无需借助文本训练来定制自己的生成模型
作者:GiantPandaCV
编辑:3D视觉开发者社区
该论文提出了一种称为 DeltaEdit 的方法,该方法以无文本的方式进行训练,可以很好地泛化到任何看不见的文本提示以进行零样本推理。
论文信息
标题:DeltaEdit: Exploring Text-free Training for Text-Driven Image Manipulation
作者:Yueming Lyu, Tianwei Lin, Fu Li, Dongliang He, Jing Dong, Tieniu Tan
原文链接:https://arxiv.org/abs/2303.06285
代码链接:https://github.com/Yueming6568/DeltaEdit
引言

如上图所示,Text-driven image manipulation的研究背景是,它是一种技术,允许用户使用自然语言文本提示来操作图像。这项技术的研究旨在解决图像编辑中的一些问题,例如需要专业知识和复杂的软件来编辑图像。这项技术可以使用户更轻松地编辑图像,并且可以通过简单的文本提示来实现操作。比较经典的方法有以下三个:
StyleCLIP:一种基于StyleGAN图像的文本驱动操作方法。
Predict, Prevent, and Evaluate (PPE):一种用于解耦文本驱动图像操作的新框架,适用于各种操作。
ManiGAN:一种文本引导的图像操作方法,旨在实现有效的图像操作,同时保留原始图像中与文本无关的内容。
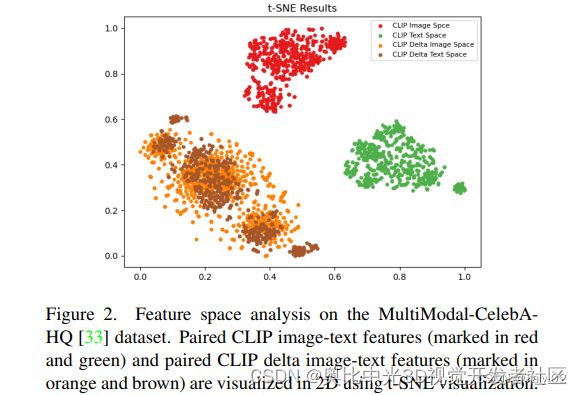
但是之前的这些方法都有一个缺陷:对于不同的text prompts,它们必须进行不同的优化过程,这在训练或推理过程中不灵活,并且不能很好地泛化到任何其他未见过的文本。通过上图的tSNE降维可以发现这一现象的原因。作者认为缓解这一问题的关键是在一个模型中精确地建立文本特征空间与 StyleGAN在latent space之间的关系。手动收集相关文本数据来训练一个模型是一种可能的方式 ,但它只能学习从属关系,所以只有有限的泛化能力。因此,探索如何在没有任何文本监督来限制泛化的情况下构建两个特征空间之间的完整映射具有挑战性但需要探索能力。
本文提出了一种在 StyleGAN空间中进行图像编辑的方法,该方法以 CLIP 图像空间中的相应embedding为条件,无需任何文本监督。该方法涉及从训练图像数据集中随机选择两幅图像,提取它们的 CLIP 的image embeddings和pre-trained StyleGAN 的模型以提取 S 空间中的latent codes。然后使用提取的latent codes来预测操作方向。该论文还提出了一种基于联合 CLIP 的图像-文本空间的对齐特性直接使用图像嵌入构造伪文本条件的解决方案。
方 法
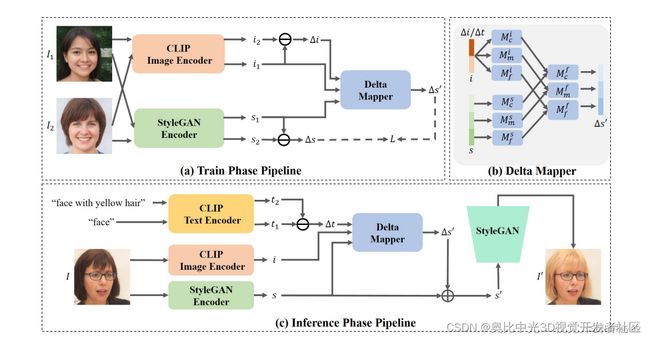
所提出的方法 DeltaEdit 基于 CLIP 图像空间中的相应嵌入来预测 StyleGAN S 空间中的编辑方向。该方法以无文本方式进行训练,可以很好地推广到任何看不见的文本提示以进行零样本推理。该方法的过程如下:
1、从训练数据集中随机选取两张图像,一张作为源图像,另一张作为目标图像。然后使用 CLIP 图像编码器将这些图像用于提取它们的 CLIP 图像的embeddings。CLIP 图像编码器是一种预训练的神经网络,可将图像映射到高维向量空间,在该空间中,相似图像彼此更接近。这一步很重要,因为它允许该方法理解图像的视觉内容及其彼此之间的关系。
2、CLIP 图像编码器用于提取它们的 CLIP 图像embeddings。从第一步获得的 CLIP 图像嵌入用于预测 StyleGAN S 空间中的操作方向。这是通过计算 CLIP embedding和 S 空间潜在代码之间的相关矩阵来完成的。然后使用相关矩阵来预测可以应用于源图像以生成目标图像的操作方向。
3、采用预训练的StyleGAN反演模型作为编码器,提取S空间中的latent codes。采用预训练的StyleGAN反演模型作为编码器,提取S空间中的隐码。这些潜在代码代表图像的底层结构,可以被操纵以生成新图像。然后使用提取的潜在代码来预测 S 空间中的操作方向,可以将其应用于源图像以生成目标图像。
4、采用提取的代码,该方法预测manipulation的方向。在训练期间,Delta Mapper 网络通过最小化两个损失来学习预测 delta 空间中的编辑方向:L2 距离重建损失和余弦相似性损失。L2 距离重建损失增加了学习编辑方向的监督,而余弦相似性损失鼓励网络最小化 S 空间中预测嵌入方向与实际编辑方向之间的余弦距离。在推理过程中,网络通过计算 S 空间中目标图像和源图像的latent codes之间的差异来预测 delta 空间中的编辑方向。这个预测的manipulation方向然后可以用来manipulation源图像的潜在代码以生成目标图像。
5、预测的manipulation方向用于manipulation源图像以生成目标图像。StyleGAN 中不同级别的子模块(coarse, medium, and fine) 通过允许在生成的图像中处理不同级别的细节,帮助在每个级别内实现从粗到精的操作。粗层次操纵图像的整体结构,而中层次操纵图像的特征,例如脸的形状或眼睛的大小。精细级别处理图像的细节,例如皮肤的纹理或头发的颜色。通过分别操纵每个级别,模型可以实现更精确和逼真的图像操纵。
实 验
论文使用两个数据集进行评估:FFHQ 数据集和 LSUN cat 数据集。

该论文提出了一种称为 DeltaEdit 的方法,该方法可以在单个模型中执行各种编辑,而无需训练许多独立模型或进行复杂的手动调整。它以无文本的方式进行训练,可以很好地泛化到任何看不见的文本提示以进行零样本推理。实验证明了所提出的方法在生成高质量结果、训练或推理阶段的效率以及对任何看不见的文本提示的泛化方面的优越性。
结 论
该论文提出了一种称为 DeltaEdit 的方法,该方法可以在单个模型中执行各种编辑,而无需训练许多独立模型或进行复杂的手动调整。它以无文本的方式进行训练,可以很好地泛化到任何看不见的文本提示以进行零样本推理。实验证明了所提出的方法在生成高质量结果、训练或推理阶段的效率以及对任何看不见的text prompts的泛化方面的优越性。
但是该论文有一些局限性,包括:
所提出的方法需要一个预训练的 StyleGAN 模型,由于其计算要求,可能不是每个人都可以访问。
该方法仅限于图像处理任务,可能不适用于其他领域。
论文没有对提出的方法的性能进行定量评估,这使得很难将其有效性与其他方法进行比较。
该方法可能不适用于涉及多个属性或需要对编辑过程进行细粒度控制的复杂图像操作。
对于未来的工作展望:
探索使用其他生成模型(例如 VAE 或 GAN 变体)来执行文本驱动的图像处理。
调查使用其他方式(例如音频或视频)来执行文本驱动的操作。
扩展所提出的方法以处理更复杂的图像操作,例如涉及多个属性或对编辑过程进行细粒度控制的操作。
定量评估所提出的方法并将其有效性与其他最先进的方法进行比较。
探索在其他应用中使用所提出的方法,例如图像合成或图像到图像的转换。
版权声明:本文为奥比中光3D视觉开发者社区特约作者授权原创发布,未经授权不得转载,本文仅做学术分享,版权归原作者所有,若涉及侵权内容请联系删文。
3D视觉开发者社区是由奥比中光给所有开发者打造的分享与交流平台,旨在将3D视觉技术开放给开发者。平台为开发者提供3D视觉领域免费课程、奥比中光独家资源与专业技术支持。
加入【3D视觉开发者社区】学习行业前沿知识,赋能开发者技能提升!
加入【3D视觉AI开放平台】体验AI算法能力,助力开发者视觉算法落地!
往期推荐:
1、奥比中光&英伟达第三届3D视觉创新应用竞赛圆满落幕!
2、 速来!2023第三届3D视觉创新应用竞赛决赛即将开启!
3、开发者社区「运营官」招募启动啦!_奥比中光3D视觉开发者社区的博客-CSDN博客
4、为什么你的手机后置摄像头越来越丑?ECCV2022这篇论文告诉你_奥比中光3D视觉开发者社区的博客-CSDN博客