论文阅读:CIL: Contrastive Instance Learning Framework for Distantly SupervisedRelation Extraction
论文:CIL: Contrastive Instance Learning Framework for Distantly Supervised
总结:提出了一种基于对比的方法来帮助MIL框架有效地学习。
Contrastive Instance Learning 主要方法:
对于源包Bs中的任何实例xs:
(1)基于![]() 的可控数据增强后的实例
的可控数据增强后的实例![]() 是它的正对实例。
是它的正对实例。
(2)批次中其他不同包的关系三元组![]() 是其负对实例。
是其负对实例。
目录
1.背景
2.模型简介
3.CIL框架
3.1 input embeddings
3.1.1 Token Embedding
3.1.2 Position Embedding
3.2 Sentence Encoder
3.3 Bag Encoder
3.4 Contrastive Instance Learning
4.Contrastive Instance Learning
4.1 Positive Pair Construction
4.1.1 实例xs 和随机实例xs'
4.1.2 实例xs 和关系三元组 Bs
4.1.3 实例xs和增强实例xs*
4.2 Negative Pair Construction
4.2.1 实例 xs和 随机实例 xt
4.2.2实例xs 和关系三元组bt
1.背景
远监督关系提取,有噪声。
1.在意识到现有的DS噪声的同时,Zeng等人(2015)将训练实例划分为多个包,并将训练实例作为新的数据单元,从而将多实例学习(MIL)框架引入到DSRE中。
2.软注意力机制:对于袋内实例的选择策略,Lin等人(2016)提出的软注意机制因其比硬选择方法具有更好的性能而被广泛应用。
现存问题:注意机制可以帮助选择包里相对信息丰富的实例(如h1、h2),但可能忽略其他丰富的实例的潜在信息(如hm),也就是无论一个包包含多少个实例,只有形成的包级表示可以用于MIL中的进一步训练,这是相当不有效的。
提出问题:如何使初始MIL框架足够高效,以利用所有实例,同时保持在DS数据噪声下获得准确模型的能力?
综上,提出了一种基于对比的方法来帮助MIL框架有效地学习
2.模型简介
方法:将初始的MIL框架视为 bag encoder,它为不同的关系三元组提供了相对准确的表示,然后开发对比实例学习(CIL),以一种无监督的方式利用每个实例。
目标:CIL的目标是共享相同三元组的实例在语义空间中应该很接近,而具有不同关系三元组的实例的表示应该很远。
3.CIL框架
3.1 input embeddings
3.1.1 Token Embedding
1.对于输入句子/实例x 利用BERT Tokenizer 将其分割成几个tokens:
![]() ,其中e1,e2是两个实体对应的标记,L是所有输入序列的最大长度。
,其中e1,e2是两个实体对应的标记,L是所有输入序列的最大长度。
2.为了以一种实体感知的方式对句子进行编码,添加了四个额外的特殊标记([H-CLS],[H-SEP])和([T-CLS],[T-SEP])来标记两个实体的开始和结束。
3.1.2 Position Embedding
在Transformer attention 机制中,学习到的位置嵌入与标记嵌入具有相同的维数,于是使两者求和,来注入位置编码,以利用序列的次序(order of the sequence)。
3.2 Sentence Encoder
BERT编码器将上述嵌入输入(Token Embedding和Position Embedding)转换为隐藏的特征向量,![]() ,其中he1和he2是对应于实体e1和e2的特征向量。
,其中he1和he2是对应于实体e1和e2的特征向量。
通过将两个实体隐藏向量连接起来,得到输入序列x的实体感知:
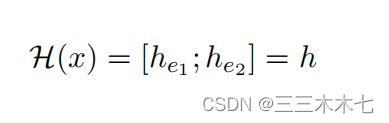
3.3 Bag Encoder
在MIL框架下,具有相同关系三元组的多个实例形成包。
论文中设计了一个包编辑器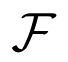 ,来获得包的表示,也就是当前关系三元组[e1,e2,r]的代表,定义为:
,来获得包的表示,也就是当前关系三元组[e1,e2,r]的代表,定义为: 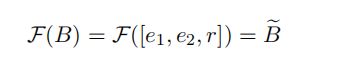 。
。
为了训练由θ参数化的包编码器,作者添加了一个简单的具有激活函数softmax的简单全连接层,将隐藏特征向量![]() 映射到条件概率分布
映射到条件概率分布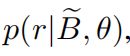 ,可以定义为:
,可以定义为:
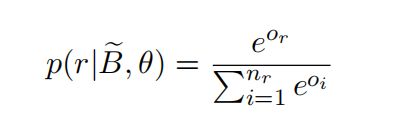
其中 ![]() 所有关系类型相关的得分,
所有关系类型相关的得分,![]() 是关系的总数,
是关系的总数,![]()
是投影矩阵, ![]() 是偏差项。
是偏差项。
其中包的编码器的目标是:
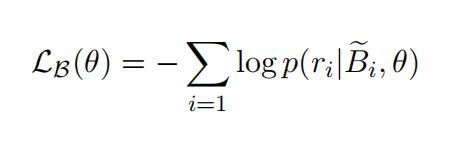
3.4 Contrastive Instance Learning
目标:相同关系三元组(positive pairs)的实例应该在隐藏的语义空间中尽可能地接近,包含不同关系三元组(negative对)的实例应该尽可能远。
包的定义:假设有一个批包输入(批大小为G):(B1、B2,…,BG),所有包的关系三元组都是不同的。批次中的每个包B都是由一个特定的关系三元组[e1,e2,r]构造的,包内的所有实例x都满足这三元组。
三元组可以用bag encoder表示为:![]() 。
。
下面,在batch中选择任意两个包![]() 和
和![]() 来进一步说明对比实例学习的过程。
来进一步说明对比实例学习的过程。
其中,![]() 被定义为由关系三元组[es1,es2,rs]构建的源包而
被定义为由关系三元组[es1,es2,rs]构建的源包而![]() 是由三元组[et1,et2,rt ]构建的目标包。
是由三元组[et1,et2,rt ]构建的目标包。
(由于标题只有三级原因,在这里把 3.4 Contrastive Instance Learning 部分单独拿出来写)
4.Contrastive Instance Learning
4.1 Positive Pair Construction
4.1.1 实例xs 和随机实例xs'
方法: 从包B里随机选择另外一个实例xs' 和 实例 xs
结果:实例xs和xs’都可能存在数据噪声,它们很难同时表达相同的关系三元组
4.1.2 实例xs 和关系三元组 Bs
方法:实例xs的另一个正对实例候选是当前包B的关系三元组表示![]() 。
。
结果:虽然![]() 可以被认为是一个去噪的,但是
可以被认为是一个去噪的,但是![]() 可能仍然有噪音和表示其它的关系
可能仍然有噪音和表示其它的关系![]() 。
。
除此之外,此外,构造的正对的质量很大程度上依赖于包编码器的模型性能。
4.1.3 实例xs和增强实例xs*
这里采用了一种基于TF-IDF数据增强的噪声树正对构造方法。
如果只对原始实例xs进行小而可控的数据增强,则增强实例xs*应该与实例xs满足相同的关系三元组。
详细说明:
(1)首先将每个实例视为一个文档,并将实例中的每个单词视为一个term,然后我们在整个训练语料库上训练一个TF-IDF模型。
(2)基于训练好的TF-IDF模型,以特定的比例插入/替换一些不重要的词,到/在 实例xs 里,以获得其增强实例xs∗。特别地,还在实体词中添加了特殊的masks,以避免它们被替换。
例子如下:

单词替换的一个例子:低得分的单词被替换为单词goehr,实体单词stephen king
和maine受到保护。
4.2 Negative Pair Construction
4.2.1 实例 xs和 随机实例 xt
方法:对于同样的包 Bs里的实例Xs,随机从另一个不同的包Bt里选择一个实例Xt 作为它的负对实例。
结果:随机选择的实例xt可能噪声太大,无法表示袋Bt的关系三元组,因此可能会影响模型的性能。
4.2.2实例xs 和关系三元组bt
方法:
实例xi可以被看作是远离包Bt的加权表示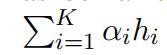 ,在这里ai都是可学习的。
,在这里ai都是可学习的。
所以与随机选择策略相比,使用关系三元组表示 Bt作为xs的负对实例是减少数据噪声影响的更好的选择。
一起加油!