记录一次使用LSTM神经网络进行量化交易预测
除了工作之外的业余时间,就喜欢倒腾,最近在查阅研习 lstm 的原理并用于个人爱好实战中,确实给了我意想不到的效果,不同于普通股票金融类的走势预测。我个人是偏好于日内的高频量化交易,喜欢做剥皮交易。以下是从特征工程 建模到实际预测的一些过程,希望能帮助喜欢使用个人技能做交易的同志。
LSTM(Long Short-Term Memory)是一种特殊类型的RNN(循环神经网络),它可以学习并记忆长时间序列中的模式。这使得LSTM非常适用于处理和预测时间序列数据,例如股票价格、气候变化等,这是我在调研中看到的并记住的一句话,我不需要预测股票价格,我只想通过我实盘交易的经验来建立特征,并作为训练数据,特种数据如下
| time | date | open | high | low | close | vol | closeTime | cje | bs | but | sell | ignore | MACD | Signal | MACD_Hist | ATR | RSI | signal |
| 1685286000000 | 2023/5/29 15:00 | 27178.2 | 27192.6 | 27160.5 | 27181.1 | 617.012 | 1.68529E+12 | 16767705.34 | 7122 | 260.335 | 7075342.392 | 0 | -1.68944469 | 2.744520225 | -4.433964915 | 21.52501302 | 43.72573251 | 0 |
| 1685286300000 | 2023/5/29 15:05 | 27181 | 27211.6 | 27181 | 27211.5 | 541.796 | 1.68529E+12 | 14736747.64 | 6284 | 393.492 | 10702600.3 | 0 | 2.421776713 | 2.679971522 | -0.258194809 | 22.17322637 | 53.56081878 | 0 |
| 1685286600000 | 2023/5/29 15:10 | 27211.6 | 27220 | 27201.7 | 27214.8 | 713.495 | 1.68529E+12 | 19416938.44 | 7631 | 388.018 | 10559593.13 | 0 | 5.017486769 | 3.147474572 | 1.870012197 | 21.89656734 | 54.49062875 | 0 |
在最后一列signal 的处理为macd 的金钗和死叉常识理论计算的进场和出场信号 -1 做空 0 空仓 1 做多,其他列做为特征数据输入训练 ,其中包含后期的预处理atr rsi macd 数据,signal 列做为 label 达到预期效果。构思为 输入当前k线时时收盘价格和数据,使用已训练的模型给出操作信号,这样结合自动化程序对接crypto coin 实现自动化的量化交易。
众所周知,在处理数据和做自动化 python 是首选语言,不接受反驳(手动狗头),所以结合talib 扩展,让这一切变得简单快速,例如预处理数据仅仅需要这么几行代码
在使用LSTM进行量化交易预测之前,首先需要对数据进行预处理。首先读取并清洗数据,移除无关特征和缺失值。然后将“signal”列(这是我的预期结果)转换为整数类型,并将数据划分为训练集和测试集。
macd, macd_signal, macd_hist = talib.MACD(df['close'], fastperiod=5, slowperiod=10, signalperiod=9) df['MACD'] = macd df['Signal'] = macd_signal df['MACD_Hist'] = macd_hist df['ATR'] = talib.ATR(df['high'], df['low'], df['close']) df['RSI'] = talib.RSI(df['close'])
bindex = 0
sindex = 0
result['signal'] = 0
for index,value in enumerate(data):
if result['sell_signal'][index] == 1:
if bindex > 0 and sindex < bindex:
if float(data[index][4]) - float(data[bindex][4]) > 50:
print("做空:%f" % float(data[index][4]) - float(data[bindex][4]))
result.loc[bindex,'signal'] = 1
if sindex < bindex and sindex != 0 or sindex == 0:
sindex = index
if result['buy_signal'][index] == 1:
if sindex > 0 and sindex > bindex:
if float(data[sindex][4]) - float(data[index][4]) > 50:
print("做多:%s" % str(float(data[sindex][4]) - float(data[index][4])))
result.loc[sindex,'signal'] = -1
if bindex < sindex and bindex != 0 or bindex == 0:
bindex = index
当然 sell_signal 与buy_signal 在计算macd 的时候就需要提前计算出来,macd 上传信号线 做多,下穿信号线做空,这是最基础的特征规则,再到后面通过信号之间的差值筛选过滤掉负收益的噪点信号,剩下数据则做为预期结果信号做为训练数据。
在处理分类标签时,我采用了独热编码(one-hot encoding)的方式,将分类标签转换为二进制向量。同时,为了让模型能够处理各种信号,我们还对数据进行了标准化处理。
data_train = pd.read_excel("btc-month-6.xlsx")
data_train = data_train.drop(['time','closeTime'],axis=1)
data_train = data_train.fillna(0)
data_train = data_train.astype(float)
encoder = LabelEncoder()
data_train['signal'] = encoder.fit_transform(data_train['signal'].astype(float))
#训练数据与测试验证数据分离
data_val = pd.read_excel("btc-month-6-val.xlsx")
testData = data_val.copy()
data_val = data_val.drop(['time','closeTime'],axis=1)
data_val = data_val.fillna(0)
data_val = data_val.astype(float)
data_val['signal'] = encoder.transform(data_val['signal'].astype(float))
建立模型
我使用了Keras库来创建我们的LSTM模型。模型包含两个LSTM层和一个全连接层,每个LSTM层包含50个神经元。我使用softmax作为激活函数,这可以将输出转换为概率分布,从而对各个类别进行预测。我使用的损失函数是分类交叉熵,优化器选择的是Adam。
model = Sequential() model.add(LSTM(50, input_shape=input_shape, return_sequences=True)) model.add(LSTM(50)) model.add(Dense(np.unique(train).shape[0], activation='softmax')) model.compile(loss="categorical_crossentropy", optimizer='adam', metrics=['accuracy'])
训练模型
在训练模型时,我采用了早停(early stopping)和模型检查点(model checkpoint)两种回调函数。早停可以防止模型过拟合,当验证集损失在一定轮次内没有改善时,训练就会停止。模型检查点则会在每个epoch后保存模型,使我们能够使用最优的模型。
我用80%的数据进行训练,20%的数据进行验证,5000个epoch,batch size设为16。
early_stopping = EarlyStopping(monitor='val_loss', patience=10)
model_checkpoint = ModelCheckpoint('model.h5', save_best_only=True)
model.fit(x_train, y_train, epochs=5000, batch_size=16, validation_data=(x_val, y_val),
callbacks=[early_stopping, model_checkpoint], class_weight=class_weights_dict)
当然在时间的推移后后,训练结束,也是最激动人心的时候,使用新数据验证模型的准确率。
我在使用训练数据后的1日内的5分钟级别k线数据上面使用模型进行验证
row : 1476
[1.65, 98.19, 0.17]
row : 1477
[0.73, 98.27, 1.0]
row : 1478
[1.49, 98.25, 0.26]
row : 1479
[0.97, 98.62, 0.41]
上面代码中我使用了
encoder = LabelEncoder() data_train['signal'] = encoder.fit_transform(data_train['signal'].astype(float))
将信号编码转换结果在验证结果数据中为 0 做空 1 空仓 2 做多
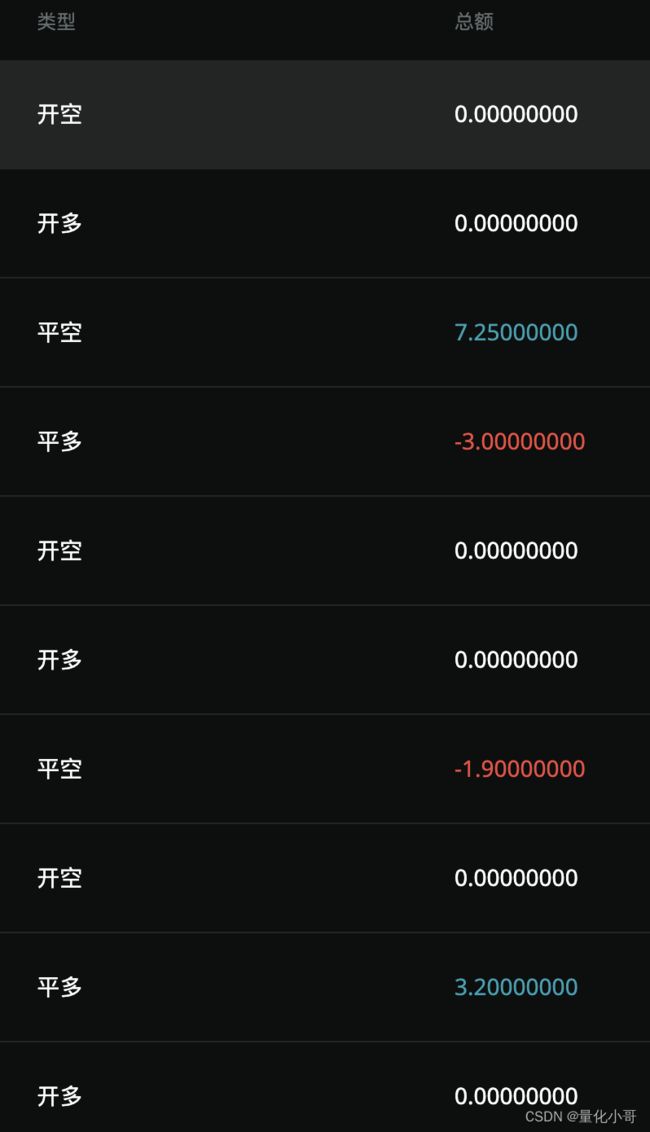
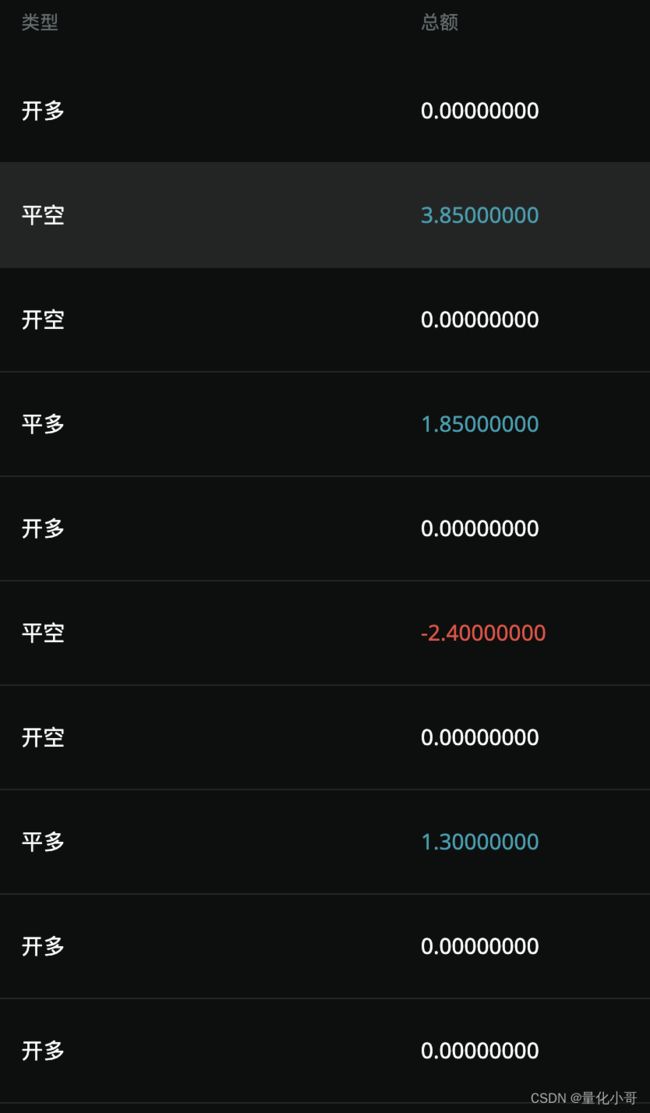
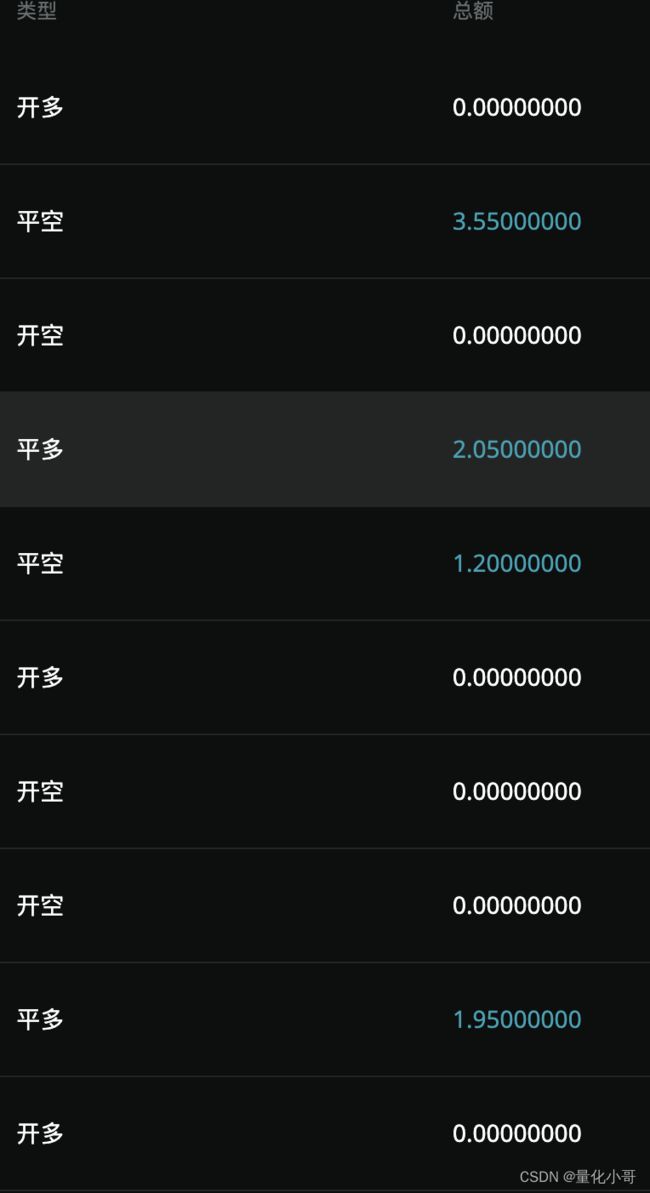
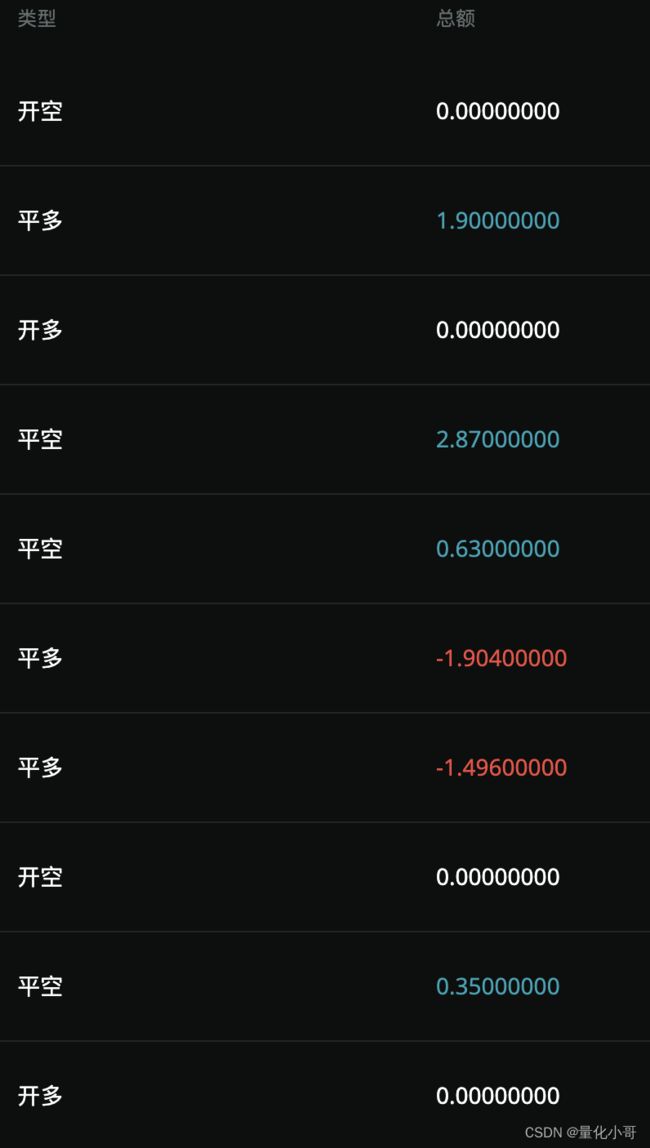
最终:
还是有些噪点,我将结果结果阀值化后,对接到自己的量化工具中,用于实时预测信号得到了还不错的胜率。感觉小有成就。

这个小工具呢方便我的实盘操作,对接上训练模型,将websocket 最新价格用于输入验证。最终返回给我的结果如上。
不知道是谁说的,程序员的尽头是量化交易,我发现走上量化交易的道路就停不了,希望我们热爱的技术能让我们都实现财富自由。交易市场也潜在很多风险,愿大家都能避开各种雷吧。