数据分析案例-二手车价格预测
目录
数据获取
加载数据
数据预处理
数据分析
特征工程
建模
数据获取
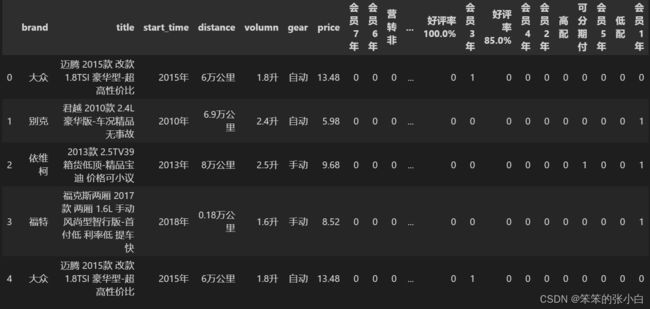
我们利用scrapy爬虫框架对58同城上海二手车数据进行抓取,部分数据如下:

加载数据
#数据分析及可视化的包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
#通过pandas读取数据,以便进一步分析
dataset = pd.read_csv("data.csv")
dataset.head()
数据预处理
查看描述性数据
dataset.describe() 
接着我们根据tag这一列提取特征值
tag_list = list()
dataset['tag'].apply(lambda x:tag_list.extend(x.split("_")))
tag_list = list(set(tag_list))
tag_list
接着我们将这一列与原数据进行合并,并将tag_list里的值用0填充
tag_df = pd.DataFrame(columns=tag_list)
df = pd.concat([dataset, tag_df], sort=False)
df[tag_list] = df[tag_list].fillna(0)
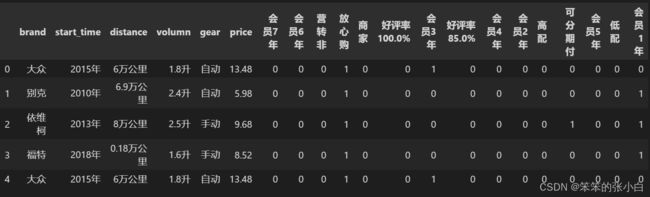
df.head()
接着我们将tag出现的记为1,并且删除原数据tag这一列数据
#将tag中的数据 处理为数字
def set_tag_status(series):
tag = series['tag'].split("_")
for t in tag:
series[t] = 1
return series
df[tag_list] = df[['tag',*tag_list]].apply(lambda x:set_tag_status(x),axis = 1).drop('tag',axis=1)
df = df.drop('tag',axis=1)
df.head()
标题没用,删除
#删除标题
df = df.drop('title',axis=1)数据分析
分析平均价格最高的前10个品牌并做可视化
#分析平均价格最高的前10个品牌
num_top = df.groupby('brand')['price'].mean().sort_values(ascending=False)[:10]
num_top
#可视化
sns.set(font="SimHei")
fig = plt.figure(figsize=(15,10))
sns.barplot(num_top.index,num_top)
plt.xticks(rotation=90)
fig.show()

销量分析 销量最多的前10个品牌
#销量分析 销量最多的前10个品牌
num_top = df['brand'].value_counts().sort_values(ascending=False)[:10]
fig = plt.figure()
sns.barplot(num_top.index,num_top)
plt.xticks(rotation=90)
fig.show()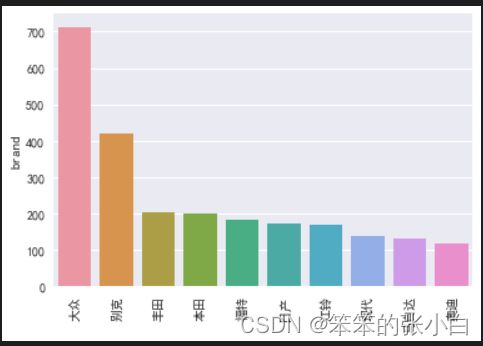
各大品牌车系数量占有比重 前10
#各大品牌车系数量占有比重 前10
fig = plt.figure()
plt.pie(num_top,labels=num_top.index,autopct="%1.2f%%")
plt.title("各大品牌车系数量占有比重前10位")
plt.show()
对大众车价格进行分区并显示各分区的概率
#对大众车价格进行分区并显示各分区的概率
df_dazhong = df[df['brand']=='大众']
df_dazhong.head()
dazhong_mean = df_dazhong['price'].mean()
dazhong_std = df_dazhong['price'].std()
num_bins = 20 #条状图数量
n,bins,patches = plt.hist(df_dazhong['price'],num_bins,normed=1,facecolor='green',alpha=0.5)
import matplotlib.mlab as mlab
y = mlab.normpdf(bins,dazhong_mean,dazhong_std)
plt.plot(bins,y,'r--')
plt.xlabel("smarts")
plt.ylabel("probability")
plt.title(r"Histogram of IQ:mean={},std={}".format(dazhong_mean,dazhong_std))
plt.subplots_adjust(left=0.15)
plt.show()

特征工程
首先我们要讲start_time这一列数据剔除“年”,distance这一列数据剔除“万公里”,以及volumn这一列数据剔除“升”,并且将gear这一列中只有一两个电动的数据进行删除
#特征工程
df['start_time']=df['start_time'].apply(lambda x:int(x[:-1]))
df['distance']=df['distance'].apply(lambda x:float(x[:-3]))
df['volumn']=df['volumn'].apply(lambda x:float(x[:-1]))
f = df[~df['volumn'].str.contains('电动')]
df.head()
接着对brand和gear进行one-hot编码并与原数据进行合并,最后删除原brand和gear这两列
one_hot_df = pd.get_dummies(df[['brand','gear']])
df = pd.merge(df,one_hot_df,left_index=True,right_index=True)
df = df.drop('brand',axis=1).drop('gear',axis=1)
df.head()
建模
数据准备
#数据准备
X = df[df.columns.difference(['price'])].values
Y = df['price'].values
导包
#导包
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_error,mean_absolute_error,r2_score拆分数据集以及训练模型
#切分数据集
x_train,x_test,y_train,y_test = train_test_split(X,Y,test_size=0.3,random_state=6)
#模型
gbdt = GradientBoostingRegressor(n_estimators=70)
#训练模型
gbdt.fit(x_train,y_train)
pred = gbdt.predict(x_test)将结果转换为DF对象打印
result_df = pd.DataFrame(np.concatenate((y_test.reshape(-1,1),pred.reshape(-1,1)),axis=1),columns=['y_pred','y_test'])
result_df.head()
我们可以看出预测值和真实值还是有一点点差距,于是我们进行模型评估
#评估
print("MSE",mean_squared_error(pred,y_test))
print("MAE",mean_absolute_error(pred,y_test))
print("RMSE",np.sqrt(mean_squared_error(pred,y_test)))
print("R2",r2_score(pred,y_test))
结果还是有一点不理想,大家可以进行参数优化来提高模型准确率