Paper | CenterPoint
CenterPoint paper

文章目录
- CenterPoint paper
-
- 摘要
- Introduction
- Related Work
- CenterPoint
-
- Two-Stage CenterPoint
- Reference
论文链接:https://arxiv.org/pdf/2006.11275.pdf
代码链接:https://github.com/tianweiy/CenterPoint
摘要
该文章是Center-based系列工作(CenterNet、CenterTrack、CenterPoint)的扩展
CenterPoint 使用关键点检测器检测物体的中心,然后回归其他属性,包括3D尺寸,3D方向和速度。
在2阶段中,它使用物体上额外的点特征修正了预测值。
Introduction
这种解决方法为每个对象方向分类不同的模板(anchor),这样UI增加不必要的计算负担,并且会招来大批非正方向。

文章提出了1个基于中心的框架来表示、检测和跟踪目标。先前基于锚点的方法使用相对于自车坐标的轴对齐锚点。
当车辆在直线道路上行驶时,基于锚点的方法和基于中心的方法都能够准确地检测到物体。然而,在以安全至上的左转弯期间,基于锚点的方法难以将轴对称的边界框拟合到旋转的对象上。基于中心的模型能够通过旋转不变点准确地检测出障碍物。
2阶段的3D检测,CenterPoint, 使用关键点检测器找到障碍物中心点和特征,通过第2阶段修正所有预测。
第2阶段在预测的障碍物3D包围盒的每个面的3D中心点上提取了点特征。它恢复了由于步幅和有限的接受域而丢失的局部几何信息,并以较小的成本带来了可观的性能提升。
基于中心的表示有几个关键的优势:
- 与边界框不同,点没有内在的方向,这大大减少了目标检测器的搜索空间,同时允许主干学习对象的旋转不变性和相对旋转的旋转等变性。
- 基于中心的表示简化了跟踪等下游任务,不需要额外的运动模型,如Kalman滤波,跟踪时间可以忽略不计;
- 基于点的特征提取使我们能够设计一个有效的2阶段细化模块,比以前的方法快得多。本文通过第二阶段预测bbox的score来降低CenterPoint第一阶段中产生的错误预测,提升目标检测的质量,同时进一步提升了追踪的结果。
Related Work
2D目标检测从图像输入预测轴边边界框。
RCNN家族找到一个类别不可知论的边界框候选者,然后对其进行分类和改进。
YOLO、SSD和RetinaNet直接找到一个特定类别的候选框,避免了后来的分类和细化。
基于中心的检测器,例如CenterNet或CenterTrack,直接检测隐式对象中心点,而不需要候选框。
许多3D物体探测器都是从这些2D物体探测器发展而来的。我们认为,与轴对齐相比,基于中心的表示更适合3D应用
3D目标检测的目的是预测3D旋转的边界框。
它们不同于输入编码器上的二维检测器。
Vote3Deep利用以特征为中心的投票,在等间隔的3D体素上有效地处理稀疏的3D点云。
VoxelNet在每个体素内使用PointNet来生成统一的特征表示,其中具有3D稀疏卷积和2D卷积的头部产生检测。
SECOND简化了VoxelNet并加速了稀疏的3D卷积。
PIXOR将所有点投影到具有3D占用率和点强度信息的2D特征图上
CenterPoint
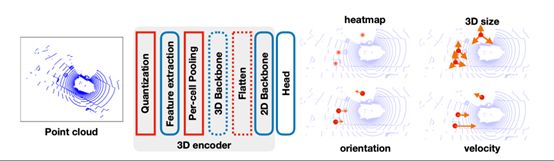
1-stage: CenterPoint的第1阶段预测类特定的热图、对象大小、子体素位置细化、旋转和速度。所有的输出都是密集的预测。
在地图视图中,车辆占用的区域很小,但在图像视图中,几个大物体可能占据了大部分屏幕
我们通过扩大在每个地面真值对象中心呈现的高斯峰值来增加对目标热图Y的正监督
CenterPoint依赖于一个标准的3D骨干,从激光雷达点云中提取地图视图特征表示.
2D CNN架构检测头找到对象中心,并使用中心特征回归到完整的3D边界框
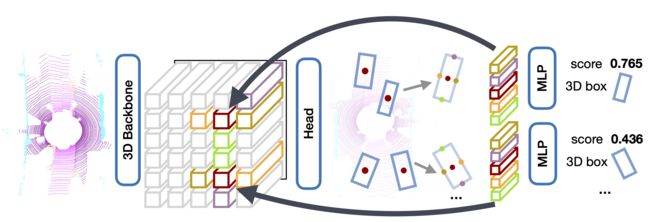
该box预测用于在估计的3D边界盒的每个面的3D中心提取点特征,并将其传递到MLP中以预测iou引导的置信度评分和盒回归细化。
回归到对数大小,以便更好地处理各种形状的盒子。
在推理时,我们通过索引到每个对象峰值位置的密集回归头输出来提取所有属性。
通过应用负速度估计将当前帧中的目标中心投影回前一帧,然后通过最接近距离匹配将其与跟踪对象进行匹配
网络的3D encoder部分使用了现有的网络模型,CenterPoint提供了两种主干网实现方式,分别为VoxelNet 和PointPillar。
Two-Stage CenterPoint
边界框中心,顶部和底部的面中心都投射到地图视图中的同一点
2-stage: 第2阶段设计了一个refinement模块,在CenterPoint的一阶段预测结果的基础上预测类别不可知论的置信度分数(score)和盒优化(refinement)
对于类别不可知论置信度分数预测,我们遵循并使用由盒子的3D IoU和相应的地面真值边界框引导的分数目标:
I = min ( 1 , max ( 0 , 2 × I o U t − 0.5 ) ) I = \min (1, \max(0, 2 \times IoU_t - 0.5)) I=min(1,max(0,2×IoUt−0.5))
其中, I o U t IoU_t IoUt 是第t个可能框和真值框之间的IoU。
训练使用二元交叉熵损失来监督的:
L s c o r e = − I t log ( I ^ t ) − ( 1 − I t ) log ( 1 − I ^ t ) L_{score} = -I_t\log(\hat I_t) - (1-I_t)\log(1-\hat I_t) Lscore=−Itlog(I^t)−(1−It)log(1−I^t)
其中, I ^ t \hat I_t I^t 是预测可信值。
在预测中,使用从1阶段CenterPoint得来的预测类型,并计算最终的置信分数作为2个分数的几何平均值
Q ^ t = Y ^ t ∗ I ^ t \hat Q_t = \sqrt{\hat Y_t * \hat I_t} Q^t=Y^t∗I^t
其中, Q ^ t \hat Q_t Q^t 是障碍物t最终的预测置信度, Y ^ t = 、 m a x 0 ≤ k ≤ K Y ^ p , k \hat Y_t = 、max_{0 \leq k \leq K} \hat Y_{p,k} Y^t=、max0≤k≤KY^p,k, I ^ t \hat I_t I^t 分别是障碍物t在1阶段和2阶段的置信度
Y ^ t \hat Y_t Y^t 计算方式为第一阶段的目标检测框对应的热力图上值最大的一点
对于box回归,模型在第一阶段建议的基础上预测一个改进,我们用L1损失来训练模型
Reference
- CVPR2021|CenterPoint :基于点云数据的3D目标检测与跟踪(代码已开源)