基于PySpark的10亿级数据集LAION-5B元数据快速处理实践(全文分享)
推荐语
多模态大模型训练如火如荼展开,但以LAION-5B为代表的大规模多模态数据集获取却成了一个令人头疼的问题。
OpenDataLab两位工程师在浦数 AI Talk做了非常实用的LAION-5B下载经验分享,我们整理了其演讲内容、Parquet文件、图片下载工具,希望能对大家下载同类数据集提供帮助和参考。以下为全文内容:
一、 数据集背景
根据历史研究发现,随着训练数据增加时,ALIGN、BASIC、Turing Bletchly、FLORENCE和GLIDE等大型多模态视觉语言模型在新的缺少样本标签的数据集上也有很强的迁移能力,而且性能还在稳定提高。但这些模型需要数十亿的图文数据才有达到良好的效果,到2022年为止,还没有十亿规模的公开图文对数据集。
直到LAION-5B发布,该数据集由5.85Billoin CLIP过滤的图像文本对组成,它为多模态预训练提供非常重要的“燃料”。(之前我们写过LAION-5B数据集解读,戳此回顾:80TB!58.5亿!世界第一大规模公开图文数据集LAION-5B 解读)
二、 LAION-5B 数据集结构
根据官方文件统计,LAION-5B数据有5,860,068,373个样本,按照语言被官方划分为3个子数据集,分别是:
- laion2b-en :2.32 billion of these contain texts in the English language
- laion2b-multi :2.26 billion contain texts from 100+ other languages
- laion1b-nolang :1.27 billion have texts where a particular language couldn’t be clearly detected.
其中每个数据集官方提供了原始图片的URL,可以根据URL下载图片文件,以及些URL上的标签。 这部分元数据被存储在parquet文件中。样例parquet文件结构如下:
data_sample
├── laion2B-en
│ ├── part-00006-5114fd87-297e-42b0-9d11-50f1df323dfa-c000.snappy.parquet
│ ├── part-00014-5114fd87-297e-42b0-9d11-50f1df323dfa-c000.snappy.parquet
│ ├── part-00039-5114fd87-297e-42b0-9d11-50f1df323dfa-c000.snappy.parquet
│ ├── part-00043-5114fd87-297e-42b0-9d11-50f1df323dfa-c000.snappy.parquet
│ ├── part-00078-5114fd87-297e-42b0-9d11-50f1df323dfa-c000.snappy.parquet
│ ├── part-00093-5114fd87-297e-42b0-9d11-50f1df323dfa-c000.snappy.parquet
│ └── part-00123-5114fd87-297e-42b0-9d11-50f1df323dfa-c000.snappy.parquet
└── laion2B-multi
├── part-00001-fc82da14-99c9-4ff6-ab6a-ac853ac82819-c000.snappy.parquet
├── part-00026-fc82da14-99c9-4ff6-ab6a-ac853ac82819-c000.snappy.parquet
├── part-00030-fc82da14-99c9-4ff6-ab6a-ac853ac82819-c000.snappy.parquet
├── part-00034-fc82da14-99c9-4ff6-ab6a-ac853ac82819-c000.snappy.parquet
└── part-00125-fc82da14-99c9-4ff6-ab6a-ac853ac82819-c000.snappy.parquet三、 Parquet元数据处理
在官方下载parquet元数据时,发现以下几个小问题:
- similarity、aesthetic_score等指标分布在多个parquet文件中,字段分散、类型不统一,需要多次下载。使用时需要先关联组合查询,TB级的文件处理速度慢,需要高配置的服务器进行处理;
- parquet文件中图片存储路径规则不明确,通过parquet过滤筛选图片时,无法关联下载图片的存储路径和其它字段
- parquet文件中parquet_id、hash等字段重复,影响图片的唯一索引
- 通过url下载的图片格式未知(有webp、jpg、png、avif等多种格式),影响下载图片的预览和存储
为了满足不同场景的数据使用需求,保证图片唯一索引ID,我们对官方的parquet文件进行了关联合并、字段补充等操作,形成一张字段丰富的“宽表”,数据表结构与字段设计如下:
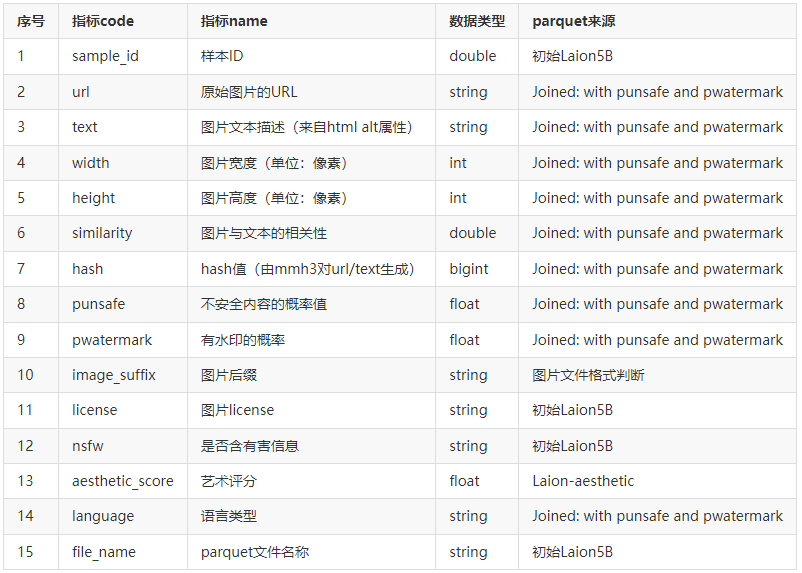
上表中,最后一列是parquet文件来源,表示字段对应的parquet文件。 这里使用了官方的3处parquet文件,数据预览、下载链接如下:
1. 初始Laion5B
- https://huggingface.co/datasets/laion/laion2B-en
- https://huggingface.co/datasets/laion/laion2B-multi
- https://huggingface.co/datasets/laion/laion1B-nolang
2. Joined: with punsafe and pwatermark
- https://huggingface.co/datasets/laion/laion2B-en-joined
- https://huggingface.co/datasets/laion/laion2B-multi-joined
- https://huggingface.co/datasets/laion/laion1B-nolang-joined
3. Laion-aesthetic
Laion aesthetic is a laion5B subset with aesthetic > 7 pwatermark < 0.8 punsafe < 0.5 See
- https://huggingface.co/datasets/laion/laion1B-nolang-aesthetic
- https://huggingface.co/datasets/laion/laion2B-en-aesthetic
- https://huggingface.co/datasets/laion/laion2B-multi-aesthetic
四、 处理流程及步骤
下面聊聊“宽表”的加工处理过程,有需求的同事可参考对官方的原始parquet进行处理。嫌麻烦的同学,可以交给opendatalab,在网站下载处理好的parquet文件。(https://opendatalab.com/LAION-5B)
因为parquet文件数据量较大,有几个TB,这里我们使用了大数据集群进行了分布式处理。
● 使用的技术栈有:
Spark/Hadooop/Hive/HDFS/Impala
● 集群硬件配置:
服务器3台,48core Cpu, 750GB Memory, 4TB Hard disk
● 数据处理过程和流程图如下:
数据输入:
- 下载官网parquet文件,并load到Hive表
- 解析下载的图片,判断图片类型,形成id, image_path, image_suffix的映射文件
数据处理:
- 读取Hive表数据,通过PySpark对Hive表的数据进行分布式join关联操作
数据输出:
- Hive结果表导出为parquet格式文件,并上传至OSS/Ceph存储

为了方便数据处理,这里对数据表进行简单的分层:
- ODS层:原始parquet文件load Hive后的结构化数据表,其中表2是对表1字段进行了裁减,表3是下载图片相关的信息。因为官方parquet文件只提供了下载url链接,我们并不知道图片类型和后缀,所以对下载的图片文件进行程序判定,识别出图片类型,对应image_suffix字段,image_path是图片的存储路径。
- DMD层:通过对表2、3、4进行join关联操作,生成中间表6
- DMS层:将中间表6与含有punsafe、pwatermark信息的表5进行关联,得到最后的结果表7
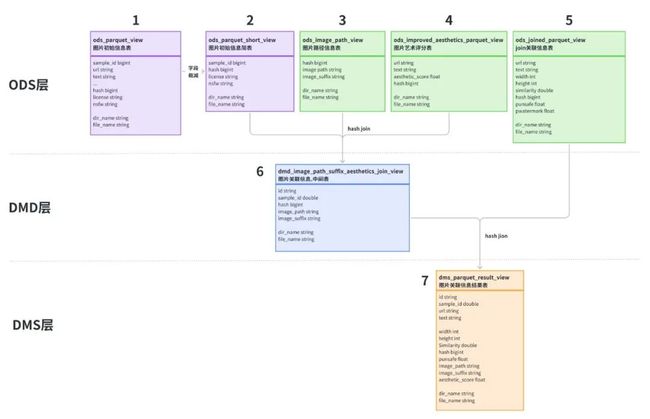
数据处理操作和代码示例如下:
4-1. Data load
主要操作是将parquet文件load到Hive表,load操作完成后,得到图中的1、3、4、5四张Hive表。
以初始parquet文件load为例,示例代码如下。
import os
from pyspark.sql import HiveContext, SQLContext
from pyspark.sql.functions import lit, input_file_name
from pyspark.sql.functions import col, udf
from pyspark.sql.types import StringType, LongType
import mmh3
sc = spark.sparkContext
sql_context = SQLContext(sc)
# 通过url/text计算hash值
def compute_hash(url, text):
if url is None:
url = ''
if text is None:
text = ''
total = (url + text).encode("utf-8")
return mmh3.hash64(total)[0]
# 注册spark udf
udf_compute_hash = udf(compute_hash, LongType())
# 提取input_file_name路径中的文件名称
def path_proc(file_path):
return str(file_path).split("/")[-1]
udf_path_proc = udf(path_proc)
# 因数据总量较大,这里按子集分批读取
parquet_path = "/nvme/datasets/laion5b/parquet/laion2B-en"
# parquet_path = "/nvme/datasets/laion5b/parquet/laion2B-multi"
# parquet_path = "/nvme/datasets/laion5b/parquet/laion2B-nolang"
# Hive一级分区名称
head_tail = os.path.split(parquet_path)
partition_name = head_tail[1]
parquet_df = spark.read.parquet(f"file://{parquet_path}/*.parquet")
parquet_df = parquet_df.withColumn("file_name", input_file_name())
parquet_df = parquet_df.withColumn("hash", udf_compute_hash(parquet_df["URL"], parquet_df["TEXT"]))
parquet_df = parquet_df.withColumn("dir_name", lit(f"{partition_name}"))
parquet_df = parquet_df.withColumn("file_name", udf_path_proc(parquet_df["file_name"]))
# 自定义视图名称,并注册视图
view_name = 'parquet_view'
parquet_df.createOrReplaceTempView(f"{view_name}")
# 数据写入Hive分区表,一级分区名称dir_name,二级分区名称file_name
sql_context.sql(f"insert overwrite table laion5b.parquet_view partition(dir_name='{partition_name}', file_name) select SAMPLE_ID,URL,TEXT,HEIGHT,WIDTH, LICENSE,NSFW,similarity,`hash`, file_name from {view_name}")4-2. Data processing
数据处理过程主要包括数据表裁减、hash join操作。
因为表1的数据量较大,存在字段冗余,这里对表1的部分字段进行裁减得到表2。 表2、3、4的join代码如下,先将图片的sample_id、licenese、nsfw、image_suffix、aesthetic_score字段,按hash值进行关联,合并成一张表。 因为需要使用file_name作为Hive表二级动态分区,也避免大量数据join导致OOM,这里按dir_name分别进行join操作,不同的分区修改对应的dir_name即可。
join_sql = """
insert overwrite table laion5b.dmd_image_path_suffix_aesthetics_join_view PARTITION (dir_name = 'laion2B-en', file_name)
select A.sample_id,
A.`hash`,
B.image_path,
B.image_suffix,
A.license,
A.nsfw,
C.aesthetic_score,
A.file_name
from laion5b.ods_parquet_short_view A
left join laion5b.ods_image_path_view B on A.`hash` = B.`hash`
and B.dir_name = 'laion2B-en'
left join laion5b.ods_improved_aesthetics_parquet_view C on A.`hash` = C.`hash`
where A.dir_name = 'laion2B-en'
"""
join_df = sqlContext.sql(join_sql)表5与表6通过hash字段进行join,得到result结果表7。
sc = spark.sparkContext
sqlContext = SQLContext(sc)
join_sql = """
insert overwrite table laion5b.dms_parquet_result_view PARTITION (dir_name = 'laion2B-en', file_name)
select B.id, B.sample_id, A.url, A.text, A.width, A.height,
A.similarity, A.`hash`, A.punsafe, A.pwatermark,
if(B.image_suffix is null or B.image_suffix = 'jpg', B.image_path,
regexp_replace(B.image_path, right(B.image_path, 3), B.image_suffix)) as image_path,
B.image_suffix, B.LICENSE, B.NSFW, B.aesthetic_score, A.language, B.file_name
from laion5b.ods_joined_parquet_view A
left join (
select id, sample_id, image_path, image_suffix, LICENSE,
NSFW, aesthetic_score, `hash`, dir_name, file_name,
ROW_NUMBER() OVER (PARTITION BY `hash` order by `hash`) as rn
from laion5b.dmd_image_path_suffix_aesthetics_join_view
where dir_name = 'laion2B-en'
) B on A.dir_name = B.dir_name
and A.`hash` = B.`hash`
and B.rn = 1
where A.dir_name = 'laion2B-en'
"""
join_df = sqlContext.sql(join_sql)4-3.Data write
最后将Hive结果表导出为snappy压缩格式的parquet文件,再上传到对象存储就可以使用了。
sc = spark.sparkContext
sql_context = SQLContext(sc)
write_df = sql_context.sql("""
select sample_id, url, text, width, height, similarity, hash,
punsafe, pwatermark, image_suffix, license, nsfw, aesthetic_score, language, file_name
from laion5b.parquet_improve_result_view
where dir_name='laion2B-multi'
""")
write_df.repartition(1).write.parquet("/datasets/result/multi/", mode="overwrite", partitionBy='file_name', compression="snappy")五、LAION-5B媒体图片下载
在OpenDataLab网站下载到parquet文件后,可以根据这份元数据下载对应的图片文件。
现在,我们也开源了LAION-5B图片下载代码,github开源地址如下: https://github.com/opendatalab/laion5b-downloader
耗时25天,目前下载的图片总量为5065377962张(因url链接和网站原因,部分图片无法下载),总存储量为300+TB。
六、parquet不可不知(附下载链接)
在对官方parquet进行处理时,发现了数据中的几个小问题,也同步你知。
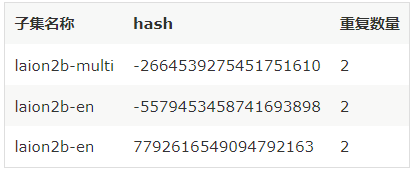
- 初始LAION-5B parquet文件中sample id字段重复度较高,有同学使用sample_id字段作为唯一索引,为了避免数据问题,建议使用hash替换。
我们来看看sample_id的重复情况:

当然,hash在按laion2b-en、laion2b-multi、独立分类的子集中共有6条重复值,laion1b-nolang无数据重复。 在使用时注意下即可,hash值重复情况如下表:
2. 3个分类子集的图片精确数量如下,可以用来对比图片是否有缺失问题。
| 子集名称 | 图片数量 |
|---|---|
| 总数据量 | 5,860,068,373 |
| laion2b-multi | 2266202935 |
| laion2b-en | 2322161808 |
| laion1b-nolang | 1271703630 |
最后,有需要的同学可以在OpenDataLab下载处理好的parquet文件。
OpenDataLab parquet文件下载链接:
https://opendatalab.com/LAION-5B
-END-
作者 | 喻佳、张文坚