Spring Boot + Vue3 前后端分离 实战 wiki 知识库系统<七>--分类管理功能开发
接着上一次Spring Boot + Vue3 前后端分离 实战 wiki 知识库系统<六>--电子书管理功能开发二的学习继续往下。
分类表设计与代码生成:
概述:
在首页中,对于左侧这块的功能还缺失:

其实它是一个电子书的分类管理,而分类管理在电子书管理也有体现:

所以,这次的目标就是完成电子书的分类管理功能。
表设计:
对于分类功能,首先需要有一张对应的表,这里直接贴出了:
# 分类
drop table if exists `category`;
create table `category` (
`id` bigint not null comment 'id',
`parent` bigint not null default 0 comment '父id',
`name` varchar(50) not null comment '名称',
`sort` int comment '顺序',
primary key (`id`)
) engine=innodb default charset=utf8mb4 comment='分类';
insert into `category` (id, parent, name, sort) values (100, 000, '前端开发', 100);
insert into `category` (id, parent, name, sort) values (101, 100, 'Vue', 101);
insert into `category` (id, parent, name, sort) values (102, 100, 'HTML & CSS', 102);
insert into `category` (id, parent, name, sort) values (200, 000, 'Java', 200);
insert into `category` (id, parent, name, sort) values (201, 200, '基础应用', 201);
insert into `category` (id, parent, name, sort) values (202, 200, '框架应用', 202);
insert into `category` (id, parent, name, sort) values (300, 000, 'Python', 300);
insert into `category` (id, parent, name, sort) values (301, 300, '基础应用', 301);
insert into `category` (id, parent, name, sort) values (302, 300, '进阶方向应用', 302);
insert into `category` (id, parent, name, sort) values (400, 000, '数据库', 400);
insert into `category` (id, parent, name, sort) values (401, 400, 'MySQL', 401);
insert into `category` (id, parent, name, sort) values (500, 000, '其它', 500);
insert into `category` (id, parent, name, sort) values (501, 500, '服务器', 501);
insert into `category` (id, parent, name, sort) values (502, 500, '开发工具', 502);
insert into `category` (id, parent, name, sort) values (503, 500, '热门服务端语言', 503);虽说此次的电子书分类只支持2级,但是其数据库表的设计是支持无限级的,这表的结构也很好理解,其中有一点说明一下,就是对于每个分类的父新的id都是整型,如下:

而每个分类的子分类,都是在父id基础上进行个位的变化,如:
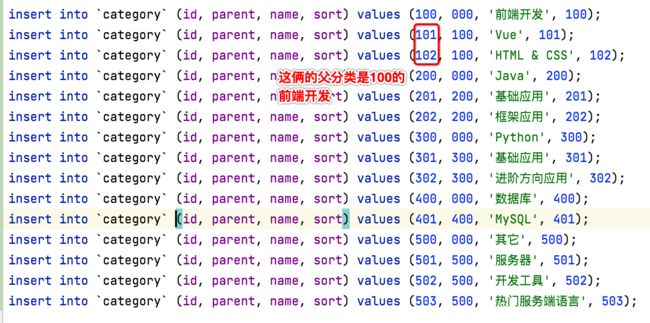
关于这个表要理解的就是这个小细节,接下来咱们执行一下该sql,初始化分类表:

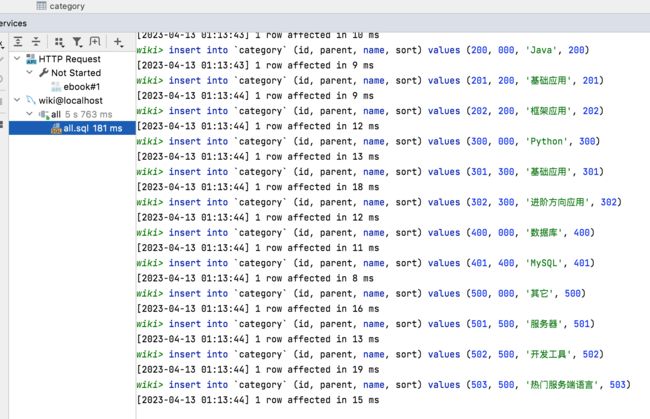
这里要注意该sql之所以直接右击能够执行,是因为咱们在之前Spring Boot + Vue3 前后端分离 实战 wiki 知识库系统<二>---后端架构完善与接口开发已经在IntelliJ IDEA配置了数据库连接了,看一下数据是否已经成功生成:

生成持久层代码:
接下来对于这个表中对应的持久层的代码就不用自己一一写了,跟电子书开发一样,使用之前咱们已经配置好的Mybatis的代码生成器,大大可以加速开发效率,再来回顾一下生成代码的流程:

在这个文件中配置一下要生成的这个分类表:
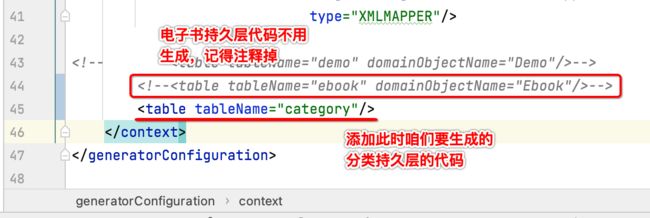
然后执行代码生成:


看一看是否真的生成成功了:
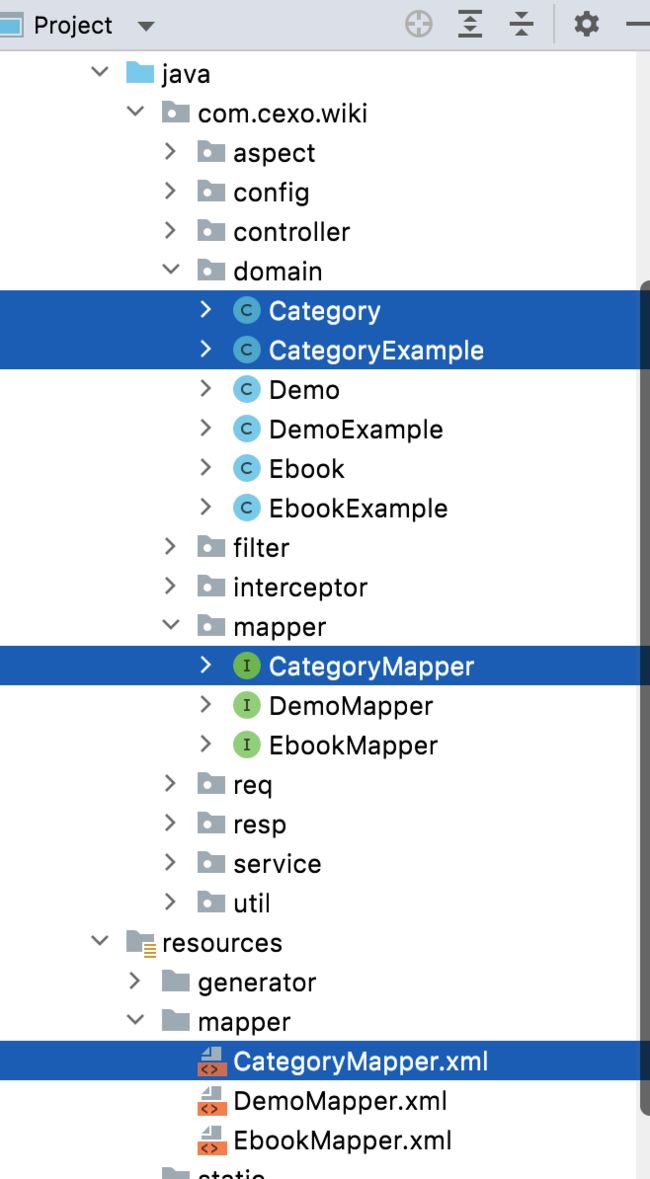
木问题,注意这里生成的代码不要人为改动。
完成分类基本增删改查功能:
目标:
有了分类的持久层代码之后,接下来咱们就可以实现对于分类管理的增删改查的功能了,而这功能其实跟之前咱们实现的电子书管理很雷同,所以这里的做法就是基于电子书管理进行代码拷贝,快速地实现分类的管理,在实际开发中,这也是大部分都会采用的做法,毕竟高效工作是非常重要的,所以下面来看一下如何快速的基于电子书管理的代码实现咱们新功能的分类管理功能。【注意:这里没啥技术含量,因为就是copy来copy去的,但是呢这种技巧我觉得比较实用~~】
从电子书管理拷贝出一套分类管理代码:
后端实现:
先来实现后端分类的接口。
1、CategoryController:
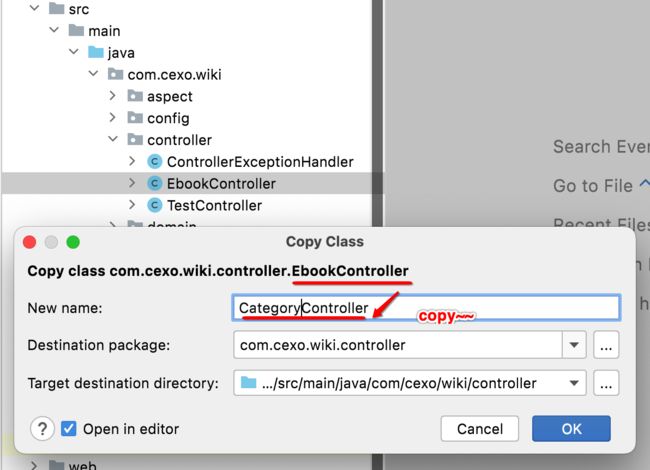

打开此文件很明显内容还是电子书相关的是吧,所以接下来用如下方法整体替换一下【其实在之前这种方式已经用过了,这里将其再温故一下】:

注意:这里的操作界面可能不同版本会存在一些显示上的差异,但是功能其实是一样的。
接下来再来用这种方式来替换大写开头的:

替换完,你会发现,该类一大堆报错:

木关系,那是因为还有其它相关的类没有拷贝生成,等全部拷贝完这里的报错就没了,这里这个类就严格按此步骤执行到这就可以了,有木有觉得很爽,我是最喜欢这种感觉了,一个功能,copy一下,再改吧改吧,功能搞定,这是我一直想要追求的~~
2、CategoryService:
同样的方法,这里再来重复一下过程,加深印象,先拷贝生成这个类:


接下来整体内容进行替换:


也是有一堆报错也不用管,有了这个类之后,我们就可以回到CategoryController中导包了,消除一点错:
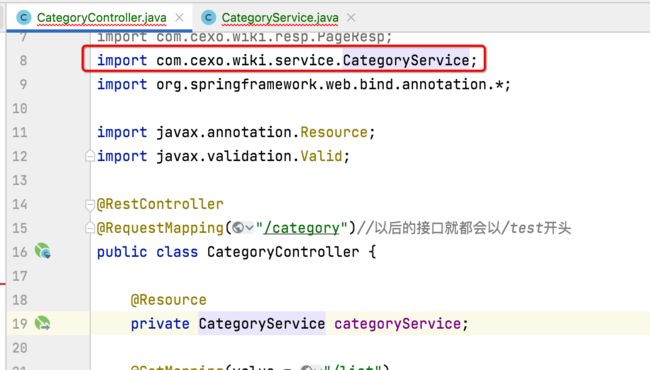
目前CategoryController和CategoryService类中报错的都是缺少对应的实体类了:
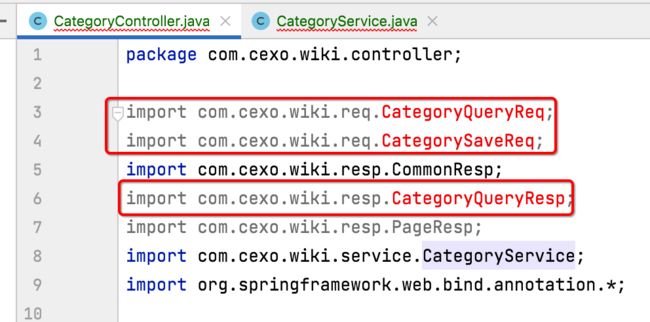
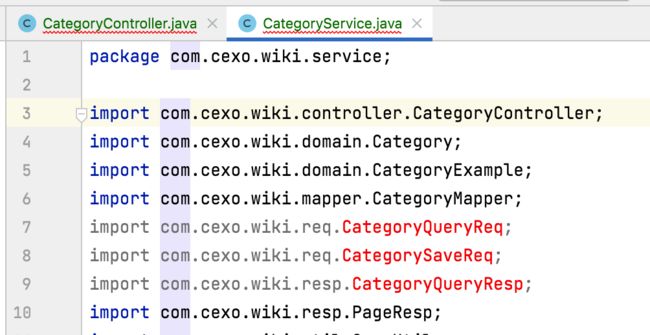
所以接下来继续copy生成对应的类。
3、CategoryQueryReq:

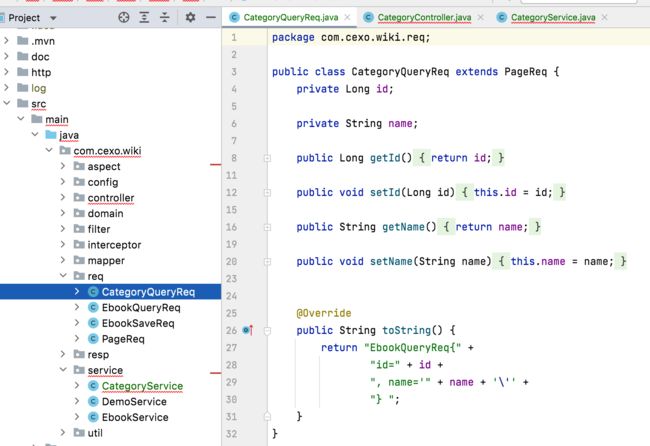
其中对于分类的查询条件这里先将字段都删掉,等到时用到查询时再来定义,所以这个类目前的内容就变成了:
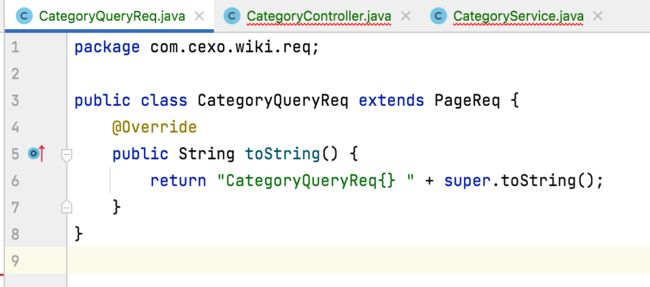
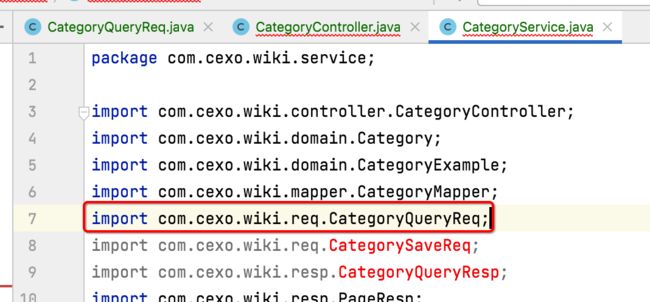
此时可以看到Categorycontroller和CategoryService这个类的报错就木有了:

4、CategorySaveReq:
这个由于字段名是跟Category这个实体是一样的,所以直接基于Category进行拷贝生成:


其中顺带我们定义一个非空约束,就像电子书这块一样:


此时再回到CategoryController和CategoryService类中,就只有一个类报错了:
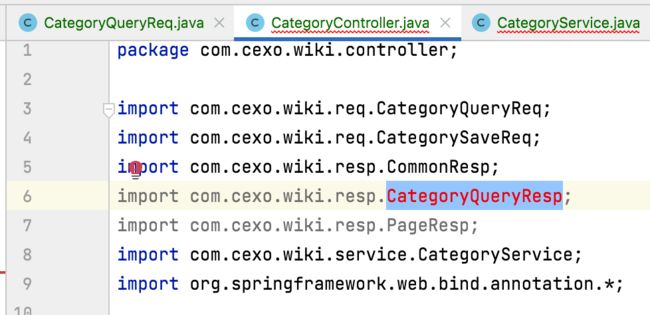

5、CategoryQueryResp:
它里面的字段也跟Category这个实体是一样的,所以也从Category进行拷贝生成一下:

此时CategoryController已经完全不报错了,但是CategoryService还有处报错,看一下:

这是因为目前分类的查询字段还没有定义,这里面还是电子书查询的代码,直接将根据name查询的报错代码给删掉既可:
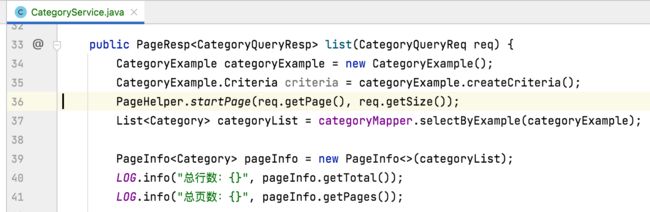
至此,整个分类的后端代码就写完了,爽不爽,自己没敲一行逻辑代码,全是copy电子书然后再稍加改个名称。
前端实现:
接下来咱们就可以回到前端来利用CV大法继续快速的生成分类相关的管理的前端功能。
1、admin-category.vue:


接下来则替换一下里面的内容,同样是两步骤:

另外再将中文也整体替换一下:

2、手动调整表单显示字段:
接下来有个需要我们手动修改的地方来了,也就是这块:


由于分类的表单跟电子书的表单字段是不一样的,所以这里木有办法,只能手工来根据分类的进行修改,这里就直接贴出修改的结果了:

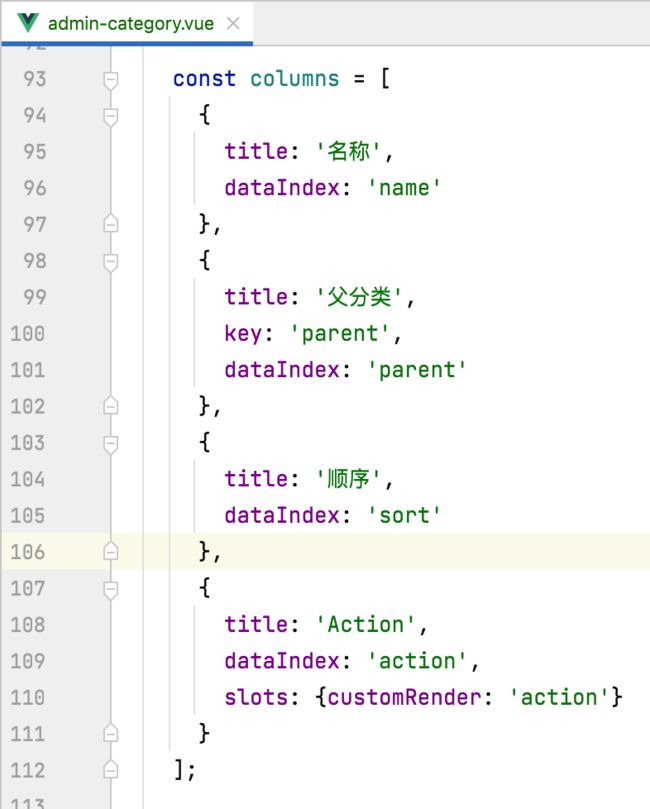
3、配置路由:

4、修改菜单:
接下来则需要增加一个分类管理:

测试:
通过上面的各种CV操作之后,整个分类的增删改查功能就已经完成了,编译运行也正常,下面看一下运行效果:

由于分类的数据比较多,这里一页只显示了2条,把它加大一下:

接下来看一下整体的增删改查的效果:
整体功能都有了,但是!!!编辑和删除功能不好使,这是为啥呢?看一下后台的日志:


确实是木有更新成功耶,那看一下数据库的这条记录的id,能不能匹配上呢?
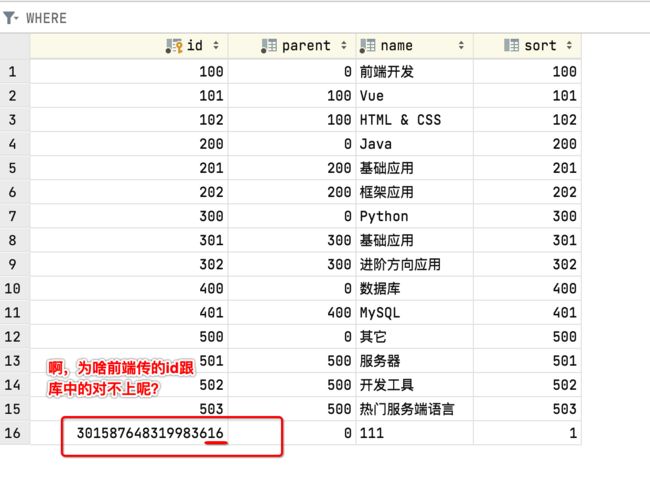
这其实是Vue中对于雪花id会有精度的问题,百度一下:完美解决雪花算法自动生成id 丢失精确的问题_vue雪花算法_小东很不戳的博客-CSDN博客,解决方案就是如这大佬所说做一个配置,如下:

package com.cexo.wiki.config;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.databind.module.SimpleModule;
import com.fasterxml.jackson.databind.ser.std.ToStringSerializer;
import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.http.converter.json.Jackson2ObjectMapperBuilder;
//用来解决vue雪花算法id会丢失精度造成无法进行数据的编辑或删除的问题
@Configuration
public class JacksonConfig {
@Bean
@Primary
@ConditionalOnMissingBean(ObjectMapper.class)
public ObjectMapper jacksonObjectMapper(Jackson2ObjectMapperBuilder builder) {
ObjectMapper objectMapper = builder.createXmlMapper(false).build();
// 全局配置序列化返回 JSON 处理
SimpleModule simpleModule = new SimpleModule();
//JSON Long ==> String
simpleModule.addSerializer(Long.class, ToStringSerializer.instance);
objectMapper.registerModule(simpleModule);
return objectMapper;
}
}好,再次运行看一下:

就问6不6,基本上没怎么写代码,这个模块的增删改查的基本功能就ok了。
分类表格显示优化:
不需要分页:
概述:
对于分类来说,由于数据量不大,所以这里不需要对它进行一个分类,直接全部展示,一个最简单的改法就像之前电子书列表显示那样将这个数改大:

但是!!!它有个问题就是性能不是太好,每次查询会查出两个sql:

对于小项目这样改当然没啥影响,但是对于商用大项目这样多一次查询是会影响性能的, 所以,好的做法就是提供一个专门查所有数据不分页的方法。
实现:
1、接口实现:
这里就快速实现一下,拷贝一下list()方法进行改造:

另外加一个排序:

其中这个方法的参数也可以去掉了:

接下来再在controller定义一下:

2、前端改造:
接下来进行前端的改造,先来改请求:
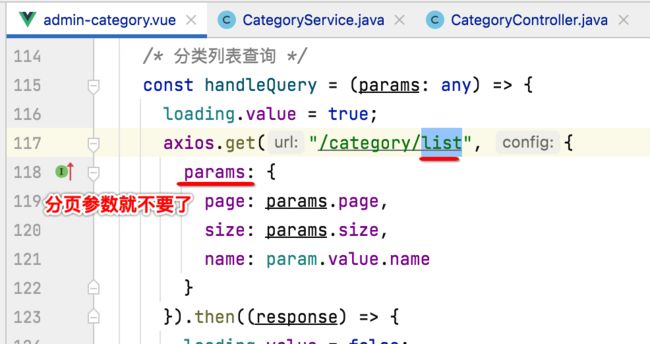

其中由于现在返回的就是一个List,所以结果取值也得改一下:

另外方法参数也可以去了:

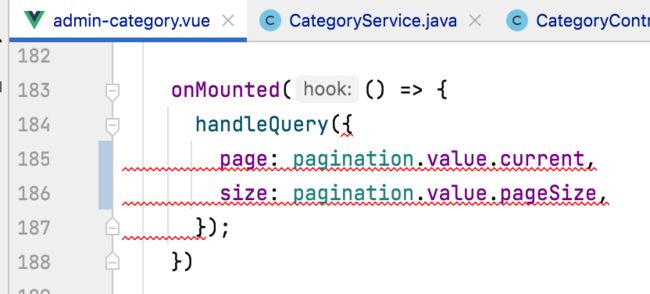
接下来就可以把所有调用handleQuery的地方把参数都去掉,目前有几处报错:
,这里就不一一截图了,纯体力活,以其中的一个为例:

然后再将页面上所有pagination相关的都给去了,这里直接把所有涉及到的地方截个图:
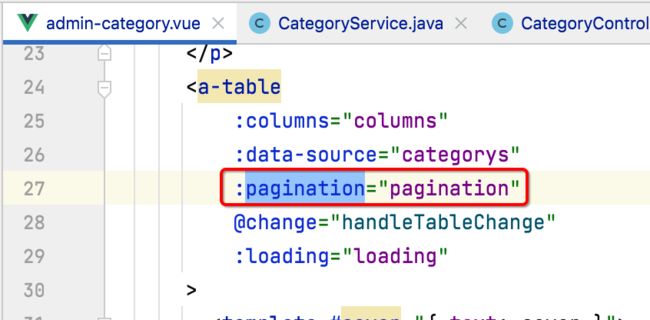
这里有个坑,要想不及格不分页,直接去掉是不管用的,需要这样设置一下:
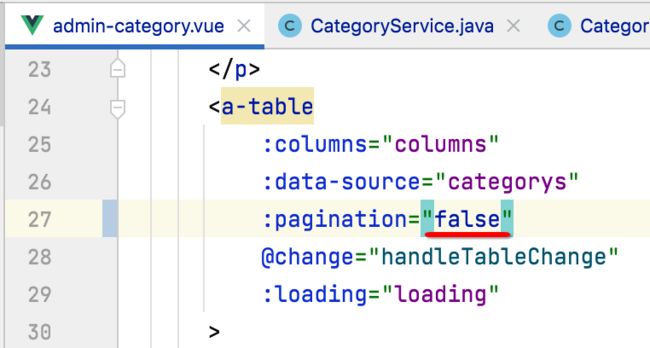
另外这里学习一下Vue的基础语法,就是对于很多标签上的属性都加一个冒号:

而有些标签的属性是木有的,那这俩有啥区别呢?度娘一下:Vue组件的属性中“:“的用法_vue中:_FangkunKr8s的博客-CSDN博客 ,这篇说得比较明白了
Vue组件的属性中,有时加":",有时不加,原因是:
加冒号的,说明后面的是一个变量或者表达式,没加冒号的,后面就是对应的字符串字面量
继续来改造:

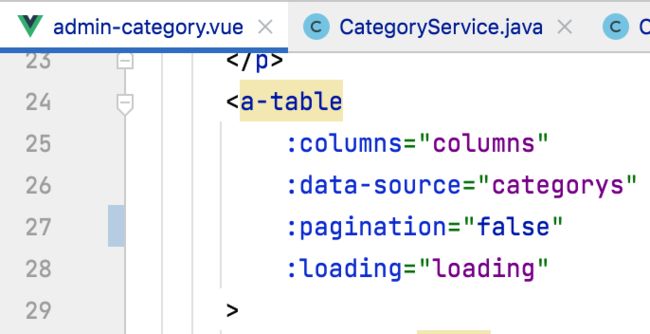
然后涉及到handleTableChange有几处代码,这里就不全贴出来了,自己根据情况删掉既可。

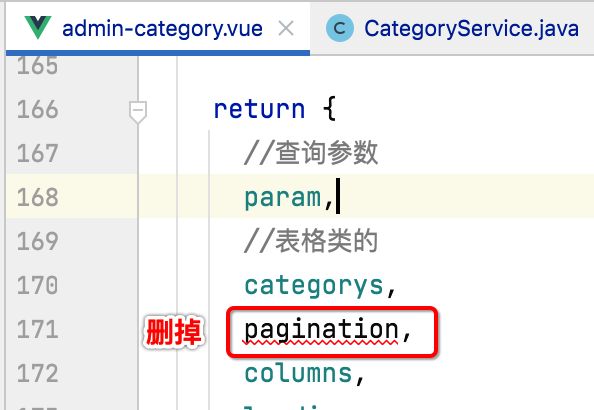
3、测试:
最后测试一下:

另外由于分类查询根据名称来查这块木有实现,暂且也不需要,所以咱们把这个input框去掉得了:

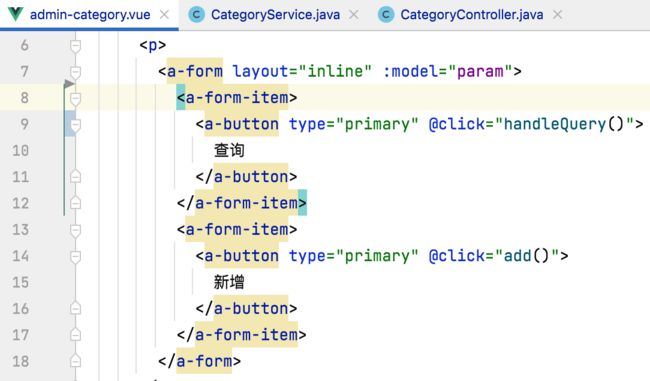
此时效果为:

此时查询就变成了一个单纯的数据刷新行为了。
树型表格展示:
效果:
由于分类是一个树形结构,目前咱们的展示完全没有这个结构的体现,肉眼也很难分清楚哪个是父级,哪个是子级,所以接下来优化一下显,实现这么一个树型展示效果:

实现:
1、上Ant Design Vue寻找效果组件:
在表格组件中有这么一个效果:

其中这个组件有个关键描述:

看一下示例代码:

所以现在的关键问题就是在于如何将咱们一条条的数据转化成这个组件要求的带children的树型结构了。
2、将数据转换成树形结构:
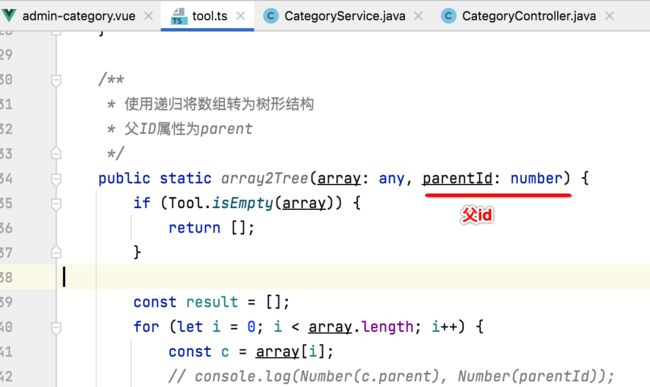
这里其实需要用到一个工具类,这里全部贴出来了:
/**
* 使用递归将数组转为树形结构
* 父ID属性为parent
*/
public static array2Tree(array: any, parentId: number) {
if (Tool.isEmpty(array)) {
return [];
}
const result = [];
for (let i = 0; i < array.length; i++) {
const c = array[i];
// console.log(Number(c.parent), Number(parentId));
if (Number(c.parent) === Number(parentId)) {
result.push(c);
// 递归查看当前节点对应的子节点
const children = Tool.array2Tree(array, c.id);
if (Tool.isNotEmpty(children)) {
c.children = children;
}
}
}
return result;
}
这里是使用到了递归,简单的看一看它的递归方法的参数:
而在这里,所有一级分类的父id都是为0的:

而如果它有子分类,则需要利用递归找到他们,并将结果放到当前父分类的children属性中:
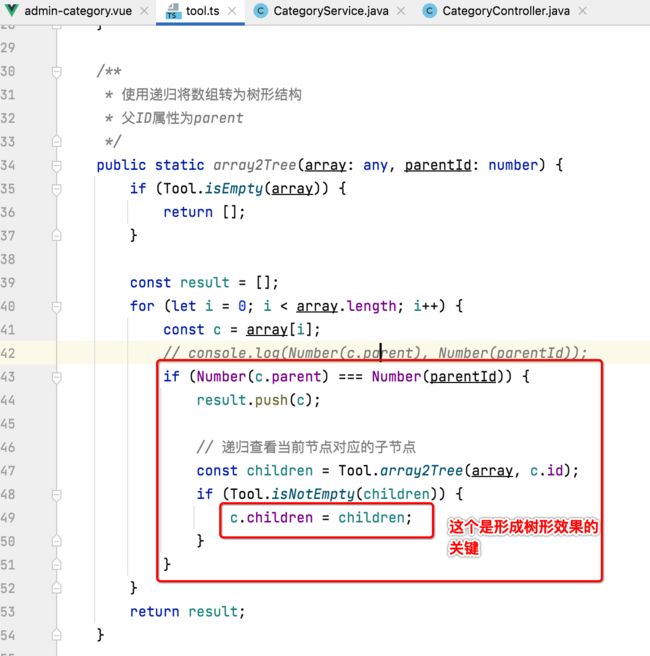
当然你如果没太读懂这个js中的递归,直接将它当工具类来使用既可。
3、前端集成树型功能:
接下来咱们回到前端,先处理树型数据的转换:

接下来在表格组件中使用一下转换后的这个数据:
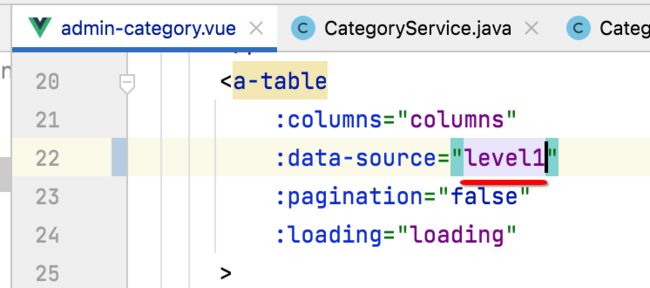
要使用它记得return一下:
4、测试:

效果还是挺不错的,关于分类的其它功能,下次再继续。
关注个人公众号,获得实时推送
