姓名:张庆庆
学号:19021211151
嵌牛导读:机器学习计算机视觉的发展以及监督学习,神经网络的基本原理
嵌牛鼻子:计算机视觉 监督学习 神经网络
嵌牛提问:什么是计算机视觉,神经网络及监督学习的基本理论有哪些
转载源:ImageNet冠军领队带你入门计算机视觉:监督学习与神经网络的简单实现 -
原作者 | 董健,原编辑 | Vincent
嵌牛正文:
AI 前线导语:近几年,人工智能的浪潮席卷了整个科技圈。Google,Facebook,微软,百度等全球最顶尖的科技公司都将目光转向了人工智能,并将之视为今后的战略重心。 随着人脸识别,辅助驾驶,AlphaGo 等应用的不断涌现,基于学习的计算机视觉(learning based vision)正在越来越多的改变我们的生活 。本系列文章,将逐步介绍这些看似神奇的系统背后的视觉算法原理。
本文是整个系列的第一篇文章,将会简单介绍一下计算机视觉的发展,以及监督学习、神经网络的基本原理。最后的实践部分,会用 TensorFlow 给出之前介绍算法的一个简单实现。
计算机视觉的发展
什么是计算机视觉? 首先我们看一下维基百科的定义:
Computer vision is an interdisciplinary field that deals with how computers can be made for gaining high-level understanding from digital images or videos.
简单来说,计算机视觉就是让机器能自动的理解图片或视频。
计算机视觉的起源可以追溯到 1966 年,当时 MIT 著名的工智能专家 Marvin Minsky 给他的本科学生留了一个暑期作业 -“Link a camera to a computer and get the computer to describe what it saw”。 虽然人可以很容易的理解图片,但事实证明,让计算机理解图片远比我们一开始想象的复杂。
早期的计算机视觉研究,由于计算资源和数据的原因,主要集中在几何和推理。 上世纪 90 年代,由于计算机硬件的不断发展和数字照相机的逐渐普及,计算机视觉进入了快速发展期。 这期间的一大突破是各种人工设计特征的涌现,例如 SIFT,HOG 等局部特征。 这些特征相对原始像素具有对尺度,旋转等的鲁棒性,因此得到了广泛的应用,催生了如图像拼接、图像检索、三位重建等视觉应用。 另一大突破是基于统计和机器学习的方法的流行。随着数字照片的不断普及,大规模的数据集也相伴而生,基于学习的计算机视觉(Learning based Vision),由于可以通过大量数据自动学习模型参数,渐渐的成为了主流。
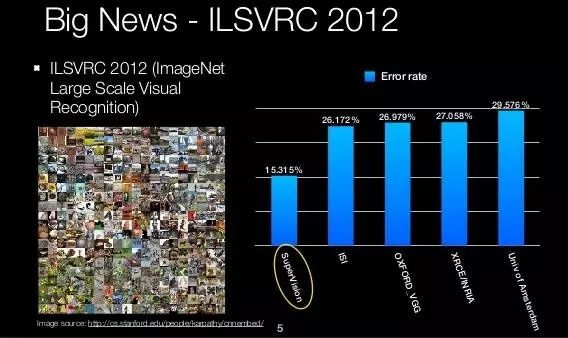
随着计算能力的不断进步和海量互联网数据的产生,传统的基于人工特征和 SVM/boosting 等简单机器学习算法的视觉技术遇到了瓶颈。因此,工业界和学术界都在探索如何避免繁琐的人工特征设计同时加强模型的拟合性能,从而进一步利用海量数据。深度学习很好的满足了这一需求,因此在视觉领域得到了非常广泛的应用。2010 年之后,计算机视觉逐渐进入了深度学习的时代。标志性的事件是 ImageNet 2012 比赛。这次比赛中,基于深度学习的算法大大超过了经过精心设计的传统算法,震惊了整个学术界,进而带动了深度学习在其他领域中的应用。这次比赛也被看成是深度学习在整个人工智能领域复兴的标志性事件。
目前,除了三维重建等 low-level vision 问题,基于深度学习的算法,在大多数视觉问题上的性能已经远远超过了传统算法,因此本系列文章会重点介绍基于深度学习的计算机视觉算法。
神经网络 (neural network)
神经网络(NN),简单来说就是神经元组成的网络,是最早出现,也是最简单的一种深度学习模型。其他很多更复杂的算法比如卷积神经网络,深度增强学习中的许多概念都来源于神经网络。因此,我们在这篇文章中先介绍一下神经网络的原理。 要理解神经网络,我们需要先了解什么是神经元。
神经元 & 感知器
神经元(neuron)是神经网络的最小单位。每个神经元将多个入映射到一个输出。如图所示,神经元的输出是输入的加权和加上偏置,再通过一个激活函数。具体可以表示成:

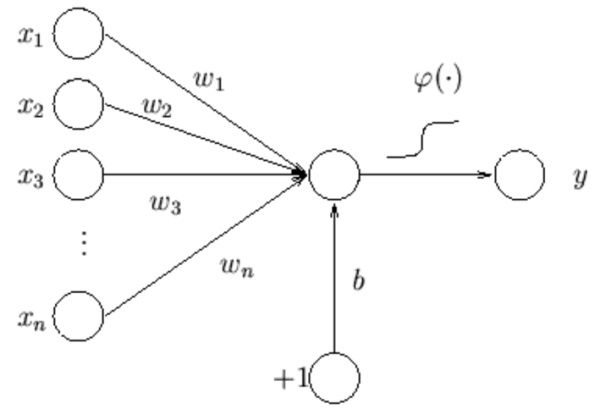
激活函数 φ 有各种不同的形式。如果使用 step 函数,那神经元等价于一个线性分类器:
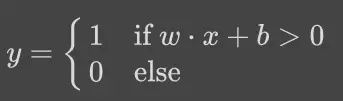
这个分类器在历史上被称为感知器(Perceptron)。
多层神经网络
单层的感知器只能解决线性可分的问题。但实际中绝大多数问题都是非线性的,这时单层感知器就无能为力了。 为此,我们可以把单个的 neuron 组成网络,让前一层 neuron 的输出做为下一层 neuron 的输入。组成如下图所示的神经网络:
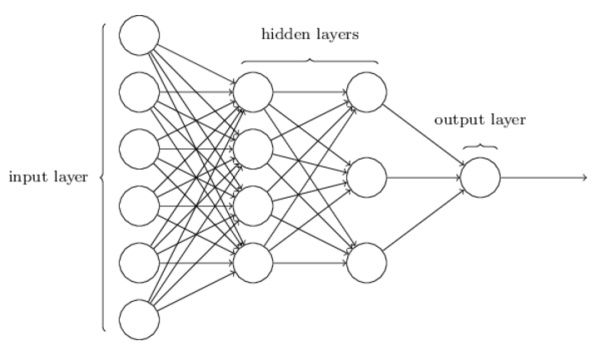
由于非线性激活函数的存在,多层神经网络就有了拟合非线性函数的能力。由于历史的原因,多层神经网络也被称为 multilayer perceptrons(MLP)。
神经网络具有拟合非线性函数的能力。但是为了拟合不同的非线性函数,我们是否需要设计不同的非线性激活函数和网络结构呢?
答案是不需要。
universal approximation theorem已经证明,前向神经网络是一个通用的近似框架。 简单来说,对常用的 sigmoid,relu 等激活函数,即使只有一层隐藏层的神经网络,只要有足够多的神经元,就可以无限逼近任何连续函数。在实际中,浅层神经网络要逼近复杂非线性函数需要的神经元可能会过多,从而提升了学习的难度并影响泛化性能。因此,我们往往通过使用更深的模型,从而减少所需神经元的数量,提升网络的泛化能力。
机器学习的基本概念
深度神经网络是深度学习中的一类算法,而深度学习是机器学习的一种特例。因此,这一节我们在机器学习的一般框架下,介绍模型训练相关的基本概念,及其在 Tensorflow 中的实现。相关概念适用于包括 NN 在内的机器学习算法。
机器学习的常见问题
常见的机器学习问题,可以抽象为 4 大类问题:
1、监督学习
2、非监督学习
3、半监督学习
4、增强学习
根据训练数据是否有 label,可以将问题分为监督学习(所有数据都有 label),半监督学习(部分数据有 label)和非监督学习(所有数据都没有 label)。 增强学习不同于前 3 种问题,增强学习也会对行为给出反馈(reward),但关注的是如何在环境中采取一系列行为,从而获得最大的累积回报。监督学习是目前应用最广泛,也是研究最充分的机器学习问题,本文接下来将重点介绍监督学习。
监督学习
在监督学习中,给定 N 个训练样本

我们的目标是得到一个从输入到输出的函数:

实际中,我们通常不会直接优化函数 f,而是根据问题的具体情况,选择一组参数化的函数 fθ, 将优化函数 f 转换成优化参数θ。
常见的分类问题和回归问题,都是监督学习的一种特例。线性分类器,深度神经网络等模型,都是为了解决这些问题设计的参数化后的函数。为了简单,我们以线性分类器
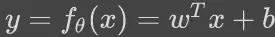
为例,需要优化的参数θ为 (w,b)。
损失函数
为了衡量函数的好坏,我们需要一个客观的标准。 在监督学习中,这个评判标准通常是一个损失函数
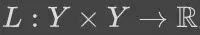
对一个训练样本
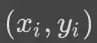
模型的预测结果为 y^,那对应的损失为
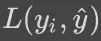
损失越小,表明函数预测的结果越准确。实际中,需要根据问题的特点,选择不同的损失函数。
二分类问题中,常用的 logistic regression 采用 sigmoid + cross entroy 作为 loss。对常见的 loss,tensorflow 都提供了相应的函数。
loss = tf.nn.sigmoid_cross_entropy_with_logits(labels=labels, logits=y)
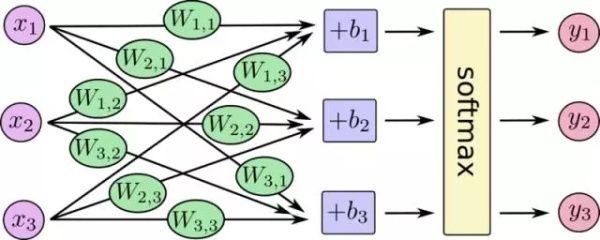
对多分类问题,如上图所示,我们可以将二分类的线性分类器进行扩展为 N 个线性方程:

然后通过
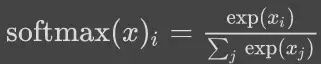
进行归一化,归一化后的结果作为每一类的概率。因此,多分类通常使用 softmax + cross entropy 作为损失函数。
loss = tf.nn.softmax_cross_entropy_with_logits(
labels=labels, logits=logits)
可以证明,对于二分类问题,采用 sigmoid cross entroy 和 softmax cross entory 作为 loss,在理论上是完全等价的。此外,实际中通常采用直接计算 softmax cross entropy 而不是先计算 softmax,后计算 cross entory,这主要是从数值稳定性的角度考虑的。
损失最小化和正则项
在定义了损失函数之后,监督学习问题可以转化为最小化实验损失
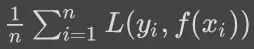
实际中,为了保证模型的拟合能力,函数 $f$ 的复杂度有时会比较高。如最图中最右边情况所示,如果训练样本数较少或者 label 有错误时,直接最小化实验损失而不对 $f$ 加限制的话,模型容易过拟合。
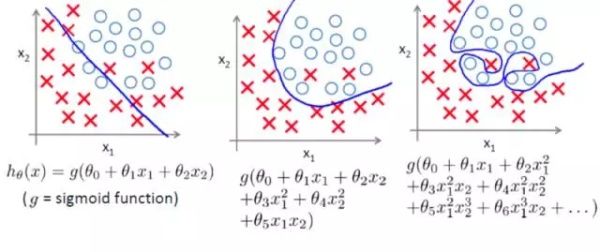
因此,在样本数量较少或者标注质量不高的情况下,需要额外添加正则项(regularizer),保证模型的泛化能力。实际中根据不同需求,可以选择不同的正则项。在神经网络当中,比较常见的是 l2 norm 正则项:
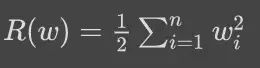
在 tensorflow 中,通常有两种方法添加正则项。一种是根据需要,自己实现相应的 regularization loss,然后和其他 loss 相加进行优化。这种方法可以实现比较复杂的 regularizer。
weight_decay = tf.multiply(tf.nn.l2_loss(weights),
wd, name='weight_loss')
对于常见的正则项,也可以使用 tensorflow 自带的功能,对相应的变量进行正则化。然后将系统生成的所有 regularization loss 和其他 loss 相加进行优化。
tf.contrib.layers.apply_regularization(
tf.contrib.layers.l2_regularizer(wd), weights)
tf.losses.get_regularization_losses()
梯度下降和反向传播
在定义了损失函数和正则项之后,最终正则化后的 loss 为:

有了 loss 函数,相应的参数可以通过标准的梯度下降算法进行优化求解。例如对线性分类器中的 $w$,可以通过如下的公式进行迭代更新:

通过设定合适的 learning rate,参数会逐步收敛到局部 / 全局最优解。
反向传播可以看成梯度下降在神经网络中的一个推广,也是通过最小化 loss 函数,计算参数相对于 loss 的梯度,然后对参数进行迭代更新。具体的推导因为篇幅原因在这里略过了。在 tensorflow 中,只需要指定 loss 函数和步长(learning rate),optimizer 可以自动帮我们完成梯度下降 / 反向传播的过程:
tf.train.GradientDescentOptimizer(
learning_rate).minimize(loss)
OCR 实战
最后本文通过一个 OCR 的例子,展示如何用 Tensorflow 实现 Softmax 分类器和 MLP 分类器。实验数据集采用著名的数字识别数据集 MNIST。该数据集包含了 60000 张训练图片和 10000 张测试图片。数据集中的每一张图片都代表了 0-9 中的一个数字,图片的尺寸为 28×28。

Softmax 分类器
我们首先实现一个简单的 Softmax 分类器。由于 Tensorflow 运行构建好的网络的过程比较复杂,为了提高开发效率和代码的复用性,我们将代码分成了 3 个主要模块,分别是 Dataset 模块,Net 模块和 Solver 模块。
模型结构
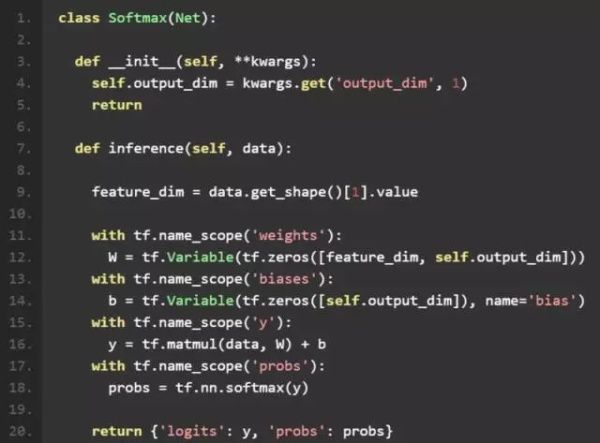
对每一个 Net 类里,我们需要实现三个函数:
1、inference
我们在 inference 函数中定义网络的主体结构。在 tensorflow 中,变量用 tf.Variable 表示。因为 Softmax 分类器是一个凸函数,任何初始化都可以保证达到全局最优解,因此我们可以简单的将W和b初始化为 0。 Softmax 分类器可以简单的通过一个矩阵乘法y = tf.matmul(data, W) + b后接一个tf.nn.softmax函数实现。
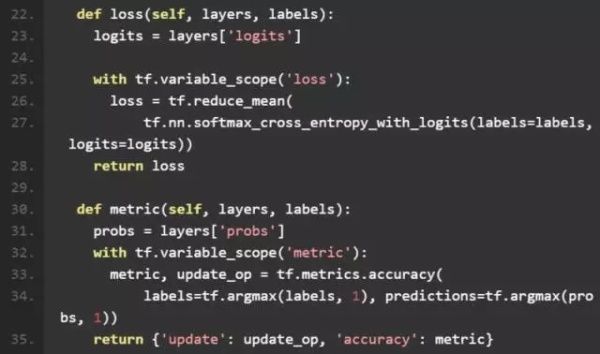
2、loss
按照之前介绍的,为了保证数值稳定性,我们直接采用直接计算tf.nn.softmax_cross_entropy_with_logits的方式。
3、metric
在训练完模型后,我们需要在 validation 或 test 集合上验证模型的性能。在测试集比较大时,我们无法一次得到模型在整个测试集上的结果,需要将测试集分成小的 batch,在每个 batch 上进行测试,之后将每个 batch 的结果汇总起来。 为此,tensorflow 提供了 tf.metrics 模块,可以自动完成对每个 batch 进行评价,并将所有的评价汇总的功能。在这个例子里,我们是解决分类问题,因此可以使用tf.metrics.accuracy计算分类的准确率。
Dataset
In versions of TensorFlow before 1.2, we recommended using multi-threaded, queue-based input pipelines for performance. Beginning with TensorFlow 1.2, however, we recommend using the tf.contrib.data module instead.
从 Tensorflow1.2 开始,Tensorflow 提供了基于 tf.contrib.data 的新 API。相比原来基于 QuequRunner 和 Coordinator 的 API,代码结构简洁了很多。所以我们在 Dataset 类中采用了新的 API,实现数据读取。
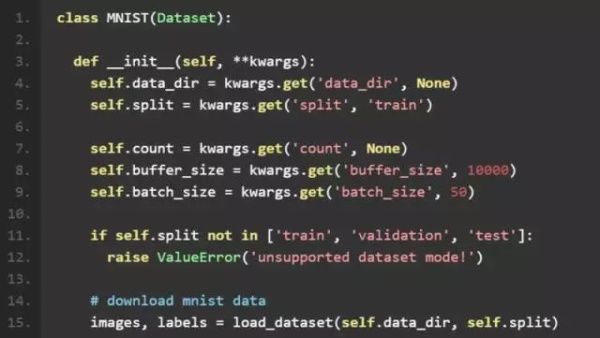
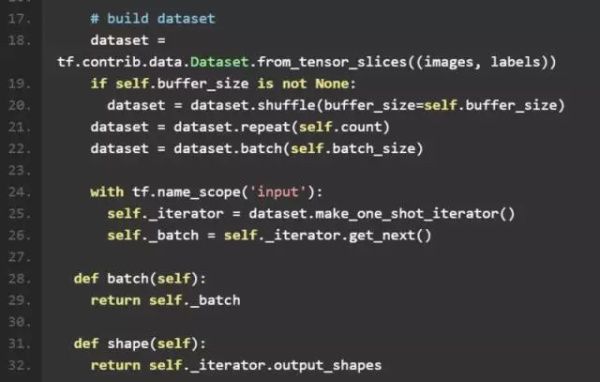
我们首先读取了 numpy.array 格式的 mnist 数据集images, labels。然后通过tf.contrib.data.Dataset.from_tensor_slices将之转换成 tf.contrib.data.Dataset 格式。之后我们可以设置对 Dataset 的遍历次数(None 代表无限次),batch size 以及是否对数据集进行 shuffle。 最后,我们采用最简单的make_one_shot_iterator()和get_next(),得到网络的基本数据单元 batch。 按默认配置,每个 batch 含有 50 张图和其对应的 label。
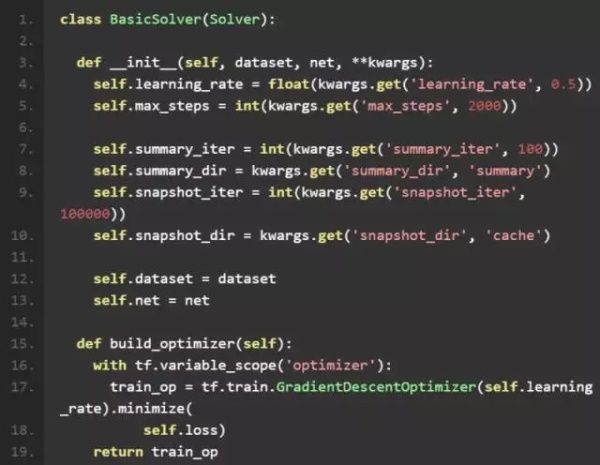
Solver
最后我们介绍 Sover 类。Solver 类主要包含五个函数:
1、build_optimizer
因为网络比较简单,这里我们选用最基本的随即梯度下降算法tf.train.GradientDescentOptimizer,并使用了固定的 learning rate。
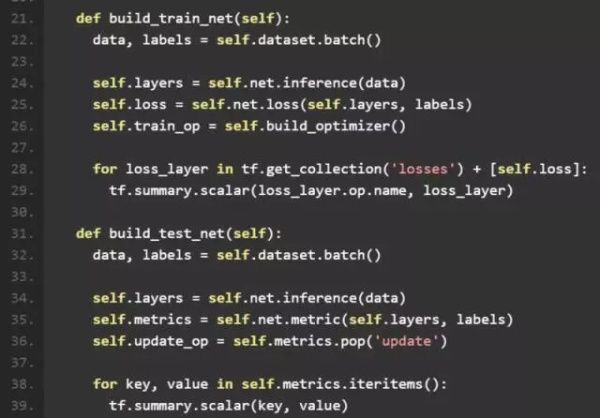
2、build_train_net、build_test_net
这两个函数的作用类似,都是将 Dataset 中的数据和 Net 中的网络结构串联起来。在最后我们调用tf.summary.scalar将 loss 添加到 summary 中。 tensorflow 提供了强大的可视化模块 tensorboard,可以很方便的对 summary 中的变量进行可视化。
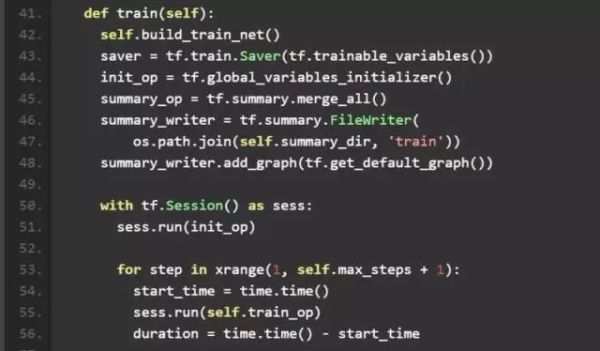
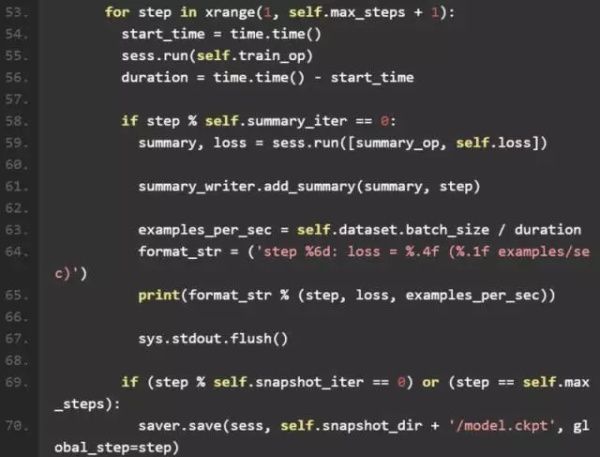
3、train_net
在 train_net 的开头,我们完成了 Graph,Saver,summary 等模块的初始化。 然后通过summary_writer.add_graph(tf.get_default_graph()),将网络结构打印到 summary 中。
之后初始化tf.Session(),并通过session.run运行对应的操作。在 tensorflow 使用了符号式编程的模式,创建 Graph 的过程只是完成了构图,并没有对数据进行实际运算。在 Session 中运行对应的操作时,才真正对底层数据进行操作。
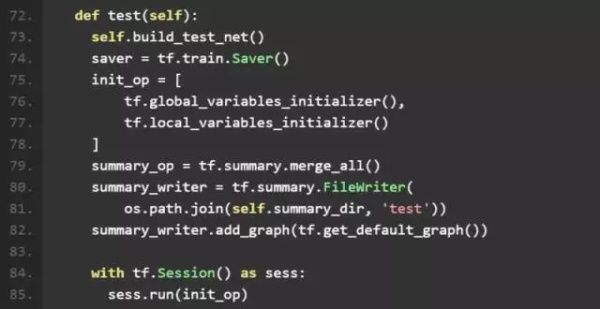
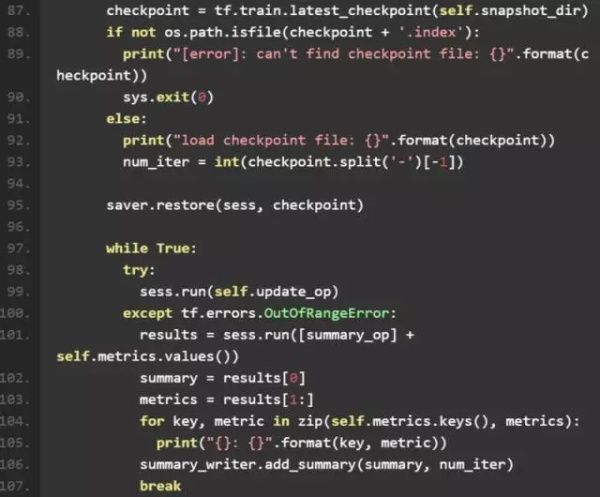
4、test_net
和 train_net 类似,test_net 主要完成了各种模块的初始化,之后读取模型目录文件下的 checkpoint 文件中记录的最新的模型,并在测试集中进行测试。
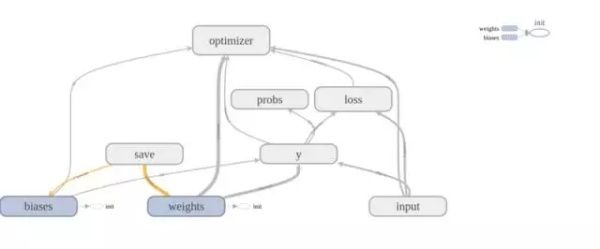
下图是 tensorboad 中可视化的网络结构,和 loss 的统计。可以看到,tensorboad 对我们进行分析提供很好的可视化支持。
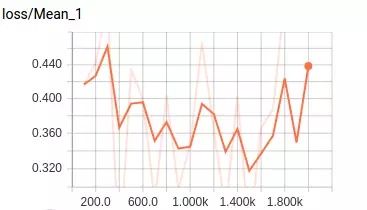
最终程序的输出结果如下:
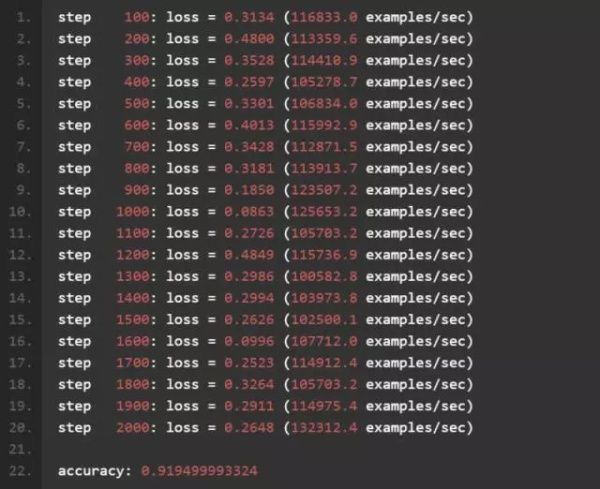
可以看到,一个简单的线性模型可以达到 92% 的准确率。我们猜测数字识别这个问题应该不是线性可分,因此使用更复杂的非线性分类器应该可以得到更好的结果。
MLP 分类器
由于我们采用了模块化的设计,各个模块直接基本是解耦合的。因此将 Softmax 分类器替换成 MLP 非常容易,我们只需要重新实现 Net 层就可以了。
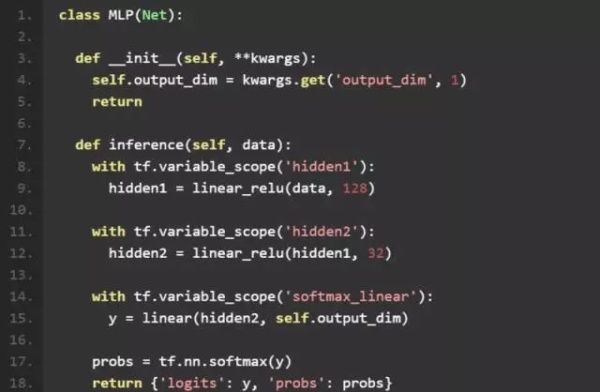

为了证明 MLP 的效果,我们构造了一个含有 2 层 hidden layer 的神经网络。代码结构和 Softmax 分类其大致一样,就不做过多解释了。 因为线性层在网络中多次出现,我们将他抽象为一个可以复用的函数。 另外,为了让 graph 在 tensorboad 中的可视化效果更好,我们将相关的变量和操作,通过with tf.variable_scope('hidden1'):放置在同一个 variable_scope 下面。这样所有相关变量和操作在 tensorboad 都会收缩成一个可以展开的节点,从而提供更好的可视化效果。
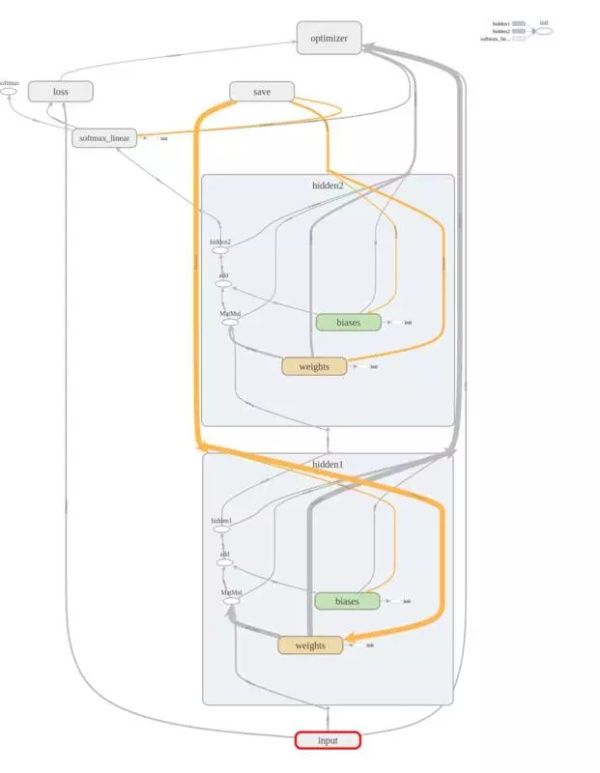
最终的网络结果和运行结果如下所示:

可以看到,使用了包含 2 层 hidden layer 的简单神经网络,分类的准确率已经提升到了 97%,大大优于简单的线性分类器。证明了模型选择对最终性能的重要影响。
完整代码下载:
https://github.com/Dong--Jian/Vision-Tutorial
嵌牛总结:本文重点介绍了计算机视觉的基本概念,以及神经网络,监督学习的基本理论,希望对学习深度学习的你有所帮助。