比。可以传递参数。
4、子查询与性能提升
将子查询转化成表连接,在大数据量下可以明显缩短查询时间。数据库引擎能更方便地得到更优的执行计划,从而减少 SQL 语句的执行时间。
例如,如下子查询语句
SELECT S.Sid, S.Sname FROM student S
WHERE EXISTS (SELECT 1 FROM score WHERE score.SId= S.SId);
转化成连接查询,对于大数据量,性能将有明显提升
SELECT distinct S.Sid, S.Sname FROM student, score
WHERE S.SId= score.SId;
(九)综合练习
- 测试表结构和关联

1、【自关联实现纵向比较】查询" 01 “课程比” 02 "课程成绩高的学生的信息及课程分数。
select Student.Sname, T.class1, T.class2 from Student
INNER JOIN (
select t1.SId, class1, class2 from
(select SId, sc as class1 from score where CId = '01')as t1,
(select SId, sc as class2 from score where CId = '02')as t2
where t1.SId = t2.SId AND t1.class1 > t2.class2
) T
on Student.SId = T.SId;
/*
Sname class1 class2
孙权 70.0 60.0
张辽 50.0 30.0
*/
2、 【自关联实现分组排序】按各科成绩进行排序,并显示排名,分数重复时保留名次空缺
select A.cid, A.sid, A.sc, count(B.sc)+1 as rank
from score A
left join score as B on A.sc < B.sc and A.cid = B.cid
group by A.cid, A.sid, A.sc
order by A.cid, rank ASC;
/* 结果(典型的数据行错位关联)
cid sid sc rank
01 01 81.0 1
01 03 80.0 2
01 05 76.0 3
01 02 70.0 4
01 04 50.0 5
01 06 31.0 6
02 01 90.0 1
02 07 89.0 2
02 05 87.0 3
02 03 80.0 4
02 02 60.0 5
02 04 30.0 6
03 01 99.0 1
03 07 98.0 2
03 02 80.0 3
03 03 80.0 3
03 06 34.0 5
03 04 20.0 6
*/
3、【聚合条件中使用子查询】查询没有学全所有课程的学生信息。
select * from student
where sid not in (
select sid from score
group by sid
having count(cid)= (select count(cid) from course)
);
/* 子查询得到的是所有课程都有成绩的学生编号
SId Sname
05 貂蝉
06 小乔
07 大乔
09 关羽
10 周瑜
11 张飞
12 陆逊
100 张三
101 李四
103 103
*/
4、 【聚合条件中使用子查询】查询和" 01 "号学生考试的课程完全相同的其他同学的信息
SELECT SId, Sname from student where SId in
(
select t2.SID from
(select SID, CId from score where Sid='01')T1, # 01 号学生
(SELECT SID, CId from score SC WHERE sid!='01')T2 # 其他同学
where T1.CId=T2.CId
GROUP BY t2.SID
having count(t2.CId)=(select count(1) from score where Sid='01')
)
/* 结果
SId Sname
02 孙权
03 曹操
04 张辽
*/
5、【数据转置——行转列】将 score 数据转成一名学生占一条数据,同时列出其所有学科成绩
select S.SId, S.Sname,
sum(CASE WHEN CId = '01' THEN SC else 0 END) 语文,
sum(CASE WHEN CId = '02' THEN SC else 0 END) 数学,
sum(CASE WHEN CId = '03' THEN SC else 0 END) 英语
FROM score inner join student S on S.SId = score.SId
group by S.SId, S.Sname
/*
SId Sname 语文 数学 英语
03 曹操 80.0 80.0 80.0
06 小乔 31.0 0.0 34.0
01 刘备 81.0 90.0 99.0
02 孙权 70.0 60.0 80.0
05 貂蝉 76.0 87.0 0.0
04 张辽 50.0 30.0 20.0
07 大乔 0.0 89.0 98.0
*/
为了给 No.6 的示例提供数据,我们执行以下 SQL,将以上结果存入新表 score_horizontal中:
set global gcluster_extend_ident=1; # 开启列名的中文支持
CREATE TABLE "score_horizontal" as
select S.SId, S.Sname,
sum(CASE WHEN CId = '01' THEN SC else 0 END) "语文",
sum(CASE WHEN CId = '02' THEN SC else 0 END) "数学",
sum(CASE WHEN CId = '03' THEN SC else 0 END) "英语"
FROM score inner join student S on S.SId = score.SId
group by S.SId, S.Sname
6、【数据转置——列转行】 score_horizontal 的数据转成一个科目占一条数据
select SId, Sname, '语文' as 学科, 语文 as 分数 from score_horizontal
union all
select SId, Sname, '数学' as 学科, 数学 as 分数 from score_horizontal
union all
select SId, Sname, '英语' as 学科, 英语 as 分数 from score_horizontal;
/* 结果(将 score_horizontal 表中的数据列转行)
SId Sname 学科 分数
03 曹操 语文 80.0
06 小乔 语文 31.0
03 曹操 数学 80.0
06 小乔 数学 0.0
03 曹操 英语 80.0
06 小乔 英语 34.0
01 刘备 语文 81.0
02 孙权 语文 70.0
01 刘备 数学 90.0
02 孙权 数学 60.0
01 刘备 英语 99.0
02 孙权 英语 80.0
05 貂蝉 语文 76.0
05 貂蝉 数学 87.0
05 貂蝉 英语 0.0
04 张辽 语文 50.0
07 大乔 语文 0.0
04 张辽 数学 30.0
07 大乔 数学 89.0
04 张辽 英语 20.0
07 大乔 英语 98.0
*/
(十)CTE(公共表表达式)
1、概念:CTE 使用 WITH AS 短语定义一个SQL片断(with子查询),执行结果存储在临时表中,可以被当前 SQL 语句其他部分重复调用,以提升查询性能,其生命周期仅仅限于当前上下文。一旦CTE被创建,你可以将它当成视图,大部分基于视图的操作都可以运用于CTE。
2、语法:
WITH
CTE1 AS (SELECT语句),
CTE2 AS (SELECT语句),
...
CTEn AS (SELECT语句)
SELECT * FROM CTE1, CTE2 WHERE CTE1.col = CTE2.col;
CTE1, CTE2…CTEn 是 CTE 别名,WITH 块中可以包含多个 CTE。注意,“CTEn AS (SELECT语句)”后面不能有逗号,因为 WITH 块和 SELECT 块是一个整体。
3、示例:
set _t_gcluster_support_cte = 1; # 开启集群的 CTE 支持,这是 Session 参数,需要在 with...as 语句之前执行
WITH cte1 AS (SELECT 'This DBMS ' as 'txt' from dual),
cte2 AS (SELECT CONCAT(cte1.txt,'is ')'txt' FROM cte1),
cte3 AS (SELECT 'GBase 8a MPP Cluster' as 'txt' from dual UNION
SELECT 'GBase 8s' as 'txt' from dual UNION
SELECT 'GBase 8c' as 'txt' from dual),
cte4 AS (SELECT concat(cte2.txt, cte3.txt) as 'txt' FROM cte2, cte3)
SELECT txt FROM cte4;
以上 WITH 块中,cte4 引用了 cte2 和 cte3,cte2 引用 cte1。最后 SELECT 块调用 cte4 输出最后的结果。
(十一)分层查询(Hierarchical Query)
如果一张表中存储着分层(树状)数据,那么你就可以使用分层查询语句以分层(树状)顺序来进行查询。
1、语法架构:

– START WITH 后面的condition标识分层查询的所有根行,START WITH子句可以省略。
– CONNECT BY 后面的condition标识父行和子行之间的连接条件;condition中的表达式中需要通过PRIOR 指定该表达式涉及的列出自父行还是子行。
– PRIOR 为一元操作符,仅用于 CONNECT BY 后面的condition,用于标识紧接在后面的表达式中涉及的列出自父行。
– 分层查询通过CONNECT BY进行递归,若探测到cycle,GBase 8a默认会报错退出;若用户指定NOCYCLE,GBase 8a会返回发生cycle之前的已查询记录。
– LEVEL:伪列,由GBase 8a自动维护;用于标识分层查询结果所在层级,从1开始。
– 允许分级查询做子查询。
2、示例
数据准备:
DROP TABLE IF EXISTS hq;
CREATE TABLE hq
(parentID int, ID int, dep varchar(10), leader varchar(20), cdt datetime) REPLICATED;
INSERT INTO hq VALUES (0,1,'总裁办','刘备', now());
INSERT INTO hq VALUES (1,2,'第一事业部','诸葛亮', now());
INSERT INTO hq VALUES (1,3,'第二事业部','关羽', now());
INSERT INTO hq VALUES (1,4,'第三事业部','张飞', now());
INSERT INTO hq VALUES (4,5,'市场组','周仓', now());
INSERT INTO hq VALUES (3,6,'行政','关平', now());
SELECT *, level FROM hq CONNECT BY PRIOR ID = parentID START WITH parentID = 0
执行结果:
| parentID | ID | dep | leader | cdt | level |
|---|---|---|---|---|---|
| 0 | 1 | 总裁办 | 刘备 | 2021-02-03 15:48:33 | 1 |
| 1 | 2 | 第一事业部 | 诸葛亮 | 2021-02-03 15:48:33 | 2 |
| 1 | 3 | 第二事业部 | 关羽 | 2021-02-03 15:48:33 | 2 |
| 3 | 6 | 行政 | 关平 | 2021-02-03 15:48:33 | 3 |
| 1 | 4 | 第三事业部 | 张飞 | 2021-02-03 15:48:33 | 2 |
| 4 | 5 | 市场组 | 周仓 | 2021-02-03 15:48:33 | 3 |
(十二)分区表查询
1、概念:
分区有利于管理非常大的表,根据一定的规则,数据库把一个表分解成多个小表。逻辑上只有一个表或一套索引,实际上这个表由多个物理分区对象组成,每个分区都是一个独立的对象。分区对应用来讲是完全透明的,不影响应用的业务逻辑。
2、数据分区的场景
超大表数据无法全部都放在内存中,只在表的最后部分有热点数据,其他均为历史数据。分区表的数据更加容易维护。例如,想批量删除大量数据可以使用清除整个分区的方式。还可以对一个独立分区进行优化、检查、修复等操作。分区表的数据可以分布在不同的物理设备上,从而高效地利用多个硬件设备。
便于备份和恢复独立的分区,这在体量非常大的数据集场景下效果极好。
3、分区类型
- RANGE分区:基于连续的区间范围,把数据分配到不同区。仅支持整数分区。
- LIST分区:类似RANGE分区,区别是LIST分区基于给出的枚举的值进行分区,无需按照顺序。只支持整数分区。
- HASH分区:给定分区个数,按照一个散列函数,确定数据进入哪个分区。仅支持整数类型(int, tinyint, bigint)分区!
- KEY分区,类似HASH分区,支持除text和BLOB之外的所有数据类型。
4、分区表查询
---- 准备测试数据
DROP TABLE if EXISTS FenQu;
CREATE TABLE FenQu (
`ftime` datetime NOT NULL,
`val` int(11) DEFAULT NULL,
PRIMARY KEY ("ftime")
)
PARTITION BY RANGE(YEAR(ftime))# PARTITIONs 4
(PARTITION p_2017 VALUES LESS THAN (2017),
PARTITION p_2018 VALUES LESS THAN (2018),
PARTITION P_2019 VALUES LESS THAN (2019),
PARTITION p_others VALUES LESS THAN MAXVALUE);
INSERT INTO FenQu VALUES ('2017-5-1',1), ('2020-4-1',2), ('2018-1-1',3), ('2019-1-1',4), ('2016-1-1',5), ('2021-1-1',6);
---- 执行分区表查询语句
select * from FenQu PARTITION(p_2017);
/*
ftime val
2016-01-01 00:00:00 5
*/
select * from FenQu PARTITION(p_2018);
/*
ftime val
2017-05-01 00:00:00 1
*/
select * from FenQu PARTITION(p_2019);
/*
ftime val
2018-01-01 00:00:00 3
*/
select * from FenQu PARTITION(p_others)
/*
ftime val
2020-04-01 00:00:00 2
2021-01-01 00:00:00 6
*/
(十三)DQL 编写注意事项
1、避免使用select *,明确真正使用的投影列
2、数据量大时,group by 、order by会很耗时,hash分布列最好写在第一个位置上
3、使用where条件提前过滤数据,减少join的运算
4、避免子表嵌套,若必须嵌套则层数应尽量少。
5、在做多表查询时应注意字段名称的唯一性;如果不唯一,则要明确写明表名。
6、内连接比外连接效率要高, 连接查询所使用的字段最好是hash分布键。
7、注意笛卡尔积的问题:
关注 $GBASE_BASE/tmpdata/cache_gbase/HashJoin 空间变化,如果出现2-10G增长,则表示可能出现笛卡尔积
四、DDL 进阶
(一)DDL 的基本概念:
DDL(Data Definition Language) 是数据库定义语言,用于定义和管理数据库中的所有对象的SQL语言。DDL 操作的主要数据库对象有:DATABASE(数据库)、TABLE(表)、VIEW(视图)、INDEX(索引)等。
| 数据库对象 | 支持的 DDL 操作 |
|---|---|
| DATABASE(数据库) | CREATE、DROP |
| TABLE(表) | CREATE、ALTER、DROP、TRUNCATE |
| VIEW(视图) | CREATE、ALTER、DROP |
| INDEX(索引) | CREATE、ALTER、DROP |
(二)DDL 的执行逻辑
DDL操作影响数据库对象的元数据信息。一条DDL命令传 gcluster 给发起节点,发起节点解析 SQL 语句后,将 SQL 语句下发给其他 gcluster 节点和 gnode 节点,各节点更新元数据、更新系统表,将结果回报给发起节点。最后,发起节点输出结果给 Client。整个过程如下图所示:

(三)数据库对象
1、数据库(DATABASE)
(1) 概念:
数据库按照一定的数据结构来组织、存储和管理数据的仓库。数据库包括表、视图、索引、存储过程、存储函数等。一个数据库实例中,可以有一个或多个数据库。
(2) 物理存储结构:
$GBASE_BASE\userdata\gbase\ 存放所有系统和用户自定义的 database 对应的目录名称。每个数据库目录包括 metadata(元数据)和 sys_tablespace(默认表空间)子目录。
(3) DATABASE 相关操作
# 创建数据库
CREATE DATABASE [IF NOT EXISTS] database_name;
# 删除数据库
DROP DATABASE [IF EXISTS] database_name;
# 选定用户数据库
use database_name;
# 显示所有数据库名称
show databases;
# 显示当前数据库的名称
select database();
2、表(TABLE)
(1) 概念:
表是关系型数据库中储存数据的基本架构。GBase 8a 采用列式存储、列式压缩、智能索引等特有技术对数据进行存储和计算,不涉及B-tree索引、水平分区、表空间等内容,具体包括复制表、随机分布表、哈希分布表、临时表和nocopies表五种存储策略。通过合理选择存储策略,可以充分发挥分布式数据库快速存储、计算数据的优势。
(2) 哈希分布表:
将表中某列指定为哈希分布列,然后将数据按照哈希算法的取值存储到不同的节点上。每个节点上只存储一部分数据。这种存储策略,将大表数据进行分拆,实现分布式存储,是大型数据中心最常用的数据分布方式。
create table MyTab (userID varchar(32), userName varchar(20)) DISTRIBUTED BY ('userID')
# MyTab 这张表在创建时使用 “DISTRIBUTED BY” 指定了哈希分布列 userID,则该表即为哈希分布表
# 一张表可以有多个hash分布列。比如 CREATE TABLE ... DISTRIBUTED BY ('userID', 'userName')
★ HASH分布列选取规则:
- 尽量选择count(distinct)值大的列做Hash分布列,让数据均匀分布。
- 优先考虑大表间的JOIN,尽量让大表JOIN条件的列为Hash分布列(相关子查询的相关JOIN也可以参考此原则),以使得大表间的JOIN可以直接分布式执行。
- 其次考虑GROUP BY,尽量让GROUPBY带有Hash分布列,让分组聚合一步完成。
- 通常是等值查询的列,并且使用的频率很高的应考虑建立为hash分布列。
- 选择某数据列随机性很大的字段,避免部分节点的热查询。
★ 注意事项:
- hash分布列只能为 varchar、int、tinyint、smallint、bigint、DECIMAL 类型。
- hash分布列不能被 update。
- hash分布列不允许设置default 值。
- 尽量保持 hash join的等值关联列在类型定义上完全相同,如char和varchar类型进行关联,可能出现结果为空情况,原因是char型不足最大长度时用空格补齐,varchar则没有空格,如果关联则需要trim空格。
(3) 随机分布表
create table MyTab (userID varchar(32), userName varchar(20))
# MyTab 不存在 hash 列,是随机分布表
将数据随机存储到不同的节点上,每个节点只存储一部分数据,各个节点上的数据量接近。如果事实表中没有主外键、每列值重复值均较多,也没有跟多表关联的列,而且表数据量比较大,无法进行哈希列选择的事实表,可以选
择随机分布表。
(4) 复制表
create table MyTab (userID varchar(32), userName varchar(20)) REPLICATED
# REPLICATED 关键字表示 MyTab 是复制表
复制表在集群的每个节点都保存一份全量数据,再与其它表进行关联查询时可以直接在本节点上完成,无需与其它节点进行交互,因此性能最优。但由于各个节点上数据完全相同,导致存储空间增加。一般数据量初始化后比较固定,数据量相对大表比较小(比如百万条记录以下级别的)的表,可以创建为复制表:常见的有编码表、维表等。
复制表表名尾部不允许是 _n{number编号,例如 mytable_n1,mytable_n12是不允许使用的,因为GBase集群的分布表在gnode的层以n{number]的表名进行数据的存储和管理:如果复制表以n{number}的形式命名,就有可能造成gnode层的表冲突和混乱。
(5) 临时表
create TEMPORARY table MyTab (userID varchar(32), userName varchar(20))
# 临时表创建时需要使用TEMPORARY 关键字
一般只需要保留会话中间结果集的数据表,可以创建为临时表。比如执行存储过程,查询中间结果集,执行完成存储过程之后,新开会话,临时表失效。
临时表是会话级的,会话断开会自动删除,因此如果需要保留中间表数据,不要创建为临时表。
(6) nocopies 表
create TEMPORARY table MyTab(userID varchar(32), userName varchar(20)) nocopies
nocopies 表使用场景不多,一般用于暂存大量数据的临时表。
(7) 表的其他操作语句
① 表的复制
- 仅表结构的复制
CREATE TABLE s00 LIKE student;
# 该语句生成和 student 表同构的 s00 表。如果 student 是哈希分布表或者复制表,s00 也是哈希分布表或者复制表,即存储策略也被复制了。
- 同时复制表结构和数据
CREATE TABLE student_bak select * from student;
# 该语句生成和 student 表同构的 student_bak 表,并且 student 表全部数据都拷贝到 student 中了。但是,源表的存储策略不会被复制,student_bak 目前是随机分布表。新表的存储策略需要特殊指定的,比如:
CREATE TABLE student_bak REPLICATED select * from student;
# student_bak 就是一张复制表。再如:
CREATE TABLE student_bak DISTRIBUTED BY ('SId') select * from student;
# student_bak 就是一张哈希分布表。
② 修改表
【语法】
ALTER TABLE <表名> [ ADD [COLUMN] (新列定义,…) ] [ CHANGE ( <旧列名> <新列名> <列类型> ,… ) ]
| MODIFY [COLUMN] col_name column_definition [FIRST | AFTER col_name ] |
[DROP [COLUMN] ( <列名> ,… ) ] | RENAME [TO] <新表名> | SHRINK SPACE |ALTER [列名] COMPRESS (值)|;
【解释】
ADD [COLUMN] (新列定义,…):增加新列。
CHANGE ( <旧列名> <新列名> <列类型> ,… ) :修改列名称。不支持修改column_definition(列定义)。
MODIFY [COLUMN] col_name column_definition [FIRST | AFTER col_name] :修改表中存在列的位置。不支持修改 column_definition(列定义)。
DROP [COLUMN] ( <列名> ,… ):删除表中存在的列。
RENAME [TO] <新表名>:修改表名称。
SHRINK SPACE :释放被删除的数据文件所占的磁盘空间。
ALTER [列名] COMPRESS [值]:修改表或列的压缩方式。
【示例】
ALTER TABLE T ADD column c varchar(10) null; # 新增一列,列名为c
ALTER TABLE T CHANGE c1 c2 varchar(10); # 修改c列的名字为d
ALTER TABLE T MODIFY c varchar(10) FIRST; # 修改c列位置为第一个
ALTER TABLE T MODIFY b varchar(10) AFTER c; # 修改b列字段位置在c列后面
ALTER TABLE T MODIFY c varchar(100); # 修改c列的varchar最大长度到100。注意:不能修改字段类型!即使将 varchar 修改为 char 可是不可以的。
ALTER TABLE T DROP column c; # 删除c列
ALTER TABLE T1 RENAME T2; # 修改表T1的名字为T2
ALTER TABLE T ALTER COMPRESS(5,5); -- 修改T表压缩模式为55压缩
/*
压缩模式保存在DC块结构中,压缩模式改变只对后续入库的数据有效;
数值型(含日期型)数据压缩选项 0、1、5;字符型数据压缩选项 0、3、5
表的压缩类型可遵循(数值型,字符型)组合:(0, 0)、(1, 3)、(5, 5)...
(5,5)、(3,1)两种算法最常用。
(5,5)是轻量级压缩算法,压缩比一般可以达到3:1或4:1左右。有助于提高查询性能。
(3,1)是重量级压缩算法,压缩比一般可以达到10:1至20:1左右。但是数据库的查询性能不高。
建议:如项目无特殊压缩要求,一律使用(5,5)压缩算法。
*/
表修改操作的限制:
A. 不支持改变列的数据类型、列的属性(NOT NULL,默认值)、字符集;
B. varchar 类型可改变列的长度,只能变大,不能变小。
③ 重命名表
RENAME TABLE T1 TO T2;
ALTER TABLE T1 RENAME T2;
# 以上两个语句效果完全相同
④ 清空表
TRUNCATE TABLE T; # 删除表中所有行数据,但表结构及其列、约束、索引等保持不变。
⑤ 删除表
DROP TABLE T; #
TRUNCATE 比 DELETE 效率高,还能释放物理空间;
DROP TABLE 移除表的数据和表定义,生产环境慎用此命令!
3、视图(VIEW)
(1) 基本概念:
视图是由 SELECT 查询语句定义的虚拟表。视图和表不同,表有实际储存数据,而视图是逻辑表,本身不实际储存数据。对视图的查询操作和实体表相同。视图不支持 INSERT、UPDATE 和 DELETE 操作。
(2) 使用场景:
第一点:使用视图,可以定制用户数据,聚焦特定的数据。
在实际过程中,公司有不同角色的工作人员,我们以销售公司为例的话,采购人员,可以需要一些与其有关的数据,而与他无关的数据,对他没有任何意义,我们可以根据这一实际情况,专门为采购人员创建一个视图,以后他在查询数据时,只需select * from view 就可以了。
第二点:使用视图,可以简化数据操作。
我们在使用查询时,在很多时候我们要使用聚合函数,同时还要显示其它字段的信息,可能还会需要关联到其它表,这时写的语句可能会很长,如果这个动作频繁发生的话,我们可以创建视图,这以后,我们只需要select * from view 就可以了。
第三点:使用视图,基表中的数据就有了一定的安全性。
因为视图是虚拟的,物理上是不存在的,只是存储了数据的集合,我们可以将基表中重要的字段信息,可以不通过视图给用户,视图是动态的数据的集合,数据是随着基表的更新而更新。同时,用户对视图,不可以随意的更改和删除,可以保证数据的安全性。
第四点:可以合并分离的数据,创建分区视图。
随着社会的发展,公司的业务量的不断的扩大,一个大公司,下属都设有很多的分公司,为了管理方便,我们需要统一表的结构,定期查看各公司业务情况,而分别看各个公司的数据很不方便,没有很好的可比性,如果将这些数据合并为一个表格里,就方便多了,这时我们就可以使用union关键字,将各分公司的数据合并为一个视图。
(3) 视图相关的操作语句
# 创建视图 vStu,引用 student 表的 SId, Sname, Ssex 字段数据
CREATE OR REPLACE VIEW vStu AS SELECT SId, Sname, Ssex FROM student;
# 修改视图 v_t 引用的数据
ALTER VIEW vStu AS SELECT SId, SC FROM score;
show tables from courseware like 'v%'; # 显示数据库 courseware 中以v字母开头的表和视图
desc vStu; # 查看视图 vStu 的字段信息
Show create view vStu; # 查看视图 vStu 的创建语句
DROP VIEW if exists vStu; # 如果视图 v_t 存在则删除
4、索引(INDEX)
数据库索引是为了提升查询定位效率而对表字段附加的一种标识,避免全表扫描。
GBase 8a 的索引文件存储在 $GBASE_BASE/userdata/gbase/<数据库名称>/metadata 目录下。
(1) 智能索引:
所有列都有的粗粒度索引,自动创建,对用户透明,免维护。
(2) 哈希索引(HASH INDEX):
提升等值查询的性能,需用户根据查询列手动创建。
同一表上不能创建相同名称的哈希索引,一张表的同一列上能且只能创建一个哈希索引,而且不支持联合索引。哈希索引支持的数据类型:除了 BLOB 和 TEXT 之外的所有类型。
HASH INDEX 存诸的是由索引列值经过 HASH 计算后的键值与对应的物理存储地址,
所以创建 HASH INDEX 后,基于索引列的等值查询(“=”,“IN"和”<>”)的性能会提高,尤其是表中的数据量非常大的情况。在小数据量的情况下,HASH INDEX 对性能的提升效果不明显。
哈希索引的使用限制:
A 索引是一种有损的优化手段,使用索引通常会带来维护的成本,会影响数据加载及写操作的性能,实际使用时需根据具体需求而定。
B 选择建立哈希索引的列应尽量选择重复值较少的列,否则哈希冲突严重,影响哈希索引的性能。
C 二进制类型的列不适合使用哈希索引。
D 针对范围查询(<,>,between and)、模糊查询(like)、排序(order by)等SQL 操作,创建哈希并不能提升性能。
常用索引操作示例:
create index idxSId on student (SId) using hash global; # 基于列的全部数据建立索引
show index from student; # 查看已创建的索引
alter table student drop index idxsid; # 删除已创建的索引
五、DML 进阶
(一)基本概念
DML(Data Manipulation Language)语句:数据操纵语句。
用途:用于添加、修改、删除数据库记录,并检查数据完整性。
常用关键字:insert、update、delete等。
(二)INSERT
1、原理:从DC尾块新增数据,不影响已入库的数据。批量入库性能高于单条入库性能。
2、语法(两种形式):
(1) 插入元组的语法:
INSERT [INTO] [cluster_name.][database_name.]table_name [(col_name,…)] VALUES ({expr | DEFAULT},…),(…),…
INSERT INTO Student(ID,age) VALUES(1,9), (2,10), (3,9), (4,8), (5,12);
# 一对圆括号的数据就是一个元组
(2) 插入查询结果语法:
INSERT [INTO] [cluster_name.][database_name.]table_name [(col_name,…)]
SELECT … FROM [cluster_name.][database_name.]table_name;
3、综合示例:
统计每位学生的平均成绩,并把结果存入数据表。
(1) 复制 score_horizontal 为 score_stat:
create table score_stat like score_horizontal;
(2) 然后统计信息存入 score_stat 表中:
insert into score_stat( SId, Sname, 语文, 数学, 英语 )
SELECT S.SId, S.Sname,
sum(CASE WHEN CId = '01' THEN SC else 0 END) 语文,
sum(CASE WHEN CId = '02' THEN SC else 0 END) 数学,
sum(CASE WHEN CId = '03' THEN SC else 0 END) 英语
FROM score inner join student S on S.SId = score.SId
group by S.SId, S.Sname
(三)UPDATE
1、语法:
UPDATE [database_name.]table_name SET col1=expr1 [, col2=expr2 …]
[WHERE where_definition]
2、典型示例:
(1) 更新表达式中引入其他字段:
UPDATE Person SET Age = floor(DATEDIFF(NOW(), Birthday)/365)
WHERE name = '路人甲';
(2) 更新表达式中自引用:
UPDATE Person SET Age = Age+1;
(3) 更新值来自其他表:
UPDATE Score inner join Student on Student.Sid=Score.Sid
inner join Course on Course.CId=Score.Cid
SET Score.SC=81
WHERE Student.Sname='刘备' and Course.Cname='语文'
# 以上 SQL 要更新 Score 中的 SC(分数)字段,即更新刘备的语文成绩。但是 Score 中没有学生姓名和学科字段,所以需要关联 Student 和 Course 表。
3、注意事项:
(1) 不允许更新 HASH 列(DISTRIBUTED BY)的值:
# 比如创建如下分布表,哈希列是 Sid
CREATE TABLE student_test (Sid int, stu_name varchar(200),stu_sex int) DISTRIBUTED BY('Sid ');
# 试图更新 Sid
UPDATE student_test SET Sid = 4 WHERE Sid = 2;
就会报错——
ERROR 1722 (HY000): (GBA-02DD-0006) Can’t update distributed column ‘Sid’;
(2) 不要在更新表达式中使用子查询。
(3) 不要在 Where 子句中使用子查询。
以上(2)(3)提及的表达式结果是如果是多值,则会报错。Update 语句中出现子查询是比较糟糕的架构,对执行性能也是有影响的。一般可以替换为 inner join 的架构。
4、快速UPDATE模式:
等价于DELETE+INSERT,即先删除符合更新条件的数据,然后再向表的末尾插入需要更新的新数据。用以提高列存储数据更新操作效率问题。
更新少量数据时,建议使用快速 UPDATE 模式。
使用 SET gbase_fast_update =1 命令打开快速 UPDATE 模式,默认是关闭快速UPDATE模式。举例:
# 查看快速UPDATE模式是否开启
show variables like 'gbase_fast_update';
SET gbase_fast_update = 1; # 开启快速UPDATE模式
# 更新数据(年龄小于 20 岁的学生年龄自增 1)
UPDATE student SET sage = sage+1 WHERE sage < 20;
# 显示结果(快速UPDATE模式对用户是透明的)
select * from student ;
(四)DELETE
1、原理:只标记删除标志,不实际删除数据。须使用SHRINK SPACE释放磁盘空间。
2、语法:
DELETE [FROM] [database_name.]table_name [alias] [WHERE conditions];
3、典型示例
(1) 条件删除:
DELETE FROM Student WHERE Sid='01' ;
(2) 关联删除:获取没有报考任何课程的学生名单
DELETE student_copy S FROM student_copy S INNER JOIN score_copy C on S.Sid = C.Sid;
(3) 条件子句中的子查询:
DELETE FROM score_copy WHERE CId in ( SELECT CId FROM course_copy ); # 删除多条数据
(五)Merge Into
1、语法
merge INTO A USING B on( A.条件字段1 = B.条件字段1 and A.条件字段2 = B.条件字段2 )
when matched then update set A.更新字段 = B.字段
when not matched then insert into A(字段1,字段2……)values(值1,值2……)
【功能】
两张表的数据有条件合并。靶表 A 和源表 B 以条件字段比较,匹配则更新某字段,否则 A 中插入 B 的数据
【关键字说明】
INTO 子句:要更新或插入数据的目标表。
USING 子句:只读的数据源表或视图。
ON 子句:目标表和源表的关联条件,如果匹配(或存在),则更新,否则插入。
关联条件中不能出现表达式和函数!
UPDATE 部分和 INSERT 部分位置不可以颠倒!
注意:A.条件字段1 和 A.条件字段2 必须为哈希列
2、示例:
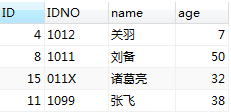
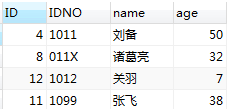
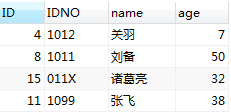
merge into M01 using M02 on M01.IDNO = M02.IDNO when matched then update set M01.age = M02.age when not matched then insert(M01.IDNO, M01.name, M01.age) values(M02.IDNO, M02.name, M02.age);
<<<<<< 执行前:
| M01 表 | M02 表 |
 |
 |
执行后 >>>>>>
| M01 表 | M02 表 |
|
 |