逻辑回归分析实训----乳腺癌肿瘤预测
1.逻辑回归
逻辑回归也称作logistic回归分析,是一种广义的线性回归分析模型,需要一个应变量 y和一个或一个以上的自变量,属于机器学习中的监督学习。逻辑回归是用来进行分类的。例如,我们给出一个人的 [身高,体重] 这两个指标,然后判断这个人是属于”胖“还是”瘦“这一类。
2.线性回归vs逻辑回归
区别:
- 它们的应变量不同,线性回归直接将ax+b作为应变量,即y=ax+b,而logistic回归则通过函数sigmoid将ax+b对应到到(0,1),从而完成概率的估测。
- 结果(y):对于线性回归,结果是一个标量值(可以是任意一个符合实际的数值),例如 50000,23.98 等;对于逻辑回归,结果是表示不同类的整数,是离散的。
- 特征(x):对于线性回归,特征都表示为一个列向量;对于涉及二维图像的逻辑回归,特征是一个二维矩阵,矩阵的每个元素表示图像的像素值,每个像素值是属于 0 到 255 之间的整数,其中 0 表示黑色,255 表示白色,其他值表示具有某些灰度阴影。
- 成本函数(成本):对于线性回归,成本函数是表示每个预测值与其预期结果之间的聚合差异的某些函数;对于逻辑回归,是计算每次预测的正确率或错误率的某些函数。
相似性:
- 逻辑回归与线性回归模型的形式基本上相同,都具有ax+b,其中,a,b都是待求参数。
- 训练:线性回归和逻辑回归的训练目标都是去学习权重(W)和偏置(b)值。
- 结果:线性回归与逻辑回归的目标都是利用学习到的权重和偏置值去预测/分类结果.
3.乳腺癌中肿瘤预测(实训)------逻辑回归分析
3.1 导入需要的各种包,例如:pandas,numpy,sklearn

3.2 定义列,给列起名字

3.3 导入数据,增加数据的参数值(导入时数据的路径一定是安装的路径)
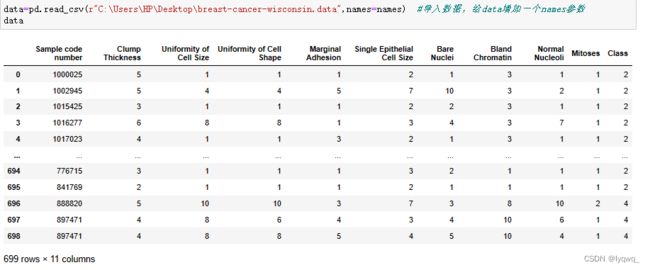
3.4 输出列表返回的元组,获取数据中的信息值
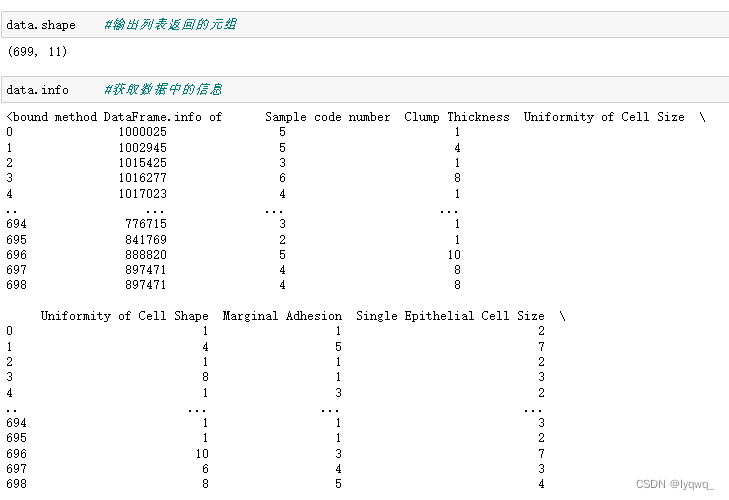
3.5 查看数据的基本情况
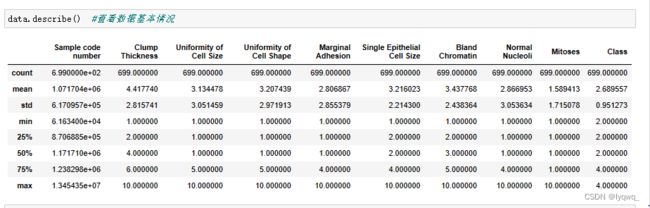
3.6 对数据目标值进行说明
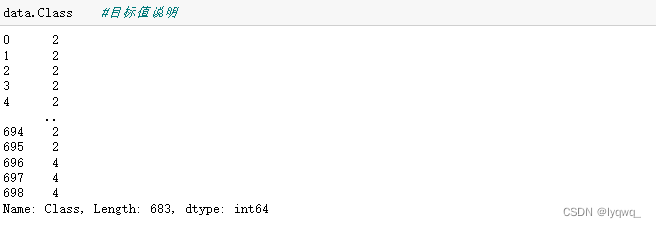
3.7 替换数据中的缺失值,并且删除缺失值的样本,再确定特征值和目标值

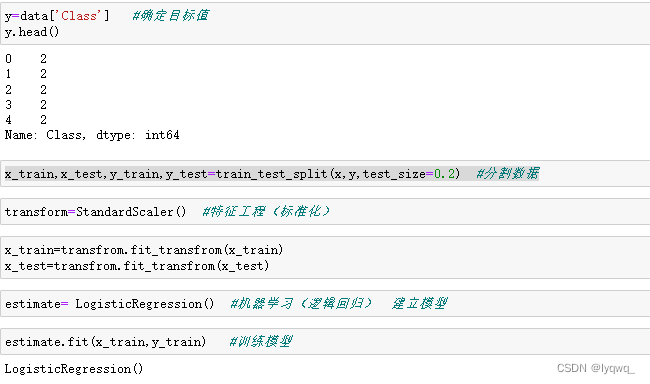
3.8 确定目标值后,对数据进行分割,建立特征工程,逻辑回归建立模型,最后训练模型
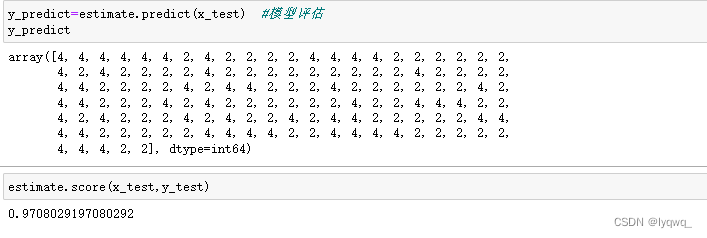
3.9 对模型进行评估,得到模型预测值
4.代码如下:
import pandas as pd #导入各种包
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
import ssl
ssl._create_default_https_contex=ssl._create_unverified_context
names = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape',
'Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin',
'Normal Nucleoli', 'Mitoses', 'Class'] #给列起名字
data=pd.read_csv(r"C:\Users\HP\Desktop\breast-cancer-wisconsin.data",names=names) #导入数据,给data增加一个names参数
data
data.shape #输出列表返回的元组
data.info #获取数据中的信息
data.describe() #查看数据基本情况
data.Class #目标值说明
data=data.replace(to_replace="?",value=np.NaN) #替换缺失值
data=data.dropna() #删除缺失值的样本
x=data.iloc[:,1:10] #确定特征值
x.head()
y=data['Class'] #确定目标值
y.head()
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.2) #分割数据
transform=StandardScaler() #特征工程(标准化)
x_train=transfrom.fit_transfrom(x_train)
x_test=transfrom.fit_transfrom(x_test)
estimate= LogisticRegression() #机器学习(逻辑回归) 建立模型
estimate.fit(x_train,y_train) #训练模型
y_predict=estimate.predict(x_test) #模型评估
y_predict
estimate.score(x_test,y_test)
学号:202113430110
姓名:罗媛