参数估计(点估计和区间估计)
参数估计(点估计和区间估计)
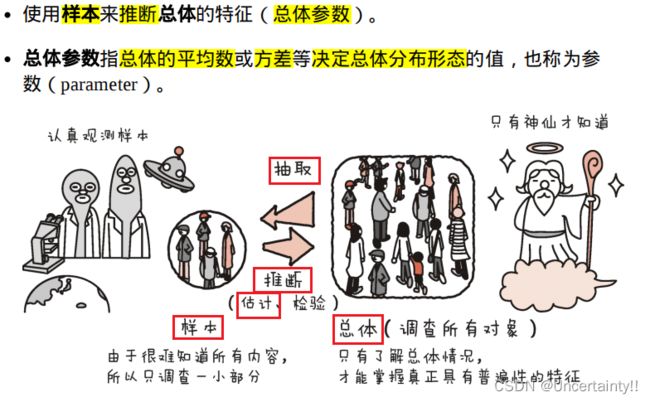
1.1 点估计
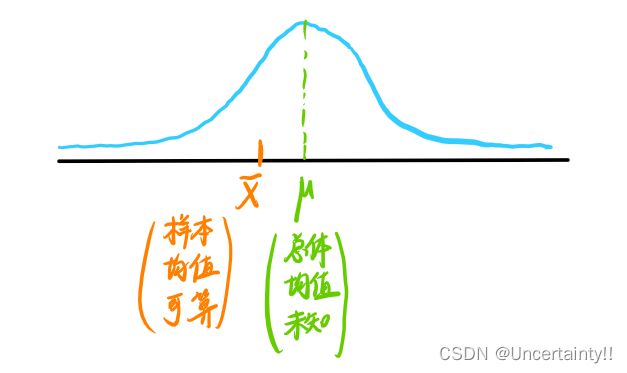
点估计的理解示意图
下图中样本均值就是对总体均值的点估计
1.1.1 矩估计
关于什么是矩?可以参考马同学。传送门:如何理解概率论中的“矩”?
根据大数定律,样本矩会依概率收敛于总体矩,故可以用样本矩替代总体矩,从而完成对总体参数的点估计
X ˉ = 1 n ∑ i = 1 n X i → P E X A 2 = 1 n ∑ i = 1 n X i 2 → P E X 2 B 2 = 1 n ∑ i = 1 n ( X i − X ˉ ) 2 → P D X \bar{X}=\frac{1}{n}\sum_{i=1}^{n}X_i \xrightarrow{P} EX\\ ~\\ A_2=\frac{1}{n}\sum_{i=1}^{n}X_i^2 \xrightarrow{P} EX^2\\ ~\\ B_2=\frac{1}{n}\sum_{i=1}^{n}(X_i-\bar{X})^2 \xrightarrow{P} DX Xˉ=n1i=1∑nXiPEX A2=n1i=1∑nXi2PEX2 B2=n1i=1∑n(Xi−Xˉ)2PDX
1.1.2 最大似然估计(MLE)
关于什么是似然?之前笔者大概了解了一下,但并不深入。传送门:区分概率与似然
似然函数 L ( θ ) L(\theta) L(θ)指的是样本( X n X_n Xn)取到观测值( x n x_n xn)的概率
离散型
L ( θ ) = P { X 1 = x 1 , X 2 = x 2 , ⋯ , X n = x n } = 独立 P { X 1 = x 1 } P { X 2 = x 2 } ⋯ P { X n = x n } \begin{align*} L(\theta)&=P\{X_1=x_1,X_2=x_2,\cdots,X_n=x_n\} \\ &\overset{\text{独立}}{=}P\{X_1=x_1\} P\{X_2=x_2\} \cdots P\{X_n=x_n\}\\ \end{align*} L(θ)=P{X1=x1,X2=x2,⋯,Xn=xn}=独立P{X1=x1}P{X2=x2}⋯P{Xn=xn}
连续型(样本落在观测值邻域内的概率)
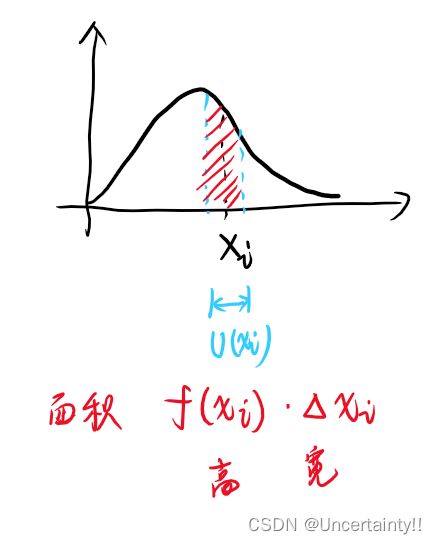
L ( θ ) = P { X 1 ∈ U ( x 1 ) , X 2 ∈ U ( x 2 ) , ⋯ , X n ∈ U ( x n ) } = f ( x 1 , θ ) Δ x 1 ⋅ f ( x 2 , θ ) Δ x 2 ⋯ f ( x n , θ ) Δ x n = f ( x 1 , θ ) f ( x 2 , θ ) ⋯ f ( x n , θ ) ⋅ Δ x 1 Δ x 2 ⋯ Δ x n Δ x 1 Δ x 2 ⋯ Δ x n 与 θ 无关,丢弃 L ( θ ) = f ( x 1 , θ ) f ( x 2 , θ ) ⋯ f ( x n , θ ) \begin{align*} L(\theta)&=P\{X_1\in U(x_1),X_2\in U(x_2),\cdots,X_n\in U(x_n)\}\\ &=f(x_1,\theta)\Delta x_1\cdot f(x_2,\theta)\Delta x_2\cdots f(x_n,\theta)\Delta x_n\\ &=f(x_1,\theta)f(x_2,\theta)\cdots f(x_n,\theta)\cdot\Delta x_1\Delta x_2\cdots\Delta x_n\\ &\Delta x_1\Delta x_2\cdots\Delta x_n\text{与}\theta无关,丢弃\\ L(\theta)&=f(x_1,\theta)f(x_2,\theta)\cdots f(x_n,\theta) \end{align*} L(θ)L(θ)=P{X1∈U(x1),X2∈U(x2),⋯,Xn∈U(xn)}=f(x1,θ)Δx1⋅f(x2,θ)Δx2⋯f(xn,θ)Δxn=f(x1,θ)f(x2,θ)⋯f(xn,θ)⋅Δx1Δx2⋯ΔxnΔx1Δx2⋯Δxn与θ无关,丢弃=f(x1,θ)f(x2,θ)⋯f(xn,θ)
最大似然的思想:概率越大的事情频率越高
引例:假设箱子内5个球,随机摸球10次,每次摸1个,摸后放回,共10次,若出现2黑8红,估计这个箱子中1黑4红,当然这个估计可能是错的,也可能是其他情况,但也不影响最大似然的正确性,只是说出现1黑4红这种情况的概率是最大的。
求最大似然步骤
在 θ \theta θ 的取值范围内找 θ ^ \hat{\theta} θ^ 使得 L ( θ ^ ) L(\hat{\theta}) L(θ^) 最大


1.1.3 估计量的评选标准
未知参数 θ \theta θ 的估计量 θ ^ \hat{\theta} θ^,判断这个估计量准不准有三个标准
无偏性
若 E ( θ ^ ) = θ E(\hat{\theta})=\theta E(θ^)=θ,则 θ ^ \hat{\theta} θ^ 是 θ \theta θ 的无偏估计量
未知参数的无偏估计量不唯一
无论何种总体,都有以下结论

注意:
若 θ ^ \hat{\theta} θ^ 是 θ \theta θ 的无偏估计量,则 g ( θ ^ ) g(\hat{\theta}) g(θ^) 未必是 g ( θ ) g(\theta) g(θ) 的无偏估计

有效性
θ 1 ^ 、 θ 2 ^ \hat{\theta_1}、\hat{\theta_2} θ1^、θ2^均为 θ \theta θ 的无偏估计(有效性的前提是要有无偏性),若 D ( θ 1 ^ ) ≤ D ( θ 2 ^ ) D(\hat{\theta_1})\leq D(\hat{\theta_2}) D(θ1^)≤D(θ2^),则称 θ 1 ^ \hat{\theta_1} θ1^ 比 θ 2 ^ \hat{\theta_2} θ2^ 更有效
一致性
若 θ ^ → P θ \hat{\theta}\overset{P}{\rightarrow}\theta θ^→Pθ(依概率收敛)则称 θ ^ \hat{\theta} θ^ 是 θ \theta θ 的一致估计量
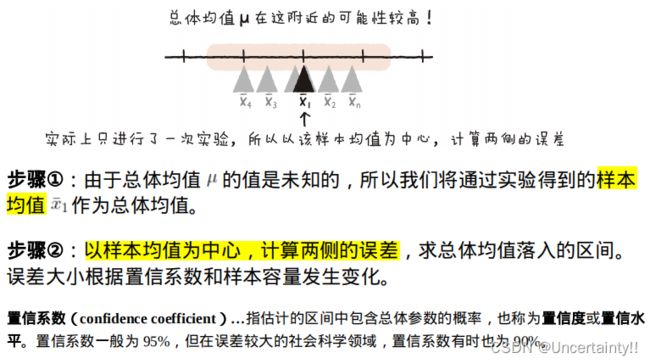
1.2 区间估计
区间估计:估计总体参数的范围
区间估计的大致步骤:
置信区间 ( θ 1 ^ , θ 2 ^ ) (\hat{\theta_1},\hat{\theta_2}) (θ1^,θ2^)
置信下限: θ 1 ^ \hat{\theta_1} θ1^、置信上限: θ 2 ^ \hat{\theta_2} θ2^
置信度/置信水平: 1 − α 1-\alpha 1−α
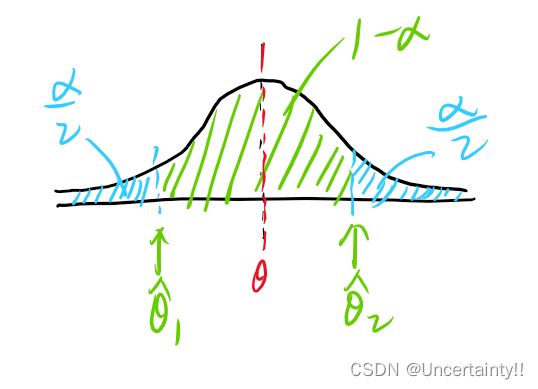
总体X含未知参数 θ \theta θ, X 1 , X 2 , ⋯ , X n X_1,X_2,\cdots,X_n X1,X2,⋯,Xn是来自总体X的样本,对于给定的 α \alpha α(值很小, 0 < α < 1 0<\alpha<1 0<α<1),若有两个统计量满足:
P { θ 1 ^ < θ < θ 2 ^ } = 1 − α P\{\hat{\theta_1}<\theta<\hat{\theta_2}\}=1-\alpha P{θ1^<θ<θ2^}=1−α
随机区间包含总体参数的可信度为 1 − α 1-\alpha 1−α
下图来自《统计学图鉴》

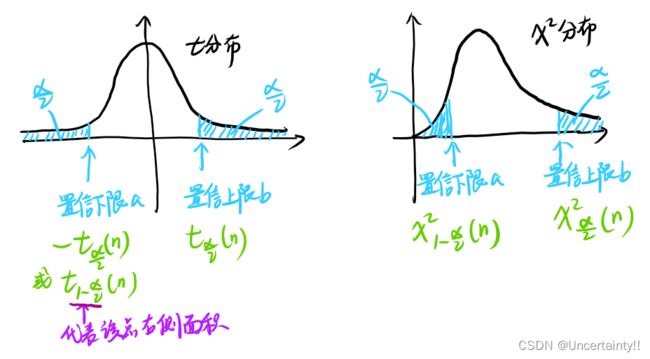
求置信区间的方法

选取置信下限a和置信上限b的原则

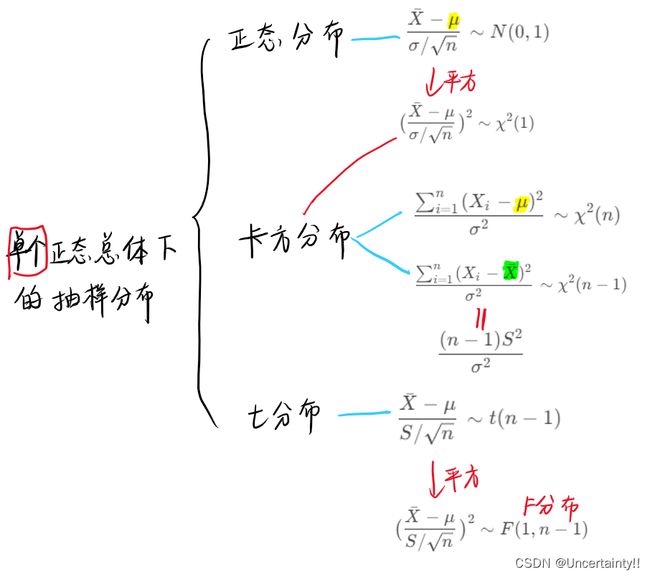
正态总体下参数 μ 、 σ 2 \mu、\sigma^2 μ、σ2 的置信区间
常见样本统计量服从的分布详见本人博客:正态总体下常见的抽样分布
在 σ 2 \sigma^2 σ2已知或未知情况下求 μ \mu μ
(1) σ 2 \sigma^2 σ2已知时, μ \mu μ的置信度为 1 − α 1-\alpha 1−α的置信区间为:
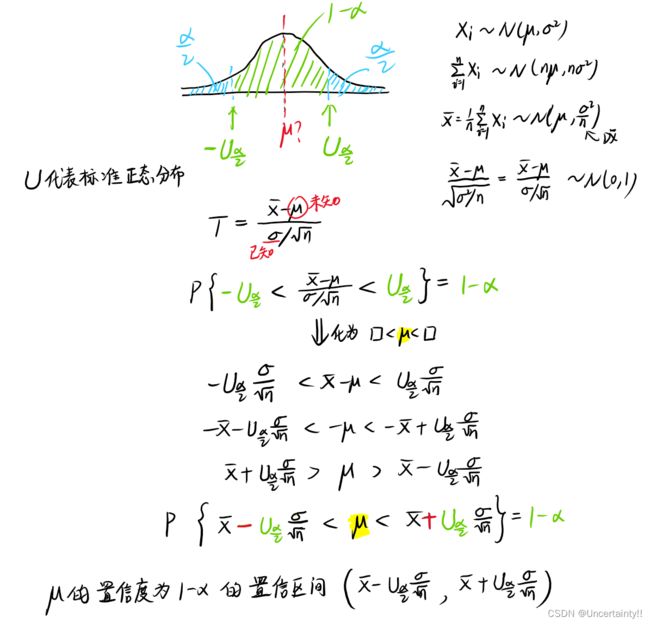
标准正态分布中当 α = 0.5 \alpha=0.5 α=0.5 时, α / 2 = 0.025 \alpha/2=0.025 α/2=0.025, U α / 2 = 1.96 U_{\alpha/2}=1.96 Uα/2=1.96

(2) σ 2 \sigma^2 σ2未知时, μ \mu μ的置信度为 1 − α 1-\alpha 1−α的置信区间为:

在 μ \mu μ已知或未知情况下求 σ 2 \sigma^2 σ2
(1) μ \mu μ已知时,求 σ 2 \sigma^2 σ2的置信度为 1 − α 1-\alpha 1−α的置信区间为:
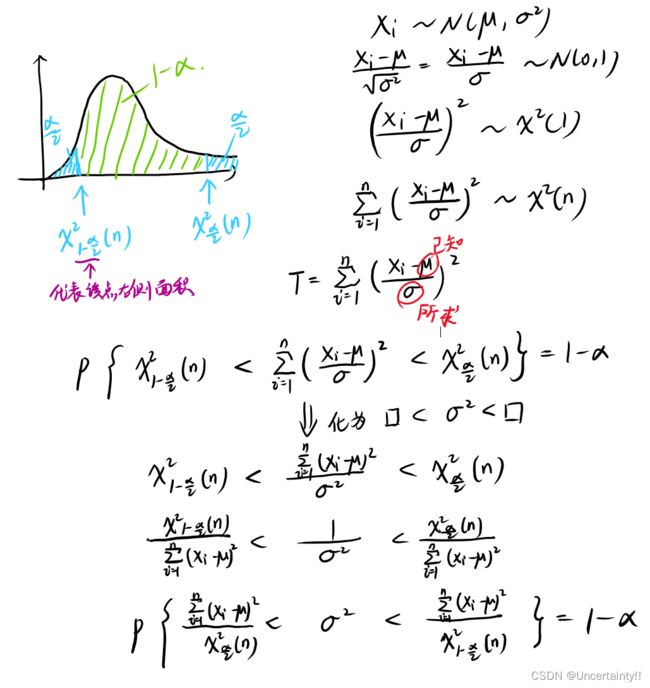
(2) μ \mu μ未知时,求 σ 2 \sigma^2 σ2的置信度为 1 − α 1-\alpha 1−α的置信区间为:
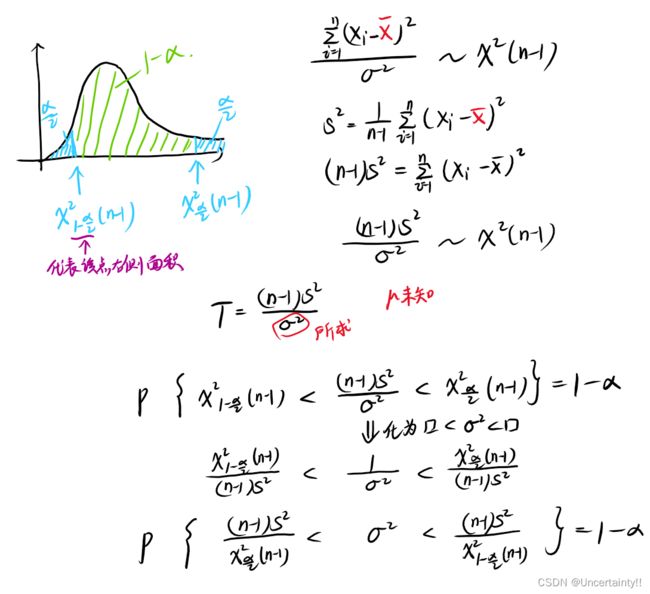
小结:各种情况下,统计量的选取
