Mac下安装Hadoop
文章目录
- 01 引言
- 02 配置ssh环境
- 02 安装与配置Hadoop
- 03 启动Hadoop并验证
-
- 3.1 启动Hadoop
- 3.2 启动yarn服务
- 04 Hadoop sbin下的命令
01 引言
如果想在Mac下安装Hadoop而且让Hadoop能正常运行,那安装之前需要先安装java,具体可以参考之前写的博客《Mac下安装JDK11(国内镜像)》。
好了,现在开始讲解如何在Mac环境下安装Hadoop。
02 配置ssh环境
在Mac下如果想使用Hadoop,必须要配置ssh环境, 如果不执行这一步,后面启动hadoop时会出现Connection refused连接被拒绝的错误。
首先终端命令框输入:
ssh localhost
如果提示错误:

表示当前用户没有权限,更改设置如下:进入系统偏好设置 --> 共享 --> 勾选远程登录->勾选所有用户,如下图:
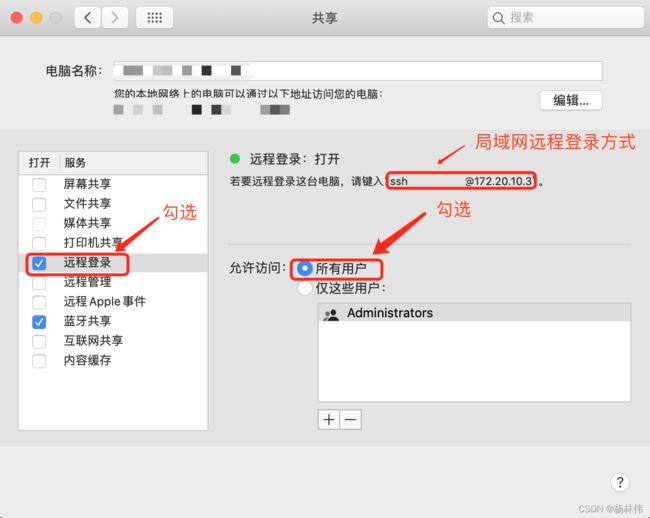
再次输入ssh localhost会提示输入密码,这个时候要重新配置一下ssh免密登录。
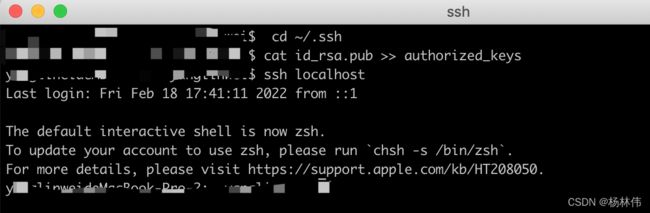
① 进入ssh的目录:
cd ~/.ssh
② 将id_rsa.pub中的内容拷贝到 authorized_keys中:
cat id_rsa.pub >> authorized_keys
操作成功:
02 安装与配置Hadoop
① 使用brew命令安装(这里没有指定版本,安装的是最新版的hadoop):
brew install hadoop
② 查看是否安装成功:
hadoop version
如果显示如下界面,表示安装成功,可以看到版本号为3.3.1:

③ 进入hadoop的目录:
cd /usr/local/Cellar/hadoop/3.3.1/libexec/etc/hadoop
④ 修改core-site.xml:
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://localhost:8020value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>file:/usr/local/Cellar/hadoop/tmpvalue>
property>
configuration>
⑤ 修改hdfs-site.xml,配置namenode和datanode:
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/usr/local/Cellar/hadoop/tmp/dfs/namevalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/usr/local/Cellar/hadoop/tmp/dfs/datavalue>
property>
configuration>
⑥ 修改 mapred-site.xml:
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapred.job.trackername>
<value>localhost:9010value>
property>
<property>
<name>yarn.app.mapreduce.am.envname>
<value>HADOOP_MAPRED_HOME=/usr/local/Cellar/hadoop/3.3.1/libexecvalue>
property>
<property>
<name>mapreduce.map.envname>
<value>HADOOP_MAPRED_HOME=/usr/local/Cellar/hadoop/3.3.1/libexecvalue>
property>
<property>
<name>mapreduce.reduce.envname>
<value>HADOOP_MAPRED_HOME=/usr/local/Cellar/hadoop/3.3.1/libexecvalue>
property>
configuration>
⑦ 修改yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>localhost:9000value>
property>
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percentname>
<value>100value>
property>
configuration>
03 启动Hadoop并验证
3.1 启动Hadoop
① 启动hadoop :
cd /usr/local/Cellar/hadoop/3.3.1/libexec/sbin
./start-dfs.sh
② 浏览器中输入http://localhost:9870/,出现以下界面就说明成功了:

如果打不开这个web页面,而且又启动了,需要在hadoop下/etc/hadoop/hadoop-env.sh文件下第52行后面添加下方配置:
cd /usr/local/Cellar/hadoop/3.3.1/libexec/etc
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"
③ 可以停止服务hadoop服务:
./stop-yarn.sh
3.2 启动yarn服务
① 启动yarn服务:
cd /usr/local/Cellar/hadoop/3.3.1/libexec/sbin
./stop-dfs.sh
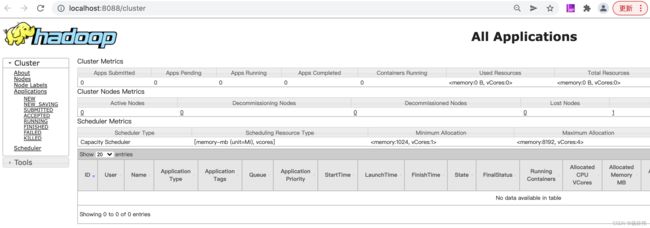
② 浏览器中打开http://localhost:8088/就会出现下图的界面:
③ 可以停止服务yarn服务:
./stop-yarn.sh
04 Hadoop sbin下的命令
1.启动所有的Hadoop守护进程(包括NameNode、 Secondary NameNode、DataNode、ResourceManager、NodeManager):
sbin/start-all.sh
2.停止所有的Hadoop守护进程(包括NameNode、 Secondary NameNode、DataNode、ResourceManager、NodeManager):
sbin/stop-all.sh
3.启动Hadoop HDFS守护进程NameNode、SecondaryNameNode、DataNode
sbin/start-dfs.sh
4.停止Hadoop HDFS守护进程NameNode、SecondaryNameNode和DataNode:
sbin/stop-dfs.sh
5.单独启动NameNode守护进程
sbin/hadoop-daemons.sh start namenode
6.单独停止NameNode守护进程
sbin/hadoop-daemons.sh stop namenode
7.单独启动DataNode守护进程
sbin/hadoop-daemons.sh start datanode
8.单独停止DataNode守护进程
sbin/hadoop-daemons.sh stop datanode
9.单独启动SecondaryNameNode守护进程:
sbin/hadoop-daemons.sh start secondarynamenode
10.单独停止SecondaryNameNode守护进程
sbin/hadoop-daemons.sh stop secondarynamenode
11.启动ResourceManager、NodeManager
sbin/start-yarn.sh
12.停止ResourceManager、NodeManager
sbin/stop-yarn.sh
13.单独启动ResourceManager
sbin/yarn-daemon.sh start resourcemanager
14.单独启动NodeManager
sbin/yarn-daemons.sh start nodemanager
15.单独停止ResourceManager
sbin/yarn-daemon.sh stop resourcemanager
16.单独停止NodeManager
sbin/yarn-daemons.sh stopnodemanager
17.手动启动jobhistory
sbin/mr-jobhistory-daemon.sh start historyserver
18.手动停止jobhistory
sbin/mr-jobhistory-daemon.sh stop historyserver