燕山大学机器学习实验一:线性回归1——糖尿病情预测
实操项目 1——糖尿病情预测
实验要求
一、加载糖尿病数据集 diabetes,观察数据
1.载入糖尿病情数据库 diabetes,查看数据。
2.切分数据,组合成 DateFrame 数据,并输出数据集前几行,观察数据。
二、基于线性回归对数据集进行分析
3.查看数据集信息,从数据集中抽取训练集和测试集。
4.建立线性回归模型,训练数据,评估模型。
三、考察每个特征值与结果之间的关联性,观察得出最相关的特征
5.考察每个特征值与结果之间的关系,分别以散点图展示。
思考:根据散点图结果对比,哪个特征值与结果之间的相关性最高?
四、使用回归分析找出 XX 特征值与糖尿病的关联性,并预测出相关结果
6.把 5 中相关性最高的特征值提取,然后进行数据切分。
8.创建线性回归模型,进行线性回归模型训练。
9.对测试集进行预测,求出权重系数。
10.对预测结果进行评价,结果可视化。
实验过程
1.对该题目的理解
糖尿病情预测主要是是利用线性回归的算法得到不同的特征值与结果之间的关联性,利用散点图的方式得到关联性最高的特征值,再对其进行回归分析与预测。
2.实现过程
(1)数据预处理:导入必要的包和数据集,其中data即为特征变量,target为目标变量,再将data和target转换为DataFrame格式以方便展示,并输出前几行观察数据。
代码如下:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd #导入pandas库
from sklearn.datasets import load_diabetes
diabetes = load_diabetes()
#print(diabetes)
#print(diabetes.keys())
#print(diabetes.feature_names)
#print(diabetes.data)
bos = pd.DataFrame(diabetes.data) #将data转换为DataFrame格式以方便展示
print (bos.head()) #前几行输出
bos_target = pd.DataFrame(diabetes.target) #将target转换为DataFrame格式以方便展示
print(bos_target)
(2)数据集划分并建立模型:数据集的划分可以采用Scikit-learn库中的model-selection程序包来实现,25%的数据构建测试样本,剩余作为训练样本。然后建立模型,训练数据,并进行模型评估。
代码如下:
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split #导入数据划分包
from sklearn.metrics import mean_squared_error
X=np.array(diabetes.data)
y=np.array(diabetes.target)# 把X、y转化为数组形式,以便于计算
train_X,test_X,train_y,test_y=train_test_split(X,y,test_size=0.25)
# 以20%的数据构建测试样本,剩余作为训练样本
#建立线性回归模型
model=LinearRegression()
model.fit(train_X,train_y)
#print(model.coef_)
pred_y=model.predict(test_X) #计算预测值
print('均方差值:',mean_squared_error(test_y,pred_y)) #计算均方差值
#通过决定系数来判断回归方程拟合程度
r_sq=model.score(train_X,train_y)
print('r_sq',r_sq)
#返回预测性能得分。score不超过1,但是可能为负值;score越大,预测性能越好
print("Score:%.2f" % model.score(test_X,test_y))
(3)考察单个特征:考察单个特征值与结果之间的关系,需要循环对每个特征值进行建模训练,分别以散点图形式展示,然后画出每一个特征训练模型得到的拟合直线,并得出每一个的模型评估结果。
代码如下:
for index in range(0,10):
x_temp=diabetes.data[:, np.newaxis, index] #获取特征
x=np.array(x_temp)
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.25)#划分数据集
lr=LinearRegression()
lr.fit(x_train,y_train)
plt.title('LinearRegression Diabetes') #标题
plt.xlabel(u'Attribute') #x轴
plt.ylabel(u'Measure of disease') #y轴
plt.scatter(x_test,y_test, color='red') #点的颜色
plt.plot(x_test,lr.predict(x_test),color='blue',linewidth=2) #直线颜色
plt.show()
print('Score:%.2f' % lr.score(x_test,y_test))(4)找到最具相关性的特征:提取出最具相关性的特征值,然后进行数据切分,创建回归模型并对其进行训练,然后对测试集进行预测,预测结果用直线表示。
代码如下:
x_temp=diabetes.data[:, np.newaxis, 8] #获取第9个特征
x=np.array(x_temp)
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.25)#划分数据集
lr=LinearRegression()
lr.fit(x_train,y_train)
plt.title('LinearRegression Diabetes') #标题
plt.xlabel(u'Attribute') #x轴
plt.ylabel(u'Measure of disease') #y轴
plt.scatter(x_test,y_test, color='red') #点的颜色
plt.plot(x_test,lr.predict(x_test),color='blue',linewidth=2) #直线颜色
plt.show()3.实验结果
每个特征值与结果之间的关系
以下分别是十个特征值与结果的散点图
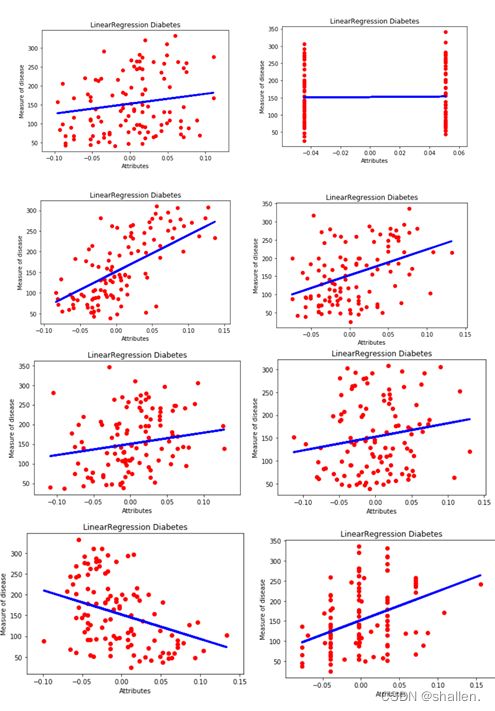
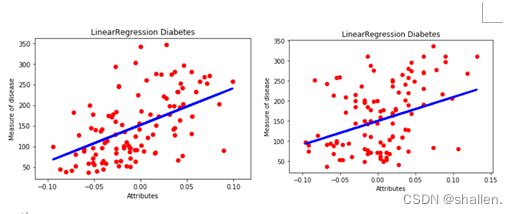
找到最具相关性的特征并预测用直线表示:

实验总结
1.从实验得知,如果单独看所有特征的训练结果,并不没有得到有效信息,需要我们拆分各个特征与指标的关系,此时我们可以看出:bmi与糖尿病的相关性最强,其他血清指标虽然多少都和糖尿病有些关系,但是有的相关性强,有的相关性弱。
2.通过此实验了解了划分训练集与测试集时,一般训练集的数据多一些,此实验中训练集数据与测试集数据之比为3:1。
3.通过此实验我更加系统的了解了Numpy和Pandas的主要功能,学会了创建DataFrame。了解了怎么构建回归模型