“文心”取自《文心雕龙》一书的开篇,作者刘勰在书中引述了一个古代典故:春秋时期,鲁国有一位名叫孔文子的大夫,他在学问上非常有造诣,但是他的儿子却不学无术,孔文子非常痛心。
一天,孔文子在山上遇到了一位神仙,神仙告诉他:“你的儿子之所以不学无术,是因为你没有给他灌输文心,让他懂得文学的魅力和意义。”孔文子听后深受启发,回家后开始给儿子灌输文学知识,儿子也逐渐对学问产生了兴趣,最终成为了一位有学问的人。因此,刘勰在书中将“文心”解释为“灌输文学知识的心灵”之意。
百度以“文心”命名自己的AI产品线,可见其对自己的中文处理能力是极为自信的,ERNIE3.0对标ChatGPT3.5/4.0,ERNIE-ViLG对标Stable-Diffusion,文心PLATO则可以理解为ChatGPT的embedding,可谓是野心勃勃。
文心一言SDK引入
百度目前已经开源文心一言的sdk工具包:
pip3 install --upgrade wenxin-api和百度云产品线一样,安装好以后,需要去文心一言官网获取appkey和appsecret
随后编写请求逻辑:
import wenxin_api
from wenxin_api.tasks.free_qa import FreeQA
wenxin_api.ak = "your ak" #输入您的API Key
wenxin_api.sk = "your sk" #输入您的Secret Key
input_dict = {
"text": "问题:天为什么这么蓝?\n回答:",
"seq_len": 512,
"topp": 0.5,
"penalty_score": 1.2,
"min_dec_len": 2,
"min_dec_penalty_text": "。?:![]",
"is_unidirectional": 0,
"task_prompt": "qa",
"mask_type": "paragraph"
}
rst = FreeQA.create(**input_dict)
print(rst)程序返回:
{
"code": 0,
"msg": "success",
"data": {
"result": "因为我们有个好心情",
"createTime": "2023-03-16 16:02:10",
"requestId": "71a6efb46acbd64394374f44579a01eb",
"text": "天为什么这么蓝",
"taskId": 1000000,
"status": 1 # 0表示生成中,1表示生成成功
}
}请求的参数含义请参照官方文档:
async
异步标识 int 1
1
是
异步标识,现阶段必传且传1
text
用户输入文本 string 空
[1, 1000]
是
模型的输入文本,为prompt形式的输入。
min_dec_len
最小生成长度 int 1
[1,seq_len]
是
输出结果的最小长度,避免因模型生成END导致生成长度过短的情况,与seq_len结合使用来设置生成文本的长度范围。
seq_len
最大生成长度 int 128
[1, 1000]
是
输出结果的最大长度,因模型生成END或者遇到用户指定的stop_token,实际返回结果可能会小于这个长度,与min_dec_len结合使用来控制生成文本的长度范围。
topp
多样性 float 1.0
[0.0,1.0],间隔0.1
是
影响输出文本的多样性,取值越大,生成文本的多样性越强。
penalty_score
重复惩罚 float 1.0
[1,2]
否
通过对已生成的token增加惩罚,减少重复生成的现象。值越大表示惩罚越大。设置过大会导致长文本生成效果变差。
stop_token
提前结束符 string 空
否
预测结果解析时使用的结束字符串,碰到对应字符串则直接截断并返回。可以通过设置该值,可以过滤掉few-shot等场景下模型重复的cases。
task_prompt
任务类型 string 空 PARAGRAPH,
SENT, ENTITY,
Summarization, MT,
Text2Annotation,
Misc, Correction,
QA_MRC, Dialogue,
QA_Closed_book,
QA_Multi_Choice,
QuestionGeneration,
Paraphrasing, NLI,
SemanticMatching,
Text2SQL,
TextClassification,
SentimentClassification,
zuowen, adtext,
couplet,novel,
cloze
否
指定预置的任务模板,效果更好。 PARAGRAPH:引导模型生成一段文章; SENT:引导模型生成一句话; ENTITY:引导模型生成词组; Summarization:摘要; MT:翻译; Text2Annotation:抽取; Correction:纠错; QA_MRC:阅读理解; Dialogue:对话; QA_Closed_book: 闭卷问答; QA_Multi_Choice:多选问答; QuestionGeneration:问题生成; Paraphrasing:复述; NLI:文本蕴含识别; SemanticMatching:匹配; Text2SQL:文本描述转SQL;TextClassification:文本分类; SentimentClassification:情感分析; zuowen:写作文; adtext:写文案; couplet:对对联; novel:写小说; cloze:文本补全; Misc:其它任务。
typeId
模型类型 int 1 1
是
通用:
1 ERNIE 3.0 Zeus 通用
2 ERNIE 3.0 Zeus instruct模型
同义改写
1 ERNIE 3.0 Zeus 同义改写精调模型
写作文:
1 ERNIE 3.0 Zeus 记叙文增强包
2 ERNIE 3.0 Zeus 议论文增强包
3 ERNIE 3.0 Zeus 小学作文增强包
写文案:
1 ERNIE 3.0 百亿 社交短文案精调模型
2 ERNIE 3.0 Zeus 商品营销文案增强包
写摘要:
1 ERNIE 3.0 Zeus 写摘要
2 ERNIE 3.0 Zeus 写标题
3 ERNIE 3.0 百亿 写标题
对对联:
1 ERNIE 3.0 Zeus 对对联
2 ERNIE 3.0 百亿 对对联
自由问答:
1 ERNIE 3.0 Zeus 自由问答增强包
2 ERNIE 3.0 百亿 自由问答
3 ERNIE 3.0 Zeus instruct模型
写小说
1 ERNIE 3.0百亿 写小说精调模型
补全文本
1 ERNIE 3.0 Zeus 词补全增强包
2 ERNIE 3.0 Zeus 句补全增强包
3 ERNIE 3.0 Zeus 段落补全增强包
penalty_text
惩罚文本 string 空
否
模型会惩罚该字符串中的token。通过设置该值,可以减少某些冗余与异常字符的生成。
choice_text
候选文本 string 空
否
模型只能生成该字符串中的token的组合。通过设置该值,可以对某些抽取式任务进行定向调优。
is_unidirectional
单双向控制开关 int 0
0或1
否
0表示模型为双向生成,1表示模型为单向生成。建议续写与few-shot等通用场景建议采用单向生成方式,而完型填空等任务相关场景建议采用双向生成方式。
min_dec_penalty_text
最小惩罚样本 string 空
否
与最小生成长度搭配使用,可以在min_dec_len步前不让模型生成该字符串中的tokens。
logits_bias
屏蔽惩罚 float -10000
[1, 1000]
否
配合penalty_text使用,对给定的penalty_text中的token增加一个logits_bias,可以通过设置该值屏蔽某些token生成的概率。
mask_type
生成粒度 string word
可选参数为word, sentence, paragraph
否
设置该值可以控制模型生成粒度。这里需要注意的是,虽然参数支持async异步,但那不是指请求的异步方式返回,换句话说,文心模型返回还是需要等待的,并不是ChatGPT那种流式返回模式。
文心一言API调用
文心一言SDK的功能有限,也不支持异步请求调用,如果需要定制化或者使用别的语言请求文心一言,需要提前发起Http请求获取token,这里我们使用异步请求库httpx:
pip3 install httpx添加获取token逻辑:
class Winxin:
def chat(self,text):
input_dict = {
"text": f"问题:{text}\n回答:",
"seq_len": 512,
"topp": 0.5,
"penalty_score": 1.2,
"min_dec_len": 2,
"min_dec_penalty_text": "。?:![]",
"is_unidirectional": 0,
"task_prompt": "qa",
"mask_type": "paragraph"
}
rst = FreeQA.create(**input_dict)
print(rst)
async def get_token(self):
headers = {"Content-Type":"application/x-www-form-urlencoded"}
async with httpx.AsyncClient() as client:
resp = await client.post(f"https://wenxin.baidu.com/moduleApi/portal/api/oauth/token?grant_type=client_credentials&client_id={wenxin_api.ak}&client_secret={wenxin_api.sk}",headers=headers)
result = resp.json()
print(result)异步调用文心一言接口的token:
if __name__ == '__main__':
wx = Winxin()
asyncio.run(wx.get_token())程序返回:
{'code': 0, 'msg': 'success', 'data': '24.3f6a63545345ae6588ea86a353.86400000.1679123673218.92a99f8955c6f9ab2c438a5f31b5d73b-173001'}这里返回的数据的data就是token,有效期是一天,吐槽一下,居然没有refreshtoken,也就是说过期了还得重新去请求,不能做到无感知换取。
随后请求接口换取taskid:
async def get_task(self,token,text):
url = "https://wenxin.baidu.com/moduleApi/portal/api/rest/1.0/ernie/3.0.25/zeus"
data = {"async": 1, "typeId": 1, "seq_len": 512, "min_dec_len": 2, "topp": 0.8, "task_prompt": "qa", "penalty_score": 1.2, "is_unidirectional": 0, "min_dec_penalty_text": "。?:![]", "mask_type": "word","text":text}
headers = { "Content-Type": "application/x-www-form-urlencoded" }
params = { "access_token": token }
async with httpx.AsyncClient() as client:
result = client.post(url, headers=headers, params=params, data=data)
result = result.json()
print(result)
返回:
{
"code":0,
"msg":"success",
"data":{
"taskId": 1229202,
"requestId":"7fad28872989e274914ee1687b8f2a13"
}
}最后请求结果:
async def get_res(self,taskid,token):
url = "https://wenxin.baidu.com/moduleApi/portal/api/rest/1.0/ernie/v1/getResult"
access_token = token
task_id = taskid
headers = { "Content-Type": "application/x-www-form-urlencoded" }
params = { "access_token": access_token }
data = { "taskId": task_id }
async with httpx.AsyncClient() as client:
response = client.post(url, headers=headers, params=params, data=data)
print(response.text)结果和SDK请求方式一致:
{
"code": 0,
"msg": "success",
"data": {
"result": "因为我们有个好心情",
"createTime": "2023-03-16 18:09:40",
"requestId": "71a6efb46acbd64394374f44579a01eb",
"text": "天为什么这么蓝",
"taskId": 1000000,
"status": 1 # 0表示生成中,1表示生成成功
}
}文心一格文字生成图像
ERNIE-ViLG AI作画大模型:文心ERNIE-ViLG2.0 是基于用户输入文本、或文本加图片生成图像及图像编辑功能的技术,主要为用户提供跨模态的文本生成图像的大模型技术服务。
文心一格和文心一言是共享appkey和appsecret的,添加图像生成逻辑:
class Winxin:
def draw(self,text):
num = 1
input_dict = {
"text": "国画,工笔画,女侠,正脸",
"style": "工笔画",
"resolution":"1024*1024",
"num": num
}
rst = TextToImage.create(**input_dict)
print(rst)
程序返回:
{
"imgUrls":[
"https://wenxin.baidu.com/younger/file/ERNIE-ViLG/61157afdaef4f0dfef0d5e51459160fbex"
]
}效果:

对比基于Stable-Diffusion算法的Lora模型:

大家丰俭由己,各取所需。
需要注意的是,该产品线并不是免费的:
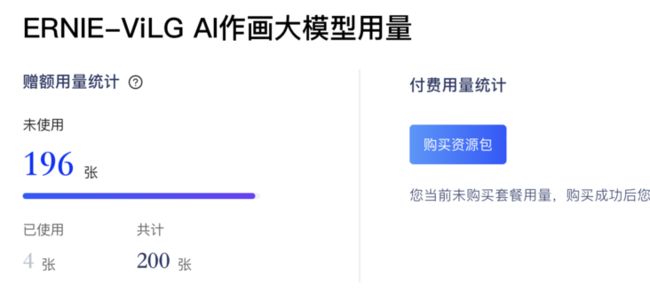
免费送200张,想继续玩就得充值,不愧是百度。话说免费的Stable-Diffusion不香吗?
结语
产品力而言,ChatGPT珠玉在前,文心一言还有很长的路需要走,用三国时期徐庶自比孔明的话来讲:“驽马焉敢并麒麟,寒鸦岂能配凤凰”。但是,也没必要一片挞伐之声,俄国著名作家契诃夫曾经说,“大狗叫,小狗也要叫”,ChatGPT虽然一座遥不可及的高峰,但是其他公司也无须放弃人工智能领域的研究,毕竟作为最老牌的中文搜索引擎,百度浸润几十年的中文处理能力,还是无人能出其右的。