Designing Applications for High Performance - Part 1
http://blogs.technet.com/b/winserverperformance/archive/2008/04/25/designing-applications-for-high-performance-part-1.aspx
25 Apr 2008 12:40 AM
- Comments 1
Rick Vicik - Architect, Windows Server Performance Team
Now that processors won’t be getting dramatically faster each year, application developers must learn how to design their applications for scalability and efficiency on multiple processor systems. I have spent the last 20 years in SQL Server development and the Windows Server Performance Group looking into multi-processor performance and scalability problems. Over the years, I have encountered a number of recurring patterns that I would like to get designers to avoid. In this three part series, I will go over these inefficiencies and provide suggestions to avoid them in order to improve application scalability and efficiency. The guidelines are oriented towards server applications, but the basic principles apply to all applications.
The underlying problem is processors are much faster than RAM and need hardware caches or else they would spend most of their time waiting for memory access. The effectiveness of any cache depends on locality of reference. Poor locality can reduce performance by an order of magnitude, even with a single processor. The problem is worse with multiple processors because data is often replicated in different caches and updates must be coordinated to give the illusion of a single copy (performing the magic of cache coherency is hard). Also, applications might generate information that needs sharing across processors, which can overload the interconnect mechanism (e.g. bus) and slow down all memory requests, even for “innocent bystanders”.
The following are some of the common pitfalls that can hurt overall performance:
· Using too many threads and doing frequent updates to shared data. This results in a high number of context switches due to lock collisions when several threads try to update the protected data.
· Cache effectiveness is reduced because thread data seldom has enough time in the cache before getting pushed out of the cache by other threads.
These are some of the things application designers can do to reduce the problem:
· Minimize the need to have multiple threads update shared data through data partitioning across processors and minimize the amount of information that must cross boundaries (OO-design and the desire to have context-free components often results in “chatty” interfaces).
· Minimize the number of context switches by keeping the number of threads close to the number of processors and minimize the reasons for them to block (locks, handing off work, handling IO-completion, etc.).
To illustrate how partitioning an application would yield optimal performance compared to having shared data and lock contentions, I will use a simple, static web server scenario as an example. The data in this scenario can be characterized as either payload (cached, previously-served pages) or control (work queues, statistics, freelists, etc.). Figure 1 shows that the combination of updates and shared data must be avoided. Even when the payload is read-only, the control data is usually update-intensive (e.g ref-counts).
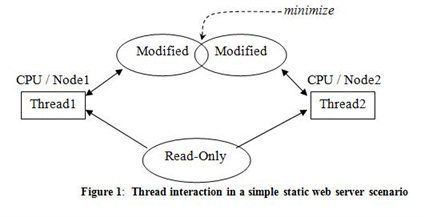
The recommendation is to partition everything by processor or by NUMA node. This can never be fully achieved in real applications, but it guides the design in the right direction. Ideally, there should be per processor threads and each thread’s affinity gets set to the respective processor. Each thread should have its own IO completion port and be event-driven. There should be a network interface card (NIC) for each processor and the interrupts from each NIC should be bound to the corresponding processor by using the IntFilter utility on Windows 2003 or the IntPolicy utility on Windows 2008 and later. Another alternative is using a NIC that supports Receive Side Scaling (RSS). An intelligent network switch can perform link or port aggregation to distribute incoming requests to the multiple NICs. Since the payload (cache of previously-served pages) is read-only, it can be read from any CPU. Full partitioning (including disk data) would require distributing the requests to the partition that owns the subset of data. That is beyond the capability of the network switch.
Figure 2 illustrates one proposed design. Each thread would loop on its completion port, servicing events as they occur (e.g. if a requested web page is not in cache, issue an asynchronous read to bring it in and attach the serving of that page to the IO completion). The only updated shared data left is for the purpose of managing the cache (ref-counting, updating hash-synonym list, evicting older contents). Frequently-updated statistical counters should also be kept per processor and rolled-up infrequently.
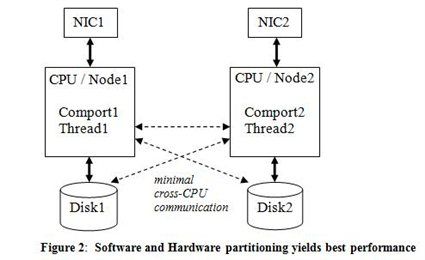
An application needs to be aware of the number of processors because it may need to distribute the load if the link or port aggregation technique isn’t good enough. It may also need to perform a type of load balancing if the requests differ significantly in processing time. Soft affinity (set via SetThreadIdealProcessor API) may be enough, but if the threads are hard-affinitized to processors (set via SetThreadAffinityMask API), periodic work-stealing logic may be needed to avoid some processors going idle while work queues up on others. The handling of I/O completion gets trickier, but more details are provided later and I will explain how using Vista can help.
The first part of this series will cover Threads and side effects associated with having too many active threads contending for resources or trying to update the same piece of memory. It will also provide an overview of some of the improvements that have gone into Vista for thread handling.
Threading Issues
An application that has too many active threads is a bad thing, especially when shared data is updated frequently because locks are needed to protect the data. When locks are taken frequently, even if the total time spent holding locks is very small, each thread runs only briefly before blocking on a lock. By the time any thread runs again, its cache-state has been wiped out. Also, preemption while holding a lock is more likely. A good designer never holds a lock while making a call that could block because that inflates lock hold time. Unfortunately, the designer doesn’t have much control over preemption and page faults, which also inflate lock hold time.
Guidelines for reducing the number of threads
Applications mainly have too many threads to simplify the code rather than to create parallelism. The classic anti-pattern for this is handing off work to another thread and waiting for it to complete when the proper approach should be to make a function call. The exception to this rule is if the consumer needs to be in a different process or thread for isolation reasons. But even then, the operation should always be asynchronous because the consumer may not be responding.
Another reason for having too many threads is not using asynchronous IO where appropriate. It is not necessary to have “lazy-writer” or “read-ahead” threads. Issue the IO asynchronously and handle the completion in the main state machine.
Other reasons that are less under the control of the application designer are the need for separate “input handler” threads when trying to create a unified state machine to handle IO Completion Ports and RPC. Also, using multiple components (RPC, COM, etc) results in multiple thread pools in the application because some components have their own thread-pools and each is unaware of the others when it makes its thread-throttling decisions.
Ideally, an application should have one thread per processor and it should never block. In real practice, it is almost impossible to avoid calling foreign code that can block that single thread. The compromise is to have a per processor main thread that executes the state machine and never calls code that may block. Potentially-blocking operations must be handed-off to a thread pool so that if they do block, the main thread can still run.
Design recommendations for an application thread pool
A well designed thread pool should minimize the active “filler” threads (i.e. those released when the current thread blocks). The application should have a single thread-pool which throttles “filler” threads by “parking” the excess ones at safe stopping points (i.e. when not holding any locks). The worker threads should obtain their own work as opposed to having separate distribution threads (or a “listener” thread to set up a new connection). Load balancing should not require a separate “load balancer” thread. Idle workers should attempt to “steal” work from others (this should be kept at a minimum because it might cause cross-processor traffic).
The Vista thread-pool has some improvements that can help. The input queue is lock-free and thread-agnostic IO completion has eliminated the need for specialized “IO threads”. It is possible to receive input from IO Completion Ports and ALPC (which eliminates the need for a separate input-handler thread). The APIs to do this are TpBindFileToDirect and TpBindAlpcToDirect.
Common threading practices
· Completion Port Thread Throttling
Each IO Completion Port has an active thread limit and keeps track of the number of active threads associated with the port. The OS thread scheduler updates the active thread count when a thread blocks or resumes and it releases a “filler” thread to take the place of the blocked one. The scheduler cannot “take back” a filler thread when the original thread resumes. This is not an issue if threads hardly ever block on anything except the completion port. The completion port thread-throttling mechanism cannot automatically “park” excess filler threads because it has no knowledge of the application and doesn’t know when it is safe to do so (it could be holding a lock... could detect if holding system lock, but not user lock).
· Switch Threads between Requests or During
A server application can spin up a thread to service each connection or it can maintain a pool of threads that service a larger number of connections. Typically the switching of threads among connections occurs on a request boundary, but it could occur during the request (i.e. when it blocks). No thread-throttling is required because no extra threads are released. It can be done with SetJump/LongJump type user stack switching or by queuing a “resume” work packet instead of blocking inside a work packet.
· Handling Multiple Input Signals
It is often necessary for an application to handle input from multiple sources (e.g. shutdown event, registry change, IO completions, device/power notifications, incoming RPC). Unfortunately there is no unified way to handle all of these. The WaitForMultipleObjects API can handle some of the cases but it doesn’t cover IO Completion Port and RPC. Also, WaitForMultipleObjects is limited to 64 objects and has a significant setup/teardown cost. In many cases, WaitForMultiple(Any) can be replaced with a single event plus a type code in the payload data. Another optimization is to use RegisterWaitForSingleObject to avoid “burning” a thread which sits waiting on an event. Instead of having a separate thread that does nothing but wait on a registry change event, RegisterWaitForSingleObject can automatically queue a work item to a thread pool where it gets processed in the main loop along with IO completions, etc.
· OS Thread Scheduling Basics
The thread is the unit of scheduling and the thread with the highest priority gets to run (not the ‘n’ highest where ‘n’ is the number of processors). Applications specify “priority class” not actual priority. Typically, a thread is boosted when readied and the boost decays as processor time is consumed. If a thread consumes a “quantum” of a processor time without waiting, it must round-robin with equal priority threads. Prior to Vista, determining when a thread consumed a quantum of processor time was done using timer-based sampling. Now it is done using the hardware cycle counter and is much more accurate.
When a thread is readied, a search is done for a processor to run it. First, an attempt is made to find an idle processor. While searching, the thread’s “ideal” processor is favored, followed by last processor and current processor. NUMA nodes and physical vs. hyper-threaded processors are considered during the search (e.g. if ideal processor is not available, try other processors on the same NUMA node; if hyper-threaded, attempt to use idle physical processors first). Secondly, if an idle processor cannot be found, attempt to preempt the thread’s “ideal” processor. If thread’s priority is not high enough to preempt, queue it to the “ideal” processor. A thread’s “Ideal” processor can be set using SetThreadIdealProcessor; otherwise it is assigned by the system in a way to spread the load but keep threads of the same process on the same NUMA node.
· HyperThreading Specifics
The thread scheduler is hyper-threading aware and the OS uses the Yield instruction to avoid starving other virtual processors on the same physical processor when spinning. User code that spins should use the YieldProcessor API for the same reason. The GetLogicalProcessorInformation API can be used to get information about the relationship among cores and nodes as well as information about the caches such as size, linesize and associativity.
Stay tuned for our next installment "Data Structures and Locking Issues" ..