word2vec Skip-Gram和CBOW小白学习笔记
一背景
非专业,业务又有这方面需要,强迫自己看一下NLP相关的背景知识。数学不高,不奢望能看懂,要是有大神能从小白的角度去讲解就好了。
NLP 入门整理(不定期更新)
Word2Vec前序 语言模型学习
相关知识点:
要知道词向量:神经网络只能接受数值输入,而且不同词汇之间可能存在的关联信息也需要挖掘。为啥不用one hot编码,维度太大计算量太大。
还有计算相似度的有一种方法就是利用夹角余弦。
词嵌入:word embedding,相关理论:上下文相似的词,其语义也相似。而word embedding是一个将词向量化的概念。
向量空间模型:向量空间模型 (VSMs)将词汇表达(嵌套)于一个连续的向量空间中,语义近似的词汇被映射为相邻的数据点。常见分类有基于统计的、基于神经概率化语言模型预测的。
简单概括下:
Word2Vec其实就是通过学习文本来用词向量的方式表征词的语义信息,即通过一个嵌入空间使得语义上相似的单词在该空间内距离很近。
要是还觉得抽象,那就用网上常见的例子,cat这个单词和kitten(小猫)属于语义上很相近的词,而dog和kitten则不是那么相近,iphone这个单词和kitten的语义就差的更远了。
二 模型
Word2Vec模型中,主要有Skip-Gram和CBOW两种模型,从算法角度看,这两种方法非常相似,其区别为CBOW根据源词上下文词汇预测input word,Skip-Gram是给定input word来预测上下文。

如果想深入了解word2vec及其内部的数学推导,可以看大神peghoty的博客,这是我见过最全的word2vec原理讲解,下面是peghoty大神的文章节选。
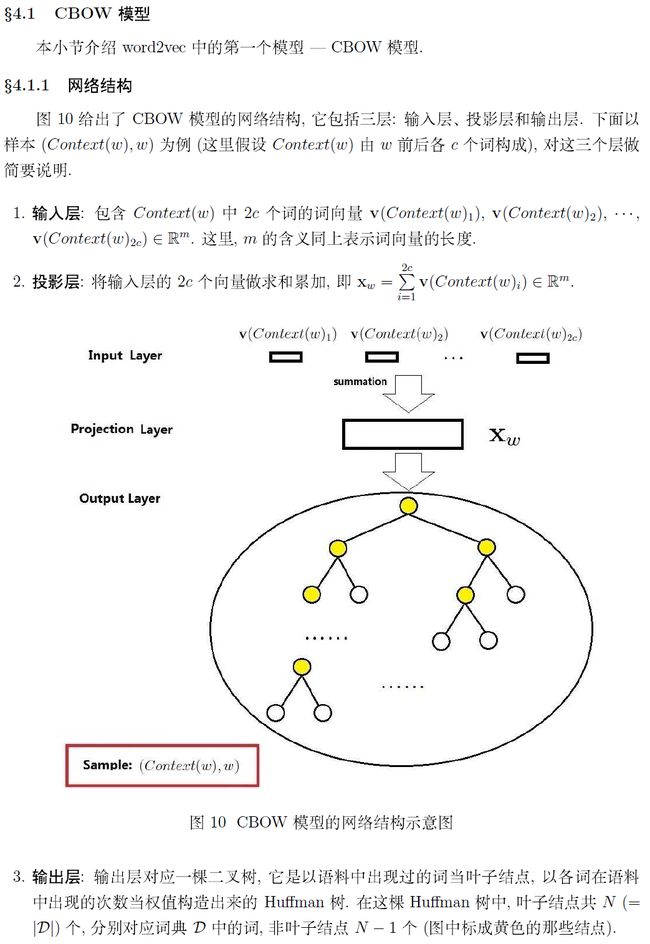

要是数学好,你那就直接看peghoty大神那种带着数学推导的解释原理的就行。我看不懂,就先看一些偏直观一些的扫盲文章。
Skip-gram
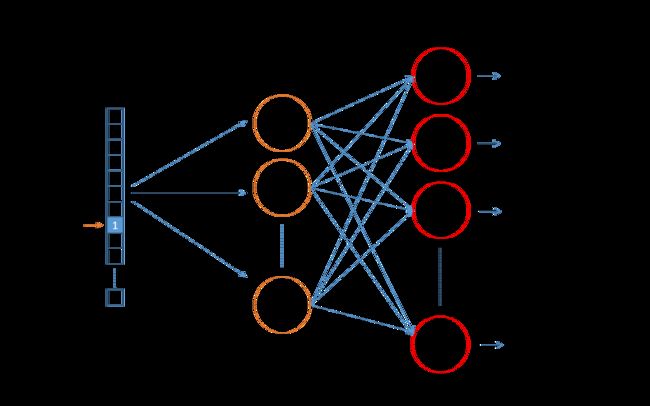
方便理解,也是3层结构。也是input word和output word都是one-hot编码的向量。最终模型的输出是一个概率分布。注意这是skip-gram模型的一个理解,Word2Vec的实际实现的输出层是Huffman Tree,不是简单的softmax.
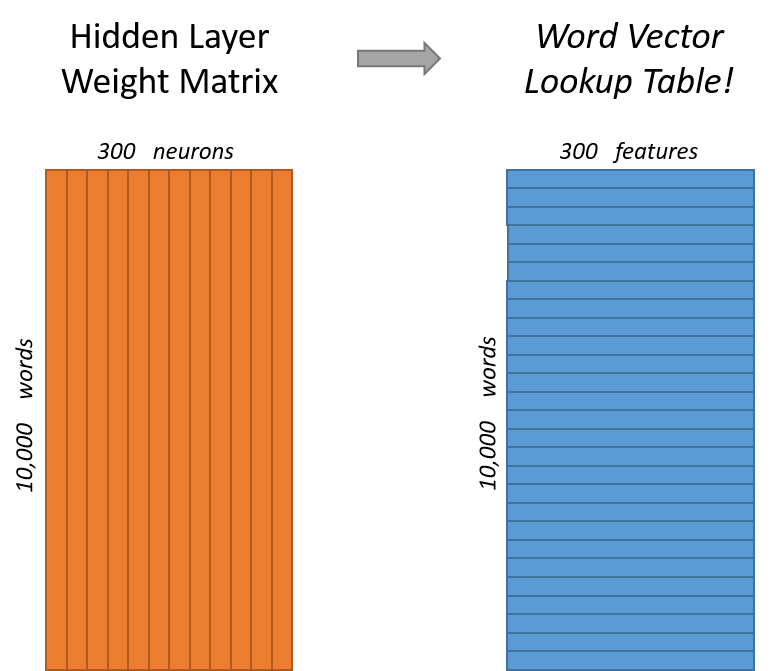
来看下隐层。如果我们现在想用300个特征来表示一个单词(即每个词可以被表示为300维的向量)。那么隐层的权重矩阵应该为10000行,300列(隐层有300个结点)。
看下面的图片,左右两张图分别从不同角度代表了输入层-隐层的权重矩阵。左图中每一列代表一个10000维的词向量和隐层单个神经元连接的权重向量。从右边的图来看,每一行实际上代表了每个单词的词向量。
上面我们提到,input word和output word都会被我们进行one-hot编码。仔细想一下,我们的输入被one-hot编码以后大多数维度上都是0(实际上仅有一个位置为1),所以这个向量相当稀疏,它会消耗相当大的计算资源,为了高效计算,它仅仅会选择矩阵中对应的向量中维度值为1的索引行。

按照矩阵乘法的规则计算方式是十分低效的。为了有效地进行计算,这种稀疏状态下不会进行矩阵乘法计算,可以看到矩阵的计算的结果实际上是矩阵对应的向量中值为1的索引,这样模型中的隐层权重矩阵便成了一个”查找表“(lookup table),进行矩阵计算时,直接去查输入向量中取值为1的维度下对应的那些权重值。隐层的输出就是每个输入单词的“嵌入词向量”。
输出层是一个softmax回归分类器,它的每个结点将会输出一个0-1之间的值(概率),这些所有输出层神经元结点的概率之和为1。
模型的输出概率代表着到我们词典中每个词有多大可能性跟input word同时出现。直观来看,下面的图中给出了一些我们的训练样本的例子。我们选定句子“The quick brown fox jumps over lazy dog”,设定我们的窗口大小为2(),也就是说我们仅选输入词前后各两个词和输入词进行组合。下图中,蓝色代表input word,方框内代表位于窗口内的单词。

我们的模型将会从每对单词出现的次数中习得统计结果。例如,我们的神经网络可能会得到更多类似(“Soviet“,”Union“)这样的训练样本对,而对于(”Soviet“,”Sasquatch“)这样的组合却看到的很少。因此,当我们的模型完成训练后,给定一个单词”Soviet“作为输入,输出的结果中”Union“或者”Russia“要比”Sasquatch“被赋予更高的概率。
可以这样理解:比如对于同义词“intelligent”和“smart”,我们觉得这两个单词应该拥有相同的“上下文”,就是窗口词很相近。那么通过我们的模型训练,这两个单词的嵌入向量将非常相似。
两个加速优化方法
上面我们了解skip-gram的输入层、隐层、输出层。然而,每当计算一个词的概率都要对词典里的V个词计算相似度,然后进行归一化,这基本上时不现实的。为此,Mikolov引入了两个加速手段:层次Softmax(Hierarchical Softmax)和负采样(Negative Sampling)。普遍认为Hierarchical Softmax对低频词效果较好;Negative Sampling对高频词效果较好,向量维度较低时效果更好。
简单来说,Hierarchical Softmax是一种对输出层进行优化的策略,输出层从原始模型的利用softmax计算概率值改为了利用Huffman树计算概率值。
Huffman树
Huffman编码又称为最优二叉树,表示一种带权路径长度最短的二叉树。带权路径长度,指的就是叶子结点的权值乘以该结点到根结点的路径长度。而我们需要构造的Huffman树结构,是以词表为根结点,每一个子节点为父节点的不相交子集,词为叶节点的结构。我们将叶节点的权值转化为词频,则带权路径长度指的就是词频乘以路径的大小,带权路径最小的条件使得构造出来的霍夫曼树中,高频词离根结点更近,而低频词离根结点更远。其构造的Huffman树如下所示

在构建Huffman树的同时,会为每一个非叶子节点初始化一个向量,该向量用于与预测向量求条件概率,从根节点出发到叶子节点,走到指定叶子节点 的过程,就是一个进行 次二分类的过程:路径上的每个非叶子节点都拥有两个孩子节点,从当前节点 n(w,j)n(w,j) 向下走时共有两种选择,走到左孩子节点 就定义为分类到了正类,走到右孩子节点就定义为分类到了负类。
公式不贴了,效果就是把 N 分类问题变成 log(N)次二分类。代价是人为增强了词与词之间的耦合性(实际上大部分呢业务场景你能满足,不用纠结)
负采样(Nagative Sampling)
NCE算法改造的是模型的似然函数,Skip-gram模型其原始的似然函数对应着一个多项分布。怎么计算推导过程我不贴了,主要是看不懂。
不同于原本每个训练样本更新所有的权重,负采样每次让一个训练样本仅仅更新一小部分的权重,这样就会降低梯度下降过程中的计算量。
直观感受:当我们用训练样本 ( input word: "fox",output word: "quick") 来训练我们的神经网络时,“ fox”和“quick”都是经过one-hot编码的。如果我们的vocabulary大小为10000时,在输出层,我们期望对应“quick”单词的那个神经元结点输出1,其余9999个都应该输出0。在这里,这9999个我们期望输出为0的神经元结点所对应的单词我们称为“negative” word。
当使用负采样时,我们将随机选择一小部分的negative words(比如选5个negative words)来更新对应的权重。我们也会对我们的“positive” word进行权重更新(在我们上面的例子中,这个单词指的是”quick“)。
作者给出的经验参考值:小规模选择5-20个,大规模选择2-5个。
回忆一下我们的隐层-输出层拥有300 x 10000的权重矩阵。如果使用了负采样的方法我们仅仅去更新我们的positive word-“quick”的和我们选择的其他5个negative words的结点对应的权重,共计6个输出神经元,相当于每次只更新300*6=1800个权重。对于3百万的权重来说,相当于只计算了0.06%的权重,这样计算效率就大幅度提高。
一个单词被选作negative sample的概率跟它出现的频次有关,出现频次越高的单词越容易被选作negative words。
word2vec的局限性
总的来说,word2vec通过嵌入一个线性的投影矩阵(projection matrix),将原始的one-hot向量映射为一个稠密的连续向量,并通过一个语言模型的任务去学习这个向量的权重,而这个过程可以看作是无监督或称为自监督的,其词向量的训练结果与语料库是紧密相关的,因此通常不同的应用场景需要用该场景下的语料库去训练词向量才能在下游任务中获得最好的效果。这一思想后来被广泛应用于包括word2vec在内的各种NLP模型中,非常经典,局限性如下:
- 在模型训练的过程中仅仅考虑context中的局部语料,没有考虑到全局信息;
- 英语不需要考虑分词,中文需要考虑(我们在训练词向量之前首先要解决分词的问题,分词直接影响词向量的质量)。
参考:
https://www.cnblogs.com/peghoty/p/3857839.html
https://zhuanlan.zhihu.com/p/27234078
https://zhuanlan.zhihu.com/p/33799633
https://zhuanlan.zhihu.com/p/28894219