AlexNet
论文信息
论文名称:ImageNet Classification with Deep Convolutional Neural Networks
论文别名:AlexNet
发表期刊:NIPS
论文地址:
https://www.cin.ufpe.br/~rmd2/ImageNet%20classification%20wth%20deep%20convolutional%20neural%20networks.pdf
摘要

精简翻译和总结
作者训练了一个大的、深的卷积神经网络来对1200万张高分辨率图像进行分类,这些图片是2010年ILSVRC比赛的图片,总共分为1000个类别。在测试数据上,top-1和top-5错误率分别为37.5%和17%,比现有的SOTA(state-of-the-art)结果还有优越。神经网络总购有6000万参数以及65万个神经元,包含5个卷积层,其中一些卷积层后面跟着最大池化层,包含3个全连接层和一个1000维的softmax。为了使得训练更快,作者使用了非饱和的神经元(ReLU)和一个非常高效的GPU来实现卷积操作,为了减轻全连接层的过拟合,作者使用了一个最近才发布的正则化方法Dropout,并被证明是十分有效的。作者还在2012年的ILSVRC比赛中使用了一个该模型的变种,并且结果比第二名要好很多
批注
SOTA:( state-of-the-art )最佳结果
ILSVRC:the ImageNet Large-Scale Visual Recognition Challenge
ReLU:(Rectified Linear Unit) , 非饱和激活函数, f ( x ) = m a x ( 0 , x ) f(x)=max(0,x) f(x)=max(0,x)
top-1和top-5:top-1 就是使用预测结果和正确结果进行对比,如果相同则表示预测正确,top-5 就是使用预测结果的.top-5(分类结果标签的前五个)与正确结果进行对比,如果五个之中有一个正确那么就认为分类器预测结果正确。
ImageNet:华裔科学家李飞飞牵头构建的数据集
1.引言
1.1 指出问题和可改进方向

现有的目标识别方法大量采用了机器学习方法 ,为了提升他们的性能,可以考虑收集更大的数据集,训练更强大的模型或者使用更好的技术来防止过拟合。迄今为止,数据集的规模仍然是非常小的。简单的分类任务如可以在小规模数据集上表现很好,但是物体在现实世界中存在相当大的可变性,所以想要识别他们必须采用更大的数据集来学习他们的共性的特征。

为了能够在1200万张图像中学得数千个类别,我们需要具有强大学习能力的模型。物体识别任务的复杂性意味着你不可能把每一个类别的数据集都构建得和ImageNet 一样大,因此模型需要获得先验知识来弥补这方面的不足。CNN的识别能力与他的深度和宽度有着很大的关系。与标准的前馈神经网络相比,CNNs的连接和参数量比较少,容易训练。

尽管它性能好,但是在2012年的时候训练这样一个网络是非常昂贵的,比较幸运的是当时的GPU已经可以进行2D的卷积运算,减轻了训练的难度,并且ImageNet数据集足够大不会发生严重的过拟合。
1.2本文贡献

① 使用了ImageNet的子集,训练了当时最大的网络之一,并运用在了2010年和2012年的比赛中,并获得了最好的结果。
② 实现了2D的GPU卷积运算,并运用在了网络的训练中,我们将它开源了。(从我的视角来看,这个相当牛逼)
③网络使用到了许多新的不常规的特征来提升性能,减少训练时间
④ 重点研究过拟合问题,并使用了几个技术来解决过拟合
⑤最终网络包含5个卷积层,三个全连接层,并且作者认为深度是非常重要的,移除任何一个卷积层会降低性能。
1.3 批注
CNN:convolutional neural networks
2.数据集

使用ImageNet 的子集,包含1200万张训练图片,5万张验证图片和15万张测试图片(有个很奇怪的现象,在随后的七八年,构建了很多更大的数据集,但是只有训练集和测试集,验证集消失了,不知道是不是数据集足够大,测试集数据可以近似等价与现实中的数据分布,所以不很出现过拟合和泛化性能下降问题,所以不需要验证集了,当然这仅是我个人的猜测)
ImageNet 包含不同分辨率的图片(其实也就是大小不同的意思),作者把图像的短边缩放到256,然后根据中心点进行裁剪,得到256x256的图片。此外没有对图像再做其他任何的预处理。
2.1 批注
ImageNet数据集的均值和方差为:mean=(0.485, 0.456, 0.406),std=(0.229, 0.224, 0.225),在之后出现的很多卷积神经网络的训练过程中很多都用到了这个值,当然它的结果并不一定会很好。
3.模型结构
作者根据相关部分的重要性进行先后的叙述。
3.1 ReLU
使用了新的非饱和激活函数ReLU,可以加速模型的收敛,减少模型的训练时间
3.2 多GPU分布式训练
随着GPU的发展,现在AlexNet不需要多GPU训练了,但是这个分布式训练的方法可以用在其他大型网络的训练中,比如GPT
3.3 Local Response Normalization(LRN 局部响应归一化)
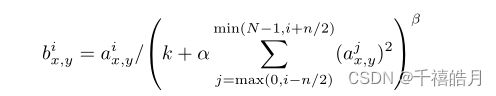
a x , y i a_{x,y}^i ax,yi是第 i i i个卷积核在 ( x , y ) (x,y) (x,y)位置计算,并经过激活函数后得到的值, b x , y i b_{x,y}^i bx,yi通过那个复杂的公式得到,这个求和作用在 n n n个近邻核的相同空间位置上, N N N是这一层卷积核的数量,假设作用在AlexNet的第一层,那么卷积核的个数 N N N为96。其中 k = 2 , n = 5 , a = 1 0 − 4 , β = 0.75 k=2,n=5,a=10^{-4},\beta=0.75 k=2,n=5,a=10−4,β=0.75,把值带入公式后,你会发现公式变得简单了很多,变量只有 i , j i,j i,j,再结合下面这张图你就明白了
b x , y i = a x , y i / ( 2 + 1 0 − 4 ∑ j = m a x ( 0 , i − 5 / 2 ) m i n ( 95 , i + 5 / 2 ) ( a x , y j ) 2 ) 0.75 b_{x,y}^i =a_{x,y}^i /(2+10^{-4}\sum_{j=max(0,i-5/2)}^{min(95,i+5/2)} (a_{x,y}^j)^2)^{0.75 } bx,yi=ax,yi/(2+10−4j=max(0,i−5/2)∑min(95,i+5/2)(ax,yj)2)0.75
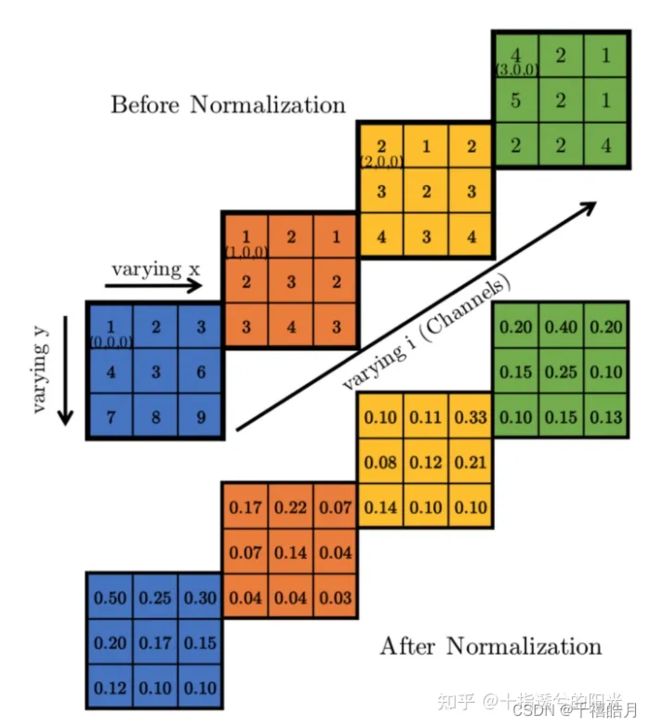
n = 5 {n=5} n=5表示当我们在对一个元素进行归一化的时候,只考虑到沿channel维度上(也就是一维的情况),这个元素的前两个元素和后两个元素。这意味着,我们在计算{(i,x,y)}这个点归一化后的值时,只需要考虑 ( i − 2 , x , y ),( i − 1 , x , y ),( i , x , y ) , ( i + 1 , x , y ) , ( i + 2 , x , y ) {(i-2,x,y),(i-1,x,y),(i,x,y),(i+1,x,y),(i+2,x,y)} (i−2,x,y),(i−1,x,y),(i,x,y),(i+1,x,y),(i+2,x,y)的值即可,如果超过边界则默认为0。
3.4 重叠池化
一般情况下池化的步长stride和filter过滤器的大小是相等的,但在本文中,stride为2,filter过滤器的边长是3
3.5 模型总体结构

3.5.1 卷积层输出特征图的计算公式
O = I − K + 2 P S + 1 O=\frac{I-K+2P}{S}+1 O=SI−K+2P+1
3.5.2 模型详解
| layer name | kernel size | kernel num | stride | padding | input size | output size | information |
|---|---|---|---|---|---|---|---|
| Conv1 | 11x11x3 | 48x( 2 G P U ) 2_{GPU}) 2GPU)=96 | 4 | 2 | 224x224x3 | 55x55x96 | 后面先接ReLU 然后接LRN |
| Pool1 | 3x3 | / | 2 | / | 55x55x96 | 27x27x96 | |
| Conv2 | 5x5x96 | 128x( 2 G P U ) 2_{GPU}) 2GPU)=256 | 1 | 2 | 27x27x96 | 27x27x256 | 后面先接ReLU 然后接LRN |
| Pool2 | 3x3 | / | 2 | / | 27x27x256 | 13x13x256 | |
| Conv3 | 3x3x256 | 192x( 2 G P U ) 2_{GPU}) 2GPU)=384 | 1 | 2 | 13x13x256 | 13x13x384 | 后面接ReLU |
| Conv4 | 3x3x384 | 192x( 2 G P U ) 2_{GPU}) 2GPU)=384 | 1 | 2 | 13x13x384 | 13x13x384 | 后面接ReLU |
| Conv5 | 3x3x384 | 128x( 2 G P U ) 2_{GPU}) 2GPU)=256 | 1 | 2 | 13x13x384 | 13x13x256 | 后面接ReLU |
| Pool3 | 3x3 | / | 2 | / | 13x13x256 | 6x6x256 | 后面接Dropout |
| FC1 | / | / | / | / | 6x6x256 | 4096 | 后面先ReLU,再接Dropout |
| FC2 | / | / | / | / | 4096 | 4096 | 后面接ReLU |
| FC3 | / | / | / | / | 4096 | 1000 | 后面接Softmax,训练阶段Softmax是隐藏在损失函数里实现的 |
3.6 批注
这里需要注意的是归一化层是分别接在第一个和第二个卷积层之后的,最大池化层是接在第一个和第二个归一化层之后以及第五个卷积层之后的。ReLU 接在每一个卷积层之后以及全连接层之后。ReLU是在归一化之前的,卷积核的维度等于输入特征图的通道数,卷积核的个数等于输出特征图的通道数。
4. 数据增强
4.1 数据增强
4.1.1 方法一

第一种方法是对生成图像以及水平的翻转。从256x256的图像中取出224x224大小的图像,这使得训练集的大小增大了2048倍,虽然数据是独立的,但是没有这个操作的话,我们的网络会过拟合。在测试阶段,我们从256x256的图像中选取了4个边角位置,1个中心位置的224x224的patch,并进行水平翻转,这样就得到了10个patch,将它们送入网络进行预测,并计算平均值。
4.1.2 方法二


在整个ImageNet训练集中对RGB像素值集执行PCA。PCA(主成分分析),PCA 颜色增强的大概含义是,比如说,如果你的图片呈现紫色,即主要含有红色和蓝色,绿色很少,然后 PCA 颜色增强算法就会对红色和蓝色增减很多,绿色变化相对少一点。顾名思义就是对主要的成分起作用。
https://www.codenong.com/78de8ccd09dd2998ddfc/(PCA数据增强)
https://blog.csdn.net/CSDNJERRYYAO/article/details/120068107(PCA数据增强)
https://www.cnblogs.com/zhangleo/p/16076052.html(PCA数据增强)
4.2 Dropout
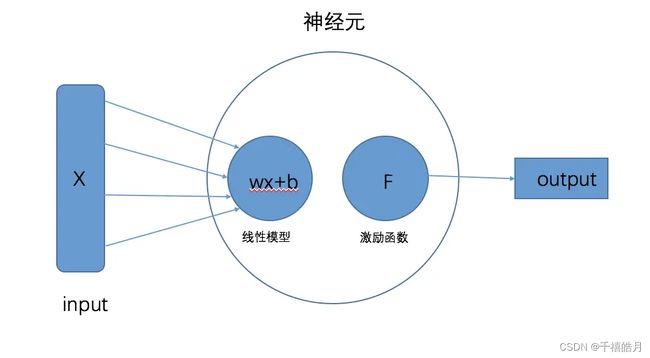
4.2.1 神经元的概念
一个完整的神经元有两部分组成,一部分是线性函数,还有一部分是激活函数。
4.2.2 感受野
感受野的定义是:卷积神经网络每一层输出的特征图(feature map)上的像素点在原始图像上映射的区域大小。
4.2.2.1 从前向后计算感受野的公式:
l 0 = 1 , S 0 = 1 l 1 = K 1 l k = l k − 1 + f k − 1 ∗ ∏ i = 0 k − 1 ∗ S i , k ≥ 2 l_0=1,S_0=1\\ l_1=K_1\\ l_k=l_{k-1}+f_k-1*\prod_{i=0}^{k-1}*S_i , k\ge2 l0=1,S0=1l1=K1lk=lk−1+fk−1∗i=0∏k−1∗Si,k≥2
其中, l k l_k lk:表示第k层的感受野, l k − 1 l_{k-1} lk−1:表示第 k − 1 {k-1} k−1层的感受野, f k f_k fk:表示第k层卷积核的大小, S i S_i Si:表示第 i i i层的步长, K 1 {K_1} K1第一层的卷积核大小
4.2.2.2 从后向前计算感受野的公式:
F ( 0 ) = K f i n a l F ( i ) = ( F ( i + 1 ) − 1 ) ∗ S t r i d e + K F(0)=K_{final}\\ F(i)=(F(i+1)-1)*Stride+K F(0)=KfinalF(i)=(F(i+1)−1)∗Stride+K
其中 F ( i ) F(i) F(i)表示第 i i i层的感受野, F ( i + 1 ) F(i+1) F(i+1)表示第 i + 1 {i+1} i+1层的感受野, S t r i d e Stride Stride表示步长, K K K卷积核大小, K f i n a l K_{final} Kfinal最后一层卷积核的大小。
4.2.2.3 举例
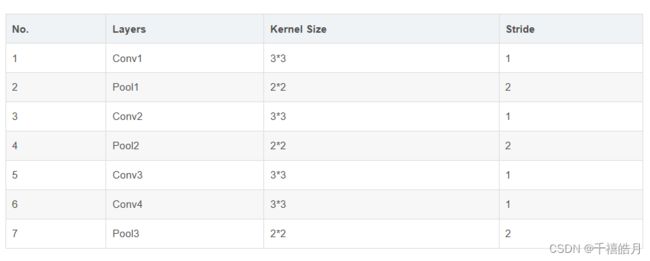
则从前往后计算的结果为:

从后向前计算的结果为:
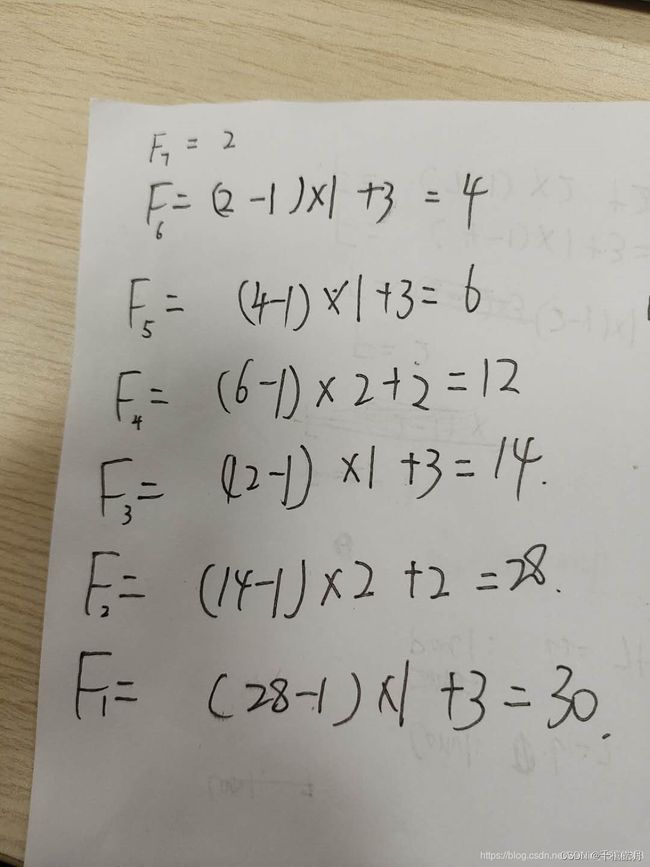
4.2.2.4 批注
使用堆叠的3x3卷积核的感受野大小等价与使用一个7x7的感受野大小,但是在这种情况下堆叠的3x3卷积核的参数更少。
4.2.3 局部连接和权值共享
权值共享
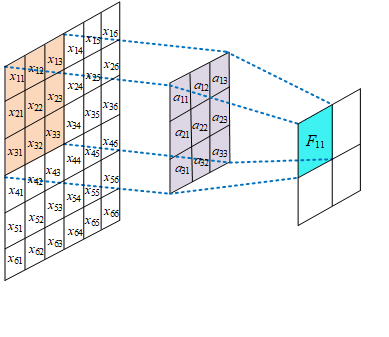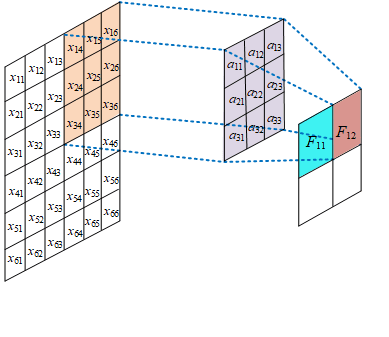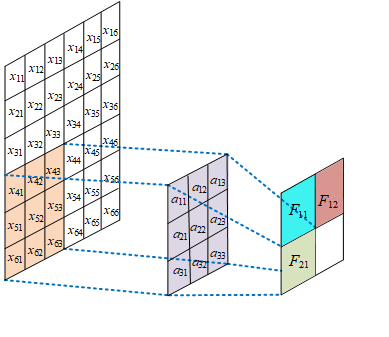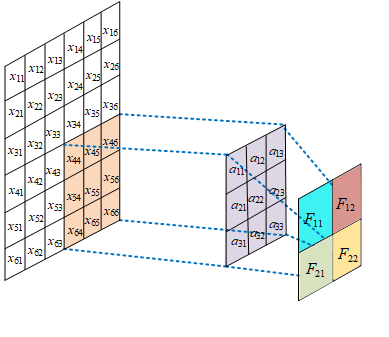
同一个特征图的神经元采用同一个卷积核的参数进行运算,因此他们是权值共享的
局部连接
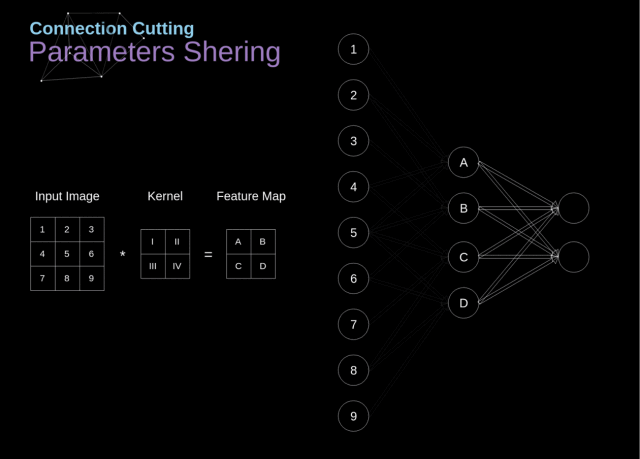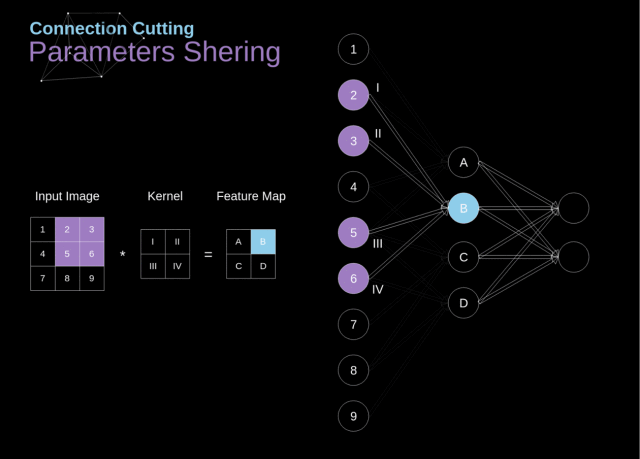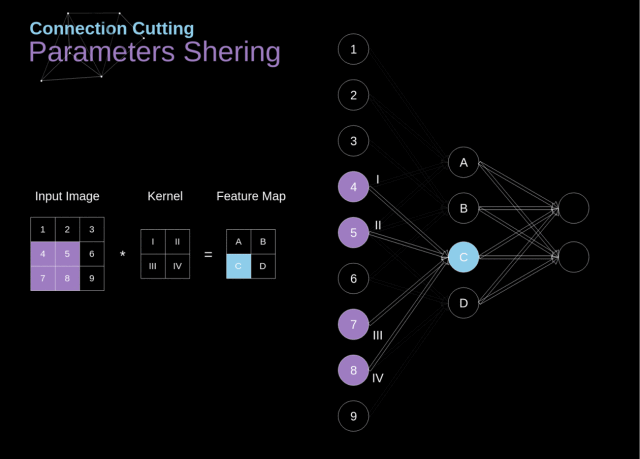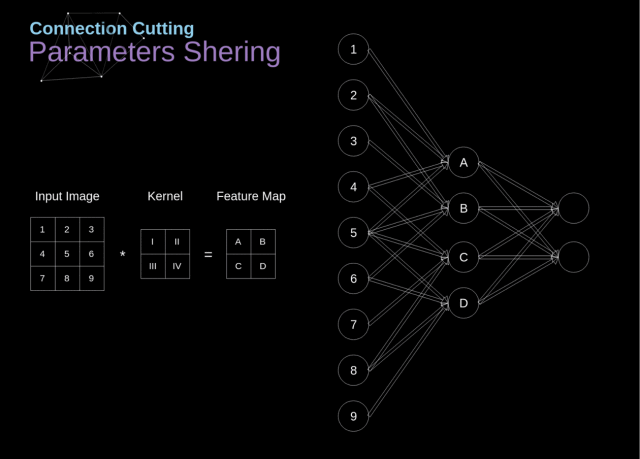
在进行卷积运算的时候,仅对当前参与卷积运算的区域进行连接
4.2.4 dropout 原理及代码
https://blog.csdn.net/qq_37555071/article/details/107801384(dropout原理及代码,写得相当详细)
4.2.4.1批注
这里丢弃的是神经元而非网络的权重
5.实现细节
主要交代了具体的超参数的设置,动量为0.9,权重衰减为0.0005,作者在这个过程中发现权重衰减非常重要,随后作者交代了一个权重初始化。所有的层使用相同的学习率,初始学习率为0.01,每三个回合衰减一次,总共迭代了大概90个epoch
相关代码
(1)pytorch官方实现的AlexNet,移除了LRN,通道数也有一些不一样
https://github.com/pytorch/vision/blob/main/torchvision/models/alexnet.py
(2)paper with code 对AlexNet的实现
https://github.com/dansuh17/alexnet-pytorch/blob/d0c1b1c52296ffcbecfbf5b17e1d1685b4ca6744/model.py#L40
class AlexNet(nn.Module):
"""
Neural network model consisting of layers propsed by AlexNet paper.
"""
def __init__(self, num_classes=1000):
"""
Define and allocate layers for this neural net.
Args:
num_classes (int): number of classes to predict with this model
"""
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4,padding=2), # (b x 96 x 55 x 55)
nn.ReLU(),
nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2), # section 3.3
nn.MaxPool2d(kernel_size=3, stride=2), # (b x 96 x 27 x 27)
nn.Conv2d(96, 256, 5, padding=2), # (b x 256 x 27 x 27)
nn.ReLU(),
nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2),
nn.MaxPool2d(kernel_size=3, stride=2), # (b x 256 x 13 x 13)
nn.Conv2d(256, 384, 3, padding=1), # (b x 384 x 13 x 13)
nn.ReLU(),
nn.Conv2d(384, 384, 3, padding=1), # (b x 384 x 13 x 13)
nn.ReLU(),
nn.Conv2d(384, 256, 3, padding=1), # (b x 256 x 13 x 13)
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2), # (b x 256 x 6 x 6)
)
# classifier is just a name for linear layers
self.classifier = nn.Sequential(
nn.Dropout(p=0.5, inplace=True),
nn.Linear(in_features=(256 * 6 * 6), out_features=4096),
nn.ReLU(),
nn.Dropout(p=0.5, inplace=True),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(),
nn.Linear(in_features=4096, out_features=num_classes),
)
def forward(self, x):
"""
Pass the input through the net.
Args:
x (Tensor): input tensor
Returns:
output (Tensor): output tensor
"""
x = self.net(x)
x = x.view(-1, 256 * 6 * 6) # reduce the dimensions for linear layer input
return self.classifier(x)
遗留问题
卷积和池化过程中的越界问题怎么处理
参考文献
https://blog.csdn.net/sunshine_youngforyou/article/details/99767600
https://blog.csdn.net/qq_45843546/article/details/124331168
http://www.datalearner.com/blog/1051558919769185(写得很不错)
https://blog.csdn.net/qq_45843546/article/details/124331168
https://wap.sciencenet.cn/blog-3428464-1255252.html(局部连接和权值共享)
https://www.jianshu.com/p/b070053a5fec(神经元的概念)
https://zhuanlan.zhihu.com/p/434773836(局部响应归一化)
https://towardsdatascience.com/difference-between-local-response-normalization-and-batch-normalization-272308c034ac(局部响应归一化)
https://zhuanlan.zhihu.com/p/349527410(局部响应归一化以及AlexNet源码实现)
https://blog.csdn.net/qq_37555071/article/details/107801384(dropout原理及代码)
https://www.codenong.com/78de8ccd09dd2998ddfc/(PCA数据增强)
https://blog.csdn.net/CSDNJERRYYAO/article/details/120068107(PCA数据增强)
https://www.cnblogs.com/zhangleo/p/16076052.html(PCA数据增强)