【目标检测】Grounding DINO:开集目标检测器(CVPR2023)
文章目录
- 前言
- 1.摘要
- 2.背景
-
- 2.1相对于GLIP优势:
- 2.2 本文贡献
- 2.3 Open-Set 目标检测
- 3.算法
-
- 3.1Feature Extraction and Enhancer
- 3.2. Language-Guided Query Selection
- 3.3. Cross-Modality Decoder
- 3.4. Sub-Sentence Level Text Feature
- 3.5. Loss Function
- 4.实验
- 代码
-
- 1 文本token化
- 2.图像编码
- 3.融合阶段
前言
文章来自清华大学和IDEA(International Digital Economy Academy)
论文: 《Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection》
github: https://github.com/IDEA-Research/GroundingDINO
1.摘要
Grounding DINO,一种开集目标检测方案,将基于Transformer的检测器DINO与真值预训练相结合。开集检测 关键 是引入自然语言至闭集检测器,用于open world的检测。 可实现对新颖类别进行检测,特定属性目标识别。在COCO数据集上零样本检测达到52.5AP,在COCO数据集finetune后达到63AP。
2.背景
大多开集检测器都是通过将闭集检测器扩展到具有语言信息的开集场景 来开发的。如下图所示,一个封闭集检测器通常有三个重要的模块,一个用于特征提取的主干,一个用于特征增强的颈部,以及一个用于区域细化(或box预测)的头部。通过学习语言感知区域嵌入,可以将闭集检测器推广到检测新对象,使每个区域在语言感知语义空间中被划分为新的类别。
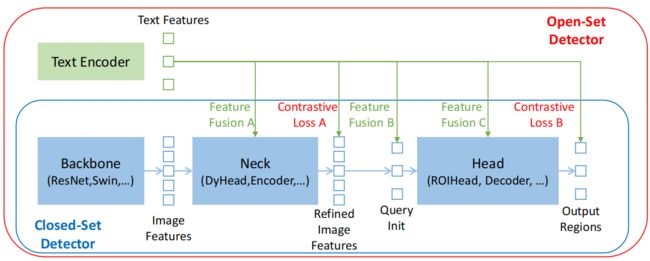 实现这一目标的关键是:在颈部(和/或头部)输出的语言特征和区域输出 之间使用对比损失。为对齐跨模态信息(上图显示了特征融合的三个阶段:颈部(阶段A)、查询初始化(阶段B)和头部(阶段C))GLIP 在颈部模块中执行早期融合(阶段A),而OV-DETR 使用语言感知查询作为头部输入(阶段B)。我们认为,在pepline 中进行更多的特征融合,可以使模型表现得更好。
实现这一目标的关键是:在颈部(和/或头部)输出的语言特征和区域输出 之间使用对比损失。为对齐跨模态信息(上图显示了特征融合的三个阶段:颈部(阶段A)、查询初始化(阶段B)和头部(阶段C))GLIP 在颈部模块中执行早期融合(阶段A),而OV-DETR 使用语言感知查询作为头部输入(阶段B)。我们认为,在pepline 中进行更多的特征融合,可以使模型表现得更好。
2.1相对于GLIP优势:
GLIP:常用的视觉语言模型,用于统一CV与NLP
1、基于Transformer结构与语言模型接近,易于处理跨模态特征;
2、基于Transformer的检测器有利用大规模数据集的能力;
3、DINO可以端到端优化,无需精细设计模块,比如:NMS
2.2 本文贡献
-
提出Grounding DINO,在多个阶段执行视觉-语言模态融合,扩展了封闭的DINO检测器:包括一个特征增强器(feature enhancer)、一个**语言引导的查询选择模块(language-guided query selection)**和一个 跨模态解码器(cross-modality decoder)。这种深度融合策略有效地提高了开集目标的检测能力。
-
我们建议将开放集目标检测的评估扩展到REC数据集。它有助于使用自由形式的文本输入来评估模型的性能。
-
在COCO、LVIS、ODinW和RefCOCO/+/g数据集上的实验证明了接地DINO在开集目标检测任务上的有效性
2.3 Open-Set 目标检测
开放集对象检测使用现有的边界框注释进行训练,旨在利用语言泛化检测任意类。OV-DETR 使用由CLIP模型编码的图像和文本嵌入作为查询来解码DETR框架中的类别指定的框。ViLD将知识从CLIP教师模型中提取为R-CNN类检测器,以便学习到的区域嵌入包含语言的语义。GLIP将目标检测定义为一个grounding问题,并利用额外的grounding数据来帮助学习在短语和区域级别上的对齐语义,可以在完全监督的检测基准上实现更强的性能。DetCLIP涉及到大规模的图像字幕数据集,并使用生成的伪标签来扩展知识库。所生成的伪标签有效地扩展了检测器的泛化能力。
以往的工作只在部分阶段融合多模态信息,这可能导致语言泛化能力的次优(GLIP只在特征增强A阶段融合,OV-DETR只在解码器输入B阶段注入语言信息)此外,REC任务在评估中通常被忽略,这是开放集检测的一个重要场景。
3.算法
如下图,对于图片、文本对,Grounding DINO可以输出多对目标框及对应名词短语。
Grounding DINO采用双编码器,单解码器结构。图像backbone 用于提取图像特征,文本backbone用于提取文本特征,特征增强用于融合图像及文本特征,语言引导的query选择模块用于query初始化,跨模态解码器用于框精细化。
流程如下:
1、图像及文本backbone分别提取原始图像及文本特征;
2、特征强化模块用于跨模态特征融合;
3、通过语言引导查询选择模块从图像特征中选择与文本对应的跨模态query;
4、跨模态解码器从跨模态query中提取需要特征,更新query;
5、输出query用于预测目标框及提取对应短语。
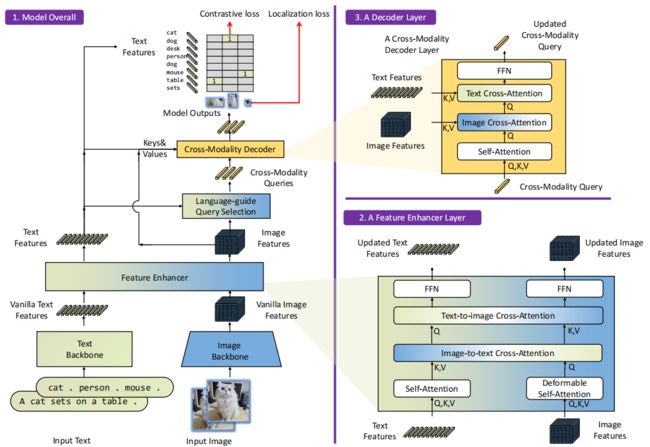
3.1Feature Extraction and Enhancer
给定一个(图像,文本)对,用 Swin Transformer用于提取图像特征,BERT用于提取文本特征,特征强化层如图3中block2,利用Deformable self-attention强化图像特征,原始的self-attention强化文本特征,受GLIP影响,增加图像到文本跨模态以及文本到图像跨模态,帮助对齐不同模态特征。
3.2. Language-Guided Query Selection
为引导文本进行目标检测,作者设计语言引导的query选择机制选择与文本更相关的特征作为解码器的query。算法下图所示。输出num_query索引,据此初始化query。每个decoder query包括两部分:content及position。位置部分公式化为dynamic anchor boxes,使用编码器输出进行初始化;内容部分训练中可学习,查询数量,在实现中被设置为900。

3.3. Cross-Modality Decoder
跨模态解码器结合图像及文本模态信息,跨模态query经过self-attention层,image cross-attention层与图像特征结合,text cross-attention层与文本特征结合,以及FFN层。与DINO相比,每个解码器都有一个额外的文本cross-attention层,引入文本信息,便于对齐模态。
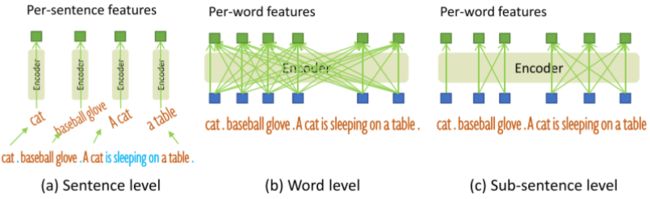
3.4. Sub-Sentence Level Text Feature
之前工作中探究了两种文本prompt,句子层级表征将整个句子编码为一个特征,移除了单词间影响;单词级表征能够编码多个类别,但引入不必要依赖关系;为避免不相关单词相互作用,作者引入attention mask,此为sub-sentence级表征,既保留每个单词特征,又消除不相关单词间相互作用。
3.5. Loss Function
类似DETR,作者使用L1损失及GIOU损失用于框回归;沿用GLIP,对预测目标是否匹配文本使用对比损失约束。具体来说,我们将每个查询点积来预测每个文本标记的对数,然后计算每个logit的 focal loss。盒子回归和分类成本首先用于预测和GT之间的两两匹配。然后,我们计算GT和与相同损失成分匹配的预测之间的最终损失。在类似detr的模型之后,我们在每个解码器层之后和编码器输出之后添加辅助损耗。
4.实验
数据集:COCO、 LVIS、ODinW Benchmark。
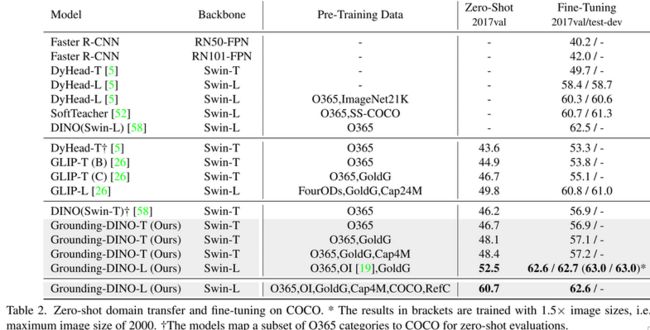
表2,coco数据集zero-shot测试Grounding-DINO-T超越DINO,达到46.2AP,更换大backbone及使用更多数据预训练,达到60.7AP,在COCO数据集finetune后在COCO test数据集达到63AP
代码
1 文本token化
1.tokenizer
tokenized = self.tokenizer(captions, padding="longest", return_tensors="pt").to( samples.device )
结果如下图所示,最终的prompt词对应 其中1012 这个数
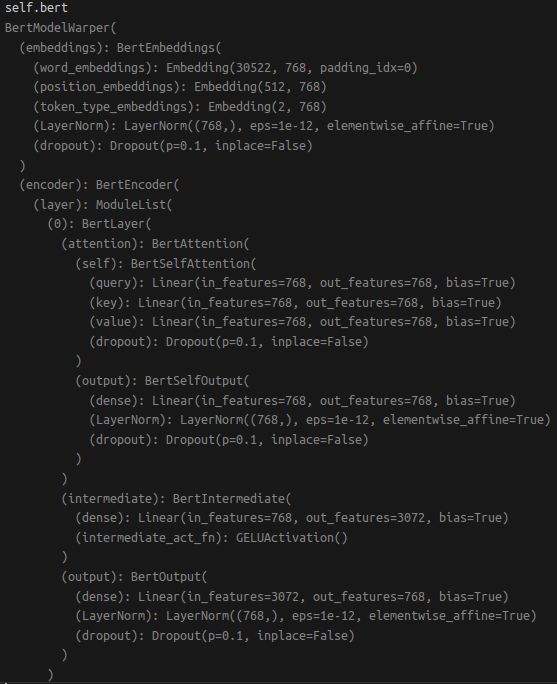
 2.bert(10层bertlayer+pooler),用于提取文本特征
2.bert(10层bertlayer+pooler),用于提取文本特征
bert_output = self.bert(**tokenized_for_encoder) # hedden:(bs, 4, 768)pooler-output(bs, 1, 768)
bert网络结构:
2.图像编码
实用swin transformer提取图像特征,得到3个特征图
features, poss = self.backbone(samples) # feat:[(bs,256,W/8,H/8) (bs,512,W/16,H/16) (bs,1024,W/32,H/32)] poss:positionEmbeddingSineHW
srcs = []
masks = []
for l, feat in enumerate(features):
src, mask = feat.decompose() # (bs,256,W/8,H/8) mask:(bs,W/8,H/8)*[False]
srcs.append(self.input_proj[l](src)) # 特征维度 都映射到256
masks.append(mask)
assert mask is not None
if self.num_feature_levels > len(srcs):
_len_srcs = len(srcs) # 3
for l in range(_len_srcs, self.num_feature_levels):
if l == _len_srcs:
src = self.input_proj[l](features[-1].tensors) # (b,1024,23,42) -> (b,256,12,21)
else:
src = self.input_proj[l](srcs[-1])
m = samples.mask # (b,H,W)*[False]
mask = F.interpolate(m[None].float(), size=src.shape[-2:]).to(torch.bool)[0] # (b,12,21) 12=w/64
pos_l = self.backbone[1](NestedTensor(src, mask)).to(src.dtype) # positionEmbeddingSineHW:(b,256,12,21)
srcs.append(src)
masks.append(mask)
poss.append(pos_l)
3.融合阶段
整体代码为:
input_query_bbox = input_query_label = attn_mask = dn_meta = None
hs, reference, hs_enc, ref_enc, init_box_proposal = self.transformer(
srcs, masks, input_query_bbox, poss, input_query_label, attn_mask, text_dict)
展开 self.transformer:
src_flatten = []
mask_flatten = []
lvl_pos_embed_flatten = []
spatial_shapes = []
for lvl, (src, mask, pos_embed) in enumerate(zip(srcs, masks, pos_embeds)):
bs, c, h, w = src.shape # (b,256,91,167)
spatial_shape = (h, w)
spatial_shapes.append(spatial_shape)
src = src.flatten(2).transpose(1, 2) # bs, hw, c
mask = mask.flatten(1) # bs, hw
pos_embed = pos_embed.flatten(2).transpose(1, 2) # bs, hw, c
if self.num_feature_levels > 1 and self.level_embed is not None:
lvl_pos_embed = pos_embed + self.level_embed[lvl].view(1, 1, -1) # 相对位置编码+绝对(4,256) ->(b,15197,256)
memory, memory_text = self.encoder(
src_flatten, # (b,20279,256)
pos=lvl_pos_embed_flatten,
level_start_index=level_start_index,
spatial_shapes=spatial_shapes,
valid_ratios=valid_ratios,
key_padding_mask=mask_flatten,
memory_text=text_dict["encoded_text"], # (b,4,256)
text_attention_mask=~text_dict["text_token_mask"],
# we ~ the mask . False means use the token; True means pad the token
position_ids=text_dict["position_ids"],
text_self_attention_masks=text_dict["text_self_attention_masks"],
) # (b,20279,256)(b,4,256)
进入主函数self.encoder:
1.获得anchor,文本位置编码
reference_points = self.get_reference_points( spatial_shapes, valid_ratios, device=src.device )
# (b,20279,4,2):0-1之间的密集anchor点(每个点xy坐标重复4遍)
pos_text = get_sine_pos_embed( position_ids[..., None], num_pos_feats=256, exchange_xy=False )
对文本的正余弦位置编码:
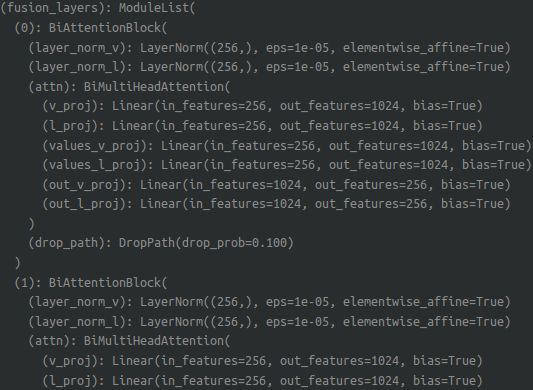
 2.首次融合 self.fusion_layers
2.首次融合 self.fusion_layers
output, memory_text = checkpoint.checkpoint( self.fusion_layers[layer_id],
output, memory_text, key_padding_mask, text_attention_mask,)
v = self.layer_norm_v(v) # (b,20279,256) 前后不变
l = self.layer_norm_l(l) # (b,4,256) 前后不变
delta_v, delta_l = self.attn(v, l, attention_mask_v=attention_mask_v, attention_mask_l=attention_mask_l) # mask 维度跟v 、l一样,都是False delta_v:(b,20279,256) delta_l:(b,4,256)
v = v + self.drop_path(self.gamma_v * delta_v)
l = l + self.drop_path(self.gamma_l * delta_l)
return v, l
self.attn:
query_states = s
elf.v_proj(v) * self.scale # 0.0625 -> (b,20279,1024)
key_states = self._shape(self.l_proj(l), -1, bsz) # (b,4,1024) reshape-> (b,4,4,256)
value_v_states = self._shape(self.values_v_proj(v), -1, bsz) # (b,4,20279,256)
value_l_states = self._shape(self.values_l_proj(l), -1, bsz) # (b,4,4,256)
proj_shape = (bsz * self.num_heads, -1, self.head_dim) # (4*b, -1, 256)
query_states = self._shape(query_states, tgt_len, bsz).view(*proj_shape) # (4*b,20279,256)
key_states = key_states.view(*proj_shape) # (4*b,4,256)
value_v_states = value_v_states.view(*proj_shape) # (4*b,20279,256)
value_l_states = value_l_states.view(*proj_shape) # (4*b,4,256)
src_len = key_states.size(1)
attn_weights = torch.bmm(query_states, key_states.transpose(1, 2)) # bs*nhead, nimg, ntxt # (4*b,20279,4)
if self.stable_softmax_2d:
attn_weights = attn_weights - attn_weights.max()
attn_weights_T = attn_weights.transpose(1, 2)
attn_weights_l = attn_weights_T - torch.max(attn_weights_T, dim=-1, keepdim=True)[0]
attn_weights_l = attn_weights_l.softmax(dim=-1) # (4b,20279,4)
attn_weights_v = attn_weights.softmax(dim=-1) # (4b,20279,4)
attn_output_v = torch.bmm(attn_probs_v, value_l_states) # (4b,20279,256)
attn_output_l = torch.bmm(attn_probs_l, value_v_states) # (4b,4,256)
attn_output_v = self.out_v_proj(attn_output_v) # (b,20279,1024) -> (b,20279,256)
attn_output_l = self.out_l_proj(attn_output_l) # (b,4,1024) -> (b,4,256)
3.文本编码:
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
q = k = self.with_pos_embed(src, pos) # src+pos
src2 = self.self_attn(q, k, value=src, attn_mask=src_mask)[0]
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout2(src2)
src = self.norm2(src)
4.图像编码:deformable transformer
sampling_offsets = self.sampling_offsets(query).view(
bs, num_query, self.num_heads, self.num_levels, self.num_points, 2 ) # (b,20279,256) -> conv-> (b,20279,8,4,4,2)
attention_weights = self.attention_weights(query).view(
bs, num_query, self.num_heads, self.num_levels * self.num_points ) # (b,20279,256) -> conv-> (b,20279,8,16)
attention_weights = attention_weights.softmax(-1) # (b,20279,8,16)
attention_weights = attention_weights.view(
bs,
num_query,
self.num_heads,
self.num_levels,
self.num_points,
)
output_memory, output_proposals = gen_encoder_output_proposals(memory, mask_flatten, spatial_shapes )
# 三层线性层。用于将256维映射到4维
enc_outputs_coord_unselected = ( self.enc_out_bbox_embed(output_memory) + output_proposals )
enc_outputs_class_unselected = self.enc_out_class_embed(output_memory, text_dict)
y = text_dict["encoded_text"]
res = x @ y.transpose(-1, -2) # (b,20279,4)
topk_logits = enc_outputs_class_unselected.max(-1)[0] # (b,20279)
topk_proposals = torch.topk(topk_logits, topk, dim=1)[1] # bs, 900
refpoint_embed_undetach = torch.gather( enc_outputs_coord_unselected, 1, topk_proposals.unsqueeze(-1).repeat(1, 1, 4) ) # unsigmoid
init_box_proposal = torch.gather( output_proposals, 1,k_proposals.unsqueeze(-1).repeat(1, 1, 4) ).sigmoid() # sigmoid
tgt_undetach = torch.gather( output_memory, 1, topk_proposals.unsqueeze(-1).repeat(1, 1, self.d_model) ) # 找到900个特征
tgt_ = ( self.tgt_embed.weight[:, None, :].repeat(1, bs, 1).transpose(0, 1) ) # nq=900, bs, 256 预先设置的可学习参数
4.解码器:包含6层重复的结构,如下图
hs, references = self.decoder(
tgt=tgt.transpose(0, 1),
memory=memory.transpose(0, 1),
memory_key_padding_mask=mask_flatten,
pos=lvl_pos_embed_flatten.transpose(0, 1),
refpoints_unsigmoid=refpoint_embed.transpose(0, 1),
level_start_index=level_start_index,
spatial_shapes=spatial_shapes,
valid_ratios=valid_ratios,
tgt_mask=attn_mask,
memory_text=text_dict["encoded_text"],
text_attention_mask=~text_dict["text_token_mask"],

DeformableTransformer:
高度封装的一种轻量化DETR,用于做局部注意力查询。感兴趣可以看论文。
output = MultiScaleDeformableAttnFunction.apply(
value, # (b,20279,8,32)
spatial_shapes,
level_start_index,
sampling_locations, # (b,900,8,4,4,2)
attention_weights, # (b,900,8,4,4)
self.im2col_step, # 64
) # out:(b,900,256)