The Category-theoretic Perspective of Statistical Learning for Amateurs
统计学习.范畴论视角
title: The Category-theoretic Perspective of Statistical Learning for Amateurs
author: Congwei Song
description: A representation in BIMSA
The Category-theoretical Perspective of Statistical Learning for Amateurs
Congwei Song Email: [email protected] Research Interest: Machine Learning, Wavelet AnalysisAbstract Statistical learning is a fascinating field that has long been the mainstream of machine learning/artificial intelligence. A large number of results have been produced which can be widely applied to real-world problems. It also leads to many research topics and also stimulates new research. This report summarizes some classic statistical learning models and well-known algorithms, especially for amateurs, and provides a category-theoretic perspective on understanding statistical learning models. The goal is to attract researchers from other fields, including basic mathematics, to participate in the research related to statistical learning.
Keywords Statistical Learning, Statistics, Category Theory, Variational Models, Neural Networks, Deep Learning
Abbreviations
distr.: distribution(s)
var.: variable(s)
cat.: category(ies)
rv: random varible(s)
Notations
- P ( X ) P(X) P(X): distr. of target rv X X X
- P ( X ∣ θ ) P(X|\theta) P(X∣θ): parameteric distr.
Introduction
- Probability theory/Statistics
- Category theory
- Statistical Learning
- Classiscal models of statistical Learning
- Advanced models
- Misc
Probability theory
Definition (Probability Model)
The probability model is a probability measure sp, denoted by ( Ω , A , P ) (\Omega, \mathcal{A},P) (Ω,A,P); or ( X , P ( X ) ) (\mathcal{X}, P(X)) (X,P(X)), as its pushback by the rv X X X, where X \mathcal{X} X is the sample space of X X X.
X ∼ P X\sim P X∼P: the distr. of X X X is P P P, or draw X X X from P P P
Statistics
Definition (Statistical Model)
The statistical model is a family/set of probability models denoted by ( Ω , A , { P λ } ) (\Omega, \mathcal{A},\{P_\lambda\}) (Ω,A,{Pλ}) (with common ambient space) or ( X , { P λ } ) (\mathcal{X},\{P_\lambda\}) (X,{Pλ}) (with common sample space which is the range of a target rv X X X), denoted by P ( X ) P(X) P(X) for short.
Parameterized version: ( X , { P ( X ∣ θ ) } , θ ∈ Θ ) (\mathcal{X},\{P(X|\theta)\},\theta\in\Theta) (X,{P(X∣θ)},θ∈Θ) where Θ \Theta Θ is the parameter space, denoted by P ( X ∣ θ ) P(X|\theta) P(X∣θ) for short.
Example
N ( μ , σ 2 ) , C a t ( p ) N(\mu,\sigma^2),Cat(p) N(μ,σ2),Cat(p)
Definition (Baysian Model)
THe Baysian model is a statistical model with priori distr. of parameters, as
( M θ , p ( θ ) ) (M_\theta,p(\theta)) (Mθ,p(θ)), where M θ M_\theta Mθ is a given statistical model.
Definition (Baysian Hierachical Model)
( M θ , p ( θ ∣ α ) , p ( α ) ) (M_\theta,p(\theta|\alpha),p(\alpha)) (Mθ,p(θ∣α),p(α))
Category theory of Statistical Models
- P r o b \mathcal{Prob} Prob: cat. of all probability models,
- P r o b X \mathcal{Prob}_X ProbX: sub-cat. of P r o b \mathcal{Prob} Prob with the form of ( X , P ( X ) ) (\mathcal{X}, P(X)) (X,P(X))
- P r o b Y ∣ x \mathcal{Prob}_{Y|x} ProbY∣x: sub-cat. of P r o b \mathcal{Prob} Prob taking the form of ( Y , P ( Y ∣ x ) ) (\mathcal{Y}, P(Y|x)) (Y,P(Y∣x)) with the conditional var. x x x.
- S t a t \mathcal{Stat} Stat: cat. of The statistical models
- S t a t X \mathcal{Stat}_X StatX: cat. of The statistical models of the target rv X X X
- S t a t Y ∣ x \mathcal{Stat}_{Y|x} StatY∣x: cat. of The statistical models of the target rv Y ∣ x Y|x Y∣x with conditional var x x x.
- B a y e s \mathcal{Bayes} Bayes: cat. of the Baysian models
S t a t \mathcal{Stat} Stat is regarded as a sub-cat. of S t a t \mathcal{Stat} Stat with the flatten priori. The Bayesian model gives joint P ( x , θ ) P(x,\theta) P(x,θ)。Therefore the category of the Bayesian models is a sub-cat. of P r o b Prob Prob.
Estimator
Definition (Statistical model with an estimator)
model with estimator: ( M θ , θ ^ ( X ) ) (M_\theta, \hat\theta(X)) (Mθ,θ^(X)) where θ ^ : X N → Θ \hat\theta: \mathcal{X}^N\to \Theta θ^:XN→Θ, X X X is a sample with size N N N.
In most case, we use MLE. The estimator has been implied by model.
Statistical Learning
supervised learning (determinant form):
( X , Y , P ( Y ∣ X ) ) (\mathcal{X},\mathcal{Y}, P(Y|X)) (X,Y,P(Y∣X)) where X X X is input (conditional var.), Y Y Y is output
Supervised learning based on sample X = { X i } X=\{X_i\} X={Xi}, is identified with statistical model:
( Y N , P ( Y ∣ X ) = ∏ i P ( y i ∣ x i ) ) (\mathcal{Y}^N, P(Y|X)=\prod_iP(y_i|x_i)) (YN,P(Y∣X)=i∏P(yi∣xi))
where the sample X X X is fixed, named design var. (design matrix, if it forms a matrix) and Y Y Y is a sample point (sample with size 1).
I claim: statistical learning == conditionalized statistics (model)
Facts in statistical learning are also facts in statistics
Bias-Variance Decomposition in statistics: Error = Bias + Variance; in statistical learning: Error = Bias + Variance under condition of input variable;
Classical Models in Statistical Learning(SL)
- Supervised Learning
- Regression: P ( Y ∣ X ) P(Y|X) P(Y∣X), Linear Regression, Ridge/LASSO Regression ( X X X is the conditional rv)
- Classification: P ( Y ∣ X ) P(Y|X) P(Y∣X), Logistic Regression/LDA(/QDA)/Naive Bayesian Classifier
- Unsupervised Learning
- Clustering: P ( X , Z ) P(X,Z) P(X,Z), where Z Z Z is unobservable, K-means/GMM
- Dimension Reduction: P ( X , Z ) P(X,Z) P(X,Z), PCA/ICA/MNF
- Latent Variable Models: P ( X , Z ) P(X,Z) P(X,Z), Mixed models(GMM), pLSA
- Hidden Markov Model: P ∗ ( X 1 : T , Z 1 : T ) P^*(X_{1:T},Z_{1:T}) P∗(X1:T,Z1:T) where ( X t , Z t ) ∼ P (X_t,Z_t)\sim P (Xt,Zt)∼P
- Others
Time sequence: P ∗ ( X 1 : T ) P^*(X_{1:T}) P∗(X1:T), ARMA
Learner
A learner is an estimator for statistical model:
( M θ , θ ^ ( X ) ) (M_\theta, \hat{\theta}(X)) (Mθ,θ^(X))
where M θ M_\theta Mθ is a statistical model.
One can define a latent model as ( P ( X , Z ) , θ ^ ( X ) ) (P(X,Z), \hat{\theta}(X)) (P(X,Z),θ^(X)) for unsupervised learning; ( P ( X , Y ) , θ ^ ( X , Y ) ) (P(X,Y), \hat{\theta}(X,Y)) (P(X,Y),θ^(X,Y)) for supervised learning.
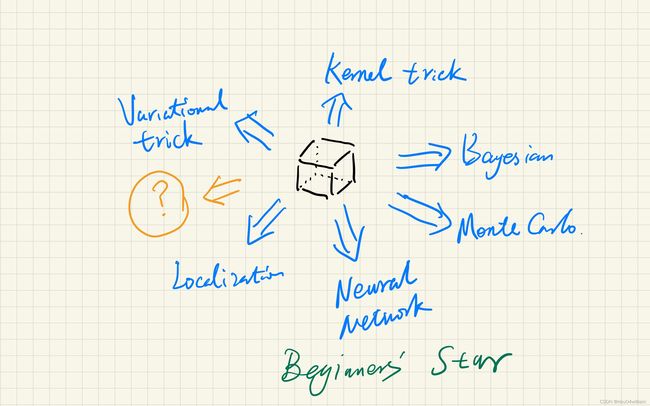
Beginners’ Magic Cube
The classical models are all categories. And we have a diagram about them. I’d like to call it “the beginners’ magic cube”, since it looks like a cube and the beginner of SL should learn them first.

Probabilitic Graph Model
Another way to describe the statistical (learning) model.
- Bayesian Network: Directed acyclic graph
- Markov Network(Random Field): Undirected graph
Methods
Methods as Functors:
- Kernel trick: X → ϕ ( X ) X\to \phi(X) X→ϕ(X)
- Localization/Smoothing: ∑ i K ( x 0 , x i ) l ( x i , y i ) \sum_i K(x_0,x_i)l(x_i,y_i) ∑iK(x0,xi)l(xi,yi)
- Hierarchical model: P ( X , Z 1 , ⋯ , Z n , Y ) P(X,Z_1,\cdots, Z_n,Y) P(X,Z1,⋯,Zn,Y) where X → Z 1 → ⋯ → Z n → Y X\to Z_1\to \cdots\to Z_n\to Y X→Z1→⋯→Zn→Y forms Markov chain usually and Z 1 , ⋯ , Z n Z_1,\cdots, Z_n Z1,⋯,Zn are hidden.
- Variational trick: ( P ( X , Z ) , Q ( Z ∣ X ) ) (P(X,Z), Q(Z|X)) (P(X,Z),Q(Z∣X)) where Q ( Z ∣ X ) Q(Z|X) Q(Z∣X) is the variational distr.
- Neural network(NN): f ( x ) → N e t ( x ) f(x) \to Net(x) f(x)→Net(x)
- Stochastic method/Monte Carlo method: Important sampling/MCMC
Advanced Models I:
Neural Models: Models equipped with Neural Networks; apply neural network in statistical models.
- Neural Models: MLP, embed NN into regression models
- RNN/LSTM: as a conditional HMM implemented by NN
- Neural Autoencoder: NLPCA, embed NN into the autoencoder
- Probabilistic Neural Autoencoder: Variational Autoencoder(VAE; the stochastic perturbation affacts the outputs of the layers)
- Stochastic NN: Dropout(the stochastic perturbation affacts the weights of the layers)
- Normalization Flow: Reparameterization, as a non-stochastic hierarchical VAE
- Hierarchical VAE: Diffusion Model/Consistency Model
Beginners’ Star
Create an advanced models I
Take VAE as an example
P ( X ) ∼ N ( μ , σ 2 ) → P ( X ∣ Z ) ∼ N ( f ( z ) , σ 2 ) , P ( Z ) ∼ N ( 0 , 1 ) → ( P ( X , Z ) , Q ( Z ∣ X = x ) ∼ N ( g ( x ) , h ( x ) ) ) → ( P ( X , Z ) , Q ( Z ∣ X = x ) = g ( x ) + ξ h ( x ) ) , ξ ∼ N ( 0 , 1 ) P(X)\sim N(\mu,\sigma^2) \to P(X|Z)\sim N(f(z),\sigma^2),P(Z)\sim N(0,1)\\ \to (P(X,Z),Q(Z|X=x)\sim N(g(x),h(x)))\\ \to (P(X,Z),Q(Z|X=x) = g(x)+\xi h(x)),\xi\sim N(0,1) P(X)∼N(μ,σ2)→P(X∣Z)∼N(f(z),σ2),P(Z)∼N(0,1)→(P(X,Z),Q(Z∣X=x)∼N(g(x),h(x)))→(P(X,Z),Q(Z∣X=x)=g(x)+ξh(x)),ξ∼N(0,1)
Write it in the style of the composition of functors (informally)
V A E ( f , g , h ) = R e p ∘ V a r ∘ L V M ( P ( X ) ) VAE(f,g,h) = \mathrm{Rep}\circ \mathrm{Var}\circ\mathrm{LVM}(P(X)) VAE(f,g,h)=Rep∘Var∘LVM(P(X)), regarding functions f , g , h f,g,h f,g,h as parameters.
The implimentation of VAE by the following NN (with a regularizing term):
y ∼ f ( g ( x ) + h ( x ) ξ ) , y \sim f(g(x)+h(x)\xi), y∼f(g(x)+h(x)ξ),
through self-supervised learning with data { ( x i , x i ) } \{(x_i,x_i)\} {(xi,xi)}, where f , g , h f,g,h f,g,h are all neural layers, ξ ∼ N ( 0 , 1 ) \xi\sim N(0,1) ξ∼N(0,1) is the perturbation variable of the hidden layer g g g. when ξ → 0 \xi\to 0 ξ→0, Q Q Q is degenerated, and VAE degenerates to an ordinary NN f ( g ( x ) ) f(g(x)) f(g(x)).
Create an advanced models II
Take RNN as an example
P ( Y ) → ⋯ → P ∗ ( Y , Z ∣ X ) → y t = N e t ( x t , z t − 1 ) , z t = N e t ( x t , z t − 1 ) P(Y)\to \cdots \to P^*(Y,Z|X)\\ \to y_t=Net(x_t,z_{t-1}),z_{t}=Net(x_t,z_{t-1}) P(Y)→⋯→P∗(Y,Z∣X)→yt=Net(xt,zt−1),zt=Net(xt,zt−1)
say R N N ( w ) = N N ∘ T S ∘ C o n d i ∘ L V M ( P ) RNN(w) = \mathrm{NN\circ TS\circ Condi\circ LVM}(P) RNN(w)=NN∘TS∘Condi∘LVM(P).
Homework
- What about Z k ∼ B ( p k ) Z_k\sim B(p_k) Zk∼B(pk) (multivariate Bernoullian distr.)
- To create time sequence version of VAE
Advanced Models II
- Ensemble Learning
- Transfer Learning
- Incremental Learning(Continual Learning、On-line Learning)
- Life-Long Learing
Possible definition of Transfer Learning
- ( P ( X ∣ θ 1 ) , P ( X ∣ θ 2 ) ) , θ 1 , θ 2 ∼ P ( θ ∣ α ) (P(X|\theta_1),P(X|\theta_2)), \theta_1,\theta_2\sim P(\theta|\alpha) (P(X∣θ1),P(X∣θ2)),θ1,θ2∼P(θ∣α)
- ( P ( X ∣ θ 1 , θ 0 ) , P ( X ∣ θ 2 , θ 0 ) ) (P(X|\theta_1,\theta_0),P(X|\theta_2,\theta_0)) (P(X∣θ1,θ0),P(X∣θ2,θ0))
- ( P ( ϕ ( X ) ∣ θ ) , P ( ϕ ( X ) ∣ θ ) ) (P(\phi(X)|\theta),P(\phi(X)|\theta)) (P(ϕ(X)∣θ),P(ϕ(X)∣θ))
with sample X 1 X_1 X1 from sorce domain and sample X 2 X_2 X2 from target domain
Misc.
- Reinforcement Learning: Stochastic Learning
evaluation/sampling-estimation alternating.
θ → v → θ → v → ⋯ \theta \to v \to \theta \to v\to \cdots θ→v→θ→v→⋯ - BiLSTM/BiLM/ELMo
- Transformer/Self-attention
- models based on Unnormalized distr. (Energy-based models)
Inspired by BiLSTM/BiLM: Tied Model
( P ( X ∣ θ 1 , θ 0 ) , P ( X ∣ θ 2 , θ 0 ) ) (P(X|\theta_1,\theta_0),P(X|\theta_2,\theta_0)) (P(X∣θ1,θ0),P(X∣θ2,θ0)) with the same sample.
Tied likelihood: P ( X ∣ θ 1 , θ 0 ) P ( X ∣ θ 2 , θ 0 ) P(X|\theta_1,\theta_0)P(X|\theta_2,\theta_0) P(X∣θ1,θ0)P(X∣θ2,θ0)
(a sort of pseudo-likelihood; a product of expert without normalized coef.)
Future Works
References
- PETER MCCULLAGH WHAT IS A STATISTICAL MODEL? The Annals of Statistics. 2002, 30(5): 1225–1310
- Jared Culbertson and Kirk Sturtz. Bayesian Machine Learning via Category Theory, 2013.
- Categories for AI. https://www.youtube.com/watch?v=4poHENv4kR0
- Kenneth A. Lloyd, Jr. A Category-Theoretic Approach to Agent-based Modeling and Simulation, 2010.
- Dan Shiebler, Bruno Gavranovic, Paul Wilson, Category Theory in Machine Learning, 2021.
链接: https://pan.baidu.com/s/1GdPiVGG3GIKVS4nWqlBm-w?pwd=1111 提取码: 1111