Lecture 17 Machine Translation
目录
-
-
- Statistical MT
- Neural MT
- Attention Mechanism
- Evaluation
- Conclusion
-
Machine translation (MT) is the task of translating text from one source language to another target language 
- why?
- Removes language barrier
- Makes information in any languages accessible to anyone
- But translation is a classic “AI-hard” challenge
- Difficult to preserve the meaning and the fluency of the text after translation
- MT is difficult
- Not just simple word for word translation
- Structural changes, e.g., syntax and semantics
- Multiple word translations, idioms(习语,成语,方言)
- Inflections for gender, case etc
- Missing information (e.g., determiners)

Statistical MT
- earliy MT
- Started in early 1950s
- Motivated by the Cold War to translate Russian to English
- Rule-based system
- Use bilingual dictionary to map Russian words to English words
- Goal: translate 1-2 million words an hour within 5 years
- statistical MT
-
Given French sentence f, aim is to find the best English sentence e
- a r g m a x e P ( e ∣ f ) argmax_eP(e|f) argmaxeP(e∣f)
-
Use Baye’s rule to decompose into two components
- a r g m a x e P ( f ∣ e ) P ( e ) argmax_e\color{blue}{P(f|e)}\color{red}{P(e)} argmaxeP(f∣e)P(e)
-
language vs translation model
- a r g m a x e P ( f ∣ e ) P ( e ) argmax_e\color{blue}{P(f|e)}\color{red}{P(e)} argmaxeP(f∣e)P(e)
- P ( e ) \color{red}{P(e)} P(e): language model
- learn how to write fluent English text
- P ( f ∣ e ) \color{blue}{P(f|e)} P(f∣e): translation model
- learns how to translate words and phrases from English to French
-
how to learn LM and TM
- Language model:
- Text statistics in large monolingual(仅一种语言的) corpora (n-gram models)
- Translation model:
- Word co-occurrences in parallel corpora
- i.e. English-French sentence pairs
- Language model:
-
parallel corpora
- One text in multiple languages
- Produced by human translation
- Bible, news articles, legal transcripts, literature, subtitles
- Open parallel corpus: http://opus.nlpl.eu/
-
models of translation
- how to learn P ( f ∣ e ) P(f|e) P(f∣e) from paralell text?
- We only have sentence pairs; words are not aligned in the parallel text
- I.e. we don’t have word to word translation

-
alignment
-
Idea: introduce word alignment as a latent variable into the model
- P ( f , a ∣ e ) P(f,a|e) P(f,a∣e)
-
Use algorithms such as expectation maximisation (EM) to learn (e.g. GIZA++)

-
complexity
-
some words are dropped and have no alignment

-
One-to-many alignment
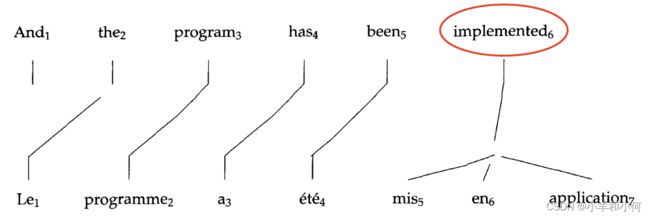
-
many-to-one alignment
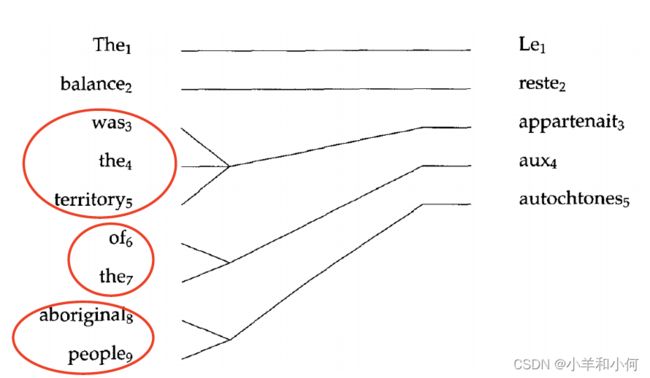
-
many-to-many alignment

-
-
-
summary
- A very popular field of research in NLP prior to 2010s
- Lots of feature engineering
- State-of-the-art systems are very complex
- Difficult to maintain
- Significant effort needed for new language pairs
-
Neural MT
-
introduction
- Neural machine translation is a new approach to do machine translation
- Use a single neural model to directly translate from source to target
- from model perspective, a lot simpler
- from achitecture perspective, easier to maintain
- Requires parallel text
- Architecture: encoder-decoder model
- 1st RNN to encode the source sentence
- 2nd RNN to decode the target sentence
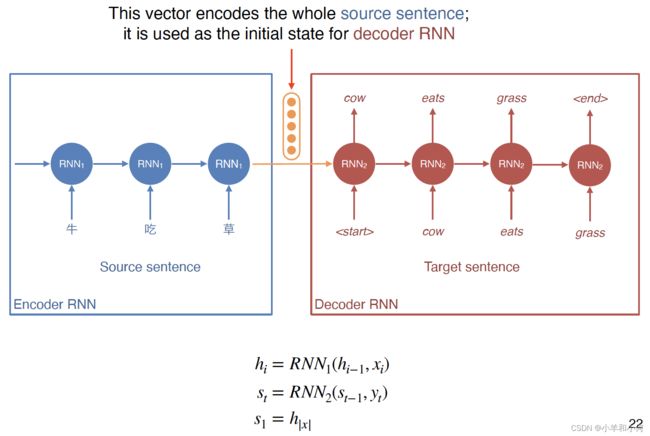
-
neural MT
-
The decoder RNN can be interpreted as a conditional language model
- Language model: predicts the next word given previous words in target sentence y
- Conditional: prediction is also conditioned on the source sentence x
-
P ( y ∣ x ) = P ( y 1 ∣ x ) P ( y 2 ∣ y 1 , x ) . . . P ( y t ∣ y 1 , . . . , y t − 1 , x ) P(y|x)=P(y_1|x)P(y_2|y_1,x)...P(y_t|\color{blue}{y_1,...,y_{t-1}},\color{red}{x}) P(y∣x)=P(y1∣x)P(y2∣y1,x)...P(yt∣y1,...,yt−1,x)
-
training
-
Requires parallel corpus just like statistical MT
-
Trains with next word prediction, just like a language model
-
loss

- During training, we have the target sentence
- We can therefore feed the right word from target sentence, one step at a time
-
-
decoding at test time

-
But at test time, we don’t have the target sentence (that’s what we’re trying to predict!)
-
argmax: take the word with the highest probability at every step
-
exposure bias
- Describes the discrepancy(差异) between training and testing
- Training: always have the ground truth tokens at each step
- Test: uses its own prediction at each step
- Outcome: model is unable to recover from its own error(error propagation)
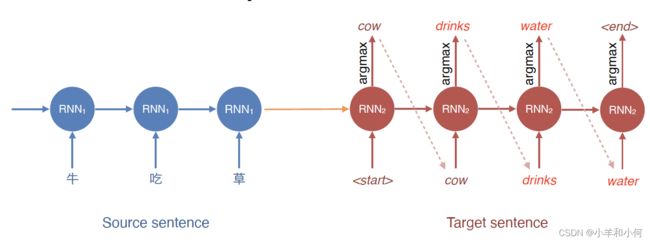
-
greedy decoding
- argmax decoding is also called greedy decoding
- Issue: does not guarantee optimal probability P ( y ∣ x ) P(y|x) P(y∣x)
-
exhaustive search decoding
- To find optimal P ( y ∣ x ) P(y|x) P(y∣x), we need to consider every word at every step to compute the probability of all possible sequences
- O ( V n ) O(V^n) O(Vn) where V = vocab size; n = sentence length
- Far too expensive to be feasible
-
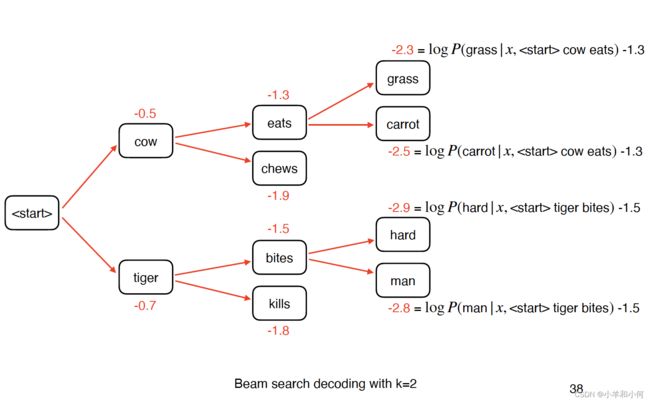
beam search decoding
- Instead of considering all possible words at every step, consider k best words
- That is, we keep track of the top-k words that produce the best partial translations (hypotheses) thus far
- k = beam width (typically 5 to 10)
- k = 1 = greedy decoding
- k = V = exhaustive search decoding
- example:







-
when to stop
- When decoding, we stop when we generate token
- But multiple hypotheses may terminate their sentence at different time steps
- We store hypotheses that have terminated, and continue explore those that haven’t
- Typically we also set a maximum sentence length that can be generated (e.g. 50 words)
-
-
issues of NMT
- Information of the whole source sentence is represented by a single vector
- NMT can generate new details not in source sentence
- NMT tend to generate not very fluent sentences ( × \times ×, usually fluent, a strength)
- Black-box model; difficult to explain when it doesn’t work
-
summary
- Single end-to-end model
- Statistical MT systems have multiple subcomponents
- Less feature engineering
- Can produce new details that are not in the source sentence (hallucination:错觉,幻觉)
- Single end-to-end model
-
Attention Mechanism
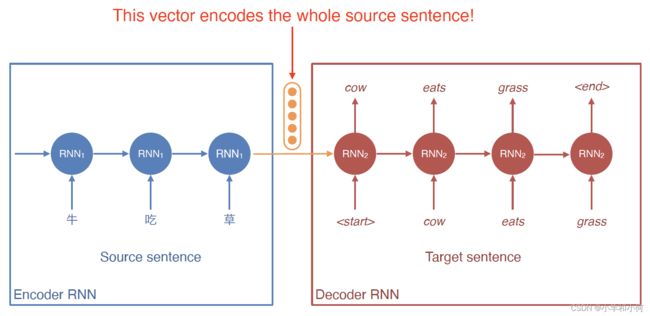
- With a long source sentence, the encoded vector is unlikely to capture all the information in the sentence
- This creates an information bottleneck(cannot capture all information in a long sentence in a single short vector)
- attention
-
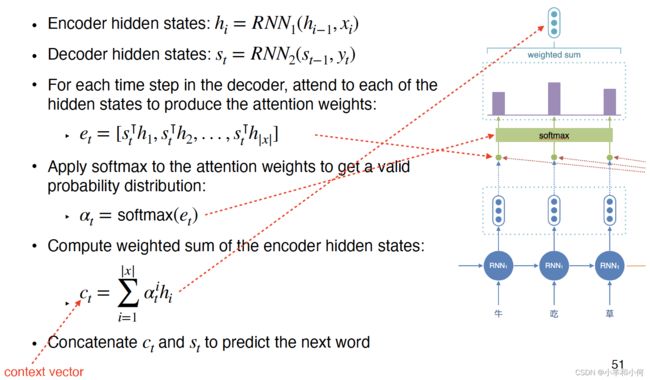
For the decoder, at every time step allow it to ‘attend’ to words in the source sentence




-
encoder-decoder with attention
-
variants
- attention
- dot product: s t T h i s_t^Th_i stThi
- bilinear: s t T W h i s_t^TWh_i stTWhi
- additive: v^Ttanh(W_ss_t+W_hh_i)
- c t c_t ct can be injected to the current state ( s t s_t st), or to the input word ( y t y_t yt)
- attention
-
summary
- Solves the information bottleneck issue by allowing decoder to have access to the source sentence words directly(reduce hallucination a bit, direct access to source words, less likely to generate new words not related to source sentence)
- Provides some form of interpretability (look at attention distribution to see what source word is attended to)
- Attention weights can be seen as word alignments
- Most state-of-the-art NMT systems use attention
- Google Translate (https://slator.com/technology/google-facebook-amazonneural-machine-translation-just-had-its-busiest-month-ever/)
-
Evaluation
- MT evaluation
- BLEU: compute n-gram overlap between “reference” translation(ground truth) and generated translation
- Typically computed for 1 to 4-gram
- B L E U = B P × e x p ( 1 N ∑ n N l o g p n ) BLEU=BP\times exp(\frac{1}{N}\sum_n^Nlogp_n) BLEU=BP×exp(N1∑nNlogpn), where BP → \to → “Brevity Penalty” to penalise short outputs
- p n = # c o r r e c t n − g r a m s # p r e d i c t e d n − g r a m s p_n=\frac{\# \ correct \ n-grams}{\# \ predicted \ n-grams} pn=# predicted n−grams# correct n−grams
- B P = m i n ( 1 , o u t p u t l e n g t h r e f e r e n c e l e n g t h ) BP=min(1,\frac{output \ length}{reference \ length}) BP=min(1,reference lengthoutput length)
Conclusion
- Statistical MT
- Neural MT
- Nowadays use Transformers rather than RNNs
- Encoder-decoder with attention architecture is a general architecture that can be used for other tasks
- Summarisation (lecture 21)
- Other generation tasks such as dialogue generation