Apache Hive函数高阶应用、性能调优
Hive的函数高阶应用
explode函数
explode属于UDTF函数,表生成函数,输入一行数据输出多行数据。
功能:
explode() takes in an array (or a map) as an input and outputs the elements of the array (map) as separate rows. --explode接收map array类型的参数 把map或者array的元素输出,一行一个元素。 explode(array(11,22,33)) 11 22 33 select explode(`array`(11,22,33,44,55)); select explode(`map`("id",10086,"name","allen","age",18));
lateral view 侧视图
侧视图的原理是将UDTF的结果构建成一个类似于视图的表,然后将原表中的每一行和UDTF函数输出的每一行进行连接,生成一张新的虚拟表
背景
UDTF函数生成的结果可以当成一张虚拟的表,但是无法和原始表进行组合查询
select name,explode(location) from test_message; --这个sql就是错误的 相当于执行组合查询从理论层面推导,对两份数据进行join就可以了
但是,hive专门推出了lateral view侧视图的语,满足上述需要。
功能:把UDTF函数生成的结果和原始表进行关联,便于用户在select时间组合查询、 lateral view是UDTf的好基友好搭档,实际中经常配合使用。
语法:
--lateral view侧视图基本语法如下 select …… from tabelA lateral view UDTF(xxx) 别名 as col1,col2,col3……; --针对上述NBA冠军球队年份排名案例,使用explode函数+lateral view侧视图,可以完美解决 select a.team_name ,b.year from the_nba_championship a lateral view explode(champion_year) b as year; --根据年份倒序排序 select a.team_name ,b.year from the_nba_championship a lateral view explode(champion_year) b as year order by b.year desc; --统计每个球队获取总冠军的次数 并且根据倒序排序 select a.team_name ,count(*) as nums from the_nba_championship a lateral view explode(champion_year) b as year group by a.team_name order by nums desc;
行列转换
多行转单列
collect_set --把多行数据收集为一行 返回set集合 去重无序
collect_list --把多行数据收集为一行 返回list集合 不去重有序字符串拼接函数
concat --直接拼接字符串
concat_ws --指定分隔符拼接
select concat("it","cast","And","heima");
select concat("it","cast","And",null);
select concat_ws("-","itcast","And","heima");
select concat_ws("-","itcast","And",null);单列转多行
技术原理: explode+lateral view
--原表 +-------+-------+--------+--+ | col1 | col2 | col3 | +-------+-------+--------+--+ | a | b | 1,2,3 | | c | d | 4,5,6 | +-------+-------+--------+--+ --目标表 +----------------+----------------+----------------+--+ | row2col2.col1 | row2col2.col2 | row2col2.col3 | +----------------+----------------+----------------+--+ | a | b | 1 | | a | b | 2 | | a | b | 3 | | c | d | 4 | | c | d | 5 | | c | d | 6 | +----------------+----------------+----------------+--+ --创建表 create table col2row2( col1 string, col2 string, col3 string )row format delimited fields terminated by '\t'; --加载数据 load data local inpath '/root/hivedata/c2r2.txt' into table col2row2; select * from col2row2; select explode(split(col3,',')) from col2row2; --SQL最终实现 select col1, col2, lv.col3 as col3 from col2row2 lateral view explode(split(col3, ',')) lv as col3;
json格式数据处理
在hive中,没有json类的存在,一般使用string类型来修饰,叫做json字符串,简称json串。
在hive中,处理json数据的两种方式
hive内置了两个用于解析json的函数
json_tuple --是UDTF 表生成函数 输入一行,输出多行 一次提取读个值 可以单独使用 也可以配合lateral view侧视图使用 get_json_object --是UDF普通函数,输入一行 输出一行 一次只能提取一个值 多次提取多次使用使用==JsonSerDe 类解析==,在加载json数据到表中的时候完成解析动作
hive 窗口函数
快速理解窗口函数功能
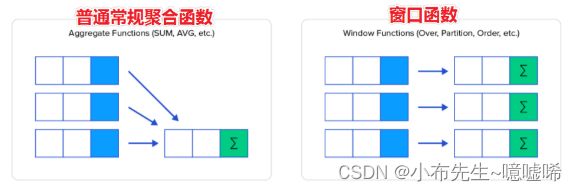
window function 窗口函数、开窗函数、olap分析函数。
窗口:可以理解为操作数据的范围,窗口有大有小,本窗口中操作的数据有多有少。
可以简单地解释为类似于聚合函数的计算函数,但是通过GROUP BY子句组合的常规聚合会隐藏正在聚合的各个行,最终输出一行;而窗口函数聚合后还可以访问当中的各个行,并且可以将这些行中的某些属性添加到结果集中。
窗口函数语法
具有OVER语句的函数叫做窗口函数。
Function(arg1,..., argn) OVER ([PARTITION BY <...>] [ORDER BY <....>] []) --其中Function(arg1,..., argn) 可以是下面分类中的任意一个 --聚合函数:比如sum max avg等 --排序函数:比如rank row_number等 --分析函数:比如lead lag first_value等 --OVER [PARTITION BY <...>] 类似于group by 用于指定分组 每个分组你可以把它叫做窗口 --如果没有PARTITION BY 那么整张表的所有行就是一组 --[ORDER BY <....>] 用于指定每个分组内的数据排序规则 支持ASC、DESC --[ ] 用于指定每个窗口中 操作的数据范围 默认是窗口中所有行
窗口聚合函数
语法
sum|max|min|avg OVER ([PARTITION BY <...>] [ORDER BY <....>] []) 重点:有PARTITION BY 没有PARTITION BY的区别;有ORDER BY没有ORDER BY的区别。
有没有partition by 影响的是全局聚合 还是分组之后 每个组内聚合。
有没有order by的区别:
没有order by,聚合的时候是组内所有的数据聚合再一起 全局聚合
如果有order by,聚合的时候是累加聚合,默认是第一行聚合到当前行。
window_expression
直译叫做window表达式 ,通俗叫法称之为window子句。
功能:控制窗口操作的范围。
语法
rows between - preceding:往前 - following:往后 - current row:当前行 - unbounded:起点 - unbounded preceding 表示从前面的起点 第一行 - unbounded following:表示到后面的终点 最后一行
窗口排序函数、窗口序列函数
功能:主要对数据分组排序之后,组内顺序标号。
核心函数:row_number、rank、dense_rank
适合场景:分组TopN问题(注意哦 不是全局topN)
ntile函数
功能:将分组排序之后的数据分成指定的若干个部分(若干个桶)
规则:尽量平均分配 ,优先满足最小的桶,彼此最多不相差1个。
Hive的数据压缩
Hive的默认执行引擎是MapReduce,因此通常所说的Hive压缩指的是MapReduce的压缩。
压缩是指通过算法对数据进行重新编排,降低存储空间。无损压缩。
MapReduce可以在两个阶段进行数据压缩
map的输出
减少shuffle的数据量 提高shuffle时网络IO的效率
reduce的输出
减少输出文件的大小 降低磁盘的存储空间
压缩的弊端
浪费时间
消耗CPU、内存
某些优秀的压缩算法需要钱
压缩的算法(推荐使用snappy)
Snappy org.apache.hadoop.io.compress.SnappyCodecHive中压缩的设置:注意 本质还是指的是MapReduce的压缩
--设置Hive的中间压缩 也就是map的输出压缩 1)开启 hive 中间传输数据压缩功能 set hive.exec.compress.intermediate=true; 2)开启 mapreduce 中 map 输出压缩功能 set mapreduce.map.output.compress=true; 3)设置 mapreduce 中 map 输出数据的压缩方式 set mapreduce.map.output.compress.codec = org.apache.hadoop.io.compress.SnappyCodec; --设置Hive的最终输出压缩,也就是Reduce输出压缩 1)开启 hive 最终输出数据压缩功能 set hive.exec.compress.output=true; 2)开启 mapreduce 最终输出数据压缩 set mapreduce.output.fileoutputformat.compress=true; 3)设置 mapreduce 最终数据输出压缩方式 set mapreduce.output.fileoutputformat.compress.codec =org.apache.hadoop.io.compress.SnappyCodec; 4)设置 mapreduce 最终数据输出压缩为块压缩 还可以指定RECORD set mapreduce.output.fileoutputformat.compress.type=BLOCK;--设置完毕之后 只有当HiveSQL底层通过MapReduce程序执行 才会涉及压缩。 --已有普通格式的表 select * from student; --ctas语句 create table student_snappy as select * from student;
Hive的数据存储格式
列式存储、行式存储
数据最终在文件中底层以什么样的形成保存。
Hive中表的数据存储格式,不是只支持text文本格式,还支持其他很多格式。
hive表的文件格式是如何指定的呢? 建表的时候通过STORED AS 语法指定。如果没有指定默认都是textfile。
Hive中主流的几种文件格式。
textfile 文件格式
ORC、Parquet 列式存储格式。
都是列式存储格式,底层是以二进制形式存储。数据存储效率极高,对于查询贼方便。 二进制意味着肉眼无法直接解析,hive可以自解析。在实际开发中,可以根据需求选择不同的文件格式并且搭配不同的压缩算法。可以得到更好的存储效果。
结论建议:在Hive中推荐使用ORC+snappy压缩。

Hive通用调优
Fetch抓取机制
功能:在执行sql的时候,能不走MapReduce程序处理就尽量不走MapReduce程序处理。
尽量直接去操作数据文件。
设置: hive.fetch.task.conversion= more。
--在下述3种情况下 sql不走mr程序 --全局查找 select * from student; --字段查找 select num,name from student; --limit 查找 select num,name from student limit 2;
mapreduce本地模式
功能:如果非要执行MapReduce程序,能够本地执行的,尽量不提交yarn上执行。
默认是关闭的。意味着只要走MapReduce就提交yarn执行。
mapreduce.framework.name = local 本地模式 mapreduce.framework.name = yarn 集群模式Hive提供了一个参数,自动切换MapReduce程序为本地模式,如果不满足条件,就执行yarn模式。
set hive.exec.mode.local.auto = true; --3个条件必须都满足 自动切换本地模式 The total input size of the job is lower than: hive.exec.mode.local.auto.inputbytes.max (128MB by default) --数据量小于128M The total number of map-tasks is less than: hive.exec.mode.local.auto.tasks.max (4 by default) --maptask个数少于4个 The total number of reduce tasks required is 1 or 0. --reducetask个数是0 或者 1切换Hive的执行引擎
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases. 如果针对Hive的调优依然无法满足你的需求 还是效率低, 尝试使用spark计算引擎 或者Tez.
join优化
底层还是MapReduce的join优化。
MapReduce中有两种join方式。指的是join的行为发生什么阶段。
map端join
reduce端join
优化1:Hive自动尝试选择map端join提高join的效率 省去shuffle的过程。
开启 mapjoin 参数设置: (1)设置自动选择 mapjoin set hive.auto.convert.join = true; --默认为 true (2)大表小表的阈值设置: set hive.mapjoin.smalltable.filesize= 25000000;优化2:大表join大表
--背景: 大表join大表本身数据就十分具体,如果join字段存在null空值 如何处理它? --方式1:空key的过滤 此行数据不重要 参与join之前 先把空key的数据过滤掉 SELECT a.* FROM (SELECT * FROM nullidtable WHERE id IS NOT NULL ) a JOIN ori b ON a.id =b.id; --方式2:空Key转换 CASE WHEN a.id IS NULL THEN 'xxx任意字符串' ELSE a.id END CASE WHEN a.id IS NULL THEN concat('hive', rand()) ELSE a.id --避免转换之后数据倾斜 随机分布打散优化3:桶表join提高优化效率。bucket mapjoin
1.1 条件 1) set hive.optimize.bucketmapjoin = true; 2) 一个表的bucket数是另一个表bucket数的整数倍 3) bucket列 == join列 4) 必须是应用在map join的场景中 1.2 注意 1)如果表不是bucket的,只是做普通join。
group by 数据倾斜优化
(1)是否在 Map 端进行聚合,默认为 True set hive.map.aggr = true; (2)在 Map 端进行聚合操作的条目数目 set hive.groupby.mapaggr.checkinterval = 100000; (3)有数据倾斜的时候进行负载均衡(默认是 false) set hive.groupby.skewindata = true; --Q:在hive中数据倾斜开启负载均衡之后 底层执行机制是什么样? --step1:启动一个MapReduce程序 将倾斜的数据随机发送到各个reduce中 进行打散 每个reduce进行聚合都是局部聚合 --step2:再启动第二个MapReduce程序 将上一步局部聚合的结果汇总起来进行最终的聚合
hive中如何调整底层MapReduce中task的个数(并行度)
maptask个数
如果是在MapReduce中 maptask是通过逻辑切片机制决定的。
但是在hive中,影响的因素很多。比如逻辑切片机制,文件是否压缩、压缩之后是否支持切割。
因此在Hive中,调整MapTask的个数,直接去HDFS调整文件的大小和个数,效率较高。
如果小文件多,就进行小文件的合并 合并的大小最好=block size 如果大文件多,就调整blocl sizereducetask个数
如果在MapReduce中,通过代码可以直接指定 job.setNumReduceTasks(N)
在Hive中,reducetask个数受以下几个条件控制的
(1)每个 Reduce 处理的数据量默认是 256MB hive.exec.reducers.bytes.per.reducer=256000000 (2)每个任务最大的 reduce 数,默认为 1009 hive.exec.reducsers.max=1009 (3)mapreduce.job.reduces 该值默认为-1,由 hive 自己根据任务情况进行判断。 --如果用户用户不设置 hive将会根据数据量或者sql需求自己评估reducetask个数。 --用户可以自己通过参数设置reducetask的个数 set mapreduce.job.reduces = N --用户设置的不一定生效,如果用户设置的和sql执行逻辑有冲突,比如order by,在sql编译期间,hive又会将reducetask设置为合理的个数。 Number of reduce tasks determined at compile time: 1