K8s in Action 阅读笔记——【14】Securing cluster nodes and the network
K8s in Action 阅读笔记——【14】Securing cluster nodes and the network
迄今为止,创建了 Pod 而不考虑它们允许消耗多少 CPU 和内存。但是,正如将在本章中看到的那样,设置 Pod 预期消耗和允许消耗的最大数量是任何 Pod 定义的重要部分。设置这两组参数可以确保 Pod 只占用 Kubernetes 集群提供的资源中的份额,并且还影响 Pod 在集群中的调度方式。
14.1 Requesting resources for a pod’s containers
在创建 Pod 时,你可以指定每个容器需要的 CPU 和内存量(称为requests),以及其允许消耗的硬限制(称为limits)。这些参数是为每个容器单独指定的,而不是为整个 Pod 指定的。Pod 的资源请求和限制是其所有容器请求和限制的总和。
14.1.1 Creating pods with resource requests
让我们来看一个 Pod 清单文件的示例,其中单个容器的 CPU 和内存requests已经指定,如下所示:
# requests-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: requests-pod
spec:
containers:
- image: busybox
command: ["dd", "if=/dev/zero", "of=/dev/null"]
name: main
resources:
requests:
cpu: 200m # 容器请求 200 毫核心(即一个单独的 CPU 核心时间的五分之一)。
memory: 10Mi
在 Pod 清单中,你的单个容器需要五分之一的 CPU 核心(200 毫核心)才能正常运行。在单个 CPU 核心上可以运行五个这样的 Pod/容器。
在 Pod 规范中,你还为容器请求了 10 mebibyte 的内存。当 Pod 启动时,你可以通过在容器内运行 top 命令快速查看该进程的 CPU 消耗情况,如下所示:
$ kubectl exec -it requests-pod -- top
Mem: 7830880K used, 321904K free, 5344K shrd, 271216K buff, 5278144K cached
CPU: 17.3% usr 15.6% sys 0.0% nic 64.3% idle 0.0% io 0.0% irq 2.6% sirq
Load average: 5.02 2.29 1.26 3/1075 12
PID PPID USER STAT VSZ %VSZ CPU %CPU COMMAND
1 0 root R 1312 0.0 1 24.6 dd if /dev/zero of /dev/null
7 0 root R 1320 0.0 0 0.0 top
让我们看看在 Pod 中指定资源请求如何影响 Pod 的调度。
14.1.2 Understanding how resource requests affect scheduling
通过指定资源请求,你指定了 Pod 需要的最小资源量。这是调度器在将 Pod 调度到节点时使用的信息。每个节点都有一定数量的 CPU 和内存可以分配给 Pod。在调度 Pod 时,调度器只考虑具有足够未分配资源以满足 Pod 资源需求的节点。如果未分配的 CPU 或内存量少于 Pod 请求的量,Kubernetes 将不会将 Pod 调度到该节点,因为该节点无法提供 Pod 所需的最小数量。
理解调度器如何确定 Pod 是否适合在节点上
如图 14.1。三个 Pod 部署在节点上。它们一起请求了节点 CPU 的 80% 和内存的 60%。图中右下角显示的 Pod D 无法被调度到节点上,因为它请求了 25% 的 CPU,这比未分配的 20% 的 CPU 要多。实际上这三个 Pod 只使用了 70% 的 CPU,但是并不影响。

理解调度器在选择 Pod 的最佳节点时如何使用 Pod 的requests
你可能还记得第 11 章中提到的,调度器首先对节点列表进行筛选,以排除不能容纳 Pod 的节点,然后根据配置的优先级函数对剩余的节点进行优先排序。其中包括根据请求的资源量对节点进行排名的两个优先级函数:LeastRequestedPriority 和 MostRequestedPriority。前者更喜欢请求更少资源的节点(具有更多未分配资源量),而后者正好相反——它更喜欢拥有最多请求资源(较少未分配 CPU 和内存)的节点。它们都考虑所请求的资源量,而不是实际使用的资源量。
调度器配置为仅使用其中之一的功能。你可能会想知道为什么有人要使用 MostRequestedPriority 功能。毕竟,如果你有一组节点,通常希望在它们之间均匀分配 CPU 负载。但是,当在云基础架构上运行时,通过保持 Pod 紧密排列,某些节点将空置可供移除,这会节省开销。
检查节点容量
让我们看看调度器的实际操作。你将部署另一个 Pod,并请求比之前多四倍的资源量。但是在这样做之前,让我们来看看节点的容量。因为调度器需要知道每个节点有多少 CPU 和内存,Kubelet 会将此数据报告给 API Server,并通过 Node 资源使其可用。你可以使用 kubectl describe 命令查看它,如下所示:
$ kubectl describe nodes
......
Addresses:
InternalIP: 33.33.33.110
Hostname: yjq-k8s1
Capacity:
cpu: 4
ephemeral-storage: 41019616Ki
hugepages-2Mi: 0
memory: 8152788Ki
pods: 110
Allocatable:
cpu: 4
ephemeral-storage: 37803678044
hugepages-2Mi: 0
memory: 8050388Ki
pods: 110
......
输出显示了与节点上可用资源相关的两组数量:节点的容量和可分配资源。容量表示节点的总资源,其中可能并非所有资源都可供 Pod 使用。某些资源可能会为 Kubernetes 和/或系统组件保留。调度器的决策仅基于可分配的资源量。
当某一个Pod请求的资源量大于任意节点的可分配资源量时,该Pod无法得到调度。
14.1.3 Understanding how CPU requests affect CPU time sharing
假设运行着两个Pod(系统Pod可以先忽略不计,因为它们大部分时间处于闲置状态)。其中一个请求了200毫卡的CPU,而另一个请求了它的五倍。在本章开始时,我们提到Kubernetes区分资源requests和limits。由于你还没有定义任何limits,因此这两个Pod在CPU使用量方面没有任何限制。如果每个Pod内的进程都使用了最大的CPU时间,那么每个Pod的CPU时间会是多少呢?
CPU请求不仅影响调度,还决定了未使用的CPU时间如何分配给Pod之间。由于你的第一个Pod请求了200毫卡的CPU,而另一个请求了1,000毫卡,因此未使用的CPU时间按1:5的比例分配给这两个Pod(见图14.2)。如果两个Pod都使用了其最大CPU时间,那么第一个Pod将获得1/6或16.7%的CPU时间,而另一个Pod将获得剩余的5/6或83.3%。

可以通过设置limits来控制Pod的最大CPU使用量。
14.1.4 Defining and requesting custom resources
Kubernetes 还允许你将自定义资源添加到节点并在 Pod 的资源请求中请求它们。最初被称为 Opaque Integer Resources,但在 Kubernetes 版本1.8中改为 Extended Resources。
首先,你需要向 Kubernetes 添加你的自定义资源,将其添加到 Node 对象的 capacity 字段中,这可以通过执行 PATCH HTTP 请求来完成。资源名称可以是任何内容,例如 example.org/myresource,只要它不以 kubernetes.io 域开头即可。数量必须是整数(例如,你不能将它设置为100毫,因为0.1不是整数;但你可以将其设置为1000m或2000m或1或2)。值将自动从容量复制到 allocatable 字段。
然后,在创建Pod时,你在容器规范的 resources.requests 字段中指定相同的资源名称和请求数量,或者在使用 kubectl run 时使用 --requests。调度器将确保该 Pod 只部署到具有所需自定义资源数量的节点上。每个部署的 Pod 显然会降低该资源可分配的数量。
自定义资源的一个示例可能是节点上可用 GPU 卡的数量。需要使用 GPU 的 Pod 在它们的请求数量中指定 GPU 卡的数量。
14.2 Limiting resources available to a container
14.2.1 Setting a hard limit for the amount of resources a container can use
CPU 是可压缩的资源,这意味着可以通过限制容器使用的 CPU 数量来限制它在不会对容器中运行的进程产生不良影响的情况下进行调整。内存显然是不同的——它是不可压缩的。一旦进程得到一块内存,该内存即无法从进程中取走,直到进程自己释放它。这就是为什么你需要限制容器可以获得的最大内存量。
如果不限制内存,运行在工作节点上的一个容器(或Pod)可能会占用全部可用内存,并影响节点上的所有其他Pod以及计划调度到该节点的任何新Pod(请记住,新Pod是基于内存请求而非实际使用情况来调度到该节点的)。单个故障或恶意Pod可以使整个节点无法使用。
为了防止这种情况发生,Kubernetes 允许你为每个容器指定资源limits。下面的示例显示了带有资源限制的 Pod:
# limited-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: limited-pod
spec:
containers:
- image: busybox
command: ["dd", "if=/dev/zero", "of=/dev/null"]
name: main
resources:
limits:
cpu: 1
memory: 20Mi
这个 Pod 的容器已经为 CPU 和内存都配置了资源限制。容器内运行的进程,无法消耗超过1个CPU核心和20mebibytes的内存。
因为没有指定资源
requests,它们将被设置为资源limits的相同值。
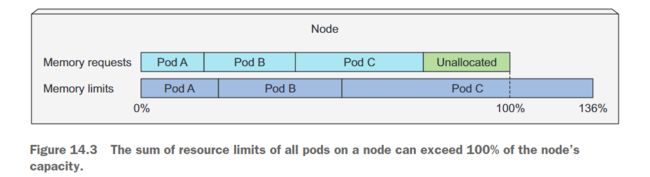
与资源请求不同,资源限制并不受节点可分配资源量的限制。在节点上所有 Pod 的所有限制的总和允许超过节点容量的100%(图14.3)。换句话说,资源限制可以超额使用。这有一个重要的后果——当节点资源使用完100%时,某些容器将需要被杀死。
14.2.2 Exceeding the limit
当运行在容器中的进程试图使用比其允许的更多的资源时会发生什么情况?
你已经学过了CPU是一种可压缩的资源,进程在不等待I/O操作时希望消耗所有CPU时间也是很自然的。但是,正如你所学到的,进程的CPU使用率受限,因此当为容器设置CPU限制时,进程不会获得比配置的限制更多的CPU时间。
对于内存来说就不同了。当进程尝试分配超出其限制的内存时,进程会被杀死(它被称为OOMKilled,其中OOM代表Out Of Memory)。如果Pod的重启策略设置为Always或OnFailure,则该进程会立即重启,因此你甚至可能没有注意到它被杀死了。但是,如果它继续超过内存限制并被杀死,Kubernetes将开始在重启之间增加延迟。在这种情况下,你会看到CrashLoopBackOff状态:
CrashLoopBackOff状态并不意味着Kubelet已经放弃。它意味着在每次崩溃后,Kubelet都会增加重启容器之前的时间间隔。在第一次崩溃后,它会立即重启容器,然后,如果再次崩溃,则在再次重启之前等待10秒钟。在随后的崩溃中,此延迟会呈指数增长,分别为20、40、80和160秒,最后限制为300秒。一旦间隔达到300秒的限制,Kubelet会每隔五分钟无限期地重启容器,直到Pod停止崩溃或被删除为止。
要检查容器崩溃的原因,你可以检查Pod的日志和/或使用kubectl describe pod命令,如下列表中所示。

OOMKilled状态告诉你,容器已经因为内存不足而被杀死。如果不想让容器被杀死,重要的是不要将内存限制设置得太低。但是,即使容器没有超过其限制,它们也可能会被OOMKilled。。
14.2.3 Understanding how apps in containers see limits
创建之前的Pod:
$ kubectl create -f limit-pod.yaml
pod/limited-pod created
使用top命令查看进程的资源使用情况:
$ kubectl exec -it limited-pod top
Mem: 8005788K used, 147000K free, 5468K shrd, 381848K buff, 5631300K cached
CPU: 15.6% usr 17.2% sys 0.0% nic 65.7% idle 0.0% io 0.0% irq 1.3% sirq
Load average: 1.47 0.82 0.56 7/1100 19
PID PPID USER STAT VSZ %VSZ CPU %CPU COMMAND
1 0 root R 1312 0.0 1 25.0 dd if /dev/zero of /dev/null
14 0 root R 1320 0.0 0 0.0 top
Pod的CPU限制设置为1核心,内存限制设置为20 MiB。仔细查看top命令的输出,与为容器设置的20 MiB完全不一样。同样,将CPU限制设置为一个核心,而主进程似乎只使用了可用CPU时间的25%,即使使用的dd命令通常会使用其所有可用的CPU时间。
容器看到的是节点的内存
top命令显示了容器运行的整个节点的内存量。即使为容器设置了内存可用量的限制,容器也不会意识到这种限制。
容器能看到节点所有的CPU核心数
与内存一样,容器也会看到节点的所有CPU,无论为容器配置了多少CPU限制。将CPU限制设置为一个核心并不能只向容器公开一个CPU核心。所有CPU限制所做的只是限制容器可以使用的CPU时间。
在具有64个CPU的CPU上运行的有一个核心CPU限制的容器将获得总CPU时间的1/64。即使将其限制设置为一个核心,容器的进程也不会只在一个核心上运行。在不同的时间点,它的代码可能会在不同的核心上执行。
某些应用程序查找系统上的CPU数量以决定应运行多少个工作线程。同样,这样的应用程序在开发笔记本电脑上运行得很好,但当部署到拥有大量核心的节点上时,它将启动过多的线程,所有线程都在争夺(可能)有限的CPU时间。此外,每个线程都需要额外的内存,导致应用程序的内存使用量飙升。
可以直接利用cgroups系统通过读取以下文件来获取配置的CPU限制:
- /sys/fs/cgroup/cpu/cpu.cfs_quota_us
- /sys/fs/cgroup/cpu/cpu.cfs_period_us
14.3 Understanding pod QoS classes
我们已经提到过资源限制可能会被超额分配,节点可能无法为它的所有Pod提供它们在资源限制中指定的数量的资源。
想象一下,有两个Pod,其中Pod A使用了节点内存的90%,而Pod B突然需要比其到目前为止使用的内存更多的内存,节点无法提供所需的内存。哪个容器应该被杀掉?应该是Pod B吗,因为无法满足其对内存的请求,还是应该杀掉Pod A以释放内存,以便提供给Pod B?
显然,这取决于具体情况。Kubernetes不能独立做出正确的决定,需要一种指定这种情况下优先级Pod的方式。Kubernetes通过将Pod分类为三个服务质量(QoS)类别来实现此目的:
- BestEffort(最低优先级)
- Burstable
- Guaranteed(最高优先级)
14.3.1 Defining the QoS class for a pod
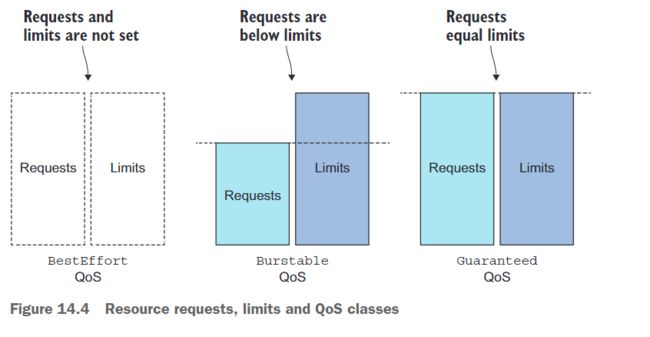
QoS类别是从Pod容器的资源请求和限制的组合中派生出来的。以下是如何进行分类的方法:
分配BestEffort类的Pod
最低优先级的QoS类是BestEffort类。它分配给那些根本没有设置任何请求或限制(在任何容器中)的Pod。这是先前章节中创建的所有Pod所分配的QoS类。在这些Pod中运行的容器完全没有任何资源保证。在最坏的情况下,它们可能根本没有获得CPU时间,在需要为其他Pod释放内存时,它们将会是被首先停止运行的。但是,因为BestEffort Pod没有设置内存限制,如果有足够的内存可用,其容器可以使用任意量的内存。
分配Guaranteed类的Pod:
Guaranteed QoS类适用于容器的请求等于限制的Pod。为了使Pod的类别为Guaranteed,需要满足以下三个条件:
- 必须为CPU和内存设置请求和限制。
- 必须为每个容器设置请求和限制。
- 他们必须相等(限制必须与每个容器中每个资源的请求相匹配)。
由于容器的资源请求(如果没有显式设置)默认等于限制,为所有资源指定限制(对于Pod中的每个容器)足以使该Pod为Guaranteed。这些Pod中的容器获得所请求的资源量,但不能使用额外的资源(因为它们的限制不高于它们的请求)。
将Burstable QoS类分配给Pod
介于BestEffort和Guaranteed之间的是Burstable QoS类别,所有其他Pod都属于这个类别。这包括容器限制不符合请求的单容器Pod以及至少有一个容器指定了资源请求但未设置限制的所有Pod。还包括一个容器的请求与限制相匹配,但另一个容器没有指定请求或限制的Pod。Burstable Pod会获得所请求的资源量,但如果需要,允许使用额外的资源。
请求和限制之间的关系如何定义QoS类别。
综上所述,可以绘制下图:
确定容器的QoS类别
表14.1显示基于单个容器上如何定义资源请求和限制的QoS类别。对于单容器Pod,QoS类别也适用于Pod。

- 如果只设置了请求但未设置限制,请参考请求小于限制的表行。如果只设置了限制,则请求默认为限制,因此请参考请求等于限制的行。
确定有多个容器的Pod的QoS类别
对于多容器Pod,如果所有容器具有相同的QoS类别,则Pod的QoS类别也相同。如果至少有一个容器具有不同的类别,则无论容器的类别是什么,Pod的QoS类别都是Burstable。表14.2显示了一个双容器Pod的QoS类别与其两个容器的类别之间的关系。可以轻松将此扩展到具有多个容器的Pod。

14.3.2 Understanding which process gets killed when memory is low
当系统超额时,QoS类别决定哪个容器首先被杀掉,以便释放的资源可以提供给更高优先级的Pod。队列中首先需要被杀掉的是BestEffort类别的Pod,其次是Burstable类别的Pod,最后是Guaranteed类别的Pod。
了解QoS类别的排列方式:
让我们看一下图14.5中显示的示例。假设有两个单容器Pod,其中第一个具有BestEffort QoS类别,第二个的类别为Burstable。当节点的整个内存已经达到最大值,而节点上的一个进程尝试分配更多的内存时,系统将需要杀死一个进程(甚至可能是尝试分配额外内存的进程)来满足分配请求。在这种情况下,始终首先杀死BestEffort Pod中正在运行的进程,而不是Burstable Pod中正在运行的进程。

显然,在任何Guaranteed Pod的进程被杀死之前,BestEffort Pod的进程也会被杀死。同样,在Guaranteed Pod的进程被杀死之前,Burstable Pod的进程也会被杀死。但是,如果只有两个Burstable Pod,会发生什么情况?显然,选择过程需要优先考虑其中一个。
如何处理具有相同QoS类别的容器
每个正在运行的进程都有一个OutOfMemory(OOM)分数。系统通过比较所有正在运行的进程的OOM分数来选择要杀死的进程。当需要释放内存时,具有最高分数的进程将被杀死。
OOM分数从两个方面计算出来:进程所使用的可用内存的百分比和固定的OOM分数调整,该分数基于Pod的QoS类别和容器的请求内存。当存在两个单容器Pod,两者均属于Burstable类别时,系统将杀死使用请求内存的百分比高于另一个的Pod。这就是为什么在图14.5中,使用其请求内存的90%的Pod B会在比使用70%的Pod C更早被杀死,即使Pod C使用的内存比Pod B更多。
14.4 Setting default requests and limits for pods per namespace
14.4.1 Introducing the LimitRange resource
LimitRange资源允许为每个命名空间指定每种资源上可以设置的最小和最大限制,以及不显式指定容器的默认请求资源,如图14.6所示。

LimitRange资源是LimitRanger Admission Control插件使用的。当Pod配置发布到API服务器时,LimitRanger插件会验证Pod spec。如果验证失败,则配置将立即被拒绝。因此,LimitRange对象的一个很好的用例是防止用户创建大于集群中任何节点的Pod。如果没有这样的LimitRange,则API服务器将接受Pod,但永远不会调度它。
LimitRange资源中指定的限制适用于与同一命名空间中的LimitRange对象创建的每个Pod /容器或其他对象。它们不限制命名空间中所有Pod的总资源量。
14.4.2 Creating a LimitRange object
YAML文件创建LimitRange的示例如下:
# limits.yaml
apiVersion: v1
kind: LimitRange
metadata:
name: example
spec:
limits:
# Pod级别的限制
- type: Pod
min:
cpu: 50m
memory: 5Mi
max:
cpu: 1
memory: 1Gi
# 容器级别的限制
- type: Container
# 默认请求
defaultRequest:
cpu: 100m
memory: 10Mi
# 默认限制
default:
cpu: 200m
memory: 100Mi
# 最大/最小的请求/限制
min:
cpu: 50m
memory: 5Mi
max:
cpu: 1
memory: 1Gi
# 每种资源的限制和请求之间的最大比率
maxLimitRequestRatio:
cpu: 4
memory: 10
# 还可以设置PVC可以请求的最小和最大存储量。
- type: PersistentVolumeClaim
min:
storage: 1Gi
max:
storage: 10Gi
在容器级别下面,不仅可以设置最小和最大限制,还可以设置默认资源请求(defaultRequest)和默认限制(default),它们将应用于未显式指定它们的每个容器。
除了最小值、最大值和默认值之外,甚至还可以设置限制与请求的最大比例。前一个示例将CPU maxLimitRequestRatio设置为4,这意味着容器的CPU限制将不允许超过其CPU请求的四倍。如果容器请求了200毫核,如果其CPU限制设置为801毫核或更高,则其将不被接受。对于内存,最大比率设置为10。
在第6章中,我们介绍了PersistentVolumeClaims(PVC),允许像Pod的容器一样声明一定量的持久存储。就像限制容器可以请求的最小和最大CPU一样,还应该限制单个PVC可以请求的存储量。 LimitRange对象也允许这样做,就像示例底部所示的那样。
示例显示一个包含所有限制的单个LimitRange对象,但是如果希望按类型将它们分组,也可以将它们拆分为多个对象(例如,一个用于Pod限制,另一个用于容器限制,而另一个用于PVC)。在验证Pod或PVC时,来自多个LimitRange对象的限制将被合并。
因为LimitRange对象中配置的验证(和默认值)是API服务器在收到新的Pod或PVC清单时执行的,因此,如果之后修改了限制,则现有的Pod和PVC将不会被重新验证,新的限制只适用于之后创建的Pod和PVC。
14.4.3 Enforcing the limits
有了你设置的限制,现在可以尝试创建一个请求超过LimitRange允许的CPU的Pod:
# limits-pod-too-big.yaml
apiVersion: v1
kind: Pod
metadata:
name: too-big
spec:
containers:
- image: busybox
args: ["sleep", "9999999"]
name: main
resources:
requests:
cpu: 2
该Pod的单个容器请求了两个CPU,这比之前在LimitRange中设置的最大值还要多。创建该Pod将产生以下结果:
$ kubectl create -f limits-pod-too-big.yaml
The Pod "too-big" is invalid: spec.containers[0].resources.requests: Invalid value: "2": must be less than or equal to cpu limit
可以发现,请求被拒绝了,因为cpu的request大于了设定的1。
14.4.4 Applying default resource requests and limits
现在让我们看看如何在未指定默认资源请求和限制的容器上设置默认值。再次部署第3章中的kubia-manual pod:
# kubia-manual.yaml
apiVersion: v1
kind: Pod
metadata:
name: kubia-manual
spec:
containers:
- image: yijunquan/kubia
name: kubia
ports:
- containerPort: 8080
protocol: TCP
$ kubectl create -f kubia-manual.yaml
pod/kubia-manual created
在设置LimitRange对象之前,所有的Pod都没有设置任何资源请求或限制,但是现在在创建Pod时会自动应用默认值。可以通过描述kubia-manual Pod来确认这一点:
$ kubectl describe po kubia-manual
......
Limits:
cpu: 200m
memory: 100Mi
Requests:
cpu: 100m
memory: 10Mi
Environment: <none>
容器的请求和限制与你在LimitRange对象中指定的请求和限制匹配。如果你在另一个命名空间中使用了不同的LimitRange规范,则在该命名空间中创建的Pod显然会有不同的请求和限制。这使得管理员可以针对每个命名空间配置Pod的默认、最小和最大资源。
但请记住,LimitRange中配置的限制仅适用于每个个体Pod /容器。仍然可以创建许多Pod并吞掉群集中所有可用的资源。LimitRanges没有提供任何保护。ResourceQuota对象提供了这种保护。你将在下一节中学习它们。
14.5 Limiting the total resources available in a namespace
14.5.1 Introducing the ResourceQuota object
ResourceQuota Admission Control插件检查正在创建的Pod是否会导致超出配置的ResourceQuota。如果是这种情况,则拒绝创建Pod。由于资源配额在Pod创建时执行,因此ResourceQuota对象仅影响创建ResourceQuota对象之后创建的Pod,对现有Pod没有影响。
ResourceQuota限制命名空间中Pod可消耗的计算资源量和PersistentVolumeClaims的存储量。它还可以限制允许用户在命名空间中创建的Pod数量、claims数量和其他API对象的数量。因为到目前为止主要处理的是CPU和内存,所以让我们从查看如何为它们指定配额(quotas)开始。
为CPU和内存创建ResourceQuota
命名空间中所有Pod允许消耗的总CPU和内存由创建ResourceQuota对象来定义,如下面的示例所示:
# quota-cpu-memory.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: cpu-and-mem
spec:
hard:
requests.cpu: 400m
requests.memory: 200Mi
limits.cpu: 600m
limits.memory: 500Mi
此ResourceQuota将命名空间中Pod可以请求的最大CPU量设置为400毫核。命名空间中CPU限制的最大总量设置为600毫核。对于内存,最大总请求量设置为200 MiB,而限制设置为500 MiB。
ResourceQuota对象适用于创建它的命名空间,就像LimitRange一样,但它适用于所有Pod的资源请求和限制的总和,而不是每个单独的Pod或容器,如图14.7所示。

查看Quota和Quota使用情况
$ kubectl create -f quota-cpu-memory.yaml
resourcequota/cpu-and-mem created
$ kubectl describe quota
Name: cpu-and-mem
Namespace: default
Resource Used Hard
-------- ---- ----
limits.cpu 1200m 600m
limits.memory 120Mi 500Mi
requests.cpu 1300m 400m
requests.memory 40Mi 200Mi
创建ResourceQuota时需要注意一点,你还需要同时创建一个LimitRange对象。在这种情况下,根据之前的设置,你已经有了一个LimitRange,但如果没有,则无法运行kubia-manual pod,因为它没有指定任何资源请求或限制。
14.5.2 Specifying a quota for persistent storage
ResourceQuota对象还可以限制在命名空间中可以声明的持久性存储的数量,如下所示:
# quota-storage.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: storage
spec:
hard:
requests.storage: 500Gi
ssd.storageclass.storage.k8s.io/requests.storage: 300Gi
standard.storageclass.storage.k8s.io/requests.storage: 1Ti
在此示例中,所有命名空间中的PersistentVolumeClaims可以请求的存储量被限制为500 GiB(由ResourceQuota对象中的requests.storage条目指定)。将ssd存储限制为300 GiB(由ssd StorageClass指定)。较低性能的HDD存储(StorageClass standard)限制为1 TiB。
14.5.3 Limiting the number of objects that can be created
ResourceQuota也可以配置,以限制在单个命名空间中的Pods、ReplicationControllers、Services和其他对象的数量。
以下示例显示了限制对象数量的ResourceQuota对象的示例:
# quota-object-count.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: objects
spec:
hard:
pods: 10
replicationcontrollers: 5
secrets: 10
configmaps: 10
persistentvolumeclaims: 5
services: 5
services.loadbalancers: 1
services.nodeports: 2
ssd.storageclass.storage.k8s.io/persistentvolumeclaims: 2
此示例中的ResourceQuota允许用户在命名空间中创建最多10个Pods,无论是手动创建还是由ReplicationController、ReplicaSet、DaemonSet、Job等创建的。它还限制了ReplicationControllers的数量为5个。最多可以创建5个Services,其中只能有一个LoadBalancer类型的Service,而且只能有两个NodePort类型的Services。类似于可以针对每个StorageClass指定的最大请求存储量,还可以针对每个StorageClass限制PersistentVolumeClaims的数量。
可以为以下对象设置对象计数配额:
- configmaps
- persistentvolumeclaims
- pods
- replicationcontrollers
- resourcequotas
- services
- services.loadbalancers
- services.nodeports
- secrets
14.5.4 Specifying quotas for specific pod states and/or QoS classes
目前为止创建的配额适用于所有Pod,无论其当前状态和QoS类别如何。但是,配额也可以被限制为一组配额范围。目前有四个范围可用,分别是BestEffort、NotBestEffort、Terminating和NotTerminating。
BestEffort和NotBestEffort范围决定配额是否适用于具有BestEffort QoS类别或其他两个类别(即Burstable和Guaranteed)中的一个的Pod。
另外两个范围(Terminating和NotTerminating)与其名称所暗示的不同,不适用于正在关闭中的(或未关闭的)Pod。可以指定每个Pod被允许运行多长时间后终止并标记为失败。这可以通过在Pod规范中设置activeDeadlineSeconds字段来实现。此属性定义了Pod相对于启动时间在节点上允许的运行秒数,超出此时间后,该Pod会被标记为失败并终止运行。Terminating配额范围适用于已设置了activeDeadlineSeconds的Pod,而NotTerminating适用于没有设置的Pod。
创建ResourceQuota时,可以指定它适用的范围。Pod必须符合配额适用的所有指定范围。此外,配额可以限制的内容取决于配额的范围。BestEffort范围仅能够限制Pod的数量,而其他三个范围则可以限制Pod的数量、CPU/内存请求以及CPU/内存限制。
例如,如果想将配额仅应用于BestEffort和NotTerminating的Pod,则可以创建以下ResourceQuota对象:
# quota-scoped.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: besteffort-notterminating-pods
spec:
scopes:
- BestEffort
- NotTerminating
hard:
pods: 4
该配额确保最多存在具有BestEffort QoS类别且没有activeDeadlineSeconds的四个Pod。如果该配额针对的是NotBestEffort的Pod,则还可以指定requests.cpu、requests.memory、limits.cpu和limits.memory。