一、深度学习引言
文章目录
- 一、机器学习中的关键组件
-
- 1. 数据
- 2. 模型
- 3. 目标函数
- 4. 算法
- 二、各种机器学习问题
-
- 1. 有监督学习
-
- 1.1 回归
- 1.2 分类
- 1.3 标记问题
- 1.4 搜索
- 1.5 推荐系统
- 1.6 序列学习
- 2. 无监督学习
- 3. 与环境互动
- 4. 强化学习
- 三、深度学习的发展
一、机器学习中的关键组件
1. 数据
数据的集合称为数据集,每个数据集由一个个的样本(sample,example)(或称为数据点(data point)/数据实例(data instance))组成,每个样本由一组特征(features,或协变量(covariates))属性组成.需要预测的属性称为标签(label 或目标(target)。
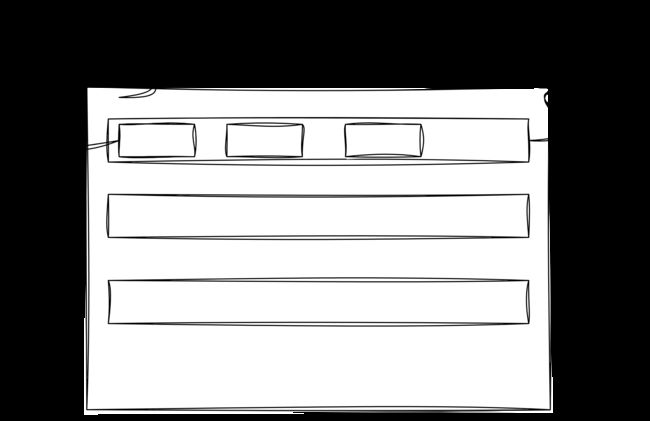
2. 模型
在深度学习中,模型是一种数学函数,它将输入数据映射到输出数据。这个函数通常由多个层组成,每一层都包含了一个或多个可训练参数。这些参数在训练过程中会被动态地调整,以最小化模型预测的输出与实际输出的差异(即损失函数)。深度学习中基本常见的有神经网络模型,它包括全连接神经网络、卷积神经网络、递归神经网络、对抗生成网络等。
3. 目标函数
目标函数 是用来评价模型优劣程度的一种度量,通常我们希望目标函数对应的值越小越好,因此目标函数也常称为损失函数(loss function)。
4. 算法
当我们获得了一些数据源及其表示、一个模型和一个合适的损失函数,接下来就需要一种算法,它能够搜索出最佳参数,以最小化损失函数。 深度学习中,大多流行的优化算法通常基于一种基本方法–梯度下降(gradient descent)。 简而言之,在每个步骤中,梯度下降法都会检查每个参数,看看如果仅对该参数进行少量变动,训练集损失会朝哪个方向移动。 然后,它在可以减少损失的方向上优化参数。
二、各种机器学习问题
1. 有监督学习
有监督学习的流程如下:

1.1 回归
回归问题指的是一类预测问题,其中我们试图使用一个函数模型来预测连续的输出变量,比如预测商品价格、股票价格、房屋价格等等。回归分析的目标是找到一个函数,使其能够在给定输入的情况下,准确地预测一个数值型输出。回归问题是利用历史数据中的特征(自变量)和对应的目标值(因变量)建立模型,并使用该模型对未来的数据进行预测。
在回归问题中,常用的模型包括线性回归、多项式回归、决策树回归、随机森林回归、支持向量回归、神经网络回归等。这些模型的目标是找到一个最佳拟合函数,使得输入特征与输出变量之间的关系最为精确的匹配。为了在未知数据上进行准确的预测,我们需要首先使用训练数据对模型进行训练,并对模型性能进行评估和优化,以提高模型的预测能力和泛化能力。
1.2 分类
分类问题是一类预测问题,其中我们试图将输入数据映射到一个有限的,预定义的离散类别。例如,根据邮件文本的内容,将邮件分类为垃圾邮件或非垃圾邮件,或者将患者的诊断结果归类为癌症和非癌症两类。分类问题是根据给定的输入,将其归类为预定义类别中的一种或几种。
在分类问题中,我们需要从训练数据中学习输入数据和标签(类别)之间的映射关系,并应用该经验来对新的输入数据进行预测。在机器学习中,常用的分类方法包括决策树、支持向量机、朴素贝叶斯、逻辑回归、人工神经网络等。
1.3 标记问题
标记问题也称为标注问题或者序列标注问题,指的是对序列(如自然语言文本)中的每个元素进行分类的问题。例如,在自然语言处理中,将句子中的每个单词标记为名词、动词、形容词或副词等等标记,就是一个标记问题。标记问题的目的是通过已有的标记样本学习一个模型,使其能够对未标记的样本进行自动标注。
在标记问题中,常用的算法包括隐**马尔可夫模型(HMM)、条件随机场(CRF)、循环神经网络(RNN)和转换器(Transformer)**等。这些算法通常采用一些统计模型或机器学习算法,利用输入数据构造特征,并针对构造好的特征进行分类。
1.4 搜索
搜索问题指的是在大规模的搜索空间中寻找最优解或最优决策的问题。例如,在棋类游戏中,在给定的初始局面下,通过搜索所有可能的走法,找到最优解即为一个搜索问题。搜索问题通常涉及到从大量可能的选择中,找到最优的选择,因此往往需要如启发式搜索等更加高效的算法来解决。
搜索问题可以用搜索算法来解决,常见的搜索算法包括广度优先搜索、深度优先搜索、A算法、最小代价搜索等等。在搜索算法中,通常采用一些启发式方法来帮助我们更加高效地搜索到最优解。例如,在A算法中,我们通过再每个搜索节点处估计从该节点到目标状态的距离,来指导搜索方向。
1.5 推荐系统
推荐系统的主要目标是根据用户的历史行为、兴趣和其他特征,为用户选择最能满足其需求的产品、服务或信息,从而提高用户体验和增加交易量。机器学习技术可以使推荐系统更加准确和个性化。
在推荐系统中,机器学习技术能够帮助我们从海量数据中挖掘有价值的信息,构建用户兴趣模型、商品属性模型、用户-商品关系模型等,并实现智能的推荐策略。常见的机器学习算法包括协同过滤、基于内容的过滤、深度学习、集成学习等等。这些算法能够有效地处理推荐系统中存在的冷启动问题、数据稀疏性、时效性等问题,并且可以根据用户的历史行为等数据源进行学习和预测,为用户提供更加准确的推荐结果。
1.6 序列学习
序列学习指的是机器学习中一种针对序列数据(如文本、语音、时间序列数据等)的学习方法,包括序列分类、序列标注、序列生成和序列到序列等任务。
序列分类是指对序列数据进行分类,例如将一段语音序列分类为特定的词语或将一段文本序列分类为情感类别。在序列分类中,输入是一个序列,输出是一个预测的标签或标签集合。
序列标注是指对序列中每个元素进行分类,例如标注音频文件中每个时刻对应的文本标签,或标注文本中每个单词的词性。在序列标注中,输入是一个序列,输出是一个序列标签序列。
序列生成是指给出一个输入序列,使得算法能够生成相应的输出序列,例如机器翻译、图像标注等。在序列生成中,输入是一个序列,输出也是一个序列。
序列到序列学习是指将一个序列映射为另一个序列的学习问题,例如机器翻译和语音合成任务。在序列到序列学习中,输入是一个序列,输出也是一个序列。
在序列学习中,常用的方法包括循环神经网络(RNN)、长短时记忆网络(LSTM)、双向RNN、注意力机制等。这些方法可以从序列数据中提取上下文信息,从而提高学习效果。序列学习在自然语言处理、语音识别、图像处理等领域都有着广泛的应用。
2. 无监督学习
无监督学习是针对没有十分具体的目标,需要自发去学习的任务。具有有:
-
聚类(clustering)问题:没有标签的情况下,我们是否能给数据分类呢?比如,给定一组照片,我们能把它们分成风景照片、狗、婴儿、猫和山峰的照片吗?同样,给定一组用户的网页浏览记录,我们能否将具有相似行为的用户聚类呢?
-
主成分分析(principal component analysis)问题:我们能否找到少量的参数来准确地捕捉数据的线性相关属性?比如,一个球的运动轨迹可以用球的速度、直径和质量来描述。再比如,裁缝们已经开发出了一小部分参数,这些参数相当准确地描述了人体的形状,以适应衣服的需要。另一个例子:在欧几里得空间中是否存在一种(任意结构的)对象的表示,使其符号属性能够很好地匹配?这可以用来描述实体及其关系,例如“罗马”
“意大利”
“法国”
“巴黎”。 -
因果关系(causality)和概率图模型(probabilistic graphical models)问题:我们能否描述观察到的许多数据的根本原因?例如,如果我们有关于房价、污染、犯罪、地理位置、教育和工资的人口统计数据,我们能否简单地根据经验数据发现它们之间的关系?
-
生成对抗性网络(generative adversarial networks):为我们提供一种合成数据的方法,甚至像图像和音频这样复杂的非结构化数据。潜在的统计机制是检查真实和虚假数据是否相同的测试,它是无监督学习的另一个重要而令人兴奋的领域。
3. 与环境互动
与环境互动是指机器学习系统通过与外部环境的交互来收集信息、学习并改进其行为的过程。换句话说,机器学习系统是在一个动态的、实时的环境中学习和演变,在这个过程中,其输出会随着输入和环境的变化而动态调整。
与环境互动的过程通常需要机器学习系统具备传感能力和执行能力。传感能力可以使机器学习系统感知环境变化,例如通过传感器或者摄像头来采集数据。执行能力则需要机器学习系统能够执行动作,例如通过机械臂或者执行器来对环境进行操作。
与环境互动是机器学习中的一个重要概念,在现实世界中的应用非常广泛,如机器人、自动驾驶、智能家居等领域都需要机器学习系统具备与环境互动的能力。
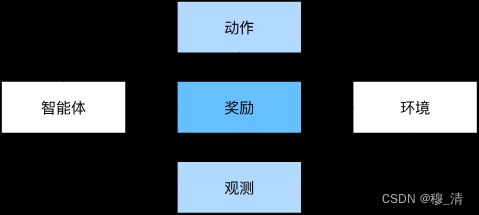
4. 强化学习
强化学习是一种人工智能算法,它可以通过与环境交互,学习如何做出最优决策以实现某个目标。在强化学习中,有一个智能体(agent)和一个环境(environment),智能体通过执行某些动作来影响环境,并获得相应的奖励或惩罚,智能体的目标是通过不断地与环境交互来学习如何做出最优决策,以最大化奖励并达到其目标。
强化学习与监督学习和无监督学习不同,它不依赖于标记好的数据或者先验知识。相反,它是一种通过与环境交互来学习的方法,经过多次试验,智能体可以改善策略,以取得更高的奖励。强化学习在多种应用领域如游戏、机器人、自然语言处理、推荐系统等都有很好的实现效果。
三、深度学习的发展
这里简单列举一下促进深度学习进步的一些案例。
-
新的容量控制方法,如dropout (Srivastava et al., 2014),有助于减轻过拟合的危险。这是通过在整个神经网络中应用噪声注入 (Bishop, 1995) 来实现的,出于训练目的,用随机变量来代替权重。
-
注意力机制解决了困扰统计学一个多世纪的问题:如何在不增加可学习参数的情况下增加系统的记忆和复杂性。研究人员通过使用只能被视为可学习的指针结构 (Bahdanau et al., 2014) 找到了一个优雅的解决方案。不需要记住整个文本序列(例如用于固定维度表示中的机器翻译),所有需要存储的都是指向翻译过程的中间状态的指针。这大大提高了长序列的准确性,因为模型在开始生成新序列之前不再需要记住整个序列。
-
多阶段设计。例如,存储器网络 (Sukhbaatar et al., 2015) 和神经编程器-解释器 (Reed and De Freitas, 2015)。它们允许统计建模者描述用于推理的迭代方法。这些工具允许重复修改深度神经网络的内部状态,从而执行推理链中的后续步骤,类似于处理器如何修改用于计算的存储器。
-
另一个关键的发展是生成对抗网络 (Goodfellow et al., 2014) 的发明。传统模型中,密度估计和生成模型的统计方法侧重于找到合适的概率分布(通常是近似的)和抽样算法。因此,这些算法在很大程度上受到统计模型固有灵活性的限制。生成式对抗性网络的关键创新是用具有可微参数的任意算法代替采样器。然后对这些数据进行调整,使得鉴别器(实际上是一个双样本测试)不能区分假数据和真实数据。通过使用任意算法生成数据的能力,它为各种技术打开了密度估计的大门。驰骋的斑马 (Zhu et al., 2017) 和假名人脸 (Karras et al., 2017) 的例子都证明了这一进展。即使是业余的涂鸦者也可以根据描述场景布局的草图生成照片级真实图像( (Park et al., 2019) )。
-
在许多情况下,单个GPU不足以处理可用于训练的大量数据。在过去的十年中,构建并行和分布式训练算法的能力有了显著提高。设计可伸缩算法的关键挑战之一是深度学习优化的主力——随机梯度下降,它依赖于相对较小的小批量数据来处理。同时,小批量限制了GPU的效率。因此,在1024个GPU上进行训练,例如每批32个图像的小批量大小相当于总计约32000个图像的小批量。最近的工作,首先是由 (Li, 2017) 完成的,随后是 (You et al., 2017) 和 (Jia et al., 2018) ,将观察大小提高到64000个,将ResNet-50模型在ImageNet数据集上的训练时间减少到不到7分钟。作为比较——最初的训练时间是按天为单位的。
-
并行计算的能力也对强化学习的进步做出了相当关键的贡献。这导致了计算机在围棋、雅达里游戏、星际争霸和物理模拟(例如,使用MuJoCo)中实现超人性能的重大进步。有关如何在AlphaGo中实现这一点的说明,请参见如 (Silver et al., 2016) 。简而言之,如果有大量的(状态、动作、奖励)三元组可用,即只要有可能尝试很多东西来了解它们之间的关系,强化学习就会发挥最好的作用。仿真提供了这样一条途径。
-
深度学习框架在传播思想方面发挥了至关重要的作用。允许轻松建模的第一代框架包括Caffe、Torch和Theano。许多开创性的论文都是用这些工具写的。到目前为止,它们已经被TensorFlow(通常通过其高级API Keras使用)、CNTK、Caffe 2和Apache MXNet所取代。第三代工具,即用于深度学习的命令式工具,可以说是由Chainer率先推出的,它使用类似于Python NumPy的语法来描述模型。这个想法被PyTorch、MXNet的Gluon API和Jax都采纳了。