常用推荐系统评测指标
文章目录
- 基于评分准确度:
-
- 1. 平均绝对误差(MAE)
- 2. 均方根误差(RMSE)
- 基于预测准确度:
-
- 3. 准确率(Precision)
- 4. 召回率(Recall)
- 5. F指标(F-measure)
- 基于排序准确度
-
- 6. AUC
- 7. MAP
- 8. MRR
- 9. NDCG
- 其他指标
-
- 10. 覆盖率
- 11. 多样性
- 12. 惊喜度
- 13. 信任度
- 14. 实时性
- 15. 健壮性
- 参考资料
本文作为我学习推荐算法时的学习笔记,来总结一些推荐系统中的评测指标
通常推荐系统的评测方法有四种: 业务规则扫描、离线模拟测试、在线对比测试、用户调查。
本文主要介绍线下评测,线下评测是推荐系统最常使用的,通常有两种评测方式,一种是离线模拟评测,一种是使用用户历史真实访问数据进行评测。
(1)离线模拟评测是一种军事演习式的测试。模拟测试当然无法代替真实数据,但是也能暴露一些问题。通常做法是先收集业务数据,也就是根据业务场景特点,构造用户访问推荐接口的参数。这些参数要尽量还原当时场景,然后拿这些参数数据去实时访问推荐推荐,产生推荐结果日志,收集这些结果日志并计算评测指标,就是离线模拟测试。
显然,离线模拟评测是失真的测试,并且评测指标也有限,因为并不能得到用户真实及时的反馈。但是仍然有参考意义。这些模拟得到的日志可以统称为曝光日志,它可以评测一些非效果类指标,例如推荐覆盖率,推荐失效率,推荐多样性等。
(2)另外就是利用历史真实日志构造用户访问参数,得到带评测接口的结果日志后,结合对应的真实反馈,可以定性评测效果对比。比如,可以评测推荐结果的 TopK 的准确率,或者排序效果 AUC。这些模型效果类指标,虽然不能代表最终关注的商业指标,但是两者之间一般存在一定的相关性。通常来说 TopK 准确率高,或者 AUC 高于 0.5 越多,对应的商业指标就会越好,这是一个基本假设。通过离线模拟评测每一天的模型效果指标,同时计算当天真实的商业指标,可以绘制出两者之间的散点图,从而回归出一个简单的模型,用离线模型效果预估上线后真实商业指标。
线下评测的指标众多,各有各的作用,实际上这些指标都是 “探索-利用” 问题的侧面反映,它们解答了两个问题:
一是系统有多好,即推荐系统当前的性能如何,对数据利用得彻不彻底,这类指标我们称之为利用类指标;
二是系统还能好多久,即推荐系统长期的健康状况,是否能够探索出用户新的兴趣,这类指标我们称之为探索类指标。
基于评分准确度:
1. 平均绝对误差(MAE)
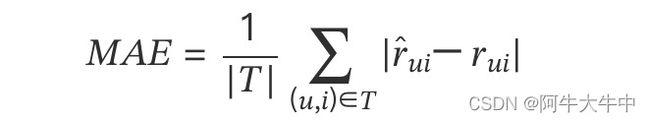
假设我们用一个列表records存放用户评分数据,令records[i] = [u, i, rui, pui],其中rui是用户u对物品i的实际评分,pui是算法预测出来的用户u对物品i的评分,那么下面的代码实现MAE的计算过程。
def MAE(records):
return sum([abs(rui-pui) for u,i,rui,pui in records])/float(len(records))
推荐算法的整体准确度是所有用户准确度(对所有物品的评估)的平均。研究表明,如果评分系统是基于整数建立的(即用户给的评分都是整数),那么对预测结果取整数会降低 MAE 的误差。
优点:
1)计算方法简单,易于理解;
2)每个系统的平均绝对误差唯一,从而能够区分两个系统平均绝对误差的差异。
缺点:
1)对 MAE 指标贡献比较大的往往是那种很难预测准确的低分商品。所以即便推荐系统 A 的 MAE 值低于系统 B,很可能只是由于系统 A 更擅长预测这部分低分商品的评分,即系统 A 比系统 B 能更好的区分用户非常讨厌和一般讨厌的商品,显然这样区分的意义不大。
2)在用户喜好偏差的程度比较小时也并不适用,因为用户只关心把好产品错归为坏产品,或者把坏产品错归为好产品的比例。例如,以 3、5 个星为界区分好坏,那么把 4 预测成了 5,或者把 3 预测成了 2 都对用户没有影响。
2. 均方根误差(RMSE)
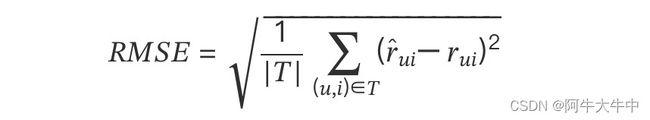
def RMSE(records):
return math.sqrt(sum([(rui-pui)*(rui-pui) for u,i,rui,pui in records])/float(len(records)))
它加大了对预测不准的用户物品评分的惩罚,对系统评测更加严格。
优点:
相比于 MAE,RMSE 加大了对预测不准的用户物品评分的惩罚(平方项的惩罚),因而对系统的评测更加苛刻。
缺点:
1)容易受到高频用户或高频物品的影响。RMSE 需要取一个平均值。这是对所有用户在所有物品上评分误差的估计的平均。那么,如果一个用户在数据集里面对很多物品进行了评分,这个用户误差的贡献就会在最后的平均值里占很大一部分。也就是说,最后的差值大部分都用于描述这些评分比较多的用户了。这个弊端会造成如果我们得到了一个比较好的 RMSE 数值,往往很可能是牺牲了大部分用户的评分结果,而对于少部分的高频用户的评分结果有提高。说得更加直白一些,那就是 RMSE 小的模型,并不代表整个推荐系统的质量得到了提高。
2)RMSE 指标并没有反应真实的应用场景。真实的应用场景,我们往往是从一大堆物品中,选择出一个物品,然后进行交互。在这样的流程下,物品单独的评分其实并不是最重要的。更进一步说,就算一个推荐系统能够比较准确地预测评分,也不能证明这个推荐系统能够在真实的场景中表现优异。
以上两种方法都是基于评分准确度的,评分准确度考虑推荐算法的预测打分与用户实际打分的相似程度,在评分类的显式用户反馈中,预测准确度非常重要。
基于预测准确度:
以下三种方法属于预测准确度评估,在行为预测准确度评估中,一般是对 TopN 推荐的准确度评估,这里的 N 和实际推荐系统场景有关,就是实际每次推荐系统需要输出几个结果。在 TopN 推荐中,设 () 为根据训练建立的模型在测试集上的推荐,() 为测试集上用户的选择。
3. 准确率(Precision)
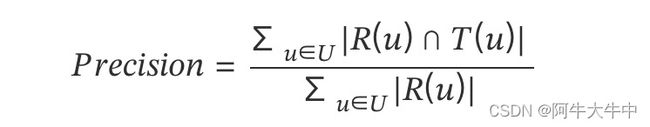
准确率就是:预测正确的/推荐列表的长度,定义为系统的推荐列表中用户喜欢的物品和所有被推荐物品的比率,也称为查准率,即在推荐(预测)的物品中,有多少是用户真正(准确)感兴趣的。
4. 召回率(Recall)
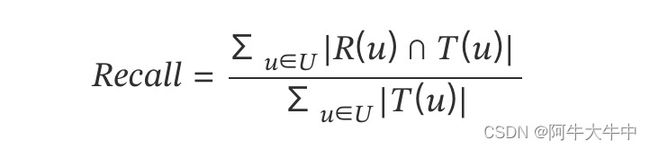
召回率就是:预测正确的/用户实际点击列表长度,召回率表示一个用户喜欢的物品被推荐的概率,也称为查全率,即用户喜欢(点击)的物品中,有多少是被推荐了的。
优点:
准确率和召回率对比评分准确度指标更能反应推荐系统在真实场景中的表现。
缺点:
1)未发生交互行为的物品很难确定用户是否真正喜欢。准确率和召回率的定义依赖于用户喜欢和不喜欢的物品分类 。如何定义用户是否喜欢一个物品,尤其是用户是否喜欢一个没有打分的物品还是十分困难的。在推荐系统中,无法知道用户是否喜欢某些未知的物品,所以召回率在纯粹意义上讲并不适合度量推荐系统。因为召回率需要知道每个用户对未选择物品的喜好,然而这与推荐系统的初衷是相悖的。
2)准确率和召回率必须要一起使用才能全面评价算法的好坏 。准确率和召回率是两个很相似的指标,这两个指标存在负相关的关系,他们分别从不同的角度来评价推荐系统,单独的指标不足以说明算法的好坏,必须一起使用才是更加全面的评价。
准确率和召回率的两种应用场景:以用户为中心和以系统为中心
准确率和召回率可以有两种计算方法:以用户为中心和以系统为中心
-
以用户为中心的方法中分别计算每个用户的准确率和召回率,再对所有的用户进行平均。这种方法的重点在于考虑用户的感受,保证每个用户对系统表现的贡献强度是一致的。
-
以系统为中心的方法以考察系统的总体表现为目的,不需要对所有用户做平均。
准确率和召回率存在负相关关联,取决于推荐列表的长度,互相牵制
1)当准确率很高的时候,表明希望推荐的物品绝大多数是用户感兴趣的,因此推荐较为保守,只推少量最有把握的物品,这样的话,有些用户可能感兴趣但排名没有那么靠前的物品则会被忽略。因此召回率就比较低。
2)如果召回率很高,表明目标是尽可能把用户感兴趣的物品全部召回,则门槛就会降低,为了捕获更多用户感兴趣的物品,召回的总量就多了,而准确率就低了。
在不同的应用场景中需要自己判断希望准确率比较高或是召回率比较高。比如系统的任务是发现所有用户喜欢的产品,召回率就变得很重要,因此需要在一定的召回率水平下考虑准确率。
这里有一个例子:
比如有一个训练集为(苹果,香蕉,橘子,草莓,哈密瓜,西红柿,黄瓜),用户选中其中几样,以此训练,
测试集为(梨子,菠萝,龙眼,黑莓,白菜,冬瓜)
根据用户在训练集上的行为:
给用户做出的推荐列表为R(u) =(梨子,菠萝,龙眼),用户在测试集上的实际行为列表T(u) =(梨子,黑莓,白菜,冬瓜)
那么R(u)和T(u)的交集为1,R(u)=3,T(u)=4,故准确率为1/3,召回率为1/4
5. F指标(F-measure)
F-Measure 是 Precision 和 Recall 加权调和平均:
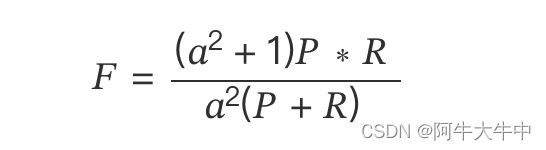
其中,P 为准确率,R 为召回率,当参数α=1 时,就是最常见的 F1,也即

F 指标把准确率和召回率统一到一个指标。
以上三种方法是基于分类准确度,分类准确度定义为推荐算法对一个物品用户是否喜欢判定正确的比例,通常用于行为预测。因此,当用户只有二元选择时,用分类准确度进行评价较为合适。
- 分类准确度在稀疏打分情况下的影响及调整:
应用于实际的离线数据时,分类准确度可能会受到打分稀疏性的影响。当评价一个推荐列表的质量时,列表中的某些物品很可能还没有被该用户打分,因此会给最终的评价结果带来偏差。需注意的是,这里的打分可以有不同的几种反馈类型,但一定是二元相关度的方式,比如可以是数值评分的二元化(如 MovieLens 数据为 5 分制 ,通常 3~5 分被认为是用户喜欢的,1~2 分被认为是用户不喜欢的。),可以是二元打分(喜欢和不喜欢),也可以是用户交互行为(有行为反馈和没有行为反馈)。
1)一个评价稀疏数据集的方法就是忽略还没有打分的物品,那么推荐算法的任务就变成了 “预测已经打分的物品中排名靠前的物品”。
2)另外一个解决数据稀疏性的方法就是假设存在默认打分,常常对还没有打分的物品打负分 。这个方法的缺点就是默认打分常常与实际的打分相去甚远。
3)还有一种方法是计算用户打分高的物品在推荐列表中出现的次数,即度量系统在多大程度上可以识别出用户十分喜欢的物品。这种方法的缺点是容易把推荐系统引向偏的方向:一些方法或者系统对某数据集中已知的数据表现非常好,但是对未知的数据表现十分差。
分类准确度评价并不直接评价算法的评分是否准确,如果分类的信息准确无误,与实际打分存在偏差也是允许的,对于分类准确率,我们更加在乎系统是否正确地预测用户是否会对某个物品产生行为。
基于排序准确度
排序是推荐系统非常重要的一个环节,因为把用户偏爱的物品放在前面是推荐系统的天职,因此检测推荐系统排序能力非常重要。
关于排序能力的评测指标,我们自然会想到搜索引擎中的排序指标,它们在某种程度是可以应用于推荐系统发的评测,但是会有些问题。由于推荐系统输出结果是非常个人化的,除了用户本人,其他人都很难替他回答哪个好哪个不好,而搜索引擎评价搜索结果和查询相关性,具有很强的客观属性,可以他人代替评价。所以通常评价推荐系统排序效果很少采用搜索引擎排序指标,比如 MAP、MRR、NDCG。推荐系统评价排序通常采用 AUC。
6. AUC
AUC(Area Under Curve)被定义为ROC曲线下与坐标轴围成的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。AUC越接近1.0,检测方法真实性越高;等于0.5时,则真实性最低,无应用价值。
ROC 全称是 “受试者工作特征”,(receiver operating characteristic)。我们根据学习器的预测结果进行排序,然后按此顺序逐个把样本作为正例进行预测,每次计算出两个重要的值,分别以这两个值作为横纵坐标作图,就得到了 ROC 曲线。ROC 曲线的横轴为 “假正例率”(False Positive Rate,FPR),又称为 “假阳率”;纵轴为 “真正例率”(True Positive Rate,TPR),又称为 “真阳率”,而 AUC(area under the curve)就是 ROC 曲线下方的面积,见下图:
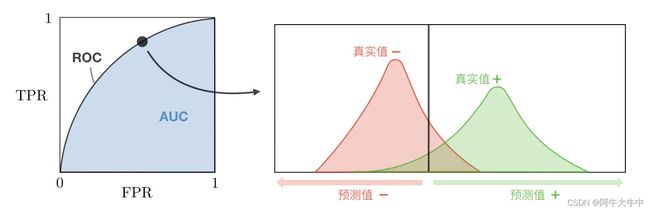
从上图可以看出,阈值最大时,对应坐标点为 (0,0), 阈值最小时,对应坐标点 (1,1),最理想的目标:TPR=1,FPR=0,即图中 (0,1) 点,故 ROC 曲线越靠拢 (0,1) 点,越偏离 45 度对角线越好,分类效果越好。
虽然,用 ROC 曲线来表示分类器的性能很直观很好用。但是人们更希望能有一个数值来表示分类器的好坏。于是 Area Under ROC Curve(AUC) 就出现了。
首先 AUC 值是一个概率值,当你随机挑选一个正样本以及负样本,当前的分类算法根据计算得到的 Score 值将这个正样本排在负样本前面的概率就是 AUC 值,AUC 值越大,当前分类算法越有可能将正样本排在负样本前面,从而能够更好地分类。
AUC 量化了 ROC 曲线表达的分类能力。这种分类能力是与概率、阈值紧密相关的,AUC 值越大,则说明分类能力越好,那么预测输出的概率越合理,因此排序的结果越合理。如此 AUC 这个值在数学上等价于:模型把关心的那一类样本排在其他样本前面的概率。最大是 1,完美结果,而 0.5 就是随机排列,0 就是完美地全部排错。
从AUC 判断分类器(预测模型)优劣的标准:
- AUC = 1,是完美分类器。
- AUC = [0.85, 0.95], 效果很好
- AUC = [0.7, 0.85], 效果一般
- AUC = [0.5, 0.7],效果较低,但用于预测股票已经很不错了
- AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
- AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
在 CTR 预估中,我们不仅希望分类器给出是否点击的分类信息,更需要分类器给出准确的概率值,作为排序的依据。所以,这里的 AUC 就直观地反映了 CTR 的准确性(也就是 CTR 的排序能力)。
7. MAP
MAP(Mean Average Precision):平均精度均值,单个主题的平均准确率是每篇相关文档检索出后的准确率的平均值。
首先定义排名为第 k 位的准确率 P@k(Precision at position k):
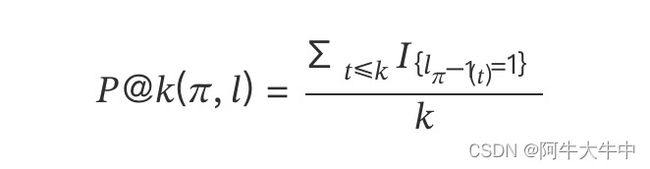
其中,k 表示排第 k 位的位置, 为整个排序列表, 为相应位置的相关性二元标签,值为 1(相关)或 0(不相关);{⋅} 是指示器,如果对应位置文档是相关的则是 1,不相关为 0;−1() 表示排序列表 中排名为第 的位置。
接下来定义平均准确率 AP(Average Precision):
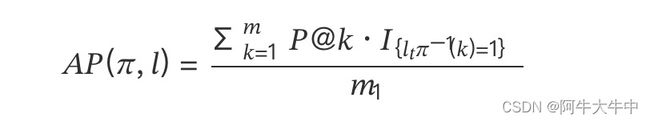
其中,m 是与查询关键字 q 关联的文档总数,1 是标签为 1 的文档数量。
测试集中所有查询关键字的 AP 求平均后就是 MAP(Mean Average Precision)。
Eg:
如下图表示某个查询关键字的检索出的网页排序列表,蓝色表示相关,白色表示不相关。
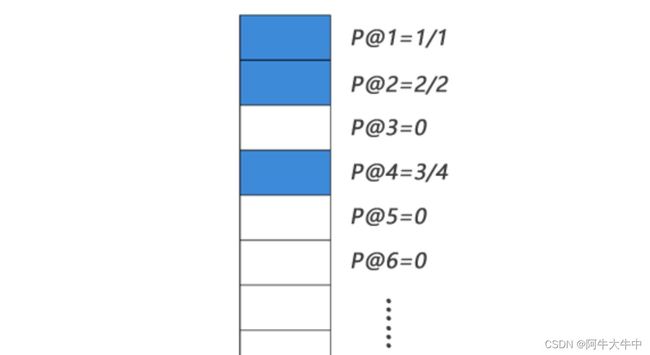
则:
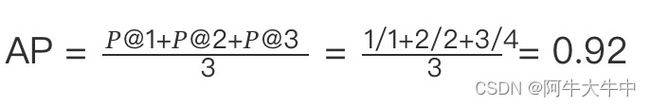
MAP 的衡量标准比较单一,q(query,搜索词) 与 d(doc,检索到的 doc) 的关系非 0 即 1,核心是利用 q 对应的相关的 d 出现的位置来进行排序算法准确性的评估。
8. MRR
MRR(Mean Reciprocal Rank):倒数排序法,把标准答案在被评价系统给出结果中的排序取倒数作为它的准确度,再对所有的问题取平均。
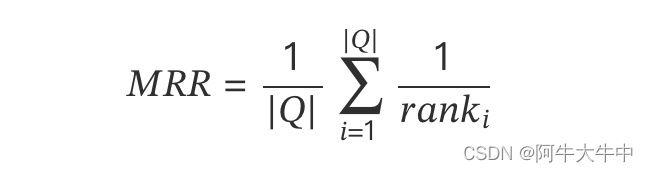
其中|Q|是查询个数, 是第 个查询,第一个相关的结果所在的排列位置。
这个是最简单的一个,因为他的评估假设是基于唯一的一个相关结果,比如 q1 的最相关是排在第 3 位,q2 的最相关是在第 4 位,那么 MRR=(1/3+1/4)/2,MRR 方法主要用于寻址类检索(Navigational Search)或问答类检索(Question Answering)
9. NDCG
NDCG(Normalized Discounted Cumulative Gain):直译为归一化折损累计增益,计算相对复杂。对于排在结束位置 n 处的 NDCG 的计算公式如下图所示:
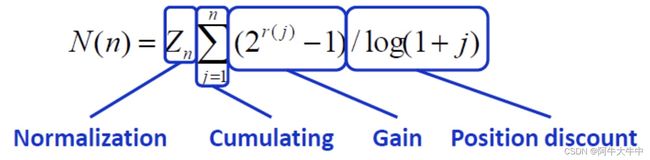
() 表示第 个位置的相关度,分母的对数通常取以 2 为底, 是 IDCG 的倒数,IDCG 是理想情况下最大 DCG 值。
在 MAP 中,四个文档和 query 要么相关,要么不相关,也就是相关度非 0 即 1。NDCG 中改进了下,相关度分成从 0 到 r 的 r+1 的等级 (r 可设定)。当取 r=5 时,等级设定如下图表所示:
| Relevance Rating | Value(Gain) |
|---|---|
| Perfect(最相关,r(j)=5) | 31=2^5−1 |
| Excellent(相关,r(j)=4) | 15=2^4−1 |
| Good(中性,r(j)=3) | 7=2^3−1 |
| Fire(不相关,r(j)=2) | 3=2^2−1 |
| Bad(最不相关,r(j)=1) | 1=2^1−1 |
NDCG 从 DCG 演化而来,DCG 就是 “折损化累计增益”(Discounted Cumulative Gain),先来介绍 DCG:
DCG 的两个思想:
1)高关联度的结果比一般关联度的结果更影响最终的指标得分;
2)有高关联度的结果出现在更靠前的位置的时候,指标会越高;
在介绍 DCG 之前,我们首先假定,位置 1 是排位最高的位置,也就是顶端的文档,而位置数随着排位降低而增高,位置 10 就是第一页最后的文档。
DCG, Discounted 的 CG,就是在每一个 CG 的结果上除以一个折损值,为什么要这么做呢?目的就是为了让排名越靠前的结果越能影响最后的结果。假设排序越往后,价值越低。到第 个位置的时候,它的价值是 1/log(1+),那么第 个结果产生的效益就是 ()∗1/log(+1),所以:
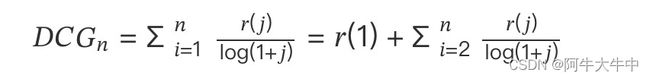
工业界最常用的公式是下面这个,增加了相关度影响比重:
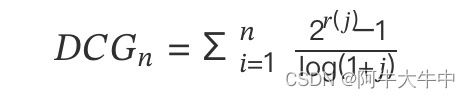
这便是 NDCG 里 DCG 部分了,当相关性值为二进制时,即 ()∈{0,1},二者结果是一样的,另外相关度也可以是实数的形式。
接下来我们看如何进行归一化,由于搜索结果随着检索词的不同,返回的数量是不一致的,而 DCG 是一个累加的值,没法针对两个不同的搜索结果进行比较,因此需要归一化处理,这里是除以 IDCG。
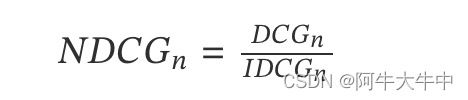
其中,IDCG 为理想情况下最大的 DCG 值,即:
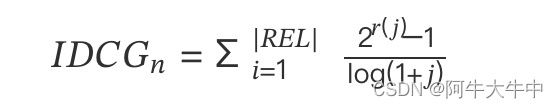
其中 |REL| 表示,结果按照相关性从大到小的顺序排序,取前 n 个结果组成的集合。也就是按照最优的方式对结果进行排序。
NDCG 计算过程示例:
| rank | r(j) | gain | Cumulative Gain | DCG | IDCG | NDCG |
|---|---|---|---|---|---|---|
| #1 | 5 | 31 | 31 | 31=31×1 | 31 | 1=31/31 |
| #2 | 2 | 3 | 34=31+3 | 32.9=31+3×0.63 | 40.5 | 0.81=32.9/40.5 |
| #3 | 4 | 15 | 49=31+3+15 | 40.4=32.9+15×0.50 | 48.0 | 0.84=40.4/48.0 |
| #4 | 4 | 15 | 64=31+3+15+15 | 46.9=40.4+15×0.43 | 54.5 | 0.86=46.9/54.5 |
| #5 | 4 | 15 | 79=31+3+15+15+15 | 52.7=46.9+15×0.39 | 60.4 | 0.87=52.7/60.4 |
| #6 | …… |
其他指标
10. 覆盖率
覆盖率(Coverage)描述一个推荐系统对物品长尾的发掘能力。最简单的定义为推荐系统能够推荐出来的物品占总物品集合的比例。
假设系统的用户集合为U,总物品集合为I ,推荐系统给每个用户推荐一个长度为N的物品列表R(u):
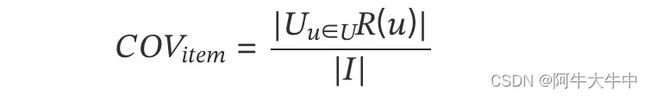
该覆盖率表示最终的推荐列表中包含多大比例的物品。如果所有的物品都被推荐给至少一个用户,那么覆盖率就是 100%。
11. 多样性
用户的兴趣是广泛的,一个经常看动漫的用户也可以喜欢其他类型的视频。为了满足用户广泛的兴趣,推荐列表需要能够覆盖用户不同的兴趣领域,即推荐结果需要具有多样性。
多样性不但要在推荐服务吐出结果时需要做一定的保证,也要通过日志做监测。
多样性可能会损失一些效果指标,但是从长远上来看,对推荐系统所在平台是有利的。多样的推荐结果也会让产品显得生机勃勃,提升品牌形象。多样性衡量方式通常要依赖维度体系选择,例如常见的是在类别维度上衡量推荐结果的多样性。方法是下面这样的。

多样性衡量实际上在衡量各个类别在推荐时的熵,一共有 n 个类别,分母是各个类别最均匀,都得到一样的推荐次数情况下对应的熵。
分子则是实际各个类别得到的推荐次数,pi 是类别 i 被推荐次数占总推荐次数的比例,计算它的熵。两者求比值是为了在类别数增加和减少时,可以互相比较。
12. 惊喜度
惊喜度是指出乎用户意料的,推荐用户认知范围外的物品给用户且令用户满意。
目前没有什么公认的惊喜度的指标定义方式。
13. 信任度
两个不同的信任系统,尽管推荐结果可能相同,但是用户可能会选择更让他信任的那个。比如京东和淘宝推荐同样的物品给用户,假如用户更多在淘宝上消费的话,用户可能会更倾向于使用淘宝推荐的物品。
14. 实时性
在新闻类网站上,例如今日头条和微博,物品具有很强的实时性。比如一条新闻,系统需要第一时间推送给用户。推荐昨天的新闻显然不如推荐今天的新闻。
推荐系统的实时性包括两个方面。首先,推荐系统需要实时的更新推荐列表来满足用户新的行为变化。第二个方面是推荐系统需要能够将新加入系统的物品推荐给用户。
15. 健壮性
推荐系统会面对各种各样的作弊行为,针对推荐系统的规则来设计一些作弊行为,以此来攻击推荐系统。而健壮性是指衡量一个推荐系统抗击作弊的能力。
算法健壮性的评测主要利用模拟攻击。
在实际的系统中,提高系统的健壮性,除了选择健壮性高的算法,还有以下方法。
-
设计推荐系统时尽量使用代价比较高的用户行为。如在用户的购买行为和浏览行为中,显然购买行为的代价更高。
-
在使用数据时,进行攻击检测,从而对数据进行清理。
参考资料
-
工业界推荐系统的评测标准
-
推荐系统评测指标
-
推荐系统的评测指标
-
推荐系统常用的评价指标
-
AUC
-
搜索评价指标——NDCG