将Parquet文件的数据导入Hive 、JSON文件导入ES
文章目录
- 将Parquet文件的数据导入Hive
-
- 查询parquet文件格式
-
- 编译cli工具
- 查看元数据信息
- 查询抽样数据
- 创建hive表 数据存储格式采用parquet
- 加载文件
- 将json数据导入ES
-
- ES批量导入api
- 原始json文件内容
- 索引结构
- 重组json脚本
- 重组后的json文件
- bulk api调用
将Parquet文件的数据导入Hive
查询parquet文件格式
主要利用社区工具 https://github.com/apache/parquet-mr/
编译cli工具
cd parquet-cli;
mvn clean install -DskipTests;
查看元数据信息
java -cp parquet-cli-1.13.1.jar;dependency/* org.apache.parquet.cli.Main meta yellow_tripdata_2023-03.parquet
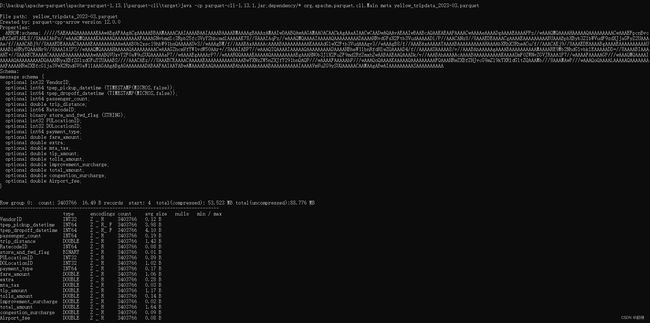
查询抽样数据
java -cp parquet-cli-1.13.1.jar;dependency/* org.apache.parquet.cli.Main head -n 2 yellow_tripdata_2023-03.parquet
{"VendorID": 2, "tpep_pickup_datetime": 1677629203000000, "tpep_dropoff_datetime": 1677629803000000, "passenger_count": 1, "trip_distance": 0.0, "RatecodeID": 1, "store_and_fwd_flag": "N", "PULocationID": 238, "DOLocationID": 42, "payment_type": 2, "fare_amount": 8.6, "extra": 1.0, "mta_tax": 0.5, "tip_amount": 0.0, "tolls_amount": 0.0, "improvement_surcharge": 1.0, "total_amount": 11.1, "congestion_surcharge": 0.0, "Airport_fee": 0.0}
{"VendorID": 2, "tpep_pickup_datetime": 1677629305000000, "tpep_dropoff_datetime": 1677631170000000, "passenger_count": 2, "trip_distance": 12.4, "RatecodeID": 1, "store_and_fwd_flag": "N", "PULocationID": 138, "DOLocationID": 231, "payment_type": 1, "fare_amount": 52.7, "extra": 6.0, "mta_tax": 0.5, "tip_amount": 12.54, "tolls_amount": 0.0, "improvement_surcharge": 1.0, "total_amount": 76.49, "congestion_surcharge": 2.5, "Airport_fee": 1.25}
parquet 和 hive 的 field 类型映射关系
| parquet 字段类型 | hive 字段类型 |
|---|---|
| BINARY | STRING |
| BOOLEAN | BOOLEAN |
| DOUBLE | DOUBLE |
| FLOAT | FLOAT |
| INT32 | INT |
| INT64 | BIGINT |
| INT96 | TIMESTAMP |
| BINARY + OriginalType UTF8 | STRING |
| BINARY + OriginalType DECIMAL | DECIMAL |
创建hive表 数据存储格式采用parquet
# 创建以parquet存储的表
CREATE TABLE `test_trino.yellow_taxi_trip_records_tmp`
(
`VendorID` int COMMENT '仪表供应商ID',
`tpep_pickup_datetime` TIMESTAMP COMMENT '仪表启动时间',
`tpep_dropoff_datetime` TIMESTAMP COMMENT '仪表关闭时间',
`passenger_count` bigint COMMENT '乘客数量',
`trip_distance` double COMMENT '行程距离',
`RateCodeID` bigint COMMENT '费率编码',
`store_and_fwd_flag` string COMMENT '是否存储',
`PULocationID` bigint COMMENT '上车区域坐标',
`DOLocationID` bigint COMMENT '下场区域坐标',
`payment_type` bigint COMMENT '付款方式',
`fare_amount` double COMMENT '票价',
`extra` double COMMENT '杂费附加费',
`mta_tax` double COMMENT '税费',
`tip_amount` double COMMENT '小费',
`tolls_amount` double COMMENT '过路费',
`improvement_surcharge` double COMMENT '改善附加费',
`total_amount` double COMMENT '费用总计,不包含现金小费',
`congestion_surcharge` double COMMENT '拥堵费',
`airport_fee` double COMMENT '机房上下车费用'
)
COMMENT '黄色的出租车记录'
PARTITIONED BY (
`ym` string COMMENT '分区字段,年月(yyyyMM)')
STORED AS PARQUET;
加载文件
# 利用hive客户端load parquet数据
LOAD DATA LOCAL INPATH '/opt/yellow_tripdata_2023-02.parquet' OVERWRITE INTO TABLE `test_trino.yellow_taxi_trip_records_tmp` PARTITION (ym=202302);
将json数据导入ES
ES批量导入api
批量写入es需要使用bulk api,这个API支持json文件的数据导入。
原始json文件内容
{"geonameid": 2986043, "name": "Pic de Font Blanca", "latitude": 42.64991, "longitude": 1.53335, "country_code": "AD", "population": 0}
{"geonameid": 2994701, "name": "Roc Mélé", "latitude": 42.58765, "longitude": 1.74028, "country_code": "AD", "population": 0}
{"geonameid": 3007683, "name": "Pic des Langounelles", "latitude": 42.61203, "longitude": 1.47364, "country_code": "AD", "population": 0}
{"geonameid": 3017832, "name": "Pic de les Abelletes", "latitude": 42.52535, "longitude": 1.73343, "country_code": "AD", "population": 0}
{"geonameid": 3017833, "name": "Estany de les Abelletes", "latitude": 42.52915, "longitude": 1.73362, "country_code": "AD", "population": 0}
{"geonameid": 3023203, "name": "Port Vieux de la Coume d’Ose", "latitude": 42.62568, "longitude": 1.61823, "country_code": "AD", "population": 0}
{"geonameid": 3029315, "name": "Port de la Cabanette", "latitude": 42.6, "longitude": 1.73333, "country_code": "AD", "population": 0}
{"geonameid": 3034945, "name": "Port Dret", "latitude": 42.60172, "longitude": 1.45562, "country_code": "AD", "population": 0}
{"geonameid": 3038814, "name": "Costa de Xurius", "latitude": 42.50692, "longitude": 1.47569, "country_code": "AD", "population": 0}
{"geonameid": 3038815, "name": "Font de la Xona", "latitude": 42.55003, "longitude": 1.44986, "country_code": "AD", "population": 0}
{"geonameid": 3038816, "name": "Xixerella", "latitude": 42.55327, "longitude": 1.48736, "country_code": "AD", "population": 0}
{"geonameid": 3038818, "name": "Riu Xic", "latitude": 42.57165, "longitude": 1.67554, "country_code": "AD", "population": 0}
{"geonameid": 3038819, "name": "Pas del Xic", "latitude": 42.49766, "longitude": 1.57597, "country_code": "AD", "population": 0}
{"geonameid": 3038820, "name": "Roc del Xeig", "latitude": 42.56068, "longitude": 1.4898, "country_code": "AD", "population": 0}
索引结构
PUT allcountries
{
"settings": {
"index.number_of_replicas": 0
},
"mappings": {
"_doc":{
"dynamic": "strict",
"properties": {
"geonameid": {
"type": "long"
},
"name": {
"type": "text"
},
"latitude": {
"type": "double"
},
"longitude": {
"type": "double"
},
"country_code": {
"type": "text"
},
"population": {
"type": "long"
}
}
}
}
}
重组json脚本
# coding=UTF-8
# 将原始josn重组出适合ES bulk API导入的JSON数据
import json
import os
import io
current_path = os.path.dirname(__file__)
#w打开一个文件只用于写入,r用于只读
#如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除
#如果该文件不存在,创建新文件
new_jsonfile = io.open(current_path+'/es-test-bulk.json','w',encoding='utf-8')
with io.open(current_path+'/es-test.json','r',encoding='utf-8')as fp:
for line in fp.readlines():
json_data=json.loads(line)
#添加index行
new_data={}
new_data['index']={}
new_data['index']['_index']="allCountries"
temp=json.dumps(new_data).encode("utf-8").decode('unicode_escape')
new_jsonfile.write(temp)
new_jsonfile.write('\n'.decode('utf-8'))
#原json对象处理为1行
old_data={}
old_data['geonameid']=json_data['geonameid']
old_data['name']=json_data['name']
old_data['latitude']=json_data['latitude']
old_data['longitude']=json_data['longitude']
old_data['country_code']=json_data['country_code']
old_data['population']=json_data['population']
temp=json.dumps(old_data).encode("utf-8").decode('unicode_escape')
new_jsonfile.write(temp)
new_jsonfile.write('\n'.decode('utf-8'))
new_jsonfile.close()
重组后的json文件
{"index": {"_index": "allcountries"}}
{"name": "El Barrerol", "geonameid": 3040809, "longitude": 1.45207, "country_code": "AD", "latitude": 42.439579999999999, "population": 0}
{"index": {"_index": "allcountries"}}
{"name": "Camí d’Easagents", "geonameid": 3040810, "longitude": 1.61341, "country_code": "AD", "latitude": 42.53349, "population": 0}
{"index": {"_index": "allcountries"}}
{"name": "Pleta de Duedra", "geonameid": 3040811, "longitude": 1.4949399999999999, "country_code": "AD", "latitude": 42.625540000000001, "population": 0}
{"index": {"_index": "allcountries"}}
{"name": "Pleta de Duedra", "geonameid": 3040812, "longitude": 1.5637000000000001, "country_code": "AD", "latitude": 42.61985, "population": 0}
{"index": {"_index": "allcountries"}}
{"name": "Plana Duedra", "geonameid": 3040813, "longitude": 1.5228900000000001, "country_code": "AD", "latitude": 42.59393, "population": 0}
{"index": {"_index": "allcountries"}}
{"name": "Planella del Duc", "geonameid": 3040814, "longitude": 1.4995700000000001, "country_code": "AD", "latitude": 42.456490000000002, "population": 0}
{"index": {"_index": "allcountries"}}
{"name": "Canal del Duc", "geonameid": 3040815, "longitude": 1.6195600000000001, "country_code": "AD", "latitude": 42.576920000000001, "population": 0}
{"index": {"_index": "allcountries"}}
{"name": "Canal Dreta", "geonameid": 3040816, "longitude": 1.5381, "country_code": "AD", "latitude": 42.551319999999997, "population": 0}
{"index": {"_index": "allcountries"}}
{"name": "Canal Dreta", "geonameid": 3040817, "longitude": 1.4865900000000001, "country_code": "AD", "latitude": 42.506630000000001, "population": 0}
{"index": {"_index": "allcountries"}}
{"name": "Port Dret", "geonameid": 3040818, "longitude": 1.7001299999999999, "country_code": "AD", "latitude": 42.573979999999999, "population": 0}
bulk api调用
curl -H "Content-Type: application/x-ndjson" -XPOST "192.168.1.1:9600/allcountries/_doc/_bulk" --data-binary @"/opt/es-documents-bulk.json"