HiveSQL基础练习题
HiveSQL基础练习题
-
- 1.环境准备
-
- 1.1建表语句
- 1.2数据准备
- 1.3插入数据
- 2.查询
-
- 2.1 查询姓名中带“华”的学生名单
- 2.2 查询姓“王”老师的个数
- 2.3 检索课程编号为“04”且分数小于60的学生学号,结果按分数降序排列
- 2.4 查询语文成绩 < 90分的学生和其对应的成绩,按照学号升序排序
- 2.5 查询各学生的年龄(精确到月份)
- 2.6 查询本月过生日的学生
- 2.7 查询课程编号为“04”的总成绩
- 2.8 查询参加考试的学生个数
- 2.9 查询各科成绩最高和最低的分,以如下的形式显示:课程号,最高分,最低分
- 2.10 查询每门课程有多少学生参加了考试(有考试成绩)
- 2.11 查询男生、女生人数
- 2.12 查询平均成绩大于60分学生的学号和平均成绩
- 2.13 查询至少选修两门课程的学生学号
- 2.14 统计同姓(假设每个学生姓名的第一个字为姓)的学生人数
- 2.15查询每门课程的平均成绩,结果按平均成绩升序排序,平均成绩相同时,按课程号降序排列
- 2.16 统计参加考试人数大于等于15的学科
- 2.17 查询学生的总成绩并进行排名
- 2.18 查询平均成绩大于60分的学生的学号和平均成绩
- 2.19 按照如下格式显示学生的语文、数学、英语三科成绩,没有成绩的输出为0,按照学生的有效平均成绩降序显示
- 2.20查询一共参加两门课程且其中一门为语文课程的学生的id和姓名
- 2.21查询所有课程成绩小于60分学生的学号、姓名
- 2.22查询没有学全所有课的学生的学号、姓名
- 2.23查询出只选修了两门课程的全部学生的学号和姓名
- 2.24查找1995年出生的学生名单
- 2.25查询两门以上不及格课程的同学的学号及其平均成绩
- 2.26 查询所有学生的学号、姓名、选课数、总成绩
- 2.27查询平均成绩大于85的所有学生的学号、姓名和平均成绩
- 2.28查询学生的选课情况:学号,姓名,课程号,课程名称
- 2.29查询出每门课程的及格人数和不及格人数
- 2.30 使用分段[100-85],[85-70],[70-60],[<60]来统计各科成绩,分别统计:各分数段人数,课程号和课程名称
- 2.31 查询课程编号为03且课程成绩在80分以上的学生的学号和姓名
- 2.32 (重要!行转列)使用sql实现将该表行转列为下面的表结构
- 2.33 检索"01"课程分数小于60,按分数降序排列的学生信息
- 2.34 查询任何一门课程成绩在70分以上的学生的姓名、课程名称和分数
- 2.35 查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
- 2.36 查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩
- 2.37 查询课程编号为“01”的课程比“02”的课程成绩高的所有学生的学号
- 2.38 查询学过编号为“01”的课程并且也学过编号为“02”的课程的学生的学号、姓名
- 2.39 查询学过“李体音”老师所教的所有课的同学的学号、姓名
- 2.40 查询学过“李体音”老师所讲授的任意一门课程的学生的学号、姓名
- 2.41 查询没学过"李体音"老师讲授的任一门课程的学生id及其学生姓名
- 2.42 查询选修“李体音”老师所授课程的学生中成绩最高的学生姓名及其成绩
- 2.43 查询至少有一门课与学号为“001”的学生所学课程相同的学生的学号和姓名
- 2.44 查询所学课程与学号为“001”的学生所学课程完全相同的学生的学号和姓名
- 2.45 查询学过与学号为“001”的学生全部所学课程的学生的学号和姓名
- 2.46 按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
- 2.47 查询每个学生的学生平均成绩及其名次
- 2.48 按各科成绩进行排序,并显示在这个学科中的排名
- 2.49 查询每门课程成绩最好的前两名学生姓名及成绩
- 2.50 查询所有课程的成绩第2名到第3名的学生信息及该课程成绩
- 2.51 查询各科成绩前三名的记录(如果有并列,则全部展示,例如如果前7名为:80,80,80,79,79,77,75,70,则统计结果为数字的前三名,结果为80,80,80,79,79,77)
题目来自于尚硅谷,笔者自己写的 SQL,不保证全部正确
1.环境准备
1.1建表语句
create database if not exists db_hive;
use db_hive;
--创建学生表
drop table if exists student;
create table if not exists student(
stu_id string COMMENT '学生id',
stu_name string COMMENT '学生姓名',
birthday date COMMENT '出生日期',
sex string COMMENT '性别'
)
row format delimited fields terminated by ','
stored as textfile;
--创建课程表
drop table if exists course;
create table if not exists course(
course_id string COMMENT '课程id',
course_name string COMMENT '课程名',
tea_id string COMMENT '任课老师id'
)
row format delimited fields terminated by ','
stored as textfile;
--创建老师表
drop table if exists teacher;
create table if not exists teacher(
tea_id string COMMENT '老师id',
tea_name string COMMENT '老师姓名'
)
row format delimited fields terminated by ','
stored as textfile;
--创建分数表
drop table if exists score;
create table if not exists score(
stu_id string COMMENT '学生id',
course_id string COMMENT '课程id',
grade int COMMENT '成绩'
)
row format delimited fields terminated by ','
stored as textfile;
1.2数据准备
- 创建/opt/module/data目录,将如下4个文件放到/opt/module/data目录下
以下是部分数据(自己准备数据)
[hyj@hadoop102 data]$ cat student.txt
001,彭于晏,1995-05-16,男
002,胡歌,1994-03-20,男
003,周杰伦,1995-04-30,男
004,刘德华,1998-08-28,男
005,唐国强,1993-09-10,男
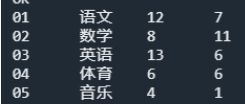
[hyj@hadoop102 data]$ cat course.txt
01,语文,1003
02,数学,1001
03,英语,1004
04,体育,1002
05,音乐,1002
[hyj@hadoop102 data]$ cat teacher.txt
1001,张高数
1002,李体音
1003,王子文
1004,刘丽英
[hyj@hadoop102 data]$ cat score.txt
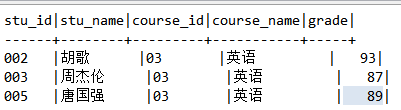
001,01,94
002,01,74
004,01,85
005,01,64
006,01,71
007,01,48
008,01,56
009,01,75
1.3插入数据
- 向表中加载数据
load data local inpath '/opt/module/data/student.txt' into table student;
load data local inpath '/opt/module/data/course.txt' into table course;
load data local inpath '/opt/module/data/teacher.txt' into table teacher;
load data local inpath '/opt/module/data/score.txt' into table score;
- 验证插入数据情况
select * from student limit 5;
select * from course limit 5;
select * from teacher limit 5;
select * from score limit 5;
2.查询
2.1 查询姓名中带“华”的学生名单
%代表任意个字符(0个或多个)
-代表一个字符
select * from student where stu_name like '%华%';
2.2 查询姓“王”老师的个数
select count(*) from teacher where tea_name like '王%';
2.3 检索课程编号为“04”且分数小于60的学生学号,结果按分数降序排列
select stu_id from score where course_id='04' and grade < 60 order by grade desc;
2.4 查询语文成绩 < 90分的学生和其对应的成绩,按照学号升序排序
select s2.stu_id,s2.stu_name,s1.grade from course c,score s1,student s2 where c.course_id=s1.course_id
and c.course_name="语文" and s1.stu_id=s2.stu_id and s1.grade < 90 order by s2.stu_id;
2.5 查询各学生的年龄(精确到月份)
- 获取年份
select year(‘2023-05-21’);- 获取当前日期
select current_date();- 获取月份
select month(‘2023-05-21’);- if条件判断: if(boolean testCondition, T valueTrue, T valueFalseOrNull)
select
stu_name,
concat(
if(bir_year>=0,bir_year,bir_year-1),'岁',
if(bir_month>=0,bir_month,bir_month+12),'个月'
) as age
from (
select
stu_name,
year(current_date())-year(birthday) bir_year,
month(current_date())-month(birthday) bir_month
from student
) t;
2.6 查询本月过生日的学生
select * from student where month(birthday)=month(current_date());
2.7 查询课程编号为“04”的总成绩
方法一:
select '04' as course_id,sum(grade) as grade_sum from score where course_id='04';
方法二:
select course_id,sum(grade) as grade_sum from score where course_id='04' group by course_id;
2.8 查询参加考试的学生个数
思路:对成绩表中的学号做去重并count
select count(distinct(stu_id)) from score;
--或
select count(*) from (select distinct(stu_id) from score) t;
2.9 查询各科成绩最高和最低的分,以如下的形式显示:课程号,最高分,最低分
思路:按照学科分组并使用max和min。
select course_id,max(grade),min(grade) from score group by course_id;
2.10 查询每门课程有多少学生参加了考试(有考试成绩)
select course_id,count(*) from score group by course_id;
2.11 查询男生、女生人数
select sex,count(*) from student group by sex;
2.12 查询平均成绩大于60分学生的学号和平均成绩
select stu_id,avg(grade) avg_grade from score group by stu_id having avg_grade>60;
2.13 查询至少选修两门课程的学生学号
select stu_id,count(distinct course_id) course_num from score group by stu_id having course_num>=2;
2.14 统计同姓(假设每个学生姓名的第一个字为姓)的学生人数
思路:先提取出每个学生的姓并分组,如果分组的count>=2则为同姓
substring(str, pos[, len])
如:substring(“hellohive”,2,3) 从2位置开始截取3长度
注意:下标是从1开始的.
select first_stu_name,
count(*) as count_first_stu_name
from (
select
substring(stu_name,1,1) first_stu_name
from student
) t
group by first_stu_name
having count_first_stu_name>=2;
2.15查询每门课程的平均成绩,结果按平均成绩升序排序,平均成绩相同时,按课程号降序排列
select course_id,avg(grade) avg_grade from score group by course_id order by avg_grade asc,course_id desc;
2.16 统计参加考试人数大于等于15的学科
select course_id,count(stu_id) count_stu from score group by course_id having count_stu >= 15;
2.17 查询学生的总成绩并进行排名
select stu_id,sum(grade) sum_grade from score group by stu_id order by sum_grade desc;
2.18 查询平均成绩大于60分的学生的学号和平均成绩
思路:分组,avg,过滤>=60
select * from (select stu_id,avg(grade) avg_grade from score group by stu_id) t where avg_grade > 60;
2.19 按照如下格式显示学生的语文、数学、英语三科成绩,没有成绩的输出为0,按照学生的有效平均成绩降序显示
学生id 学生姓名 语文 数学 英语 有效课程数 有效平均成绩
NVL( value,default_value) 函数
- 它的功能是如果value为NULL,则NVL函数返回default_value的值,否则返回value的值,如果两个参数都为NULL ,则返回NULL。
case when 判断:
- 语法1:
CASE
WHEN 条件1 THEN VALUE1
WHEN 条件2 THEN VALUE2
……
WHEN 条件N THEN VALUEN
ELSE 默认值
END
- 语法2:
CASE 列
WHEN V1 THEN VALUE1
WHEN V2 THEN VALUE2
……
WHEN VN THEN VALUEN
ELSE 默认值
END
select h.stu_id as `学生id`,student.stu_name as `学生姓名`,`语文`,`数学`,`英语`,`有效课程数`,`平均成绩`
from
(select
stu_id,
max(case course_name when '语文' then grade else 0 end) as `语文`,
max(case course_name when '数学' then grade else 0 end) as `数学`,
max(case course_name when '英语' then grade else 0 end) as `英语`,
count(*) as `有效课程数`,
avg(grade) as `平均成绩`
from
(select s.stu_id,c.course_name,s.grade from course c join score s on c.course_id=s.course_id) t
group by stu_id
order by avg(grade) desc
) h join student on h.stu_id=student.stu_id;
2.20查询一共参加两门课程且其中一门为语文课程的学生的id和姓名
select t2.stu_id,student.stu_name
from (
select stu_id,count(*) cnt,sum(case course_name when '语文' then 1 else 0 end) as cond
from
(select g.stu_id,c.course_id,c.course_name from course c join score g on c.course_id=g.course_id) t1
group by stu_id having cnt=2 and cond=1
) t2 join student on t2.stu_id=student.stu_id;
select t.stu_id,student.stu_name
from
(select
stu_id
from
score
where
stu_id in (select stu_id from score where course_id in (select course_id from course where course_name='语文'))
group by stu_id
having count(*)=2
) t join student on t.stu_id=student.stu_id;
2.21查询所有课程成绩小于60分学生的学号、姓名
select s.stu_id,s.stu_name,t.max_grade
from (
select stu_id,max(grade) max_grade from score group by stu_id having max_grade <60
) t join student s on t.stu_id=s.stu_id;
2.22查询没有学全所有课的学生的学号、姓名
解释:没有学全所有课,也就是该学生选修的课程数 < 总的课程数
select stu_id,stu_name
from (
select student.stu_id,student.stu_name,score.course_id from score join student on score.stu_id=student.stu_id
) t
group by stu_id,stu_name
having count(course_id) < (select count(course_id) from course);
2.23查询出只选修了两门课程的全部学生的学号和姓名
解释:学生选修的课程数=2
select s.stu_id,s.stu_name
from (
select stu_id from score group by stu_id having count(score.course_id)=2
) t join student s on t.stu_id=s.stu_id;
select stu_id,stu_name
from
student
where stu_id in (select stu_id from score group by stu_id having count(score.course_id)=2);
2.24查找1995年出生的学生名单
date_format() 函数: 格式化日期
select date_format(‘2023-05-23 15:58:43’,‘yyyy/MM/dd HH:mm:ss’);
select * from student where date_format(birthday,'yyyy')='1995';
2.25查询两门以上不及格课程的同学的学号及其平均成绩
先找出有两门以上不及格的学生名单,按照学生分组,过滤组内成绩低于60的并进行count,count>=2。
接着做出一张表查询学生的平均成绩并和上一个子查询中的学生学号进行连接
select s.stu_id,avg(s.grade) as avg_grade
from score s where s.stu_id in
(
select stu_id
from
score
where grade<60
group by stu_id
having count(*)>=2
)
group by s.stu_id;
2.26 查询所有学生的学号、姓名、选课数、总成绩
select t.stu_id,s.stu_name,`选课数`,`总成绩`
from (
select stu_id,count(course_id) as `选课数`,sum(grade) as `总成绩` from score group by stu_id
) t join student s on t.stu_id=s.stu_id;
2.27查询平均成绩大于85的所有学生的学号、姓名和平均成绩
select student.stu_id,student.stu_name,t.avg_grade
from (
select stu_id,avg(grade) avg_grade from score group by stu_id having avg_grade > 85
) t join student on t.stu_id=student.stu_id;
select distinct stu_id,stu_name,avg_grade
from(
select t.stu_id,t.stu_name,avg(grade) over(partition by s.stu_id) avg_grade
from
score s left join student t on s.stu_id=t.stu_id
) t
where t.avg_grade>85;
2.28查询学生的选课情况:学号,姓名,课程号,课程名称
select t.stu_id,t.stu_name,m.course_id,m.course_name
from student t left join (
select s.stu_id,c.course_id,c.course_name from score s left join course c on s.course_id=c.course_id
) m on t.stu_id=m.stu_id;
2.29查询出每门课程的及格人数和不及格人数
select
s.course_id,
c.course_name,
sum(case when grade>=60 then 1 else 0 end) as `及格人数`,
sum(case when grade<60 then 1 else 0 end) as `不及格人数`
from score s left join course c on s.course_id=c.course_id
group by s.course_id,c.course_name;
2.30 使用分段[100-85],[85-70],[70-60],[<60]来统计各科成绩,分别统计:各分数段人数,课程号和课程名称
select
sum(case when grade<=100 and grade >85 then 1 else 0 end) `[100-85]`,
sum(case when grade<=85 and grade>70 then 1 else 0 end) `[85-70]`,
sum(case when grade<=70 and grade>60 then 1 else 0 end) `[70-60]`,
sum(case when grade<60 then 1 else 0 end) `[<60]`,
s.course_id,
c.course_name
from score s left join course c on s.course_id=c.course_id
group by s.course_id,c.course_name;

2.31 查询课程编号为03且课程成绩在80分以上的学生的学号和姓名
select stu_id,stu_name
from
student
where stu_id in
(select stu_id from score where course_id='03' and grade>80);

select t.stu_id,t.stu_name,c.course_id,c.course_name,grade
from
score s inner join course c on s.course_id=c.course_id inner join student t on s.stu_id=t.stu_id
where c.course_id='03' and s.grade>80;
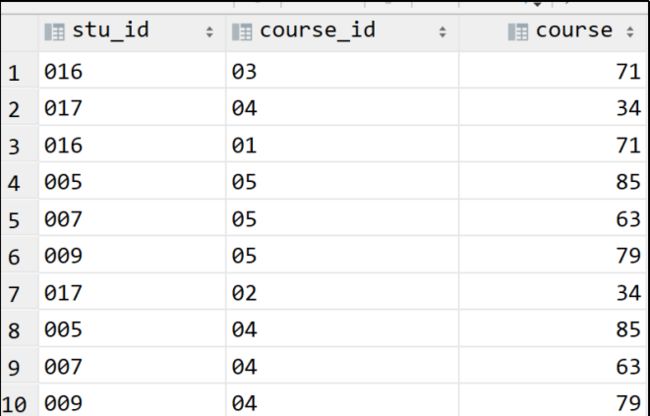
2.32 (重要!行转列)使用sql实现将该表行转列为下面的表结构
如果没有该课程成绩用0代替。
学号 课程01 课程02 课程03 课程04
select
stu_id,
max(case course_id when '01' then grade else 0 end) `课程01`,
max(case course_id when '02' then grade else 0 end) `课程02`,
max(case course_id when '03' then grade else 0 end) `课程03`,
max(case course_id when '04' then grade else 0 end) `课程04`
from
score
group by stu_id;
2.33 检索"01"课程分数小于60,按分数降序排列的学生信息
select s.*,t.grade
from
student s join (select stu_id,grade from score where course_id='01' and grade < 60) t on s.stu_id=t.stu_id
order by t.grade desc;

2.34 查询任何一门课程成绩在70分以上的学生的姓名、课程名称和分数
- 只要有一门课程超70分:
select t.stu_name,c.course_name,grade
from
score s join course c on s.course_id=c.course_id join student t on s.stu_id=t.stu_id
where s.grade>70;
- 所有的课程都在70分以上:
select t.stu_id,t.stu_name,c.course_name,s.grade
from
student t join score s on t.stu_id=s.stu_id join course c on s.course_id=c.course_id
where t.stu_id in
(select stu_id from score group by stu_id having min(grade)>70)
order by t.stu_id;
2.35 查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
知识点:分组 + 条件 + 多表连接
思路:计算每个学号不及格分数个数,筛选出大于2个的学号并找出姓名,平均成绩
select s.stu_id,s.stu_name,t.avg_grade
from(
select stu_id,avg(grade) avg_grade
from
score
where stu_id in (select stu_id from score where grade<60 group by stu_id having count(*)>=2)
group by stu_id
) t join student s on t.stu_id=s.stu_id;
2.36 查询不同课程成绩相同的学生的学生编号、课程编号、学生成绩
select s1.*
from score s1 inner join score s2 on s1.stu_id=s2.stu_id and s1.course_id<>s2.course_id and s1.grade=s2.grade;
2.37 查询课程编号为“01”的课程比“02”的课程成绩高的所有学生的学号
select stu_id
from(
select
stu_id,
max(case when course_id='01' then grade else 0 end) course_01,
max(case when course_id='02' then grade else 0 end) course_02
from
score
where score.course_id='01' or score.course_id='02'
group by stu_id
having count(*) =2
) t where course_01>course_02;
2.38 查询学过编号为“01”的课程并且也学过编号为“02”的课程的学生的学号、姓名
select stu_id,stu_name
from student
where stu_id in
(
select
stu_id
from
score
where score.course_id='01' or score.course_id='02'
group by stu_id
having count(*) =2
) ;
2.39 查询学过“李体音”老师所教的所有课的同学的学号、姓名
- size() 求集合中元素的个数 size(Map
) size(Array) - concat_set(colName) 用于将一列中的多行合并为一行,并进行去重,返回Array类型字段。而COLLECT_LIST(col) 不进行去重。
--先查询李体音老师所教的课程,并计算其所教的课程数
select stu_id,stu_name
from
student
where stu_id in
(
select score.stu_id
from(
select course_id, count_course
from
(select collect_set(course_id) course_ids,size(collect_set(course_id)) count_course
from
course where tea_id in (select tea_id from teacher where tea_name='李体音')
) a
lateral view explode(course_ids) b as course_id
) t join score on t.course_id=score.course_id
group by score.stu_id
having count(*)=max(count_course)
);
2.40 查询学过“李体音”老师所讲授的任意一门课程的学生的学号、姓名
select s.stu_id,s.stu_name
from (
select stu_id
from
score s join (select course_id from course where tea_id in (select tea_id from teacher where tea_name='李体音')) t on s.course_id=t.course_id
group by stu_id
having count(*)=1
) a join student s on a.stu_id=s.stu_id;
--查询只学过一门“李体音”老师所讲授的课程的学生的学号、姓名
select stu_id,stu_name
from student
where stu_id in
(select stu_id
from
score
where course_id in
(select course_id from course where tea_id in (select tea_id from teacher where tea_name='李体音'))
)
;
2.41 查询没学过"李体音"老师讲授的任一门课程的学生id及其学生姓名
select stu_id,stu_name
from
student
where stu_id not in (
select
distinct stu_id
from score s join
(select course_id from course where tea_id in (select tea_id from teacher where tea_name='李体音')) t
on s.course_id=t.course_id
);
2.42 查询选修“李体音”老师所授课程的学生中成绩最高的学生姓名及其成绩
(与上题类似,用成绩排名,用 limit 1得出最高一个)
select student.stu_name,grade
from
student join (
select stu_id,grade
from
score s join (
select course_id from course where tea_id in (select tea_id from teacher where tea_name='李体音')
) t on s.course_id=t.course_id
order by grade desc
limit 1
) a on a.stu_id=student.stu_id
;
2.43 查询至少有一门课与学号为“001”的学生所学课程相同的学生的学号和姓名
select stu_id,stu_name
from student where stu_id in (
select distinct stu_id
from
score
where stu_id!='001' and course_id in (select course_id from score where stu_id='001')
);
2.44 查询所学课程与学号为“001”的学生所学课程完全相同的学生的学号和姓名
concat_ws(SplitChar,element1,element2……) 用于实现字符串拼接,可以指定分隔符。
注意: CONCAT_WS must be"string or array"
array(n0, n1…) 创建一个数组
sort_array(array(obj1, obj2,…)) 对数组中的元素进行升序排序
select sort_array(array(‘021’,‘3’,‘21’,‘87’));
select sort_array(array(29,4,22,1,4,32,5));
select stu_id,stu_name
from
student
where stu_id in (
select stu_id
from
(select stu_id,concat_ws(',',sort_array(collect_list(course_id))) as course_ids from score group by stu_id) t2
where stu_id!='001' and course_ids=(select concat_ws(',',sort_array(collect_list(course_id))) as course_ids from score where stu_id='001')
);
2.45 查询学过与学号为“001”的学生全部所学课程的学生的学号和姓名
select stu_id,stu_name
from
student
where stu_id in (
select stu_id
from
score join
(select course_id, course_nums
from
(select collect_list(course_id) as course_ids,count(*) course_nums from score where stu_id='001') t1 lateral view explode(course_ids) l as course_id
) t2 on score.course_id=t2.course_id
where stu_id!='001'
group by stu_id
having count(*)=max(course_nums) --因为分组后的course_nums列可能有好几个值,只取一个
);
2.46 按平均成绩从高到低显示所有学生的所有课程的成绩以及平均成绩
select stu_name,course_name,grade,avg_grade
from
student join (
select stu_id,course_name,grade,avg(grade) over(partition by stu_id) avg_grade
from (
select s.stu_id,c.course_id,c.course_name,s.grade from course c join score s on c.course_id=s.course_id
) t1
) t2 on student.stu_id=t2.stu_id
order by avg_grade desc,student.stu_id asc
;
2.47 查询每个学生的学生平均成绩及其名次
- 取整函数: round 返回double类型的整数值部分 (遵循四舍五入)
select round(3.1415926);- 指定精度取整函数: round(double a, int d) 返回指定精度d的double类型
select round(3.1415926,4); --3.1416
-- RANK() 排序相同时会重复,总数不会变
select s.*,avg_grade,rank() over(order by avg_grade desc)
from
student s left join
(select stu_id,round(avg(grade),2) avg_grade from score group by stu_id) t
on s.stu_id=t.stu_id
;
2.48 按各科成绩进行排序,并显示在这个学科中的排名
select
stu_id,
stu_name,
course_name,
grade,
rank() over(partition by course_name order by grade desc)
from (
select s1.stu_id,s1.stu_name,c.course_name,s2.grade
from student s1 join score s2 on s1.stu_id=s2.stu_id join course c on s2.course_id=c.course_id
) t;
2.49 查询每门课程成绩最好的前两名学生姓名及成绩
窗口函数排名+多表连接+条件
select course_name,stu_name,grade,rk
from (
select
stu_name,
course_name,
grade,
rank() over(partition by course_name order by grade desc) as rk
from (
select s1.stu_name,c.course_name,s2.grade from student s1 join score s2 on s1.stu_id=s2.stu_id join course c on s2.course_id=c.course_id
) t
) t2 where rk<=2;
2.50 查询所有课程的成绩第2名到第3名的学生信息及该课程成绩
select *
from (
select
t1.*,
rank() over(partition by course_name order by grade desc) as rk
from (
select s1.*,c.course_name,s2.grade from student s1 join score s2 on s1.stu_id=s2.stu_id join course c on s2.course_id=c.course_id
) t1
) t2 where rk=2 or rk=3;
2.51 查询各科成绩前三名的记录(如果有并列,则全部展示,例如如果前7名为:80,80,80,79,79,77,75,70,则统计结果为数字的前三名,结果为80,80,80,79,79,77)
--DENSE_RANK() 排序相同时会重复,总数会减少
select *
from (
select
s2.stu_id,
s2.stu_name,
c.course_name,
s1.grade,
dense_rank() over(partition by c.course_name order by s1.grade desc) rk
from teacher t
join course c on t.tea_id=c.tea_id
join score s1 on c.course_id=s1.course_id
join student s2 on s1.stu_id=s2.stu_id
) temp where rk<=3;