C++概述——浅谈C++对C的拓展

纵有疾风起,人生不言弃。本文篇幅较长,如有错误请不吝赐教,感谢支持。
C++核心编程一
-
- 一.C++简介
- 二.第一个程序Hello,world!
- 三.C++的特点
- 四.C++对C的扩展
-
- 1️⃣作用域运算符::
- 2️⃣C++命名空间(namespace)
-
- ①名字控制
- ②为什么有命名空间(namespace)
- ③命名空间使用语法
- ④命名空间注意事项
- 3️⃣using
-
- ①using声明(引入单个名称)
- ②using编译指示(引入整个命名空间)
- 4️⃣struct 类型的加强
- 5️⃣更严格的类型转换
- 6️⃣三目操作符功能加强
- 7️⃣C/C++中const的区别
-
- ①C中的const
- ②C++中的const
- 8️⃣引用(reference)
-
- ①引用是做什么的?
- ②引用的注意事项
- ③建立对数组的引用。
- ④引用的本质:
- ⑤指针的引用:
- ⑥常量的引用
- ⑦引用的使用场景
- 9️⃣宏(#define)的优缺点和解决办法
-
- ①宏常量
- ②宏函数
- 内联函数
- 1️⃣函数的默认参数和占位参数
-
- ①默认参数
- ②占位参数
- 2️⃣函数重载
- 1️⃣3️⃣new/delete
-
- (1)new创建基本数据类型对象
- (2)创建数组类型对象
- 使用delete运算符释放堆内存
一.C++简介
C++中的++来自于C语言中的递增运算符++,该运算符将变量加1。C++起初也叫"c with clsss".通过名称表明,C++是对C的扩展,因此C++是C语言的超集,这意味着任何有效的c程序都是有效的C++程序。C++程序可以使用已有的C程序库。

C++之父-本贾尼·斯特劳斯特卢普
C++语言在c语言的基础上添加了面向对象编程和泛型编程的支持。C++继承了C语言高效,简洁,快速和可移植的传统。
C++融合了3种不同的编程方式:
1️⃣C语言代表的过程性语言.
2️⃣C++在c语言基础上添加的类代表的面向对象语言.
3️⃣C++模板支持的泛型编程。
C与C++的关系
以我们常常将这两门语言统称为"C/C++"。C语言和C++并不是对立的竞争关系:
️C++是C语言的加强,是一种更好的C语言。
️C++是以C语言为基础的,并且完全兼容C语言的特性。
C语言和C++语言的学习是可以相互促进。学好C语言,可以为我们将来进一步地学习C++语言打好基础,而C++语言的学习,也会促进我们对于C语言的理解,从而更好地运用C语言。
二.第一个程序Hello,world!
老朋友了!(C++版)
#include详解:
C++程序从 main 函数开始执行。该函数只有一条语句cout<<“Hello, world!” <
#includeC与C++的对比:
相同之处:
C程序与C++程序的结构完全相同。
不同之处:
☯️C源程序文件的扩展名为c,C++源程序文件的扩展名为 cpp。
☯️C程序所包含的标准输入流、输出流的头文件是stdioh,输入、输出通常通过调用函数来完成;而C++程序包含的标准输入流、输出流的头文件是iostream,输入、输出可以通过使用标准输入流、输出流对象来完成。
为什么cpp的头文件没有.h了?
在c语言中头文件使用扩展名.h,将其作为一种通过名称标识文件类型的简单方式。但是c++得用法改变了,c++头文件没有扩展名。但是有些c语言的头文件被转换为c++的头文件,这些文件被重新命名,丢掉了扩展名.h(使之成为c++风格头文件),并在文件名称前面加上前缀c(表明来自c语言)。
例如c++版本的math.h为cmath.
由于C使用不同的扩展名来表示不同文件类型,因此用一些特殊的扩展名(如hpp或hxx)表示c++的头文件也是可以的,ANSI/IOS标准委员会也认为是可以的,但是关键问题是用哪个比较好,最后一致同意不适用任何扩展名。
三.C++的特点
C++语言是当今应用最广泛的面向对象的程序设计语言之一,因此,其具有面向对象程序设计的特点。
面向对象三大特性:(了解)
①封装性
封装是把一组数据和与这组数据有关的操作集合组装在一起,形成一个能动的实体,即对象。封装是面向对象的重要特征。首先,它实现了数据隐藏它实现了数据隐藏,保护了对象的数据不被外界随意改变:其次,它使对象成了相对独立的功能模块。
对象像是一个黑匣子,表示对象属性的数据和实现各个操作的代码都被封装在黑匣子里,从外面是看不见的。
C++通过建立类这个数据类型来支持封装性。使用对象时,只需知道它向外界提供的接口,而无须知道它的数据结构细节和实现操作的算法。
②继承性
继承所表达的是类之间相关的关系,这种关系使得对象可以继承另外一类对象的特征和能力。
继承的作用:避免公用代码的重复开发,减少代码和数据冗余。
③多态性
多态是指不同的对象调用相同名称的函数,并可导致完全不同的行为。
相对于学校,基本的物理单位就是教室,教室是教师上课的地方,可是教室没有规定具体哪一个老师才能来上课,对它来说;只提供老师上课的地点,它只知道老师会来这里上课,没有规定具体谁来上。当然,虽然教室没有做硬性规定,学生们也不会担心,因为每个老师都知道自己该怎么上课。像这种情况,教室只要求了一个大工种(教师)的限制,而具体每个老师过来怎么上则由老师自己的具体工种(语文老师还是数学老师)来决定。有了多态之后,在设计软件的时候,就可以从大的方向进行设计,而不必拘泥于细枝末节,因为具体怎么操作都由对象自己负责。
四.C++对C的扩展
1️⃣作用域运算符::
通常情况下,如果有两个同名变量,一个是全局变量,另一个是局部变量,那么局部变量在其作用域内具有较高的优先权,它将屏蔽全局变量。
#include局部变量在其作用域内具有较高的优先权,它将屏蔽全局变量。

借助::操作符,在局部作用域访问全局变量。
#include
作用域运算符可以用来解决局部变量与全局变量的重名问题,即在局部变量的作用域内,可用::对被屏蔽的同名的全局变量进行访问。
:: 操作符用来访问某个作用域里面的成员,上面的例子就是在局部作用域访问全局作用域的成员a。我们C++就有局部域,类域,命名空间域,文件域。
2️⃣C++命名空间(namespace)
①名字控制
创建名字是程序设计过程中一项最基本的活动,当一个项目很大时,它会不可避免地包含大量名字。c++允许我们对名字的产生和名字的可见性进行控制。我们之前在学习c语言可以通过static关键字来使得名字只得在本编译单元内可见,在C++中我们将通过一种通过命名空间来控制对名字的访问。
②为什么有命名空间(namespace)
在c++中,名称(name)可以是符号常量、变量、函数、结构、枚举、类和对象等等,这些变量、函数和类的名称都将作用于全局作用域中,工程越大,名称互相冲突性的可能性越大。另外使用多个厂商的类库时,也可能导致名称冲突。为了避免,在大规模程序的设计中,以及在程序员使用各种各样的C++库时,这些标识符的命名发生冲突,标准C++引入关键字namespace(命名空间/名字空间/名称空间),可以更好地控制标识符的作用域。
⚠️:一个命名空间就定义了一个新的作用域,命名空间中的所有内容都局限于该命名空间,访问命名空间的成员需要使用::操作符。
③命名空间使用语法
//命名空间的关键字是namespace
namespace A{//A是空间的名字,
int a=66;//成员变量
int b=100;
int Add(int a,int b)//成员函数
{
return a+b;
}
}
④命名空间注意事项
1.命名空间只能在全局范围内定义
#include❌示范:
#include
2.命名空间可嵌套定义
#include3.命名空间是开放的,可以随时添加新成员到已有的命名空间中,但是新成员只能在加入后使用
namespace Maker
{
int a;
}
//这个函数定义是错误的,因为成员c,
//还没加入到Maker命名空间,此函数直接使用了
void func()
{
cout<<"c="<<Maker::c<<endl;
}
//加入新成员c
namespace Maker
{
int c;
}
4.匿名命名空间
命名空间还可以定义成匿名的,即创建命名空间时不写名字,由系统自动分配。例如,下面定义的命名空间就是匿名的。
//类似于static int d=50;只能在本文件使用,不希望别的文件使用该变量。
namespace
{
int d = 50;
}
匿名命名空间的作用是限制命名空间的内容仅能被当前源文件使用,其他源文件是无法访问的,使用extern声明访问也是无效的。
拓展:
在C语言中,static关键字的作用如下:
1、在修饰变量的时,static修饰的静态局部变量只执行一次,而且延长了局部变量的生命周期,直到程序运行结束以后才释放。
2、static修饰全局变量的时,这个全局变量只能在本文件中访问,不能在其它文件中访问,即便是extern外部声明也不可以。
3、static修饰一个函数,则这个函数的只能在本文件中调用,不能被其他文件调用。Static修饰的局部变量存放在全局数据区的静态变量区。
5.命名空间可以取别名
namespace Maker
{
int a;
}
void test01()
{
// 新名字 旧名字
namespace nameMaker = Maker;
cout << nameMaker::a << endl;
}
6.分文件编写代码时,如果.h中有两个命名空间,但是里面的成员函数或成员变量同名时,在.cpp中实现函数时,需要加上命名空间,便于区分。
test.h文件
#pragma once
#includetest.cpp
#include "test.h"
void myMaker1::func()//需要在函数名前面加入确定命名空间名字
{
cout << "func" << endl;
}
3️⃣using
①using声明(引入单个名称)
using声明是将命名空间中某个名字单独引入到当前作用域。这使得我们在当前作用域下可以直接使用该名字而无需使用作用域限定符::。
namespace A
{
int a=20;
int b=666;
}
int c=100;
void test01()
{
//using声明A命名空间中的a
//以后再使用a就不需要使用::来访问A命名空间了。
using A::a;
//这个a相当于A::a
cout<<"a="<<a<<endl;
//using声明全局作用域中的c
//以后再使用c就不需要使用::来访问全局作用域了。
using ::c
//这个c相当于::c
cout<<"c="<<c<<endl;
//int a = 50;//注意:using声明了某个变量,在该作用域内不能定义同名的变量
}
②using编译指示(引入整个命名空间)
using指示就是将一个命名空间中的所有名字全部引入到当前作用域(将命名空间在当前作用域展开)。可能会存在命名冲突的问题。
using namespace 你命名空间的名字
//你命名空间中所以成员都直接使用
namespace A
{
int a = 10;
int b = 20;
int c = 30;
}
void test02()
{
//using编译指令,让某个命名空间中的标识符都可以直接使用
using namespace A;
cout << a << endl;
cout << b << endl;
cout << c << endl;
int a = 100;//为什么不会冲突
//类似于命名空中的a是全局变量,这里的a的局部变量
cout << "a=" << a << endl;
}
例如:using namespace std;
C++标准程序库中的所有标识符都被定义于一个名为std的namespace中,使用using指示后,std命名空间中的所以标识符都可以被直接使用。例如cout,cin。如果没有using指令,我们写的代码就要变成std::cout,std::cin,std::endl。
⚠️注意:
①使用using声明或using编译指令会增加命名冲突的可能性。也就是说,如果有命名空间,并在代码中使用作用域解析运算符,则不会出现二义性。
②using声明和using编译指示都有作用域,using声明和编译指示只在其被声明的语向块内有效(一个语句块是指在一对花括号 {}内的一组指令)。如果是在全局范围内被声明的,则在所有代码中都有效。
4️⃣struct 类型的加强
c中定义结构体变量需要加上struct关键字,c++不需要。
c中的结构体只能定义成员变量,不能定义成员函数。c++即可以定义成员变量,也可以定义成员函数。
☯️:
#include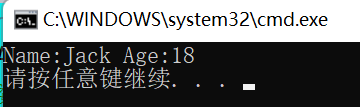
5️⃣更严格的类型转换
类型转换(cast)是将一种数据类型转换成另一种数据类型。例如,如果将一个整型值赋给一个浮点类型的变量,编译器会暗地里将其转换成浮点类型。
转换是非常有用的,但是它也会带来一些问题,比如在转换指针时,我们很可能将其转换成一个比它更大的类型,但这可能会破坏其他的数据。C语言中的类型转换运算符太过松散。
标准C++提供了一个显示的转换的语法,来替代旧的C风格的类型转换。使用C风格的强制转换可以把想要的任何东西转换成我们需要的类型。那为什么还需要一个新的C++类型的强制转换呢 ?新类型的强制转换可以提供更好的控制强制转换过程,允许控制各种不同种类的强制转换。
C++风格的强制转换其他的好处是,它们能更清晰的表明它们要干什么。程序员只要扫一眼这样的代码,就能立即知道一个强制转换的目的。
C++添加4个类型转换运算符,使转换过程更规范:
- static cast 静态转换
- dynamic cast 动态转换
- const cast 常量转换
- reinterpret_cast 重新解释转换
这四种转换将在后续讲到。
6️⃣三目操作符功能加强
左值和右值概念:
在c++中可以放在赋值操作符左边的是左值,可以放到赋值操作符右面的是右值。有些变量即可以当左值,也可以当右值。
左值为Lvalue,L代表Location,表示内存可以寻址,可以赋值。
右值为Rvalue,R代表Read,就是可以知道它的值。
①C语言三目运算表达式返回值为数据值,为右值,不能赋值。
验证:
#include②C++语言三目运算表达式返回值为变量本身(引用),为左值,可以赋值。
验证:
#include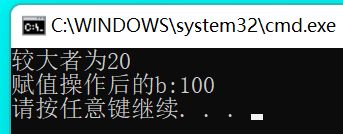
7️⃣C/C++中const的区别
①C中的const
C中const修饰的变量是只读变量,在使用const关键字声明定义变量时会给该变量分配内存空间,所以C语言的const修饰的变量都有空间。
const修饰的全局变量默认是外部链接的,即其它源文件可以直接使用该变量。
const修饰的局部变量存储在栈区中,不能通过变量名直接修改该变量的值,但是可以通过指针的方式修改该变量对应的值,从某种意义上来说,C中const修饰的变量不是真正意义上的常量,可以将其当作一种只读变量。
验证:
C语言的全局变量用const修饰,不能直接修改,也不能间接修改。
本质: C语言const修饰的全局变量,会被存储到只读数据段,受到只读数据段的保护不能修改,即C语言const修饰的全局变量有空间。
#include
C语言的局部变量用const修饰,不能直接修改,但可以通过指针间接修改。
本质:
C语言言中局部const存储在堆栈区,只是不能通过变量直接修改const只读变量的值,但是可以跳过编译器的检查,通过指针间接修改const值。
int main()
{
const int a=100;//在栈区
//a=1000;不能被修改
int* p = (int*)&a;//可以通过指针间接修改
*p = 200;
return 0;
}
C语言中的const修饰全局变量还是局部变量,const都有空间,一个在常量区,一个在栈区。
验证2:
C语言的全局变量具有外部链接属性。
在test1.c定义一个const修饰的全局变量
const int a=666;
在test2.c文件进行访问
#include
②C++中的const
C++中定义声明的全局常量是内部链接的,只能作用于当前的整个文件中,如果想让其它源文件对该常量进行访问的,必须加extern关键字将该常量转换成外部链接。
C++语言的const修饰的变量有时有空间,有时没有空间(发生常量折叠,且没有对变量进行取址操作)
在c++中,是否为const常量分配内存空间依赖于如何使用。一般说来,如果一个const仅仅用来把一个名字用一个值代替(就像使用#define一样),那么该存储空间就不必创建。
♒️C++中const变量不分配空间情况:
C++对于基础数据类型(整数、浮点数、字符),编译器不会给const变量分配空间,编译器会进行优化,比如定义常量const int data = 10;,C++会在一张符号表中添加name为data,value为10的一条记录,如下图所示:在编译阶段,编译器会自动将value替换成10,这种操作也叫做常量折叠。
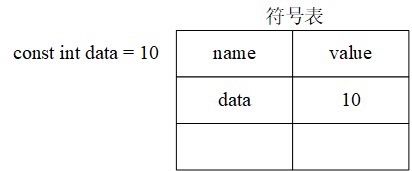 既然,const修饰的变量没有内存空间,所以在C++中const修饰的变量才是真正意义上的常量。
既然,const修饰的变量没有内存空间,所以在C++中const修饰的变量才是真正意义上的常量。
♒️C++中const变量分配空间的情况:
1.C++中当对const变量取地址的时候系统就会给它开辟空间。
2.当用变量给const变量赋值时,系统直接为其开辟空间 而不会把它放入符号表中。
3.const 自定义数据类型(结构体、对象) 和数组系统会分配空间。
验证:
在fun.cpp文件中创建num:
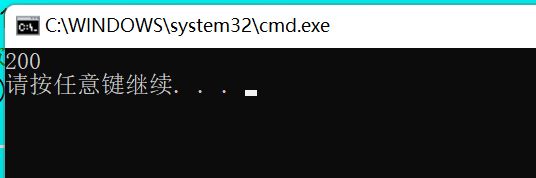
extern const int num = 200;//是没有外部链接属性的
//如果加上extern就具有外部链接属性。
在test.cpp引用num:
#include 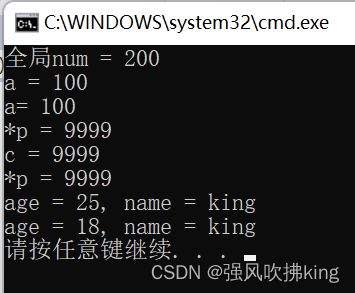
那我们思考一个问题,为什么c修改成功而a没修改成功?
#include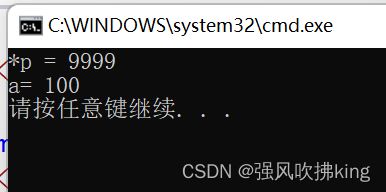
究其原因就是而C++对于const修饰基础类型的变量是在符号表中添加一条记录,不会在栈中开辟空间,所以不能通过指针的方式修改变量的值。
即使后面进行了取地址,有了空间编译器还是会进行替换优化。先放入符号表在前,分配空间在后。
解决方法:
让编译器不优化,在const变量前加volatile。
#include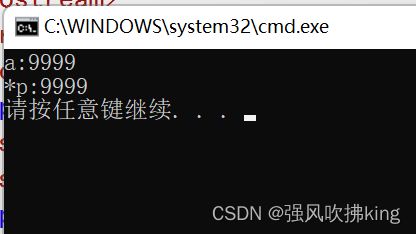
8️⃣引用(reference)
引用是c++对c的重要扩充。在c/c++中指针的作用基本都是一样的,但是c++增加了另外一种给函数传递地址的途径,这就是按引用传递(pass-by-reference),它也存在于其他一些编程语言中,并不是c++的发明。
①引用是做什么的?
和C语言指针一样的功能,但语法更简洁,引用就是给空间取别名。
基本语法:

习惯使用C语言开发的读者看到“&”符号就会想到取地址。但是在C++引用中,“&”只是起到标识的作用。
举例:
#include
引用在函数中用途也很广泛。
通过形参修改实参。
举例:交换ab的值
#include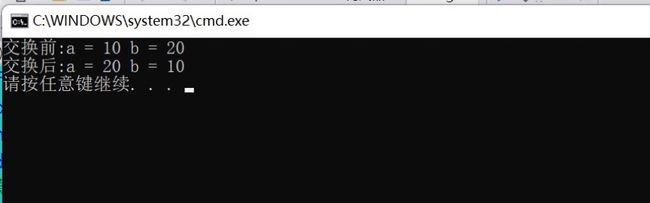
②引用的注意事项
- &符号前面有数据类型时,是引用。其他均为取地址。
int &b = s;//&标识作用
cout<<&b<<endl;//这是取地址
- 类型标识符是指目标变量的类型
- 必须在声明引用变量时进行初始化。
Type& ref = val; val必须要有,你给空间起别名,首先要有空间
- 引用初始化之后不能改变。 不能有NULL引用。
int a = 10;
int b = 20;
int& ref = a;
ref = b; //不能改变引用
- 必须确保引用是和一块合法的存储单元关联。
③建立对数组的引用。
1.建立数组引用方法一,重命名数组类型
数组类型就是你把你命名的那个变量名去掉就是类型,int arr[5]的类型就是把arr去掉,就是int [5]
#include
2. 建立数组引用方法二,直接用数组类型。
#include
④引用的本质:
引用的本质在C++内部实现是一个常指针.
例如:
Type& ref = val; // Type* const ref = &val;
c++编译器在编译过程中使用常指针作为引用的内部实现,因此引用所占用的空间大小与指针相同,只是这个过程是编译器内部实现,用户不可见。
举例:
int a = 10;
int& aRef = a;
//自动转换为int* const aRef = &a;
//这也能说明引用为什么必须初始化
aRef = 20;
//内部发现aRef是引用,自动帮我们转换为: *aRef = 20;
引用是隐式的指针,但引用却不等同于指针,使用引用与使用指针有着本质的区别。
- 指针指向一个变量,需要占据额外的内存单元,而引用指向一个变量,不占据额外内存单元。
- 作为函数参数时,指针的实参是变量的地址,而引用的实参是变量本身,但系统向引用传递的是变量的地址而不是变量的值。
⑤指针的引用:
1.指针的引用是给存储指针变量这块空间取别名。
int main()
{
char* p="强风吹拂king";
//p的类型是char*,
//所以我们引用时类型就是char*
char* &p1=p;
//就是将存储p指针的空间起了个别名叫p1
cout<<p1<<endl;
return 0;
}
为什么不是输出字符串的首地址?
按道理此时会输出字符串的首地址,但是cout会直接将字符串输出,而不是字符串的首地址,而在c语言中printf(“%p”,p);就会输出字符串数组的首地址,printf(“%s”,p);则会输出字符串。
2.在C语言中,如果我们想改变指针本身,也就是改变指针指向的对象,(注意是对象,不是指针指向对象中的内容)我们需要对指针进行取地址操作,然后用二级指针接收。
如果要借用函数实现的话:
void fun(int**p1);
如果用C++表示
void fun(int* &p1)
⑥常量的引用
常量引用的定义格式:
const Type& ref = val;
如果想使用常量值初始化引用,则引用必须用const修饰,用const修饰的引用称为const引用,也称为常引用。
常量引用注意:
- 字面量不能赋给引用,但是可以赋给const修饰的引用。
- const修饰的引用,不能修改。
示例代码如下所示:
void test01()
{
int a = 100;
const int& aRef = a; //此时aRef就是a
//aRef = 200; 不能通过aRef的值
a = 100; //OK
cout << "a:" << a << endl;cout << "aRef:" << aRef << endl;
}
void test02()
{
//不能把一个字面量赋给引用
//int& ref = 100;
//但是可以把一个字面量赋给常引用
const int& ref = 100; //int temp = 200; const int& ret = temp;
}

常量引用主要用在函数的形参,尤其是类的拷贝/复制构造函数。
将函数的形参定义为常量引用的好处:
- 引用不产生新的变量,减少形参与实参传递时的开销。
- 由于引用可能导致实参随形参改变而改变,将其定义为常量引用可以消除这种副作用。
- 如果希望实参随着形参的改变而改变,那么使用一般的引用,如果不希望实参随着形参改变,那么使用常引用。
当引用作函数参数时,也可以使用const修饰,表示不能在函数内部修改参数的值。例如下面的函数,比较两个字符串长度:
//const string &s1, const string &s2防止函数中意外修改数据
bool isLonger(const string &s1, const string &s2)
{
return s1.size() > s2.size();
}
在isLonger()函数中,只能比较两个字符串长度而不能改变字符串内容。
⑦引用的使用场景
最常见看见引用的地方是在函数参数和返回值中。当引用被用作函数参数的时,在函数内对任何引用的修改,将对还函数外的参数产生改变。当然,可以通过传递一个指针来做相同的事情,但引用具有更清晰的语法。
如果从函数中返回一个引用,必须像从函数中返回一个指针一样对待。当函数返回值时,引用关联的内存一定要存在。
//值传递
void ValueSwap(int m, int n){
int temp = m;
m = n;
n = temp;
}
//地址传递
void PointerSwap(int* m, int* n){
int temp = *m;
*m = *n;
*n = temp;
}
//引用传递
void ReferenceSwap(int& m, int& n){
int temp = m;
m = n;
n = temp;
}
void test(){
int a = 10;
int b = 20;
//值传递
ValueSwap(a, b);
cout << "a:" << a << " b:" << b << endl;
//地址传递
PointerSwap(&a, &b);
cout << "a:" << a << " b:" << b << endl;
//引用传递
ReferenceSwap(a, b);
cout << "a:" << a << " b:" << b << endl;
}

通过引用参数产生的效果同按地址传递是一样的。引用的语法更清楚简单:
- 函数调用时传递的实参不必加“&”符
- 在被调函数中不必在参数前加“*”符
引用作为其它变量的别名而存在,因此在一些场合可以代替指针。C++主张用引用传递取代地址传递的方式,因为引用语法容易且不易出错。
//返回局部变量引用
int& TestFun01(){
int a = 10; //局部变量
return a;
}
//返回静态变量引用
int& TestFunc02(){
static int a = 20;
cout << "static int a : " << a << endl;
return a;
}
int main(){
//不能返回局部变量的引用
int& ret01 = TestFun01();
//如果函数做左值,那么必须返回引用
TestFunc02();
TestFunc02() = 100;
TestFunc02();
return 0;
}
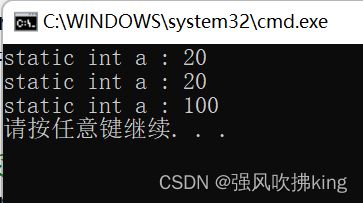
- 不能返回局部变量的引用。
- 函数当左值,必须返回引用。
9️⃣宏(#define)的优缺点和解决办法
①宏常量
例如:
#define PI 3.14
优点:
1.牵一发而动全身,一改全改
2.降低出错率
3.提高了程序的可读性
缺点:
1.在旧版本C中,如果想建立一个常量有两种方法:
#define MAX 1024;
const int max = 1024
我们定义的宏MAX从未被编译器看到过,因为在预处理阶段,所有的MAX已经被替换为了1024,于是MAX并没有将其加入到符号表中。但我们使用这个常量获得一个编译错误信息时,可能会带来一些困惑,因为这个信息可能会提到1024,但是并没有提到MAX.如果MAX被定义在一个不是你写的头文件中,你可能并不知道1024代表什么,也许解决这个问题要花费很长时间。解决办法就是用一个常量替换上面的宏。
const int max= 1024;
2.#define无类型,不可进行类型检查.
#define MA 128
void func(short a)
{
cout << "func(short a)" << endl;
}
void func(int a)
{
cout << "func(int a)" << endl;
}
int main()
{
func(MA);
system("pause");
return 0;
}
#define没有类型,不进行安全检查。
解决方法:
尽量以const替换#define,const有类型,可进行编译器类型安全检查。
3.#define不重视作用域,默认定义处到文件结尾.如果定义在指定作用域下有效的常量,那么#define就不能用。
#define b=100;
void func()
{
cout<<"b="<<b<<endl;
}
int main()
{
cout<<"b="<<b<<endl;
func();
return 0;
}
b在任意一个作用域都可以访问。
解决方法:尽量以const替换#define,
②宏函数
在C语言中我们经常把一些短并且执行频繁的计算写成宏,而不是函数,这样做的理由是为了执行效率,宏可以避免函数调用的开销,这些都由预处理来完成。
优点:
1.不是函数,少了函数调用,提高程序运行效率
2.少写代码:因为宏函数是多条语句的封装注意:
不能提高代码复用率,因为宏函数在预处理阶段就展开了
3.可以提高代码的可读性
缺点:
1.在预处理阶段被替换,不会进行类型检测,代码安全性低
2.在预处理阶段展开–>不能调试
3.每个使用部分都会展开---->造成代码膨胀
4.容易出错,每个部分需要加括号
5.宏函数存在很多问题,边界效应,是举例
问题①:
#define ADD(x,y) x+y
inline int Add(int x, int y)
{
return x + y;
}
void test01()
{
int ret1 = ADD(10, 20) * 10; //希望的结果是300
cout << "ret1:" << ret1 << endl; //210
}

问题②:
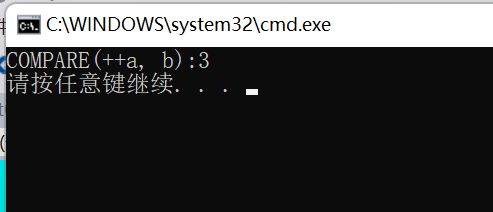
#define COMPARE(x,y) ((x) < (y) ? (x) : (y))
inline int Compare(int x, int y)
{
return x < y ? x : y;
}
void test02()
{
int a = 1;
int b = 3;
cout << "COMPARE(++a, b):" << COMPARE(++a, b) << endl; // 3
}
问题③:
预定义宏函数没有作用域概念,无法作为一个类的成员函数,也就是说预定义宏没有办法表示类的范围。
C++中的解决方法:
使用内联函数。
内联函数
为了保持预处理宏的效率又增加安全性,而且还能像一般成员函数那样可以在类里访问自如,c++引入了内联函数(inline function).
内联函数为了继承宏函数的效率,没有函数调用时开销,
然后又可以像普通函数那样,可以进行参数、返回值类型
的安全检查,又可以作为成员函数。
使用方法:
普通函数(非成员函数)函数前面加上inline关键字使之成为内联函数。但是必须注意必须函数体和声明结合在一起,否则编译器将它作为普通函数来对待。
inline void func(int a);以上写法没有任何效果,仅仅是声明函数,应该如下方式来做:
inline int func(int a)
{
//语句必须简单
//内联函数是以空间换时间
}
内联函数的确占用空间,但是内联函数相对于普通函数的优势只是省去了函数调用时候的压栈,跳转,返回的开销。我们可以理解为内联函数是以空间换时间。
②使用内联函数解决宏函数的缺陷
#include 
③限制条件:
但是c++内联编译会有一些限制,以下情况编译器可能考虑不会将函数进行内联编译:
1.不能存在任何形式的循环语句
2.不能存在过多的条件判断语句函数体
3.不能过于庞大
4.不能对函数进行取址操作
内联仅仅只是给编译器一个建议,编译器不一定会接受这种建议,如果你没有将函数声明为内联函数,那么编译器也可能将此函数做内联编译。一个好的编译器将会内联小的、简单的函数。
1️⃣函数的默认参数和占位参数
①默认参数
C++在声明函数原型的时可为一个或者多个参数指定默认(缺省)的参数值,当函数调用的时候如果实参没有指定这个值,编译器会自动用默认值代替。
例如:
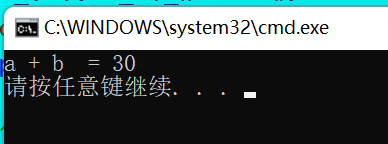
void Test01(int a = 10, int b = 20)
{//int a = 10, int b = 20就是默认参数。
//当函数调用的时候如果实参没有指定这个值,
//编译器会自动用默认值代替。
cout << "a + b = " << a + b << endl;
}
int main()
{
Test01();
//实参什么都没传,编译器使用默认参数
}
注意事项:
1.函数的默认参数从左向右,如果一个参数设置了默认参数,那么这个参数之后的参数都必须设置默认参数。
例如:
//这是❌的
void Test01(int a = 10, int b,intc)
//参数a后面必须都是默认参数
void Test01(int a = 10, int b=100,int c=155)
//✔️
2.如果函数声明和函数定义分开写,函数声明和函数定义不能同时设置默认参数。
TestFunc03(int a = 0,int b = 0);
//函数定义无需在设置默认参数。
void TestFunc03(int a, int b)
{
}
②占位参数
C++在声明函数时,可以设置占位参数。**占位参数只有参数类型声明,而没有参数名声明。**一般情况下,在函数体内部无法使用占位参数。
void TestFunc01(int a,int b,int)
{//函数内部无法使用占位参数
cout << "a + b = " << a + b << endl;
}//占位参数也可以设置默认值
void TestFunc02(int a, int b, int = 20)
{//函数内部依旧无法使用占位参数
cout << "a + b = " << a + b << endl;
}
int main()
{
//错误调用,占位参数也是参数,必须传参数
//TestFunc01(10,20);
//正确调用
TestFunc01(10,20,30);
//正确调用,占位参数有默认值,第三个参数可传可不传
TestFunc02(10,20);
//正确调用
TestFunc02(10, 20, 30);
return 0;
}
2️⃣函数重载
在传统C语言中,函数名必须是唯一的,程序中不允许出现同名的函数。在C++中是允许出现同名的函数,这种现象称为函数重载。函数重载的目的就是为了方便的使用函数名。
①函数重载的基本语法
实现函数重载的条件:
1.同一个作用域下
2.函数名必须相同
3.函数的参数类型不同或者个数不同或者顺序不同
C++的这种编程机制给编程者极大的方便,不需要为功能相似、参数不同的函数选用不同的函数名,也增强了程序的可读性。
:
//参数的个数不同
void func()
{
cout << "func()" << endl;
}
void func(int a)
{
cout << "func(int a)" << endl;
}
//参数的类型不同
void func(char c)
{
cout << "func(char c)" << endl;
}
//参数的顺序不同
void func(int a, double b)
{
cout << "func(int a, double b)" << endl;
}
void func(double b, int a)
{
cout << "func(double b, int a)" << endl;
}
void test01()
{
int a = 100;
double b = 3.14;
func();//调用没有参数的那个func函数
//func(b);错误,double转换不到int
func(a, b);//调用void func(int a, double b)函数
func(b, a);//调用void func(double b, int a)函数
char c = 'a';
func(c);//注意:字符可以转换为int类型
//如果没有void func(char c),func(c)
//就会调用func(int a)
}
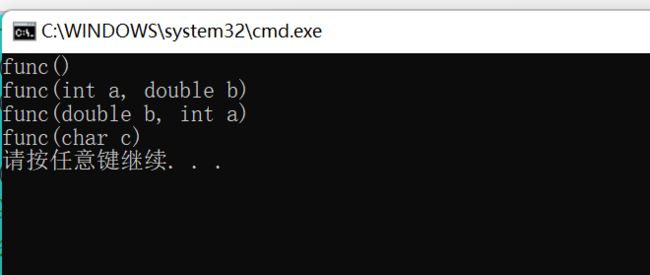
②函数重载和函数的默认参数一起使用,需要注意二义性问题。
//函数重载和函的默认参数一起使用
void myfunc(int a, int b = 0)
{
cout << "myfunc(int a, int b = 0)" << endl;
}
void myfunc(int a)
{
cout << "myfunc(int a)" << endl;
}
void test02()
{
//myfunc(10); err,二义性问题,不知道调用哪个函数
}
思考:为什么函数返回值不作为重载条件呢?
当编译器能从上下文中确定唯一的函数的时,如int ret = func(),这个当然是没有问题的。然而,我们在编写程序过程中可以忽略他的返回值。那么这个时候,假如一个函数为void func(int x);另一个为int func(int x); 当我们直接调用func(10),这个时候编译器就不确定调用那个函数。所以在c++中禁止使用返回值作为重载的条件。
③函数重载实现原理
编译器为了实现函数重载,也是默认为我们做了一些幕后的工作,编译器用不同的参数类型来修饰不同的函数名,比如void func(); 编译器可能会将函数名修饰成_func,当编译器碰到void func(int x),编译器可能将函数名修饰为func_int,当编译器碰到void func(int x,char c),编译器可能会将函数名修饰为_func_int_char我这里使用”可能”这个字眼是因为编译器如何修饰重载的函数名称并没有一个统一的标准,所以不同的编译器可能会产生不同的内部名。
1️⃣3️⃣new/delete
C++增加了new运算符分配堆内存,delete运算符释放堆内存。具体用法如下。
使用new运算符分配堆内存new运算符用于申请一块连续的内存,格式如下:

上述格式中,数据类型表示申请的内存空间要存储数据的类型;初始化列表指的是要存储的数据。如果暂时不存储数据,初始化列表可以为空,或者数据类型后面直接没有()。
如果内存申请成功,则new返回一个具体类型的指针;如果内存申请失败,则new返回NULL。new申请内存空间的过程,通常称为new一个对象。
与C语言的malloc()相比,new创建动态对象时不必为对象命名,直接指定数据类型即可,并且new能够根据初始化列表中的值进行初始化。下面介绍new运算符常见的几种用法。
(1)new创建基本数据类型对象
使用new创建基本数据类型对象,示例代码如下所示
char* pc = new char;//存储char类型的数据 
int* pi = new int(10);//存储int类型的数据 
double* pd = new double();//存储double类型的数据
上述代码分别用new创建了char、int、double三个对象。其中,char对象没有初始化列表,新分配内存中没有初始值;int对象初始化列表为10,即分配一块内存空间,并把10存入该空间;double对象初始化列表为空,编译器会用0初始化该对象。
(2)创建数组类型对象
使用new创建数组对象,格式如下所示:
 使用new创建数组的示例代码如下所示:
使用new创建数组的示例代码如下所示:
char* pc = new char[10];
在上述代码中,指针pc指向大小为10的char类型数组。
使用delete运算符释放堆内存
用new运算符分配的内存在使用后要及时释放以免造成内存泄漏,C++提供了delete运算符释放new出来的内存空间,格式如下:
delete 指针名;
由上述格式可知,delete运算符直接作用于指针就可以释放指针所指向的内存空间。但是使用delete运算符释放数组对象时要在指针名前加上[],格式如下:
delete[]指针名;
如果漏掉了[],编译器在编译时无法发现错误,导致内存泄漏。