宏任务和微任务
采纳 JSC 引擎的术语,我们把宿主发起的任务称为宏观任务,把 JavaScript 引擎发起的任务称为微观任务。
JavaScript 引擎等待宿主环境分配宏观任务,在操作系统中,通常等待的行为都是一个事件循环,所以在 Node 术语中,也会把这个部分称为事件循环。在底层的 C/C++ 代码中,这个事件循环是一个跑在独立线程中的循环。
宏观任务的队列就相当于事件循环。
在宏观任务中,JavaScript 的 Promise 还会产生异步代码,JavaScript 必须保证这些异步代码在一个宏观任务中完成,因此,每个宏观任务中又包含了一个微观任务队列。
语句的执行过程 (Completion Record )
我们知道有的语句按顺序执行,有的语句会阻断执行。那么这是何种原因导致的呢?
我们来看一下js语句执行的完成状态。JavaScript 语句执行的完成状态,我们用一个标准类型来表示:Completion Record。
Completion Record 表示一个语句执行完之后的结果,它有三个字段:
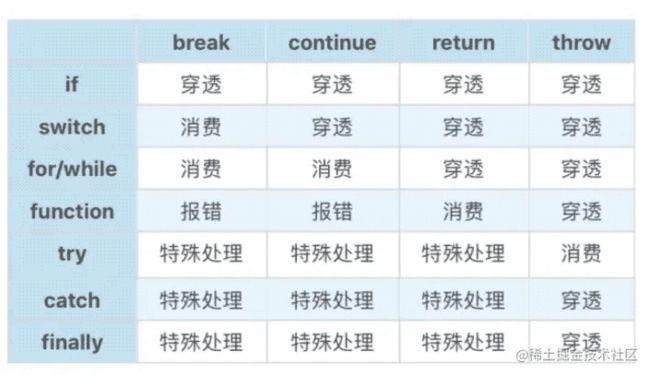
- [[type]] 表示完成的类型,有 break continue return throw 和 normal 几种类型;如果返回的type是normal,那么语句将会顺序执行。
- [[value]] 表示语句的返回值,如果语句没有,则是 empty;只有表达式语句会产生 [[value]]。
- [[target]] 表示语句的目标,通常是一个 JavaScript 标签。当在循环语句中,结合break/continue可以跳出多层循环。
outer: while(true) {
inner: while(true) {
break outer;
}
}
console.log("finished")
在任何一个js语句之前都可以加一个标签。
firstStatement: var i = 1;
控制语句跟 break 、continue 、return 、throw四种类型与控制语句两两组合产生的效果。
- 消费就是在当前语句中结束了。
穿透就是继续执行下一条语句。
文法
文法 = 词法 + 语法。
词法
JavaScript 源代码中的输入可以这样分类:
WhiteSpace 空白字符
LineTerminator 换行符
Comment 注释
Token 词
- IdentifierName 标识符名称,典型案例是我们使用的变量名,注意这里关键字也包含在内了。
- Punctuator 符号,我们使用的运算符和大括号等符号。
- NumericLiteral 数字直接量,就是我们写的数字。 为什么
12.toString会报错?
十进制的 Number 可以带小数,小数点前后部分都可以省略,但是不能同时省略。12.被当成一个词。如果想让表达式正常运行,我们可以让.成为一个词。
12. toString()
- StringLiteral 字符串直接量,就是我们用单引号或者双引号引起来的直接量。
字符串中其他必须转义的字符是\和所有换行符。
- Template 字符串模板,用反引号`括起来的直接量。
- RegularExpressionLiteral
正则表达式有自己的语法规则,在词法阶段,仅会对它做简单解析。
语句是否需要加分号
自动插入分号规则其实独立于所有的语法产生式定义,它的规则说起来非常简单,只有三条。
- 要有换行符,且下一个符号是不符合语法的,那么就尝试插入分号。
- 有换行符,且语法中规定此处不能有换行符,那么就自动插入分号。
- 源代码结束处,不能形成完整的脚本或者模块结构,那么就自动插入分号。
no LineTerminator here规则
这个规则与自动插入分号的第二条规则紧密相关。

脚本和模块
脚本是可以由浏览器或者 node 环境引入执行的,而模块只能由 JavaScript 代码用 import引入执行。
从概念上,我们可以认为脚本具有主动性的 JavaScript 代码段,是控制宿主完成一定任务的代码;而模块是被动性的 JavaScript 代码段,是等待被调用的库。
直接 import 一个模块,只是保证了这个模块代码被执行,引用它的模块是无法获得它的任何信息的。带 from 的 import 意思是引入模块中的一部分信息,可以把它们变成本地的变量。
通过export default导出的值,和导入文件的变量不是实时绑定的。导出文件的变量改变不会影响导入变量的变化。
声明提升
预处理阶段,var 和函数声明的作用能够穿透一切语句结构,它只认脚本、模块和函数体三种语法结构。
函数声明提升和var变量声明提升的区别
函数声明能穿过if等语句,但是只是在全局创建一个同名的变量赋值为undefined,并没有把函数体提升。
console.log(foo); // undefined
if(true) {
function foo(){}
}
// 因为一般函数都是整体提升的。
var a = 1;
function foo() {
console.log(a); // undefined
if(false) {
var a = 2;
}
}
foo();
解析HTML
编译阶段。会将html标签拆分成一个个token(表示最小的有意义的单元), 种类大约只有标签开始、属性、标签结束、注释、CDATA 节点几种。
实现分词,又用到了状态机。用状态机做词法分析,其实正是把每个词的“特征字符”逐个拆开成独立状态,然后再把所有词的特征字符链合起来,形成一个联通图结构。 其中每一个状态函数都返回一个状态函数,做状态迁移。
把html元素分成若干词后,我们就可以构建dom树了。这个过程是使用栈来实现的。我们把每个解析的词加入到栈中,当接收完所有输入,栈顶就是最后的根节点。
对于 Text 节点,我们则需要把相邻的 Text 节点合并起来,我们的做法是当词(token)入栈时,检查栈顶是否是 Text 节点,如果是的话就合并 Text 节点。
可以点击这里查看解析规则
github上别人写了一个简易的解析器
排版。
- 浏览器对行的排版,一般是先行内布局,再确定行的位置,根据行的位置计算出行内盒和文字的排版位置。
- 块级盒比较简单,它总是单独占据一整行,计算出交叉轴方向的高度即可。
- 浮动元素排版,float 元素非常特别,浏览器对 float 的处理是先排入正常流,再移动到排版宽度的最左 /最右(这里实际上是主轴的最前和最后)。
- 绝对定位元素。完全跟正常流无关的一种独立排版模式,逐层找到其父级的 position 非 static 元素即可。
渲染。
浏览器中渲染这个过程,就是把每一个元素对应的盒变成位图。 这里的元素包括 HTML 元素和伪元素,一个元素可能对应多个盒(比如 inline 元素,可能会分成多行)。每一个盒对应着一张位图。
渲染过程,是不会把子元素绘制到渲染的位图上的,这样,当父子元素的相对位置发生变化时,可以保证渲染的结果能够最大程度被缓存,减少重新渲染。
合成。
合成的过程,就是为一些元素创建一个“合成后的位图”(我们把它称为合成层),把一部分子元素渲染到合成的位图上面。
绘制。
绘制过程,实际上就是按照 z-index 把合成位图依次绘制到屏幕上。
DOM API
DOM API 大致会包含 4 个部分。
- 节点:DOM 树形结构中的节点相关 API。
- 事件:触发和监听事件相关 API。
- Range:操作文字范围相关 API。
- 遍历:遍历 DOM 需要的 API。

节点
元素在DOM树中关系api
- parentNode
- childNodes
- firstChild
- lastChild
- nextSibling
- previousSibling
操作 DOM 树的API
- appendChild
- insertBefore
- removeChild
- replaceChild
一些高级 API
- compareDocumentPosition 是一个用于比较两个节点中关系的函数。
- contains 检查一个节点是否包含另一个节点的函数。这个方法一般用于做一些点击判断,然后关闭一些dom的功能。
- isEqualNode 检查两个节点是否完全相同。
- isSameNode 检查两个节点是否是同一个节点,实际上在 JavaScript 中可以用“===”。
- cloneNode 复制一个节点,如果传入参数 true,则会连同子元素做深拷贝。
创建DOM的api
- createElement
- createTextNode
- createCDATASection
- createComment
- createProcessingInstruction
- createDocumentFragment
- createDocumentType
操作属性的api
- getAttribute
- setAttribute
- removeAttribute
- hasAttribute 如果你喜欢 property 一样的访问 attribute,还可以使用 attributes 对象,比如document.body.attributes.class =“a”等效于document.body.setAttribute(“class”,“a”)。
查找元素api
- querySelector
- querySelectorAll
- getElementById
- getElementsByName
- getElementsByTagName
- getElementsByClassName
我们需要注意,getElementById、getElementsByName、getElementsByTagName、getElementsByClassName,这几个 API 的性能高于 querySelector。
新增加的节点会被添加到非querySelector, querySelectorAll查询出来的对象上的。
遍历
- createNodeIterator
- createTreeWalker
Range
Range API 表示一个 HTML 上的范围,这个范围是以文字为最小单位的,所以 Range 不一定包含完整的节点。
具体请看这里
DOM中的位置
全局尺寸信息

我们获取宽高的对象应该是“盒”,于是 CSSOM View 为 Element 类添加了两个方法:
- getClientRects()。返回一个列表,里面包含元素对应的每一个盒所占据的客户端矩形区域,这里每一个矩形区域可以用 x, y, width, height 来获取它的位置和尺寸。
- getBoundingClientRect()。它返回元素对应的所有盒的包裹的矩形区域,需要注意,这个 API 获取的区域会包括当 overflow 为visible 时的子元素区域。
这两个 API 获取的矩形区域都是相对于视口的坐标,这意味着,这些区域都是受滚动影响的。
事件
事件捕获的由来?
我们操作元素时,都是通过输入设备来做到的,点击事件来自触摸屏或者鼠标,鼠标点击并没有位置信息,但是一般操作系统会根据位移的累积计算出来,跟触摸屏一样,提供一个坐标给浏览器。把这个坐标转换为具体的元素上事件的过程,就是捕获过程了。
建议这样使用冒泡和捕获机制:默认使用冒泡模式,当开发组件时,遇到需要父元素控制子元素的行为,可以使用捕获机制。
事件处理函数不一定是函数,也可以是个 JavaScript 具有 handleEvent 方法的对象。
var o = {
handleEvent: event => console.log(event)
}
document.body.addEventListener("keydown", o, false);
自定义事件。DOM API 中的事件并不能用于普通对象,所以很遗憾,我们只能在 DOM 元素上使用自定义事件。
var evt = new Event("look", {
"bubbles":true,
"cancelable":false
});
document.dispatchEvent(evt); // 调用自定义事件
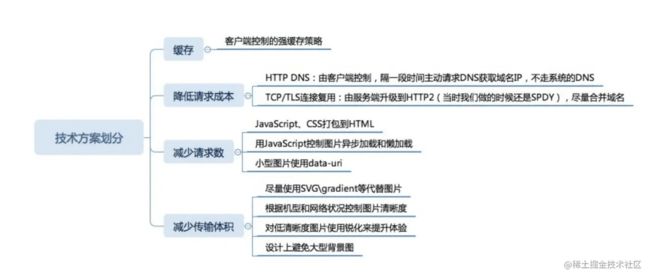
性能优化
以上就是js的一些潜在规则示例分析的详细内容,更多关于js潜在规则的资料请关注脚本之家其它相关文章!