解读大模型的微调
在快速发展的人工智能领域中,有效地利用大型语言模型(LLM)变得越来越重要。然而,有许多不同的方式可以使用大型语言模型,这可能会让我们感到困惑。实际上,可以使用预训练的大型语言模型进行新任务的上下文学习并进行微调。
那么,什么是上下文学习?又如何对大模型进行微调呢?
1. 上下文学习与索引
自从GPT-2和GPT-3出现以来,可以发现在预训练的通用文本语料库上的生成式大型语言模型(LLM)具备了上下文学习的能力,这意味着如果我们想要执行LLM没有明确训练的特定或新任务,不需要进一步训练或微调预训练的LLM。同时,我们可以通过输入提示直接提供一些目标任务的示例。
In Context Learning(ICL)的关键思想是从类比中学习。下图给出了一个描述语言模型如何使用 ICL 进行决策的例子。首先,ICL 需要一些示例来形成一个演示上下文。这些示例通常是用自然语言模板编写的。然后 ICL 将查询的问题(即需要预测标签的 input)和一个上下文演示(一些相关的 cases)连接在一起,形成带有提示的输入,并将其输入到语言模型中进行预测。
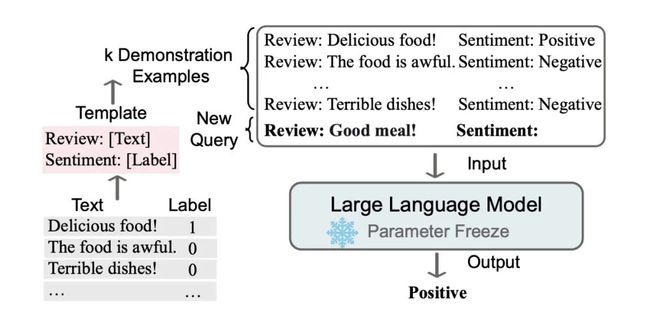
如果无法直接访问模型,例如通过 API 使用模型,上下文学习非常有用。与上下文学习相关的是“硬提示微调”的概念,可以通过修改输入来期望改善输出。将直接修改输入的单词或标记的微调称为“硬”提示微调,另一种微调方式称为“软”提示微调或通常称为“提示微调”。这种提示微调方法提供了一种更为节省资源的参数微调替代方案。然而,由于它不会更新模型参数以适应特定任务的微小差异,因此可能会限制其适应能力。此外,由于通常需要手动比较不同提示的质量,提示微调可能需要耗费大量人力。
另一种利用纯粹的上下文学习方法的方法是索引。在LLM的范围内,索引可以被视为一个上下文学习的解决方法,它使得LLM可以转换为信息检索系统,用于从外部资源和网站中提取数据。在此过程中,索引模块将文档或网站分解为较小的段落,并将它们转换为可以存储在向量数据库中的向量。然后,当用户提交查询时,索引模块计算嵌入式查询与数据库中每个向量之间的向量相似度。最终,索引模块获取前k个最相似的嵌入式向量以生成响应。索引的示意图如下:

2. 基于三种特征的微调方法
上下文学习是一种有价值且用户友好的方法,适用于直接访问大型语言模型受限的情况,例如通过API或用户界面与LLM进行交互。然而,如果可以访问LLM,则使用来自目标领域的数据对其进行适应和微调通常会导致更好的结果。那么,我们如何将模型适应到目标任务?下图概述了三种常规的基于特征的微调方法。
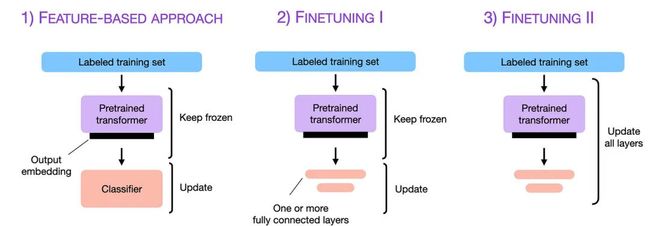
除了微调编码器风格的LLM之外,相同的方法也适用于GPT般的解码器风格LLM。此外,还可以微调解码器风格的LLM生成多句话的答案,而不仅仅是分类文本。
2.1 基于特征的方法
在基于特征的方法中,需要加载预训练的LLM,并将其应用于目标数据集。在这里,需要特别关注生成训练集的输出嵌入,这些嵌入可以用作训练分类模型的输入特征。虽然这种方法在以嵌入为重点的模型(如BERT)中特别常见,但也可以从生成式GPT-style模型中提取嵌入。
分类模型可以是逻辑回归模型、随机森林或XGBoost ,也可以任何我们想要的模型。一般地,在这里线性分类器如逻辑回归表现最佳。

从概念上讲,可以用以下代码说明基于特征的方法:
model = AutoModel.from_pretrained("distilbert-base-uncased")
# ...
# tokenize dataset
# ...
# generate embeddings
@torch.inference_mode()
def get_output_embeddings(batch):
output = model(
batch["input_ids"],
attention_mask=batch["attention_mask"]
).last_hidden_state[:, 0]
return {"features": output}
dataset_features = dataset_tokenized.map(
get_output_embeddings, batched=True, batch_size=10)
X_train = np.array(imdb_features["train"]["features"])
y_train = np.array(imdb_features["train"]["label"])
X_val = np.array(imdb_features["validation"]["features"])
y_val = np.array(imdb_features["validation"]["label"])
X_test = np.array(imdb_features["test"]["features"])
y_test = np.array(imdb_features["test"]["label"])
# train classifier
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression()
clf.fit(X_train, y_train)
print("Training accuracy", clf.score(X_train, y_train))
print("Validation accuracy", clf.score(X_val, y_val))
print("test accuracy", clf.score(X_test, y_test))2.2 基于输出层更新的微调
与上述基于特征的方法相关的一种流行方法是微调输出层。与基于特征的方法类似,保持预训练LLM的参数不变,只训练新添加的输出层,类似于在嵌入特征上训练逻辑回归分类器或小型多层感知器。在代码中,将如下所示:
model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased",
num_labels=2
)
# freeze all layers
for param in model.parameters():
param.requires_grad = False
# then unfreeze the two last layers (output layers)
for param in model.pre_classifier.parameters():
param.requires_grad = True
for param in model.classifier.parameters():
param.requires_grad = True
# finetune model
lightning_model = CustomLightningModule(model)
trainer = L.Trainer(
max_epochs=3,
...
)
trainer.fit(
model=lightning_model,
train_dataloaders=train_loader,
val_dataloaders=val_loader)
# evaluate model
trainer.test(lightning_model, dataloaders=test_loader)理论上,这种方法应该具有与基于特征的方法同样的良好建模性能和速度。然而,由于基于特征的方法使预计算和存储嵌入特征更加容易,因此在特定的实际情况下,记忆特征的方法可能更加方便。
2.3 面向所有层更新的微调
尽管原始的BERT论文声称,仅微调输出层可以实现与微调所有层相当的建模性能,但后者涉及更多参数,因此成本更高。例如,BERT基本模型约有1.1亿个参数。然而,BERT基本模型用于二元分类的最后一层仅包含1,500个参数。此外,BERT基本模型的最后两层占据60,000个参数,仅占总模型大小的约0.6%。]
由于目标任务和目标领域与模型预训练的数据集相似程度的不同,几乎总是通过微调所有层来获得更优秀的模型性能。因此,当优化模型性能时,使用预训练LLM的黄金标准是更新所有层。从概念上讲,这种方法与输出层更新非常相似。唯一的区别是不冻结预训练LLM的参数,而是对其进行微调。
model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased",
num_labels=2
)
# don't freeze layers
# for param in model.parameters():
# param.requires_grad = False
# finetune model
lightning_model = LightningModel(model)
trainer = L.Trainer(
max_epochs=3,
...
)
trainer.fit(
model=lightning_model,
train_dataloaders=train_loader,
val_dataloaders=val_loader)
# evaluate model
trainer.test(lightning_model, dataloaders=test_loader)多层微调通常会导致更好的性能,但代价也会增加,各种方法的计算和模型性能如下图所示。

上面的情景突出了微调的三种极端情况:基于特征,仅训练最后一层或几层,或者训练所有层。当然,根据模型和数据集的不同,在各种选项之间探索也可能是值得的。
3. 参数高效微调
参数高效微调允许我们在最小化计算和资源占用的同时重复使用预训练模型。总的来说,参数高效微调至少有以下5个优点:
减少计算成本(需要更少的GPU和GPU时间);
更快的训练时间(更快地完成训练);
更低的硬件要求(可以使用更小的GPU和更少的存储器);
更好的模型性能(减少过拟合);
更少的存储空间(大部分权重可以在不同任务之间共享)。
如前所述,微调更多的层通常会导致更好的结果。如果想要微调更大的模型,例如重新生成的LLM,这些模型只能勉强适合GPU内存,该怎么办呢?人们开发了几种技术,只需训练少量参数便可通过微调提升LLM的性能。这些方法通常被称为参数高效微调技术(PEFT)。
在huggingface提供的PEFT工具中,可以很方便地实现将普通的HF模型变成用于支持轻量级微调的模型,使用非常便捷,目前支持4种策略,分别是:
LoRA
Prefix Tuning
P-Tuning
Prompt Tuning
下图总结了一些最广泛使用的PEFT技术。

那么这些技术是如何工作的呢?简而言之,它们都涉及引入少量的额外参数,而不是对所有层都进行修改。从某种意义上讲,输出层微调也可以被视为一种参数高效的微调技术。然而,像前缀微调、适配器和低秩适应等技术,它们“修改”多个层,以极低的成本实现更好的预测性能。
4.RHLF
在人类反馈增强学习中,预训练模型使用监督学习和强化学习相结合进行微调。这种方法是由原始的ChatGPT模型推广而来,而该模型又基于InstructGPT。RLHF通过让人类对不同的模型输出进行排名或评分来收集人类反馈,从而提供奖励信号。然后,可以使用收集的奖励标签来训练奖励模型,进而指导LLM对人类偏好的适应。
奖励模型本身是通过监督学习进行学习的,通常使用预训练的LLM作为基本模型。接下来,奖励模型用于更新预训练的LLM,以适应人类的偏好。训练使用了一种称为近端策略优化的强化学习方法。InstructGPT论文中概述了RLHF的过程。
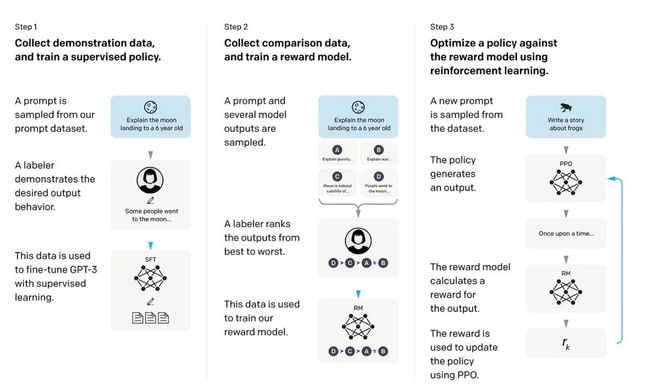
为什么要使用奖励模型而不是直接训练预先训练好的模型并使用人类反馈?主要原因是将人类纳入学习过程会造成瓶颈,我们无法实时获取反馈。
5.小结
微调预训练LLM的所有层仍然是适应新目标任务的黄金准则。但是,诸如基于特征的方法、上下文学习和参数高效微调技术等方法,可以在最小化计算成本和资源的同时,有效地将LLM应用到新任务中。此外,带有人类反馈的强化学习(RLHF)作为有监督微调的替代方法,也可以提高模型性能。
【参考资料与关联阅读】
A Survey on In-context Learning,https://arxiv.org/pdf/2301.00234.pdf
LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS,https://arxiv.org/pdf/2106.09685.pdf
Prefix-Tuning: Optimizing Continuous Prompts for Generation, https://aclanthology.org/2021.acl-long.353
P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks,https://arxiv.org/pdf/2110.07602.pdf
The Power of Scale for Parameter-Efficient Prompt Tuning,https://arxiv.org/pdf/2104.08691.pdf
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,https://arxiv.org/abs/1810.04805
https://github.com/huggingface/peft
https://github.com/rasbt
一文读懂“语言模型”
解读TaskMatrix.AI
深度学习架构的对比分析
解读ChatGPT中的RLHF
解读Toolformer
知识图谱的5G追溯
图计算的学习与思考
AI系统中的偏差与偏见
面向AI 的数据生态系统
机器学习与微分方程的浅析
神经网络中常见的激活函数
老码农眼中的大模型(LLM)
《深入浅出Embedding》随笔
机器学习系统架构的10个要素
清单管理?面向机器学习中的数据集
DuerOS 应用实战示例——机器狗DIY
《基于混合方法的自然语言处理》译者序