3、hive的使用示例详解-建表、数据类型详解、内部外部表、分区表、分桶表
Apache Hive 系列文章
1、apache-hive-3.1.2简介及部署(三种部署方式-内嵌模式、本地模式和远程模式)及验证详解
2、hive相关概念详解–架构、读写文件机制、数据存储
3、hive的使用示例详解-建表、数据类型详解、内部外部表、分区表、分桶表
4、hive的使用示例详解-事务表、视图、物化视图、DDL(数据库、表以及分区)管理详细操作
5、hive的load、insert、事务表使用详解及示例
6、hive的select(GROUP BY、ORDER BY、CLUSTER BY、SORT BY、LIMIT、union、CTE)、join使用详解及示例
7、hive shell客户端与属性配置、内置运算符、函数(内置运算符与自定义UDF运算符)
8、hive的关系运算、逻辑预算、数学运算、数值运算、日期函数、条件函数和字符串函数的语法与使用示例详解
9、hive的explode、Lateral View侧视图、聚合函数、窗口函数、抽样函数使用详解
10、hive综合示例:数据多分隔符(正则RegexSerDe)、url解析、行列转换常用函数(case when、union、concat和explode)详细使用示例
11、hive综合应用示例:json解析、窗口函数应用(连续登录、级联累加、topN)、拉链表应用
12、Hive优化-文件存储格式和压缩格式优化与job执行优化(执行计划、MR属性、join、优化器、谓词下推和数据倾斜优化)详细介绍及示例
13、java api访问hive操作示例
文章目录
- Apache Hive 系列文章
- 一、 数据定义语言(DDL)概述
- 二、Hive数据类型详解
-
- 1、整体概述
- 2、原生数据类型
- 3、复杂数据类型
- 4、数据类型隐式、显示转换
- 三、示例
-
- 1、原生数据类型
- 2、复杂数据类型
- 3、默认分隔符案例
- 四、内外部表
-
- 1、内部表
- 2、外部表
- 3、内部表、外部表差异
- 五、Hive分区表
-
- 1、简单示例
- 2、分区表的概念、创建
-
- 1)、语法
- 2)、示例
- 3、分区表数据加载--静态分区
- 4、分区表数据加载--动态分区
- 5、分区表的本质
- 6、分区表的使用
- 7、分区表的注意事项
- 8、多重分区表
-
- 1)、示例1:单分区表,按省份分区
- 2)、示例2:双分区表,按省份和市分区
- 3)、示例3:三分区表,按省份、市、县分区
- 六、Hive分桶表
-
- 1、分桶表的概念
- 2、分桶表的语法
- 3、分桶表的创建
- 4、分桶表的数据加载
- 5、分桶表的作用
本文详细的介绍了hive的DDL、数据类型、内外部表、分区与分桶表的概念、使用以及详细的示例。
本文依赖是hive环境可用。
本分分为6个部分,即DDL概述、数据类型、简单的ddl示例、内外部表、分区表与分桶表。
一、 数据定义语言(DDL)概述
数据定义语言 (Data Definition Language, DDL),是SQL语言集中对数据库内部的对象结构进行创建,删除,修改等的操作语言,这些数据库对象包括database(schema)、table、view、index等。核心语法由CREATE、ALTER与DROP三个所组成。
DDL并不涉及表内部数据的操作。
-- |表示使用的时候,左右语法二选一。
-- 建表语句中的语法顺序要和上述语法规则保持一致。
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later)
[(col_name data_type [column_constraint_specification] [COMMENT col_comment], ... [constraint_specification])]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10.0 and later)]
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format]
[STORED AS file_format] | STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later)
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later)
[AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables)
-- 表
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
LIKE existing_table_or_view_name
[LOCATION hdfs_path];
-- 数据类型
data_type
: primitive_type
| array_type
| map_type
| struct_type
| union_type -- (Note: Available in Hive 0.7.0 and later)
-- 基础数据类型
primitive_type
: TINYINT
| SMALLINT
| INT
| BIGINT
| BOOLEAN
| FLOAT
| DOUBLE
| DOUBLE PRECISION -- (Note: Available in Hive 2.2.0 and later)
| STRING
| BINARY -- (Note: Available in Hive 0.8.0 and later)
| TIMESTAMP -- (Note: Available in Hive 0.8.0 and later)
| DECIMAL -- (Note: Available in Hive 0.11.0 and later)
| DECIMAL(precision, scale) -- (Note: Available in Hive 0.13.0 and later)
| DATE -- (Note: Available in Hive 0.12.0 and later)
| VARCHAR -- (Note: Available in Hive 0.12.0 and later)
| CHAR -- (Note: Available in Hive 0.13.0 and later)
-- 数组数据类型
array_type
: ARRAY < data_type >
-- map数据类型
map_type
: MAP < primitive_type, data_type >
-- 结构体数据类型
struct_type
: STRUCT < col_name : data_type [COMMENT col_comment], ...>
-- union数据类型
union_type
: UNIONTYPE < data_type, data_type, ... > -- (Note: Available in Hive 0.7.0 and later)
-- 行格式
row_format
: DELIMITED [FIELDS TERMINATED BY char [ESCAPED BY char]] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
[NULL DEFINED AS char] -- (Note: Available in Hive 0.13 and later)
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
-- 文件格式
file_format:
: SEQUENCEFILE
| TEXTFILE -- (Default, depending on hive.default.fileformat configuration)
| RCFILE -- (Note: Available in Hive 0.6.0 and later)
| ORC -- (Note: Available in Hive 0.11.0 and later)
| PARQUET -- (Note: Available in Hive 0.13.0 and later)
| AVRO -- (Note: Available in Hive 0.14.0 and later)
| JSONFILE -- (Note: Available in Hive 4.0.0 and later)
| INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname
-- 列约束
column_constraint_specification:
: [ PRIMARY KEY|UNIQUE|NOT NULL|DEFAULT [default_value]|CHECK [check_expression] ENABLE|DISABLE NOVALIDATE RELY/NORELY ]
-- 默认值
default_value:
: [ LITERAL|CURRENT_USER()|CURRENT_DATE()|CURRENT_TIMESTAMP()|NULL ]
-- 列约束类型
constraint_specification:
: [, PRIMARY KEY (col_name, ...) DISABLE NOVALIDATE RELY/NORELY ]
[, PRIMARY KEY (col_name, ...) DISABLE NOVALIDATE RELY/NORELY ]
[, CONSTRAINT constraint_name FOREIGN KEY (col_name, ...) REFERENCES table_name(col_name, ...) DISABLE NOVALIDATE
[, CONSTRAINT constraint_name UNIQUE (col_name, ...) DISABLE NOVALIDATE RELY/NORELY ]
[, CONSTRAINT constraint_name CHECK [check_expression] ENABLE|DISABLE NOVALIDATE RELY/NORELY ]
二、Hive数据类型详解
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
1、整体概述
Hive中的数据类型指的是Hive表中的列字段类型。
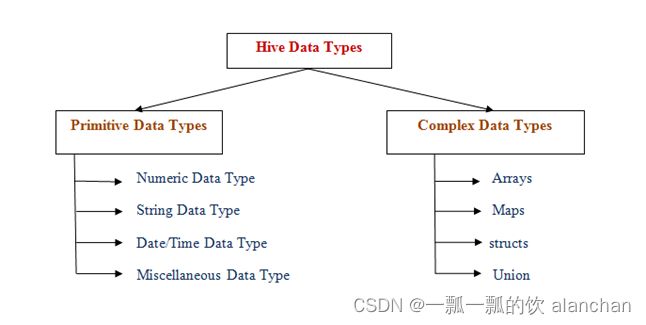
Hive数据类型整体分为两个类别:原生数据类型(primitive data type)和复杂数据类型(complex data type)。
原生数据类型包括:数值类型、时间类型、字符串类型、杂项数据类型;
复杂数据类型包括:array数组、map映射、struct结构、union联合体。
注意事项:
- 英文字母大小写不敏感
- 除SQL数据类型外,还支持Java数据类型,比如:string
- int和string是使用最多的,大多数函数都支持
- 复杂数据类型的使用通常需要和分隔符指定语法配合使用
- 如果定义的数据类型和文件不一致,hive会尝试隐式转换,但是不保证成功
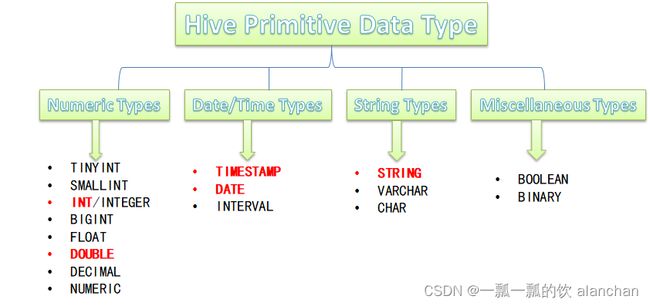
2、原生数据类型
Hive支持的原生数据类型如下图所示
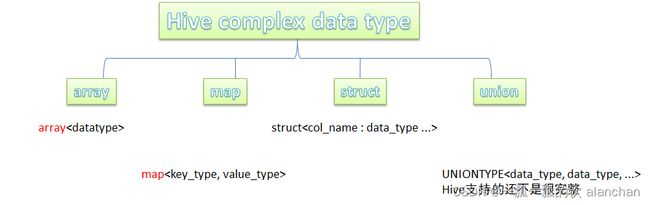
3、复杂数据类型
Hive支持的复杂数据类型如下图所示:
4、数据类型隐式、显示转换
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Types
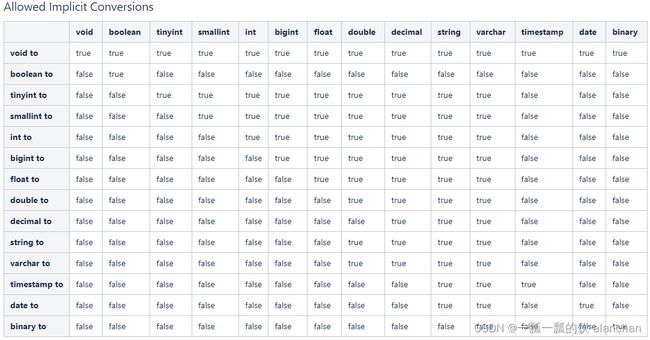
与SQL类似,HQL支持隐式和显式类型转换。
原生类型从窄类型到宽类型的转换称为隐式转换,反之,则不允许。
下表描述了类型之间允许的隐式转换:
## 显式类型转换使用CAST函数。
## 例如,CAST('100' as INT)会将100字符串转换为100整数值。 如果强制转换失败,例如CAST('INT' as INT),该函数返回NULL。
select cast('100' as INT) ;
0: jdbc:hive2://server4:10000> select cast('100' as INT) ;
INFO : Compiling command(queryId=alanchan_20221017152244_5d8323e3-0f96-4b22-ad02-51fd9afdc386): select cast('100' as INT)
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:_c0, type:int, comment:null)], properties:null)
INFO : Completed compiling command(queryId=alanchan_20221017152244_5d8323e3-0f96-4b22-ad02-51fd9afdc386); Time taken: 0.29 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=alanchan_20221017152244_5d8323e3-0f96-4b22-ad02-51fd9afdc386): select cast('100' as INT)
INFO : Completed executing command(queryId=alanchan_20221017152244_5d8323e3-0f96-4b22-ad02-51fd9afdc386); Time taken: 0.001 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+------+
| _c0 |
+------+
| 100 |
+------+
三、示例
1、原生数据类型
# archer.txt 数据使用制表符\t分割
1 后羿 5986 1784 396 336 remotely archer
2 马可波罗 5584 200 362 344 remotely archer
3 鲁班七号 5989 1756 400 323 remotely archer
4 李元芳 5725 1770 396 340 remotely archer
5 孙尚香 6014 1756 411 346 remotely archer
6 黄忠 5898 1784 403 319 remotely archer
7 狄仁杰 5710 1770 376 338 remotely archer
8 虞姬 5669 1770 407 329 remotely archer
9 成吉思汗 5799 1742 394 329 remotely archer
10 百里守约 5611 1784 410 329 remotely archer assassin
--创建数据库并切换使用
create database test;
use test;
--ddl create table
create table t_archer(
id int comment "ID",
name string comment "英雄名称",
hp_max int comment "最大生命",
mp_max int comment "最大法力",
attack_max int comment "最高物攻",
defense_max int comment "最大物防",
attack_range string comment "攻击范围",
role_main string comment "主要定位",
role_assist string comment "次要定位"
) comment "王者荣耀射手信息"
row format delimited fields terminated by "\t"
0: jdbc:hive2://server4:10000> select * from t_archer;
INFO : Compiling command(queryId=alanchan_20221017161923_3260ca84-cc04-4ffa-9b9d-ae104f14d207): select * from t_archer
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:t_archer.id, type:int, comment:null), FieldSchema(name:t_archer.name, type:string, comment:null), FieldSchema(name:t_archer.hp_max, type:int, comment:null), FieldSchema(name:t_archer.mp_max, type:int, comment:null), FieldSchema(name:t_archer.attack_max, type:int, comment:null), FieldSchema(name:t_archer.defense_max, type:int, comment:null), FieldSchema(name:t_archer.attack_range, type:string, comment:null), FieldSchema(name:t_archer.role_main, type:string, comment:null), FieldSchema(name:t_archer.role_assist, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=alanchan_20221017161923_3260ca84-cc04-4ffa-9b9d-ae104f14d207); Time taken: 0.228 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=alanchan_20221017161923_3260ca84-cc04-4ffa-9b9d-ae104f14d207): select * from t_archer
INFO : Completed executing command(queryId=alanchan_20221017161923_3260ca84-cc04-4ffa-9b9d-ae104f14d207); Time taken: 0.0 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+--------------+----------------+------------------+------------------+----------------------+-----------------------+------------------------+---------------------+-----------------------+
| t_archer.id | t_archer.name | t_archer.hp_max | t_archer.mp_max | t_archer.attack_max | t_archer.defense_max | t_archer.attack_range | t_archer.role_main | t_archer.role_assist |
+--------------+----------------+------------------+------------------+----------------------+-----------------------+------------------------+---------------------+-----------------------+
| 1 | 后羿 | 5986 | 1784 | 396 | 336 | remotely | archer | NULL |
| 2 | 马可波罗 | 5584 | 200 | 362 | 344 | remotely | archer | NULL |
| 3 | 鲁班七号 | 5989 | 1756 | 400 | 323 | remotely | archer | NULL |
| 4 | 李元芳 | 5725 | 1770 | 396 | 340 | remotely | archer | NULL |
| 5 | 孙尚香 | 6014 | 1756 | 411 | 346 | remotely | archer | NULL |
| 6 | 黄忠 | 5898 | 1784 | 403 | 319 | remotely | archer | NULL |
| 7 | 狄仁杰 | 5710 | 1770 | 376 | 338 | remotely | archer | NULL |
| 8 | 虞姬 | 5669 | 1770 | 407 | 329 | remotely | archer | NULL |
| 9 | 成吉思汗 | 5799 | 1742 | 394 | 329 | remotely | archer | NULL |
| 10 | 百里守约 | 5611 | 1784 | 410 | 329 | remotely | archer | assassin |
+--------------+----------------+------------------+------------------+----------------------+-----------------------+------------------------+---------------------+-----------------------+
10 rows selected (0.28 seconds)
2、复杂数据类型
# 文件内容
1,孙悟空,53,西部大镖客:288-大圣娶亲:888-全息碎片:0-至尊宝:888-地狱火:1688
2,鲁班七号,54,木偶奇遇记:288-福禄兄弟:288-黑桃队长:60-电玩小子:2288-星空梦想:0
3,后裔,53,精灵王:288-阿尔法小队:588-辉光之辰:888-黄金射手座:1688-如梦令:1314
4,铠,52,龙域领主:288-曙光守护者:1776
5,韩信,52,飞衡:1788-逐梦之影:888-白龙吟:1188-教廷特使:0-街头霸王:888
# 字段:id、name(英雄名称)、win_rate(胜率)、skin_price(皮肤及价格)
# 前3个字段原生数据类型、最后一个字段复杂类型map。需要指定字段之间分隔符、集合元素之间分隔符、map kv之间分隔符
# 格式:id,name,win_rate,--。。。。
create table t_hot_hero_skin_price(
id int,
name string,
win_rate int,
skin_price map<string,int>
)
row format delimited
fields terminated by ','
collection items terminated by '-'
map keys terminated by ':' ;
# 建好表后,上传文件,查询
0: jdbc:hive2://server4:10000> select * from t_hot_hero_skin_price;
INFO : Compiling command(queryId=alanchan_20221017162515_152f0382-ae78-402a-8f46-7333afbb49b6): select * from t_hot_hero_skin_price
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:t_hot_hero_skin_price.id, type:int, comment:null), FieldSchema(name:t_hot_hero_skin_price.name, type:string, comment:null), FieldSchema(name:t_hot_hero_skin_price.win_rate, type:int, comment:null), FieldSchema(name:t_hot_hero_skin_price.skin_price, type:map<string,int>, comment:null)], properties:null)
INFO : Completed compiling command(queryId=alanchan_20221017162515_152f0382-ae78-402a-8f46-7333afbb49b6); Time taken: 0.184 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=alanchan_20221017162515_152f0382-ae78-402a-8f46-7333afbb49b6): select * from t_hot_hero_skin_price
INFO : Completed executing command(queryId=alanchan_20221017162515_152f0382-ae78-402a-8f46-7333afbb49b6); Time taken: 0.0 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+---------------------------+-----------------------------+---------------------------------+----------------------------------------------------+
| t_hot_hero_skin_price.id | t_hot_hero_skin_price.name | t_hot_hero_skin_price.win_rate | t_hot_hero_skin_price.skin_price |
+---------------------------+-----------------------------+---------------------------------+----------------------------------------------------+
| 1 | 孙悟空 | 53 | {"西部大镖客":288,"大圣娶亲":888,"全息碎片":0,"至尊宝":888,"地狱火":1688} |
| 2 | 鲁班七号 | 54 | {"木偶奇遇记":288,"福禄兄弟":288,"黑桃队长":60,"电玩小子":2288,"星空梦想":0} |
| 3 | 后裔 | 53 | {"精灵王":288,"阿尔法小队":588,"辉光之辰":888,"黄金射手座":1688,"如梦令":1314} |
| 4 | 铠 | 52 | {"龙域领主":288,"曙光守护者":1776} |
| 5 | 韩信 | 52 | {"飞衡":1788,"逐梦之影":888,"白龙吟":1188,"教廷特使":0,"街头霸王":888} |
+---------------------------+-----------------------------+---------------------------------+----------------------------------------------------+
5 rows selected (0.239 seconds)
3、默认分隔符案例
文件内容
建表示例
# 字段:id、team_name(战队名称)、ace_player_name(王牌选手名字)
# 数据都是原生数据类型,且字段之间分隔符是\001,因此在建表的时候可以省去row format语句,因为hive默认的分隔符就是\001。
create table t_team_ace_player(
id int,
team_name string,
ace_player_name string
);
0: jdbc:hive2://server4:10000> select * from t_team_ace_player;
INFO : Compiling command(queryId=alanchan_20221017162753_3b611f96-687f-4ec2-95d5-a8945df6c067): select * from t_team_ace_player
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:t_team_ace_player.id, type:int, comment:null), FieldSchema(name:t_team_ace_player.team_name, type:string, comment:null), FieldSchema(name:t_team_ace_player.ace_player_name, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=alanchan_20221017162753_3b611f96-687f-4ec2-95d5-a8945df6c067); Time taken: 0.176 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=alanchan_20221017162753_3b611f96-687f-4ec2-95d5-a8945df6c067): select * from t_team_ace_player
INFO : Completed executing command(queryId=alanchan_20221017162753_3b611f96-687f-4ec2-95d5-a8945df6c067); Time taken: 0.0 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+-----------------------+------------------------------+------------------------------------+
| t_team_ace_player.id | t_team_ace_player.team_name | t_team_ace_player.ace_player_name |
+-----------------------+------------------------------+------------------------------------+
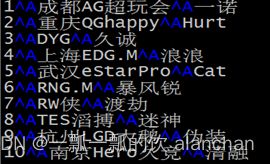
| 1 | 成都AG超玩会 | 一诺 |
| 2 | 重庆QGhappy | Hurt |
| 3 | DYG | 久诚 |
| 4 | 上海EDG.M | 浪浪 |
| 5 | 武汉eStarPro | Cat |
| 6 | RNG.M | 暴风锐 |
| 7 | RW侠 | 渡劫 |
| 8 | TES滔搏 | 迷神 |
| 9 | 杭州LGD大鹅 | 伪装 |
| 10 | 南京Hero久竞 | 清融 |
+-----------------------+------------------------------+------------------------------------+
10 rows selected (0.228 seconds)
四、内外部表
1、内部表
内部表(Internal table)也称为被Hive拥有和管理的托管表(Managed table)。
默认情况下创建的表就是内部表,Hive拥有该表的结构和文件。
Hive完全管理表(元数据和数据)的生命周期,类似于RDBMS中的表。
删除内部表时,它会删除数据以及表的元数据。
create table student(
num int,
name string,
sex string,
age int,
dept string)
row format delimited
fields terminated by ',';
0: jdbc:hive2://server4:10000> desc formatted t_user;
INFO : Compiling command(queryId=alanchan_20221017153821_c8ac2142-aacf-479c-a8f2-e040f2f791cb): desc formatted t_user
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:col_name, type:string, comment:from deserializer), FieldSchema(name:data_type, type:string, comment:from deserializer), FieldSchema(name:comment, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=alanchan_20221017153821_c8ac2142-aacf-479c-a8f2-e040f2f791cb); Time taken: 0.024 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=alanchan_20221017153821_c8ac2142-aacf-479c-a8f2-e040f2f791cb): desc formatted t_user
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=alanchan_20221017153821_c8ac2142-aacf-479c-a8f2-e040f2f791cb); Time taken: 0.037 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+-------------------------------+----------------------------------------------------+----------------------------------------------------+
| col_name | data_type | comment |
+-------------------------------+----------------------------------------------------+----------------------------------------------------+
| # col_name | data_type | comment |
| id | int | |
| name | varchar(255) | |
| age | int | |
| city | varchar(255) | |
| | NULL | NULL |
| # Detailed Table Information | NULL | NULL |
| Database: | test | NULL |
| OwnerType: | USER | NULL |
| Owner: | alanchan | NULL |
| CreateTime: | Mon Oct 17 14:47:08 CST 2022 | NULL |
| LastAccessTime: | UNKNOWN | NULL |
| Retention: | 0 | NULL |
| Location: | hdfs://HadoopHAcluster/user/hive/warehouse/test.db/t_user | NULL |
| Table Type: | MANAGED_TABLE | NULL |
| Table Parameters: | NULL | NULL |
| | COLUMN_STATS_ACCURATE | {\"BASIC_STATS\":\"true\",\"COLUMN_STATS\":{\"age\":\"true\",\"city\":\"true\",\"id\":\"true\",\"name\":\"true\"}} |
| | bucketing_version | 2 |
| | numFiles | 0 |
| | numRows | 0 |
| | rawDataSize | 0 |
| | totalSize | 0 |
| | transient_lastDdlTime | 1665989228 |
| | NULL | NULL |
| # Storage Information | NULL | NULL |
| SerDe Library: | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe | NULL |
| InputFormat: | org.apache.hadoop.mapred.TextInputFormat | NULL |
| OutputFormat: | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | NULL |
| Compressed: | No | NULL |
| Num Buckets: | -1 | NULL |
| Bucket Columns: | [] | NULL |
| Sort Columns: | [] | NULL |
| Storage Desc Params: | NULL | NULL |
| | field.delim | , |
| | serialization.format | , |
+-------------------------------+----------------------------------------------------+----------------------------------------------------+
35 rows selected (0.081 seconds)
2、外部表
外部表(External table)中的数据不是Hive拥有或管理的,只管理表元数据的生命周期。
要创建一个外部表,需要使用EXTERNAL语法关键字。
删除外部表只会删除元数据,而不会删除实际数据。在Hive外部仍然可以访问实际数据。而且外部表更为方便的是可以搭配location语法指定数据的路径。
create external table student_ext(
num int,
name string,
sex string,
age int,
dept string)
row format delimited
fields terminated by ','
location '/hivetest/stent_ext';
DESC FORMATTED test.student_ext;
0: jdbc:hive2://server4:10000> select * from student_ext;
INFO : Compiling command(queryId=alanchan_20221017164012_067f8142-73b3-4474-a8aa-17b2b5e3290f): select * from student_ext
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:student_ext.num, type:int, comment:null), FieldSchema(name:student_ext.name, type:string, comment:null), FieldSchema(name:student_ext.sex, type:string, comment:null), FieldSchema(name:student_ext.age, type:int, comment:null), FieldSchema(name:student_ext.dept, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=alanchan_20221017164012_067f8142-73b3-4474-a8aa-17b2b5e3290f); Time taken: 0.177 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=alanchan_20221017164012_067f8142-73b3-4474-a8aa-17b2b5e3290f): select * from student_ext
INFO : Completed executing command(queryId=alanchan_20221017164012_067f8142-73b3-4474-a8aa-17b2b5e3290f); Time taken: 0.001 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+------------------+-------------------+------------------+------------------+-------------------+
| student_ext.num | student_ext.name | student_ext.sex | student_ext.age | student_ext.dept |
+------------------+-------------------+------------------+------------------+-------------------+
| 95001 | 李勇 | 男 | 20 | CS |
| 95002 | 刘晨 | 女 | 19 | IS |
| 95003 | 王敏 | 女 | 22 | MA |
| 95004 | 张立 | 男 | 19 | IS |
| 95005 | 刘刚 | 男 | 18 | MA |
| 95006 | 孙庆 | 男 | 23 | CS |
| 95007 | 易思玲 | 女 | 19 | MA |
| 95008 | 李娜 | 女 | 18 | CS |
| 95009 | 梦圆圆 | 女 | 18 | MA |
| 95010 | 孔小涛 | 男 | 19 | CS |
| 95011 | 包小柏 | 男 | 18 | MA |
| 95012 | 孙花 | 女 | 20 | CS |
| 95013 | 冯伟 | 男 | 21 | CS |
| 95014 | 王小丽 | 女 | 19 | CS |
| 95015 | 王君 | 男 | 18 | MA |
| 95016 | 钱国 | 男 | 21 | MA |
| 95017 | 王风娟 | 女 | 18 | IS |
| 95018 | 王一 | 女 | 19 | IS |
| 95019 | 邢小丽 | 女 | 19 | IS |
| 95020 | 赵钱 | 男 | 21 | IS |
| 95021 | 周二 | 男 | 17 | MA |
| 95022 | 郑明 | 男 | 20 | MA |
+------------------+-------------------+------------------+------------------+-------------------+
22 rows selected (0.453 seconds)
0: jdbc:hive2://server4:10000> DESC FORMATTED test.student_ext;
INFO : Compiling command(queryId=alanchan_20221017164029_a99b89d6-9b25-4cd7-b2ff-8317e4e46ee7): DESC FORMATTED test.student_ext
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:col_name, type:string, comment:from deserializer), FieldSchema(name:data_type, type:string, comment:from deserializer), FieldSchema(name:comment, type:string, comment:from deserializer)], properties:null)
INFO : Completed compiling command(queryId=alanchan_20221017164029_a99b89d6-9b25-4cd7-b2ff-8317e4e46ee7); Time taken: 0.022 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=alanchan_20221017164029_a99b89d6-9b25-4cd7-b2ff-8317e4e46ee7): DESC FORMATTED test.student_ext
INFO : Starting task [Stage-0:DDL] in serial mode
INFO : Completed executing command(queryId=alanchan_20221017164029_a99b89d6-9b25-4cd7-b2ff-8317e4e46ee7); Time taken: 0.017 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+-------------------------------+----------------------------------------------------+-----------------------+
| col_name | data_type | comment |
+-------------------------------+----------------------------------------------------+-----------------------+
| # col_name | data_type | comment |
| num | int | |
| name | string | |
| sex | string | |
| age | int | |
| dept | string | |
| | NULL | NULL |
| # Detailed Table Information | NULL | NULL |
| Database: | test | NULL |
| OwnerType: | USER | NULL |
| Owner: | alanchan | NULL |
| CreateTime: | Mon Oct 17 16:39:29 CST 2022 | NULL |
| LastAccessTime: | UNKNOWN | NULL |
| Retention: | 0 | NULL |
| Location: | hdfs://HadoopHAcluster/hivetest/stent_ext | NULL |
| Table Type: | EXTERNAL_TABLE | NULL |
| Table Parameters: | NULL | NULL |
| | EXTERNAL | TRUE |
| | bucketing_version | 2 |
| | transient_lastDdlTime | 1665995969 |
| | NULL | NULL |
| # Storage Information | NULL | NULL |
| SerDe Library: | org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe | NULL |
| InputFormat: | org.apache.hadoop.mapred.TextInputFormat | NULL |
| OutputFormat: | org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat | NULL |
| Compressed: | No | NULL |
| Num Buckets: | -1 | NULL |
| Bucket Columns: | [] | NULL |
| Sort Columns: | [] | NULL |
| Storage Desc Params: | NULL | NULL |
| | field.delim | , |
| | serialization.format | , |
+-------------------------------+----------------------------------------------------+-----------------------+
32 rows selected (0.047 seconds)
3、内部表、外部表差异
无论内部表还是外部表,Hive都在Hive Metastore中管理表定义及其分区信息。
删除内部表会从Metastore中删除表元数据,还会从HDFS中删除其所有数据/文件。
删除外部表,只会从Metastore中删除表的元数据,并保持HDFS位置中的实际数据不变。
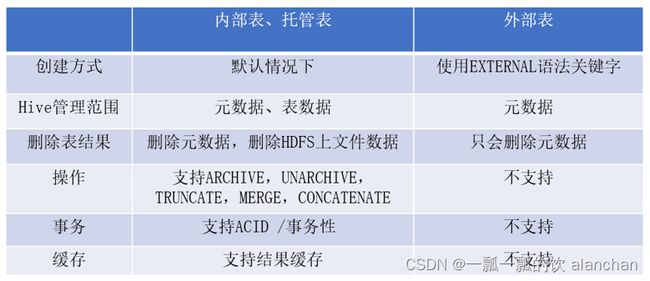
- 当需要通过Hive完全管理控制表的整个生命周期时,使用内部表。
- 当文件已经存在或位于远程位置时,使用外部表,因为即使删除表,文件也会被保留
五、Hive分区表
1、简单示例
要求通过建立一张表t_all_hero,把6份文件同时映射加载

create table t_all_hero(
id int,
name string,
hp_max int,
mp_max int,
attack_max int,
defense_max int,
attack_range string,
role_main string,
role_assist string
)
row format delimited
fields terminated by "\t";
0: jdbc:hive2://server4:10000> select * from t_all_hero;
INFO : Compiling command(queryId=alanchan_20221017164736_9349bd30-f543-4814-92ef-393d5779679b): select * from t_all_hero
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:t_all_hero.id, type:int, comment:null), FieldSchema(name:t_all_hero.name, type:string, comment:null), FieldSchema(name:t_all_hero.hp_max, type:int, comment:null), FieldSchema(name:t_all_hero.mp_max, type:int, comment:null), FieldSchema(name:t_all_hero.attack_max, type:int, comment:null), FieldSchema(name:t_all_hero.defense_max, type:int, comment:null), FieldSchema(name:t_all_hero.attack_range, type:string, comment:null), FieldSchema(name:t_all_hero.role_main, type:string, comment:null), FieldSchema(name:t_all_hero.role_assist, type:string, comment:null)], properties:null)
INFO : Completed compiling command(queryId=alanchan_20221017164736_9349bd30-f543-4814-92ef-393d5779679b); Time taken: 0.102 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=alanchan_20221017164736_9349bd30-f543-4814-92ef-393d5779679b): select * from t_all_hero
INFO : Completed executing command(queryId=alanchan_20221017164736_9349bd30-f543-4814-92ef-393d5779679b); Time taken: 0.001 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+----------------+------------------+--------------------+--------------------+------------------------+-------------------------+--------------------------+-----------------------+-------------------------+
| t_all_hero.id | t_all_hero.name | t_all_hero.hp_max | t_all_hero.mp_max | t_all_hero.attack_max | t_all_hero.defense_max | t_all_hero.attack_range | t_all_hero.role_main | t_all_hero.role_assist |
+----------------+------------------+--------------------+--------------------+------------------------+-------------------------+--------------------------+-----------------------+-------------------------+
| 1 | 后羿 | 5986 | 1784 | 396 | 336 | remotely | archer | NULL |
| 2 | 马可波罗 | 5584 | 200 | 362 | 344 | remotely | archer | NULL |
| 3 | 鲁班七号 | 5989 | 1756 | 400 | 323 | remotely | archer | NULL |
| 4 | 李元芳 | 5725 | 1770 | 396 | 340 | remotely | archer | NULL |
| 5 | 孙尚香 | 6014 | 1756 | 411 | 346 | remotely | archer | NULL |
| 6 | 黄忠 | 5898 | 1784 | 403 | 319 | remotely | archer | NULL |
| 7 | 狄仁杰 | 5710 | 1770 | 376 | 338 | remotely | archer | NULL |
| 8 | 虞姬 | 5669 | 1770 | 407 | 329 | remotely | archer | NULL |
| 9 | 成吉思汗 | 5799 | 1742 | 394 | 329 | remotely | archer | NULL |
| 10 | 百里守约 | 5611 | 1784 | 410 | 329 | remotely | archer | assassin |
| 11 | 橘石京 | 7000 | 0 | 347 | 392 | melee | assassin | warrior |
| 12 | 李白 | 5483 | 1808 | 330 | 358 | melee | assassin | warrior |
| 13 | 韩信 | 5655 | 1704 | 386 | 323 | melee | assassin | warrior |
| 14 | 阿轲 | 5968 | 0 | 427 | 349 | melee | assassin | NULL |
select count(*) from t_all_hero where role_main="archer" and hp_max >6000;
# where语句的背后需要进行全表扫描才能过滤出结果,对于hive来说需要扫描表下面的每一个文件。
# 如果数据文件特别多的话,效率很慢也没必要。
2、分区表的概念、创建
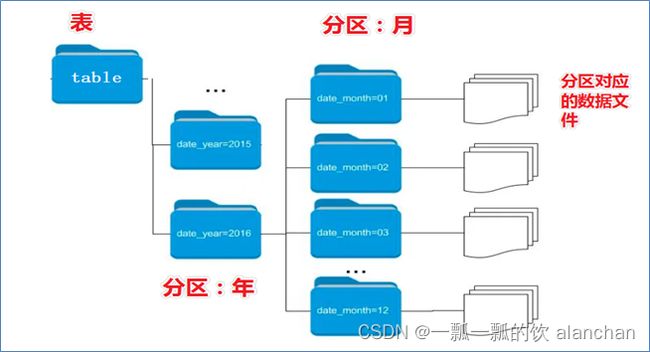
当Hive表对应的数据量大、文件多时,为了避免查询时全表扫描数据,Hive支持根据用户指定的字段进行分区,分区的字段可以是日期、地域、种类等具有标识意义的字段。比如把一整年的数据根据月份划分12个月(12个分区),后续就可以查询指定月份分区的数据,尽可能避免了全表扫描查询。
1)、语法
CREATE TABLE table_name (column1 data_type, column2 data_type)
PARTITIONED BY (partition1 data_type, partition2 data_type,….)
;
2)、示例
针对《王者荣耀》英雄数据,重新创建一张分区表t_all_hero_part,以role角色作为分区字段。
create table t_all_hero_part(
id int,
name string,
hp_max int,
mp_max int,
attack_max int,
defense_max int,
attack_range string,
role_main string,
role_assist string
)
partitioned by (role string)
row format delimited
fields terminated by "\t";
分区字段不能是表中已经存在的字段,因为分区字段最终也会以虚拟字段的形式显示在表结构上。
3、分区表数据加载–静态分区
所谓静态分区指的是分区的字段值是由用户在加载数据的时候手动指定的。
语法如下
load data [local] inpath ' ' into table tablename partition(分区字段='分区值'...);
Local表示数据是位于本地文件系统还是HDFS文件系统。
静态加载数据操作如下,文件都位于Hive服务器所在机器本地文件系统上。
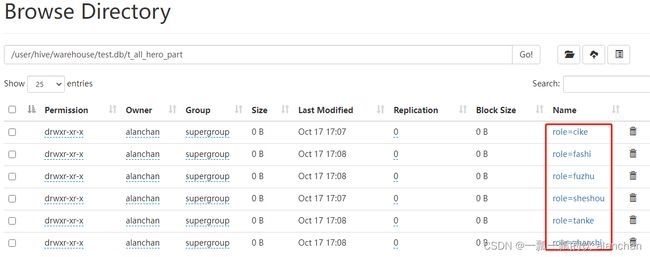
load data inpath '/hivetest/partition/archer(335).txt' into table t_all_hero_part partition(role='sheshou');
load data inpath '/hivetest/partition/assassin.txt' into table t_all_hero_part partition(role='cike');
load data inpath '/hivetest/partition/mage.txt' into table t_all_hero_part partition(role='fashi');
load data inpath '/hivetest/partition/support.txt' into table t_all_hero_part partition(role='fuzhu');
load data inpath '/hivetest/partition/tank.txt' into table t_all_hero_part partition(role='tanke');
load data inpath '/hivetest/partition/warrior.txt' into table t_all_hero_part partition(role='zhanshi');
#验证
select * from t_all_hero_part;
4、分区表数据加载–动态分区
往hive分区表中插入加载数据时,如果需要创建的分区很多,则需要复制粘贴修改很多sql去执行,效率低。因为hive是批处理系统,所以hive提供了一个动态分区功能,其可以基于查询参数的位置去推断分区的名称,从而建立分区。
所谓动态分区指的是分区的字段值是基于查询结果自动推断出来的。
核心语法就是insert+select。
启用hive动态分区,需要在hive会话中设置两个参数:
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
# 第一个参数表示开启动态分区功能
# 第二个参数指定动态分区的模式。
# 分为nonstick非严格模式和strict严格模式。strict严格模式要求至少有一个分区为静态分区。
# 创建一张新的分区表t_all_hero_part_dynamic
create table t_all_hero_part_dynamic(
id int,
name string,
hp_max int,
mp_max int,
attack_max int,
defense_max int,
attack_range string,
role_main string,
role_assist string
) partitioned by (role string)
row format delimited
fields terminated by "\t";
# 执行动态分区插入,通过MR执行
insert into table t_all_hero_part_dynamic partition(role) select tmp.*,tmp.role_main from t_all_hero tmp;
动态分区插入时,分区值是根据查询返回字段位置自动推断的。
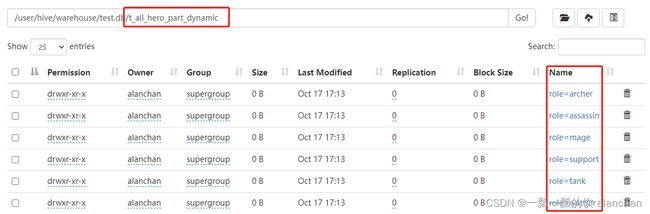
5、分区表的本质
外表上看起来分区表好像没多大变化,只不过多了一个分区字段。实际上在底层管理数据的方式发生了改变。
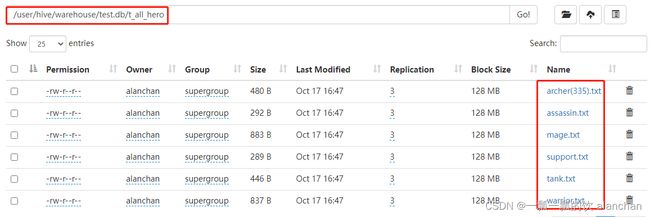
- 非分区表:t_all_hero
- 分区表:t_all_hero_part
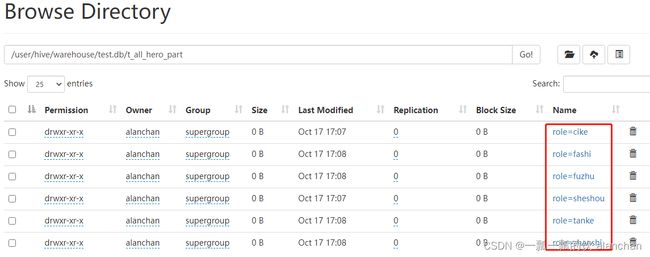
分区的概念提供了一种将Hive表数据分离为多个文件/目录的方法。
不同分区对应着不同的文件夹,同一分区的数据存储在同一个文件夹下。
只需要根据分区值找到对应的文件夹,扫描本分区下的文件即可,避免全表数据扫描。
6、分区表的使用
分区表的使用重点在于
- 建表时根据业务场景设置合适的分区字段。比如日期、地域、类别等;
- 查询的时候尽量先使用where进行分区过滤,查询指定分区的数据,避免全表扫描。
比如:查询英雄主要定位是射手并且最大生命大于6000的个数。使用分区表查询和使用非分区表进行查询,SQL如下:
--非分区表 全表扫描过滤查询
select count(*) from t_all_hero where role_main="archer" and hp_max >6000;
--分区表 先基于分区过滤 再查询
select count(*) from t_all_hero_part where role="sheshou" and hp_max >6000;
7、分区表的注意事项
- 分区表不是建表的必要语法规则,是一种优化手段表,可选;
- 分区字段不能是表中已有的字段,不能重复;
- 分区字段是虚拟字段,其数据并不存储在底层的文件中;
- 分区字段值的确定来自于用户价值数据手动指定(静态分区)或者根据查询结果位置自动推断(动态分区)
- Hive支持多重分区,也就是说在分区的基础上继续分区,划分更加细粒度
8、多重分区表
通过建表语句中关于分区的相关语法可以发现,Hive支持多个分区字段:PARTITIONED BY (partition1 data_type, partition2 data_type,….)。
多重分区下,分区之间是一种递进关系,可以理解为在前一个分区的基础上继续分区。从HDFS的角度来看就是文件夹下继续划分子文件夹。比如:把全国人口数据首先根据省进行分区,然后根据市进行划分,如果你需要甚至可以继续根据区县再划分,此时就是3分区表。
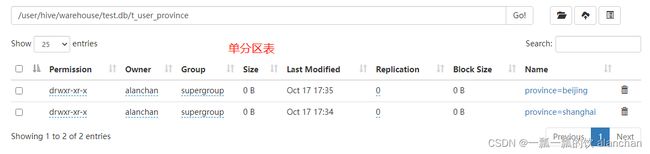
1)、示例1:单分区表,按省份分区
--单分区表,按省份分区
create table t_user_province (id int, name string,age int)
partitioned by (province string)
row format delimited
fields terminated by ",";
;
多分区表的数据插入(静态加载)和查询使用。此处仅为示例,同一份数据源,加载到不同的表中。
指定的数据会是全部加载到同一个分区中,一个数据是否属于某一个分区,静态加载时由人为控制。
load data local inpath '/usr/local/bigdata/apache-hive-3.1.2-bin/test' into table t_user_province partition(province='shanghai');
load data local inpath '/usr/local/bigdata/apache-hive-3.1.2-bin/test' into table t_user_province partition(province='beijing');
0: jdbc:hive2://server4:10000> select * from t_user_province where province='shanghai';
+---------------------+-----------------------+----------------------+---------------------------+
| t_user_province.id | t_user_province.name | t_user_province.age | t_user_province.province |
+---------------------+-----------------------+----------------------+---------------------------+
| 1 | zhangsan | 18 | beijing |
| 2 | lisi | 25 | beijing |
| 3 | allen | 30 | beijing |
| 4 | woon | 15 | beijing |
| 5 | james | 45 | beijing |
| 6 | tony | 26 | beijing |
| 1 | zhangsan | 18 | shanghai |
| 2 | lisi | 25 | shanghai |
| 3 | allen | 30 | shanghai |
| 4 | woon | 15 | shanghai |
| 5 | james | 45 | shanghai |
| 6 | tony | 26 | shanghai |
+---------------------+-----------------------+----------------------+---------------------------+
0: jdbc:hive2://server4:10000> select * from t_user_province where province='shanghai';
+---------------------+-----------------------+----------------------+---------------------------+
| t_user_province.id | t_user_province.name | t_user_province.age | t_user_province.province |
+---------------------+-----------------------+----------------------+---------------------------+
| 1 | zhangsan | 18 | shanghai |
| 2 | lisi | 25 | shanghai |
| 3 | allen | 30 | shanghai |
| 4 | woon | 15 | shanghai |
| 5 | james | 45 | shanghai |
| 6 | tony | 26 | shanghai |
+---------------------+-----------------------+----------------------+---------------------------+
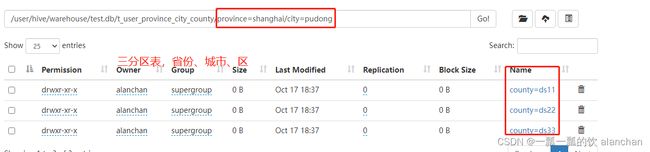
2)、示例2:双分区表,按省份和市分区
--双分区表,按省份和市分区
create table t_user_province_city (id int, name string,age int)
partitioned by (province string, city string)
row format delimited
fields terminated by ",";
;
load data local inpath '/usr/local/bigdata/apache-hive-3.1.2-bin/test' into table t_user_province_city partition(province='shanghai',city='pudong');
load data local inpath '/usr/local/bigdata/apache-hive-3.1.2-bin/test' into table t_user_province_city partition(province='shanghai',city='putuo');
load data local inpath '/usr/local/bigdata/apache-hive-3.1.2-bin/test' into table t_user_province_city partition(province='beijing',city='daxing');
load data local inpath '/usr/local/bigdata/apache-hive-3.1.2-bin/test' into table t_user_province_city partition(province='beijing',city='haidian');
0: jdbc:hive2://server4:10000> select * from t_user_province_city ;
+--------------------------+----------------------------+---------------------------+--------------------------------+----------------------------+
| t_user_province_city.id | t_user_province_city.name | t_user_province_city.age | t_user_province_city.province | t_user_province_city.city |
+--------------------------+----------------------------+---------------------------+--------------------------------+----------------------------+
| 1 | zhangsan | 18 | beijing | daxing |
| 2 | lisi | 25 | beijing | daxing |
| 3 | allen | 30 | beijing | daxing |
| 4 | woon | 15 | beijing | daxing |
| 5 | james | 45 | beijing | daxing |
| 6 | tony | 26 | beijing | daxing |
| 1 | zhangsan | 18 | beijing | haidian |
| 2 | lisi | 25 | beijing | haidian |
| 3 | allen | 30 | beijing | haidian |
| 4 | woon | 15 | beijing | haidian |
| 5 | james | 45 | beijing | haidian |
| 6 | tony | 26 | beijing | haidian |
| 1 | zhangsan | 18 | shanghai | pudong |
| 2 | lisi | 25 | shanghai | pudong |
| 3 | allen | 30 | shanghai | pudong |
| 4 | woon | 15 | shanghai | pudong |
| 5 | james | 45 | shanghai | pudong |
| 6 | tony | 26 | shanghai | pudong |
| 1 | zhangsan | 18 | shanghai | putuo |
| 2 | lisi | 25 | shanghai | putuo |
| 3 | allen | 30 | shanghai | putuo |
| 4 | woon | 15 | shanghai | putuo |
| 5 | james | 45 | shanghai | putuo |
| 6 | tony | 26 | shanghai | putuo |
+--------------------------+----------------------------+---------------------------+--------------------------------+----------------------------+
0: jdbc:hive2://server4:10000> select * from t_user_province_city where province='shanghai' ;
+--------------------------+----------------------------+---------------------------+--------------------------------+----------------------------+
| t_user_province_city.id | t_user_province_city.name | t_user_province_city.age | t_user_province_city.province | t_user_province_city.city |
+--------------------------+----------------------------+---------------------------+--------------------------------+----------------------------+
| 1 | zhangsan | 18 | shanghai | pudong |
| 2 | lisi | 25 | shanghai | pudong |
| 3 | allen | 30 | shanghai | pudong |
| 4 | woon | 15 | shanghai | pudong |
| 5 | james | 45 | shanghai | pudong |
| 6 | tony | 26 | shanghai | pudong |
| 1 | zhangsan | 18 | shanghai | putuo |
| 2 | lisi | 25 | shanghai | putuo |
| 3 | allen | 30 | shanghai | putuo |
| 4 | woon | 15 | shanghai | putuo |
| 5 | james | 45 | shanghai | putuo |
| 6 | tony | 26 | shanghai | putuo |
+--------------------------+----------------------------+---------------------------+--------------------------------+----------------------------+
0: jdbc:hive2://server4:10000> select * from t_user_province_city where province='shanghai' and city = 'pudong';
+--------------------------+----------------------------+---------------------------+--------------------------------+----------------------------+
| t_user_province_city.id | t_user_province_city.name | t_user_province_city.age | t_user_province_city.province | t_user_province_city.city |
+--------------------------+----------------------------+---------------------------+--------------------------------+----------------------------+
| 1 | zhangsan | 18 | shanghai | pudong |
| 2 | lisi | 25 | shanghai | pudong |
| 3 | allen | 30 | shanghai | pudong |
| 4 | woon | 15 | shanghai | pudong |
| 5 | james | 45 | shanghai | pudong |
| 6 | tony | 26 | shanghai | pudong |
+--------------------------+----------------------------+---------------------------+--------------------------------+----------------------------+
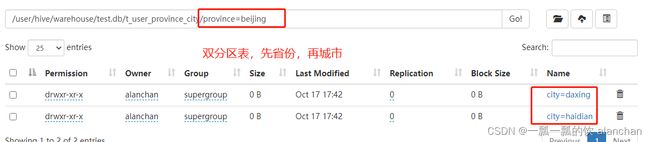
3)、示例3:三分区表,按省份、市、县分区
--三分区表,按省份、市、县分区
create table t_user_province_city_county (id int, name string,age int)
partitioned by (province string, city string,county string)
row format delimited
fields terminated by ",";
;
多分区表的数据插入(静态加载)和查询使用。此处仅为示例,同一份数据源,加载到不同的表中。
指定的数据会是全部加载到同一个分区中,一个数据是否属于某一个分区,静态加载时由人为控制。
load data local inpath '/usr/local/bigdata/apache-hive-3.1.2-bin/test' into table t_user_province_city_county partition(province='beijing',city='haidian',county='ds1');
load data local inpath '/usr/local/bigdata/apache-hive-3.1.2-bin/test' into table t_user_province_city_county partition(province='beijing',city='haidian',county='ds2');
load data local inpath '/usr/local/bigdata/apache-hive-3.1.2-bin/test' into table t_user_province_city_county partition(province='beijing',city='haidian',county='ds3');
load data local inpath '/usr/local/bigdata/apache-hive-3.1.2-bin/test' into table t_user_province_city_county partition(province='beijing',city='daxing',county='ds11');
load data local inpath '/usr/local/bigdata/apache-hive-3.1.2-bin/test' into table t_user_province_city_county partition(province='beijing',city='daxing',county='ds22');
load data local inpath '/usr/local/bigdata/apache-hive-3.1.2-bin/test' into table t_user_province_city_county partition(province='beijing',city='daxing',county='ds33');
load data local inpath '/usr/local/bigdata/apache-hive-3.1.2-bin/test' into table t_user_province_city_county partition(province='shanghai',city='putuo',county='ds1');
load data local inpath '/usr/local/bigdata/apache-hive-3.1.2-bin/test' into table t_user_province_city_county partition(province='shanghai',city='putuo',county='ds2');
load data local inpath '/usr/local/bigdata/apache-hive-3.1.2-bin/test' into table t_user_province_city_county partition(province='shanghai',city='putuo',county='ds3');
load data local inpath '/usr/local/bigdata/apache-hive-3.1.2-bin/test' into table t_user_province_city_county partition(province='shanghai',city='pudong',county='ds11');
load data local inpath '/usr/local/bigdata/apache-hive-3.1.2-bin/test' into table t_user_province_city_county partition(province='shanghai',city='pudong',county='ds22');
load data local inpath '/usr/local/bigdata/apache-hive-3.1.2-bin/test' into table t_user_province_city_county partition(province='shanghai',city='pudong',county='ds33');
load data local inpath '文件路径' into table t_user_province partition(province='shanghai');
load data local inpath '文件路径' into table t_user_province_city_county partition(province='zhejiang',city='hangzhou',county='xiaoshan');
select * from t_user_province_city_county ;
select * from t_user_province_city_county where province='shanghai';
select * from t_user_province_city_county where province='shanghai' and city='putuo';
select * from t_user_province_city_county where province='shanghai' and city='putuo' and county = 'ds1';
六、Hive分桶表
1、分桶表的概念
分桶表也叫做桶表,源自建表语法中bucket单词。
是一种用于优化查询而设计的表类型。
该功能可以让数据分解为若干个部分易于管理。
在分桶时,要指定根据哪个字段将数据分为几桶(几个部分)。
默认规则是Bucket number = hash_function(bucketing_column) mod num_buckets。
可以发现桶编号相同的数据会被分到同一个桶当中。
hash_function取决于分桶字段bucketing_column的类型:
如果是int类型,hash_function(int) == int;
如果是其他类型,比如bigint,string或者复杂数据类型,hash_function比较棘手,将是从该类型派生的某个数字,比如hashcode值。
2、分桶表的语法
--分桶表建表语句
CREATE [EXTERNAL] TABLE [db_name.]table_name[(col_name data_type, ...)]
CLUSTERED BY (col_name)
INTO N BUCKETS;
其中CLUSTERED BY (col_name)表示根据哪个字段进行分;
INTO N BUCKETS表示分为几桶(也就是几个部分)。
需要注意的是,分桶的字段必须是表中已经存在的字段。
3、分桶表的创建
-- 根据state州把数据分为5桶,建表语句如下:
CREATE TABLE test.t_usa_covid19(
count_date string,
county string,
state string,
fips int,
cases int,
deaths int
)
CLUSTERED BY(state) INTO 5 BUCKETS;
在创建分桶表时,还可以指定分桶内的数据排序规则
--根据state州分为5桶 每个桶内根据cases确诊病例数倒序排序
CREATE TABLE test.t_usa_covid19_bucket_sort(
count_date string,
county string,
state string,
fips int,
cases int,
deaths int
)
CLUSTERED BY(state) sorted by (cases desc) INTO 5 BUCKETS;
CREATE TABLE test.t_user_bucket(
id int,
name string,
age int,
city string
)
CLUSTERED BY(city) INTO 5 BUCKETS;
insert into t_user_bucket select * from t_user;
4、分桶表的数据加载
--step1:开启分桶的功能 从Hive2.0开始不再需要设置
set hive.enforce.bucketing=true;
--step2:把源数据加载到普通hive表中
CREATE TABLE test.t_usa_covid19(
count_date string,
county string,
state string,
fips int,
cases int,
deaths int
)
row format delimited fields terminated by ",";
--将源数据上传到HDFS,t_usa_covid19表对应的路径下
hadoop fs -put us-covid19-counties.dat /user/hive/warehouse/test.db/t_usa_covid19
--step3:使用insert+select语法将数据加载到分桶表中
insert into t_usa_covid19_bucket_sort select * from t_usa_covid19;
#如果一直出现Stage-1 map = 0%, reduce = 0% 重启--service metastore和--service hiveserver2。也可能是重启yarn后,需要重启这俩服务。
0: jdbc:hive2://server4:10000> insert into t_usa_covid19_bucket_sort select * from t_usa_covid19;
INFO : Compiling command(queryId=alanchan_20221018173902_d2377188-0834-4c38-85fa-fa4613609b17): insert into t_usa_covid19_bucket_sort select * from t_usa_covid19
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:t_usa_covid19.count_date, type:string, comment:null), FieldSchema(name:t_usa_covid19.county, type:string, comment:null), FieldSchema(name:t_usa_covid19.state, type:string, comment:null), FieldSchema(name:t_usa_covid19.fips, type:int, comment:null), FieldSchema(name:t_usa_covid19.cases, type:int, comment:null), FieldSchema(name:t_usa_covid19.deaths, type:int, comment:null)], properties:null)
INFO : Completed compiling command(queryId=alanchan_20221018173902_d2377188-0834-4c38-85fa-fa4613609b17); Time taken: 0.28 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=alanchan_20221018173902_d2377188-0834-4c38-85fa-fa4613609b17): insert into t_usa_covid19_bucket_sort select * from t_usa_covid19
WARN : Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
INFO : Query ID = alanchan_20221018173902_d2377188-0834-4c38-85fa-fa4613609b17
INFO : Total jobs = 2
INFO : Launching Job 1 out of 2
INFO : Starting task [Stage-1:MAPRED] in serial mode
INFO : Number of reduce tasks determined at compile time: 5
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:1
INFO : Submitting tokens for job: job_1666082878454_0011
INFO : Executing with tokens: []
INFO : The url to track the job: http://server1:8088/proxy/application_1666082878454_0011/
INFO : Starting Job = job_1666082878454_0011, Tracking URL = http://server1:8088/proxy/application_1666082878454_0011/
INFO : Kill Command = /usr/local/bigdata/hadoop-3.1.4/bin/mapred job -kill job_1666082878454_0011
INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 5
INFO : 2022-10-18 17:39:52,858 Stage-1 map = 0%, reduce = 0%
INFO : 2022-10-18 17:39:58,965 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.29 sec
INFO : 2022-10-18 17:40:05,091 Stage-1 map = 100%, reduce = 20%, Cumulative CPU 5.88 sec
INFO : 2022-10-18 17:40:10,201 Stage-1 map = 100%, reduce = 40%, Cumulative CPU 9.55 sec
INFO : 2022-10-18 17:40:15,297 Stage-1 map = 100%, reduce = 60%, Cumulative CPU 13.29 sec
INFO : 2022-10-18 17:40:19,362 Stage-1 map = 100%, reduce = 80%, Cumulative CPU 16.89 sec
INFO : 2022-10-18 17:40:23,427 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 20.31 sec
INFO : MapReduce Total cumulative CPU time: 20 seconds 310 msec
INFO : Ended Job = job_1666082878454_0011
INFO : Starting task [Stage-0:MOVE] in serial mode
INFO : Loading data to table test.t_usa_covid19_bucket_sort from hdfs://HadoopHAcluster/user/hive/warehouse/test.db/t_usa_covid19_bucket_sort/.hive-staging_hive_2022-10-18_17-39-02_104_4508105226998765089-1/-ext-10000
INFO : Launching Job 2 out of 2
INFO : Starting task [Stage-3:MAPRED] in serial mode
INFO : Number of reduce tasks determined at compile time: 1
INFO : In order to change the average load for a reducer (in bytes):
INFO : set hive.exec.reducers.bytes.per.reducer=<number>
INFO : In order to limit the maximum number of reducers:
INFO : set hive.exec.reducers.max=<number>
INFO : In order to set a constant number of reducers:
INFO : set mapreduce.job.reduces=<number>
INFO : number of splits:1
INFO : Submitting tokens for job: job_1666082878454_0012
INFO : Executing with tokens: []
INFO : The url to track the job: http://server1:8088/proxy/application_1666082878454_0012/
INFO : Starting Job = job_1666082878454_0012, Tracking URL = http://server1:8088/proxy/application_1666082878454_0012/
INFO : Kill Command = /usr/local/bigdata/hadoop-3.1.4/bin/mapred job -kill job_1666082878454_0012
INFO : Hadoop job information for Stage-3: number of mappers: 1; number of reducers: 1
INFO : 2022-10-18 17:41:15,668 Stage-3 map = 0%, reduce = 0%
INFO : 2022-10-18 17:41:16,687 Stage-3 map = 100%, reduce = 0%, Cumulative CPU 2.31 sec
INFO : 2022-10-18 17:41:17,705 Stage-3 map = 100%, reduce = 100%, Cumulative CPU 2.76 sec
INFO : MapReduce Total cumulative CPU time: 2 seconds 760 msec
INFO : Ended Job = job_1666082878454_0012
INFO : Starting task [Stage-2:STATS] in serial mode
INFO : MapReduce Jobs Launched:
INFO : Stage-Stage-1: Map: 1 Reduce: 5 Cumulative CPU: 20.31 sec HDFS Read: 190944 HDFS Write: 151433 SUCCESS
INFO : Stage-Stage-3: Map: 1 Reduce: 1 Cumulative CPU: 2.76 sec HDFS Read: 51085 HDFS Write: 913737 SUCCESS
INFO : Total MapReduce CPU Time Spent: 23 seconds 70 msec
INFO : Completed executing command(queryId=alanchan_20221018173902_d2377188-0834-4c38-85fa-fa4613609b17); Time taken: 136.595 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
No rows affected (136.881 seconds)
到HDFS上查看t_usa_covid19_bucket底层数据结构可以发现,数据被分为了5个部分。
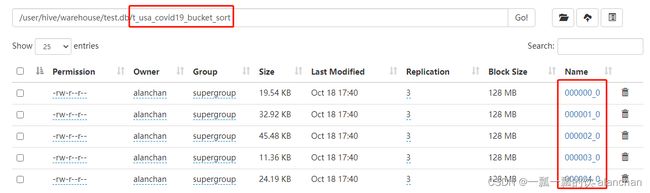
并且从结果可以发现,只要hash_function(bucketing_column)一样的,就一定被分到同一个桶中。
0: jdbc:hive2://server4:10000> select * from t_usa_covid19_bucket_sort where state = 'New York' limit 10;
INFO : Compiling command(queryId=alanchan_20221018174416_dd42394c-c5dc-4f3c-9268-469782a917ec): select * from t_usa_covid19_bucket_sort where state = 'New York' limit 10
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Semantic Analysis Completed (retrial = false)
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:t_usa_covid19_bucket_sort.count_date, type:string, comment:null), FieldSchema(name:t_usa_covid19_bucket_sort.county, type:string, comment:null), FieldSchema(name:t_usa_covid19_bucket_sort.state, type:string, comment:null), FieldSchema(name:t_usa_covid19_bucket_sort.fips, type:int, comment:null), FieldSchema(name:t_usa_covid19_bucket_sort.cases, type:int, comment:null), FieldSchema(name:t_usa_covid19_bucket_sort.deaths, type:int, comment:null)], properties:null)
INFO : Completed compiling command(queryId=alanchan_20221018174416_dd42394c-c5dc-4f3c-9268-469782a917ec); Time taken: 0.428 seconds
INFO : Concurrency mode is disabled, not creating a lock manager
INFO : Executing command(queryId=alanchan_20221018174416_dd42394c-c5dc-4f3c-9268-469782a917ec): select * from t_usa_covid19_bucket_sort where state = 'New York' limit 10
INFO : Completed executing command(queryId=alanchan_20221018174416_dd42394c-c5dc-4f3c-9268-469782a917ec); Time taken: 0.0 seconds
INFO : OK
INFO : Concurrency mode is disabled, not creating a lock manager
+---------------------------------------+-----------------------------------+----------------------------------+---------------------------------+----------------------------------+-----------------------------------+
| t_usa_covid19_bucket_sort.count_date | t_usa_covid19_bucket_sort.county | t_usa_covid19_bucket_sort.state | t_usa_covid19_bucket_sort.fips | t_usa_covid19_bucket_sort.cases | t_usa_covid19_bucket_sort.deaths |
+---------------------------------------+-----------------------------------+----------------------------------+---------------------------------+----------------------------------+-----------------------------------+
| 2021-01-28 | New York City | New York | NULL | 591160 | 26856 |
| 2021-01-28 | Suffolk | New York | 36103 | 140113 | 2756 |
| 2021-01-28 | Nassau | New York | 36059 | 125370 | 2655 |
| 2021-01-28 | Westchester | New York | 36119 | 92061 | 1875 |
| 2021-01-28 | Erie | New York | 36029 | 56080 | 1444 |
| 2021-01-28 | Monroe | New York | 36055 | 47196 | 857 |
| 2021-01-28 | Rockland | New York | 36087 | 33995 | 645 |
| 2021-01-28 | Orange | New York | 36071 | 31393 | 586 |
| 2021-01-28 | Onondaga | New York | 36067 | 29588 | 566 |
| 2021-01-28 | Dutchess | New York | 36027 | 18553 | 347 |
+---------------------------------------+-----------------------------------+----------------------------------+---------------------------------+----------------------------------+-----------------------------------+
10 rows selected (0.45 seconds)
5、分桶表的作用
和非分桶表相比,分桶表的使用好处有以下几点:
- 基于分桶字段查询时,减少全表扫描
--基于分桶字段state查询来自于New York州的数据
--不再需要进行全表扫描过滤
--根据分桶的规则hash_function(New York) mod 5计算出分桶编号
--查询指定分桶里面的数据 就可以找出结果 此时是分桶扫描而不是全表扫描
select * from t_usa_covid19_bucket where state="New York";
- JOIN时可以提高MR程序效率,减少笛卡尔积数量
对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了分桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。

以上,详细介绍了hive的ddl、数据类型、内外部表、分区与分桶表的介绍与示例。