C语言基础 位域
C语言基础:位域
主题:位域(bit-field)
关键字:位域 冒号 结构体 存储空间
参考链接:C语言中文网:位域 、C菜鸟工具(在线编译器)、位域知乎问答
注:以下内容中如存在错误或缺漏,感谢评论指正,将尽快进行更正完善。
文章目录
- C语言基础:位域
- 一、位域是什么?
- 二、为什么需要使用位域
-
- 1. 减少数据存储空间
- 2. 提高代码阅读性
- 二、位域结构体成员的使用
-
- 1.C 语言的位域结构体成员
- 2.位域使用注意事项
- 3.位域的存储
- 总结
一、位域是什么?
struct
{
unsigned int led_status : 1; //led灯的开关状态,占1个bit
unsigned int led_color : 3; //led灯的颜色,占3个bit
unsigned int led_luminance : 4; //led灯的亮度等级,占4个bit
} status;
现实中的很多信息,例如设备的开关状态,并不需要占用一个完整的字节存储。为了更方便处理这类数据,C语言提供了一种数据结构类型,叫做“位域”,也叫“位段”。位域是一种结构体成员的类型,从字面意思理解,位域把一个存储单元,比如一个字节单元含8bit空间,按占用位bit大小划分出不同的区域,存放不同的数据。
| bit | 7 | 6-4 | 3-0 |
|---|---|---|---|
| 位域成员 | 存放数据1 | 存放数据2 | 存放数据3 |
二、为什么需要使用位域
1. 减少数据存储空间
为什么需要使用位存储?举个直观的例子:我们要控制2个彩色的灯,通过串口通信,给它下发控制指令,从而改变灯的开关状态和颜色状态。(表中data=0xda=0b11011010)
开关状态(占1位): 0=OFF ,1= ON
颜色状态(占3位): 0=红色,1=绿色,2=蓝色,3=黄色,4=紫色,5=白色。
| 字节存储方式(共4字节)byte | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| 位域存储方式(共1字节)bit位 | 7 | 6-4 | 3 | 2-0 |
| 数据定义 | 灯a开关 | 灯a颜色 | 灯b开关 | 灯b颜色 |
| 数据解释 | 1=ON | 5=白色 | 1=ON | 2=蓝色 |
| data | 1 | 101 | 1 | 010 |
表中可以看出,通过位存储的方式,1个字节,就能实现2个灯的控制,而如果采用字节方式,控制2个灯需要4字节。假设要控制200个灯时,按位域方式进行的存储和通信,只需要100字节,而以字节方式则需要400字节。更少的通信数据,有利于保证通信效率,减少误码率,因此位域结构体在网络通信和CAN通信中较常见,有利于提高网络带宽利用率。
总结1:位域方式在数据存储中起到了减少存储空间的作用、在通信中起到减少通信数据量的作用。
2. 提高代码阅读性
接上面控制灯的例子,(表中data=0xda=0b11011010),现在要将灯a关闭,也就是第7bit置0,同时不能改变影响其他数据,也就是将数据变化为(data=0x5a=0b01011010)。虽然可以通过以下代码间接实现位域的赋值功能,但过程并不直观,代码理解起来费时。
总结2:使用位域结构体成员,有助于简化代码,使代码结构清晰
int main()
{
#define LED_OFF 0
unsigned char led_data_init = 0b11011010;//灯总状态初始数据
unsigned char led_data = led_data_init;//灯总状态数据
unsigned char leda_status = LED_OFF;//灯a状态数据:关灯
unsigned char leda_status_bitsize = 1; //灯a状态数据,占用led_data的1个bit
unsigned char leda_status_bitindex = 7; //灯a状态数据,存储在led_data的bit7位置(bit7-0)
/**
* 该宏函数得到一个将对应位域位置赋值0的值(bit7-0)
* 例:0b0111 1111 = BIT_SEAT(1,7)
* 例:0b0001 1111 = BIT_SEAT(3,5)
*/
#define BIT_SEAT(bit_size,bit_index) (unsigned char)(~(~(0xff<< bit_size)<<bit_index))
led_data &= BIT_SEAT(leda_status_bitsize,leda_status_bitindex);//led_data中对应域值清零
led_data |= leda_status << 7;//led_data中对应域赋值新值
//输出结果:led_data_init=0xda,led_data=0x5a
printf("led_data_init=0x%x,led_data=0x%x",led_data_init,led_data);
return 0;
}
二、位域结构体成员的使用
1.C 语言的位域结构体成员
带有预定义宽度的变量被称为位域,位域在本质上就是一种结构类型,其成员按二进制位分配,它的基本用法与结构体一样。
struct 位域结构名
{
类型说明符 type 位域名member_name : 位域长度 width ;
类型说明符 type 位域名member_name : 位域长度 width ;
......
}位域结构体定义的变量;
/**
* 以下代码定义了一个名为 struct bs 的结构体,
* data 为 bs 的结构体变量,共占四个字节:
*/
struct bs{
int a:8; //变量a,占8bit
int b:2; //变量b,占2bit
int c:6; //变量c,占6bit
}data,*pdata;
pdata=&data;
data.b = 1;//位域的使用和结构成员的使用相同
pdata->c = 10;//位域结构体可以使用指针,位域成员不能使用指针。
2.位域使用注意事项
2.1.位域的类型
根据早期ANSI C规定,位域最开始只支持 int,unsigned int ,unsigned int三种类型,后面C99标准又增加了bool类型。但几乎所有的编译器都对此进行了进一步扩展,char ,unsigned char ,long,enum等都是可用的类型。实际应用中,尽量使用无符号类型,否则可能存在符号不一致问题。
位域不支持浮点型,否则编译提示:bit-field ‘c’ has invalid type。
2.2.位域的宽度
宽度必须小于或等于位域类型的位宽度,例如char类型,位宽度最大为8,int类型32位系统中,位宽度最大为32。错误的示例如下,编译器会提示错误:error: width of ‘a’ exceeds its type。
unsigned char a:9; //错误的宽度定义,a最大为8。
unsigned int b:33; //错误的宽度定义(假设在32位系统),32位系统中最大为32。
**注:**网上常见一种说法”位域不允许跨2字节,如一个字节所剩空间不够存放另一位域时,则会从下一单元起存放该位域,也就是说位域不能超过8bit。“这种说法并不正确,可能是英文翻译和理解错误。
比较恰当的说法是,**位域不允许跨2个类型单位,也就是说位域长度不能超过所依赖类型的最大位bit数。**例如,程序运行在32位系统,使用unsigned int,则位域宽度不能超过32。
使用以下例程序测试验证,刚好占32位,4个字节,位域数据紧密排列,并不存在一个字节所剩空间不够,从下一单元存放的现象。
struct bs{
unsigned a:7;
unsigned b:7;
unsigned c:7;
unsigned d:7;
unsigned e:4;
} n;
//结果输出sizeof n = 4
printf("sizeof n = %d\n",sizeof(n));
2.3.对位域结构体成员赋值不要超出其位域数值范围
在使用位域时,要特别注意检查数据赋值范围,虽然很基础但也最容易出错的操作,在进行位域成员赋值时,很可能不经意间就超出了范围。
struct
{
unsigned int age : 3;//age 的赋值范围0-7
} Age;
int main( )
{
Age.age = 8; // 二进制表示为 1000 有四位,超出
printf( "Age.age : %d\n", Age.age );
return 0;
}
位域成员赋值不要超过范围,以上代码编译时,会提示警告:第四位溢出,溢出的位会被忽略,只保留有效位,printf输出Age.age : 0
2.3无名位域、空域
位域可以是无名位域,也叫空域,这时它只用来作填充或调整位置。无名的位域是不能使用的。
无名位域的长度为0时,表示该单元后续空间都不能使用,需要从下一个新单元存储新数据。
已命名位域不能设置0长度(编译报错),位段定义的第一个位段长度不能为0(虽然编译不报错,但应避免这样使用)。
struct k{
int a:1;
int :2; /* 该 2 位不能使用 */
int :0; /* 该int单元,后续位不能使用 */
int b:2; /* 存储在下一个新的int单元 */
};
2.4位域成员指针
C语言无法使用&对位域成员做取地址运算,不存在位域成员指针。
2.5位域数据的符号问题
在计算机中,所有的数据以补码的形式存储。使用有符号类型时,其最高位,会被作为符号位,数据以补码存储。
位域成员a,只有1位,0b1,最高位即本身,被当做符号位1。可以理解为向前补充符号位0xffffffff=-1,
位域成员b,有2位,0b11,最高位被当做符号位1,可以理解为向前补充符号位0xffffffff=-1。也可以通过补码转原码方式理解,补码的符号位1,数据为1,转换为原码,符号位1不变表示负号,数据为1,取反=0+1=1,整体表示-1。
正数补码等于原码,不存在符号变化,推荐位域中使用无符号类型。
{
struct bs{
signed a:1;
signed b:2;
} n ;
n.a=1;
n.b=3;
//打印输出a=-1,b=-1
printf ("a =%d, b=%d",n.a,n.b);
3.位域的存储
3.1位域数据的平台兼容性
位域天然的不利于兼容性。因为C语言标准并没有规定位域的具体存储方式,基于不同的编译器,不同的运行环境都可能有不同的实现。位域的数据存储,和编译器和运行环境有很大的关系,为了保证在不同平台运行结果的一致性,实现跨平台兼容。尽量使用无符号类型,并尽量简单的使用位域结构体成员。
如果位域在该项目中使用非常少,无关键用途,为了保证保证兼容性,可以选择不使用位域。
3.2类型相同的相邻位域数据存储
当相邻成员的类型相同时,位域按顺序优先存储在同一个单元中。
如果一个单元所剩空间不够存放另一位域时,则会从下一单元起存放该位域。如果剩余空间还够存放另一位域,那么后面的成员紧邻前一个成员存储,中间没有空隙。就像行李箱里放衣服一样,塞的下就继续放,塞不下就换下一个行李箱放。
struct bs{
unsigned short a: 6;
unsigned short b: 7;
unsigned short c: 4;
};
先定义的数据放在低位,单元1存完a、b后,剩余3bit空间放不下c,将c放到下一个单元中。

3.3不同类型的相邻位域数据存储问题
如果相邻位域字段的类型不同,则各编译器的具体实现不同。是否进行压缩,以及如何对齐都存在不确定性,建议编写例程,在具体环境下编译测试。
如果相邻位域字段的类型不相同,但数据长度相同,根据编译器不同,确定是否进行压缩,可能压缩。
如果相邻位域字段的类型不相同,但数据长度不同,根据编译器不同,确定是否进行压缩,通常不压缩。
如果相邻位域字段的类型不相同,总字节数为位域类型所占字节较大的整数倍,遵守结构体数据对齐规则。
如果位域中间穿插着非位域类型,则非位域数据,不参与压缩。可以简单理解为非位域类型,是独立的单元,本身已经占用了自身单元所有bit位置,没有空位给别的数据填充。
struct bs{
unsigned a:7;
unsigned b;//非位域数据,单独占一个unsigned int单元
unsigned c:1;
} n;
3.4位域数据的大小端存储及位序
数据的大小端及位序和编译器,处理器都有关系。
大小端是一种字节序,是指字节数据的外部排序方式,也就是多个btye数据在存储地址中的排序方式,单纯的大小端定义与字节内部存储无关。但通常,我们默认大端使用MSB,小端使用LSB,所以很多文章并不会特别指明位序,只提大小端,默认不提位序,导致对大小端的解释看起来有多个不同的版本。
| 模式 | 应用 |
|---|---|
| 大端 | STM8,C51,TCP/IP协议 |
| 小端 | STM32,X86 |
ARM的大小端模式可配置,需要具体分析,最好运行测试代码进行验证确认,常见使用小端模式。
3.4.1大小端
大小端,是一种字节序,针对多字节数据。而单字节的数据例如char,不需要特意考虑大小端的问题。
首先明确区分两个高低,内存/存储地址高低,数据的高低字节。
大端(Big-endian), 将数据的高位存储在内存的低地址处。
小端(Little-endian),将数据的低位存储在内存的低地址处。
“大小端”这个名词并不容易记忆和理解,它英文描述反而看起来更直观形象。例如,将“大端”翻译成“高尾端"更容易被理解,内存高地址存放数据的尾部低字节。大小指的是内存/存储地址,端指的是数据结束端,也就是数据的结束端字节(也就是最低字节)。
| 模式 | 大小 | 端 |
|---|---|---|
| 大端(Big-endian) | 内存高地址 | 数据的低字节 |
| 小端(Little-endian) | 内存低地址 | 数据的低字节 |
例如数据 int a=0x12345678,在大小端系统中的存储。
| 内存地址 | 大端 | 小端 |
|---|---|---|
| 高地址00000004 | 尾字节78 | 12 |
| 00000003 | 56 | 34 |
| 00000002 | 34 | 56 |
| 低地址00000001 | 12 | 尾字节78 |
换一种更直接的理解和记忆方式,由于计算机总是从低地址往高地址方向读取,大端模式,先读到高字节,小端模式先读到低字节。
基于这个特性使得大小端模式表现出各自的优缺点,符号位在高字节,大端模式能快速判断数据的正负和大小。小端模式,数据字节顺序和内存地址顺序一致,计算机按顺序读取更加高效。同时进行强制类型转换时,可以直接截取,不需要再调整内容。
3.4.2 位序
大小端,是指字节间的排序。字节内部的排序用位序表示。
位序,也叫比特序,分为LSB和MSB两种。
首先明确区分两个高低,内存/存储地址单字节空间内的bit高低位号,数据单字节内的bit权重高低位。
LSB(least significant bit):数据的最低权重位存放在内存字节的第0位。
MSB (most significant bit):数据的最高权重位存放在内存字节的第0位。
小端模式下,只能使用LSB位序模式。
大端模式下,可以使用MSB位序模式,也可以使用LSB,大部分情况使用MSB。
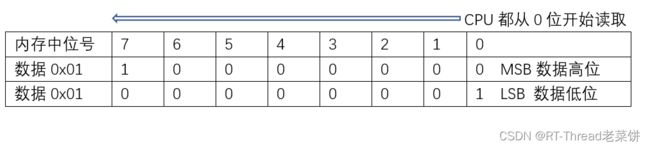
无论LSB还是MSB,CPU都从内存中的低位开始读取,在MSB中读取到的0位内容为数据的高位,在LSB中读取到的0位内容为数据低位。虽然图中数据的存储在内存中不一样,但实际表示的都是同样的数据。对于一般的存储读取操作,字节序及位序并不影响数据读取结果。
但如果涉及大端系统与小端系统进行通信,或对数据进行分割截取,例如强制类型转换,就需要考虑字节序及位序影响。
在C结构体和位域中约定,无论LSB还是MSB,先定义的数据或位域总是放在低位地址。
可以这么理解,计算机总是从低位地址往高位地址寻址,总是先准备好低位的地址用来存储下一个数据,所以无论对结构体还是位域,先定义的数据先被分配,并优先分配到存储空间的低位地址的低位号。
先看LSB和MSB位序对单字节的影响。
在单字节下,小端模式和大端模式并不造成影响,但其默认采用的位序模式对数据造成了影响。
struct bs{
unsigned char a:1;
unsigned char b:2;
unsigned char c:5;
} ;
union {
struct bs n;
unsigned char n_char;
}u;
u.n.a=1;
u.n.b=1;
u.n.c=1;
printf("n_char=0x%.2x",u.n_char);
在LSB模式下,n_char= 0b00001011,0x0b
在MSB模式下,n_char=0b10100001,0xa1

在多字节下,也是一样的,先考虑位序的影响,同时还要附加考虑到大小端的影响。
struct bs{
unsigned short a:1;
unsigned short b:2;
unsigned short c:8;
unsigned short d:2;
unsigned short e:3;
} ;
union {
struct bs n;
unsigned short n_short;
}u;
u.n.a=1;
u.n.b=1;
u.n.c=1;
u.n.d=1;
u.n.e=1;
printf("n_char=0x%.4x",u.n_short);
在小端模式LSB下,byte0 = 0x0b ,byte1 = 0b00101000 =0x28 ;小端模式下,byte1为高权重字节,n_short=0x280b;
在大端模式MSB下,byte0 = 0xa1,byte1 = 0b00101001 =0x29 ;大端模式下,byet1为低权重字节,n_short=0xa129;

可以看到同样的位域数据内容,存储在小端模式和大端模式下,进行整体取值后的值,变成了两个不同的值。所以在采用大端和小端的设备间进行相互通信,需要对数据进行转换后发送,或接收后重新解析。
3.4.3网络序
TCP/IP中,规定了自己的格式,与具体的CPU,操作系统等无关。从而保证了不同主机间通信格式统一。TCP/IP采用大端字节序,小端序主机进行大端网络序TCP/IP通信时候,需要使用htonl()、ntohl()等进行位序转换。
注:网络资料介绍:htonl()只做了字节序的转换,并没有进行比特序的转换。该知识涉及到更深入的网络通信底层,目前还不能理解。
总结
**位域的特点:**减少数据存储,提高代码阅读性,不利于平台兼容。
**位域的推荐使用方法:**简单的去使用位域,
位域推荐使用无符号类型,并尽量使用同一种类型,推荐使用unsigned int。将同类型的位域数据放在一起,尽量将位域数据成员相邻放置在一起,或单独打包成一个结构体。