【论文阅读】Group Emotion Detection Based on Social Robot Perception
【论文阅读】Group Emotion Detection Based on Social Robot Perception
- 摘要
- 1.介绍
- 2.相关工作
- 3.方法
- 4.数据集生成
- 5.模拟与结果
- 6.讨论
摘要
本篇博客参考MDPI sensors 2022收录的论文Group Emotion Detection Based on Social Robot Perception,对其主要内容进行总结,以便加深理解和记忆
1.介绍
社交机器人与视角:
社交机器人是一个新兴领域,社交机器人在这样的社交环境中提供服务、执行任务并与人互动,这就要求更高效、更复杂的人机交互(HRI)设计。提高HRI的一个策略是为机器人提供检测周围人情绪的能力,以规划轨迹,修改他们的行为,并根据分析的信息与人产生适当的互动。现有的研究主要集中在群体凝聚力的检测和群体情绪的识别上;然而,这些工作并没有从以机器人为中心的角度来关注执行识别任务。
社交机器人越来越多地被纳入人类空间,如博物馆、医院和餐馆,以提供服务、执行任务和与人互动。社交机器人被认为是具有在复杂社会环境中行动能力的物理代理[1]。它们必须模仿人类的社会认知能力,探索移情行为,并协助机器人与人类之间的互动[2,3],这反过来又需要更高效、更复杂的人机交互(HRI)设计。HRI必须包括行为适应技术、认知架构、有说服力的沟通策略和同理心[4]。
在一个群体中,人们可以表达不同的情绪,机器人必须处理每个人的情绪,并将其总结为群体情绪,以定义其行动。在这种情况下,有必要考虑机器人的第一人称视角。安装在机器人头部或底盘上的摄像头可以让机器人从第一人称视角观察世界。计算机视觉的这一研究领域被称为自我中心或第一人称视觉[11]。当社交机器人与不止一个人交互时,例如在学校、医院、餐馆和博物馆等社交环境中,这种做法非常有用。第一人称视角开发系统使机器人能够适应人类的社会群体[12]。然而,现有的大多数与群体情绪检测相关的研究都是基于第三人称摄像机的[17-21]。
2.相关工作
1)GER
①图像预处理:人脸、姿态、骨架、物品、场景
②特征提取
③融合方法与评价指标:加权融合、LSTM、注意力机制;平均绝对误差MAE、均方根误差RMSE、均方误差MSE、精度(最常用)
④比较评估(从人脸角度出发)

2)社交机器人的情感识别
在HRI的背景下,情绪识别已成为产生与人类共享空间的社交和服务机器人行为的重要策略。根据检测到的情绪,机器人可以改变自己的行为或导航,表现出社会接受的态度。
- [41]中提出的研究描述了232篇论文,重点关注情绪智力(即系统如何处理情绪、使用的算法、外部信息的使用以及基于过去信息的情绪改变)、情绪模型或模型的实现,从这三个角度展示了改善HRI的趋势和进展。
- 作者在[9]中提到了情绪识别对HRI的重要性。
- 机器人表达情感也是该领域关注的另一个方面,如[42]所示。该调查回顾了2000年至2020年的研究论文,重点研究了机器人人工情绪(刺激)的产生、人类对机器人人工情绪的识别(有机体)以及人类对机器人情绪的反应(反应),作为对机器人心理学领域的贡献。
这两项调查[41,42]中描述的这些工作表明,社交机器人是一个不断发展的领域,心理学和社会学各方面都在融合[8]。
- 个体情绪的估计也会影响社交机器人应该具有的代理行为。机器人和人之间的这种分离可能受到可达距离、用户舒适距离和用户情绪的限制。基于这些特征和机器人识别人的情绪或情绪状态的能力,机器人可以规划最佳路线[15,43,44]。
各种感官能力使机器人能够捕捉多种多媒体内容(例如,图像、视频、语音、文本),从中可以检测情绪。在这项工作中,许多研究都集中在从图像和视频中识别人脸情绪,以提高HRI或社交导航。
- [45]中介绍了2000年至2020年对101篇论文的调查,这些论文涉及人类面部情绪的检测和机器人面部表情的生成。作者比较了野生图像与对照场景中图像的面部情绪识别准确性,发现第一种情况的准确性远低于第二种情况。
为了提高从野外获取信息的准确性(如服务中的社交机器人),一种新兴的策略包括考虑多模式或多源方法。因此,一些工作已经开始采用多模式方法,将基于几种机器人传感器捕获的信息的几种模式相结合,例如:
- 从Kinect相机识别基于人类面部表情和步态的情绪,如[46]中所述的研究;
- 从相机和机器人的语音系统来看,一些研究结合面部和语音[47-53]以及身体手势和语音[5]来检测人类情绪,并相应地改善HRI或导航
- 从文本和语音中,通过将语音转换为文本,然后应用自然语言处理(NLP)来识别情绪,如[54]所述。
然而,正如[55]中的调查所报道的那样,机器人的这一主题仍然有限。
关于社交机器人中的群体情绪识别,只有少数研究涉及个体情绪的群体检测和识别。
- 对于社交机器人的导航,考虑了人或机器人本身的运动轨迹、位置或速度等参数,但没有考虑多人的情绪[12,56-58]。
- 有研究考虑了机器人在一群人中的影响[13,16,59],但没有进行群体情绪的检测,更没有进行环境情绪的检测。
很少有研究提出群体情绪估计的方法
- 在[60]中,基于贝叶斯网络的个人情绪识别,提出了一种从面部表情和韵律信息估计群体情绪的方法。
- 在[61]中,通过贝叶斯网络和个人面部表情识别,但结合环境条件(如光、温度),提出了一种估计群体情绪的方法,然后产生适当的刺激来诱导目标群体情绪。
- 在[62]中,根据个人面部表情,描述了一种用于识别娱乐机器人群体情绪的系统
- 在[63]中,对小组中的HRI进行了研究,得出的结论是,小组是复杂、适应性强和动态的系统。作者建议开发适合群体互动的机器人,并改进在涉及HRI的情况下测量人类和机器人行为的过程中使用的方法。
这些研究没有假装是详尽的综述,但揭示了一些局限性和挑战性
3.方法
首先,当机器人在室内空间中导航时,通过机器人的前置摄像头进行帧捕获。在每一帧中,所有的人脸都被Viola–Jones算法检测到,并存储在一个向量中。对于每个存储的人脸,计算人脸的面积,进行特征提取,并估计帧中每个人脸的个体情绪。然后,采用个体情感融合的方法确定框架情感;如果框架中只有一个人,那么框架的情感就是那个人的情感。
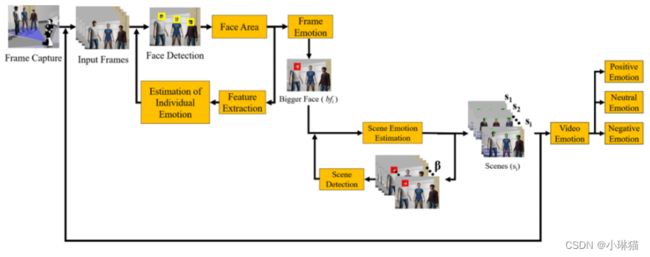
1)人脸检测
Viola-Jones分类器被用作人脸检测器,它存储每个人脸的左上角坐标(x, y)、宽度(w)和高度(h)。利用w和h的值,计算出每个人脸的面积(w * h),并将其信息用于场景检测。在这种情况下,当机器人向一群人移动时,机器人捕捉到的面部面积开始增加,当它离开时,面部面积开始减少。有了这些信息,确定场景的限制就建立起来了。
2)特征提取
使用了VGGFace神经网络,使用260万张图像进行预训练。图像特征向量在flatten层,在flatten层中,将卷积层得到的多维数据转换为一维数据。根据该神经网络的配置,输入图像的大小必须为224 × 224像素。
3)个人情绪估计
经过训练,VGGFace可以识别2622个类。然而,在这种情况下,没有2622种情绪可以分类;因此,修改了VGGFace模型的全连接层,如表2所示。层fc6和fc7有512个节点,层fc8有6个节点,分别表示待分类的情绪(快乐、悲伤、愤怒、恐惧、厌恶、惊讶)。此外,还增加了0.5的dropout,以减少神经网络(d1和d2层)的过拟合。一旦这个设置完成,只有VGGFace神经网络的完全连接层使用图像数据集进行训练。
4)在每个帧,场景和视频中的情感估计
惊讶被认为是一种中性情绪,因为它可以是积极的,也可以是消极的。

5)场景检测(场景情感)
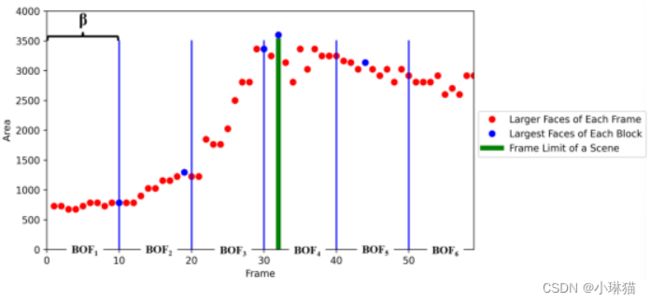
一组被检测到的场景的持续时间是由帧中被识别的人脸的面积决定的。当机器人接近或离开一群人时,面部的面积会相应地增加或减少。在这种方法中,机器人分析b帧来区分一个场景。图2中显示了一个示例,其中b = 10;每10帧符合一个BOF,机器人在属于该BOF的帧中提取最大的人脸(图2中的蓝点);由于BOF1, BOF2, BOF3和BOF4中最大的面面积不断增长,所有这些帧都属于第一个场景(直到BOF4中的第32帧;图2中的绿线);这是第一场景的终点;从那一帧直到BOF6结束属于第二场景。因此,一个场景是由机器人在接近一个群体时捕获的所有帧(增加面部面积)组成的,如果机器人看到远处的人脸(减少面部面积),则将其视为另一个场景。
4.数据集生成
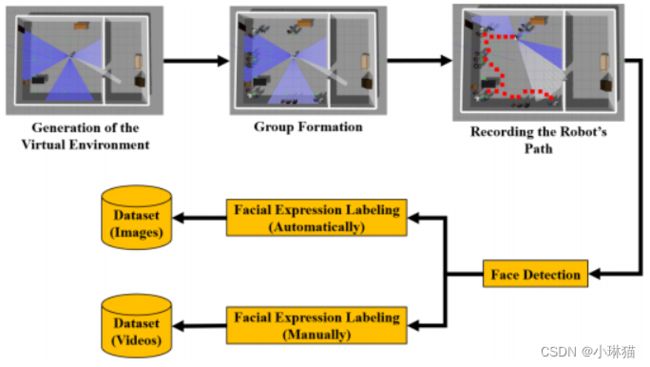
在ROS和Gazebo模拟的社交机器人Pepper的帮助下,我们创建了数据集Dataset-in-ROS,图像用于训练、视频用于场景检测
5.模拟与结果
1)模拟环境
2)IER
3)视频的情感(博物馆、自助餐厅)

4)在ROS/Gazebo中的仿真(Emoción de una Escena en ROS - YouTube)

6.讨论
1)通过对人群及其情绪的识别,提出了“场景情感”的概念。这一概念可以应用于与群体行为相关的情境中,例如,识别艺术品(在博物馆中)、演讲者(在会议中)、动物(在动物园中)或食物(在餐馆中)在一群人中产生的情感。
2)为什么机器人想要探测一群人的情绪呢?
一个明显的应用是设计机器人的行为,并改善人力资源指数,使它们更容易被社会接受。例如,如果机器人识别出群体中的消极情绪,它会离开以避免冲突或做出顺从的反应;相反,如果检测到的情绪是积极的,机器人可以接近并与小组交谈。
另一个应用例子是,机器人的任务是监控和记录参加课程、会议、音乐表演、博物馆等活动的一群人的情绪;这超越了识别一个群体的情感,而是为群体定义的场景的情感;这些信息不仅可以用来定义机器人的行为和提高人力资源指数,而且可以用于后期分析