点云深度学习系列博客(七): 针对点云的数据增强技术
好长时间不更新博客了,入职以后突然就变忙了,确实有心无力。最近做一个点云数据增强的项目,搞了一个简单的前期调研,趁着最近几天不太忙,凑一篇博客出来,保一下博客专家资格...
一. 简介
我们在利用深度学习进行三维视觉任务计算,尤其是三维点云数据处理时,始终要面对一个难题,即数据规模和数据自身的偏见性问题。对于自然语言处理和图像任务来说,由于存量数据足够大,使得在统计上,训练数据可以被作为是真实场景的一个离散采样模拟,这样训练出来的模型,其鲁棒性和适用性在真实数据上是有保障的。但是点云数据是完全不同的。首先,点云数据本身的数据规模存在极大的限制,目前主流的ModelNet40也就40个类别,就算组合了shapeNet,其数据量远远不能覆盖实际的样本空间,使得模型的泛化性受到了极大的限制。另外,由于点云属于三维数据,其表示形式自然要比文本和图像复杂,受到坐标系的限制会更大,对于姿态,尺度等更加敏感。这使得对于点云建立特征学习模型变得尤其困难。因此,面向点云的数据增强研究被提出。
顾名思义,点云数据增强就是为了解决点云训练数据的种种限制问题。包括点云训练数据集的样本量不够,受限于欧氏空间,对相似变换,非均匀分布以及几何缺失敏感等,数据增强技术通过一些生成,特征抽取与表达,学习模型,迁移学习等方式,以降低训练数据自身缺陷的负面影响,进而提升三维点云智能计算的性能。我调研了2019年到2022年的几个数据增强相关的前沿工作,接下来我们就详细学习下这些工作的基本思路。
二. 姿态增强
在点云深度学习领域的先驱性工作PointNet中,Qi等介绍了一个基于学习的变换矩阵,来解决针对点云数据集模型不同姿态的对应问题。后来经过一些研究者的深入学习后,大家发现这个学习的变换矩阵没什么鸟用。一个最简单的证明就是,如果我们为训练数据的每一个模型添加一个随机的变换,那么网络模型的性能就会显著下降。原因是,类似像ModelNet这样的数据集,其姿态已经是初步对准过的了。因此,数据增强相关研究,很大一部分工作是用来解决姿态或旋转的问题。对于开源项目点云训练任务,很多都会默认添加一个随机的旋转点云副本。即在数据集中人为的对点云做一些旋转,然后添加到训练数据。这些看似冗余的副本,为网络学习出姿态影响提供了一些可能,但是缺点也是明显的,就是增加了训练任务的计算量,本质又没有添加新的数据。北大王选所的研究人员提出一种点映射特征[1],以获得一种面向点云的旋转不变特征表示。大体的思路是利用奇异值分解,找到一些内蕴坐标方向(如下图),然后重建对点的坐标表示,这样就使得点云的数据表示形式脱离了欧氏空间的限制,获得旋转不变性。
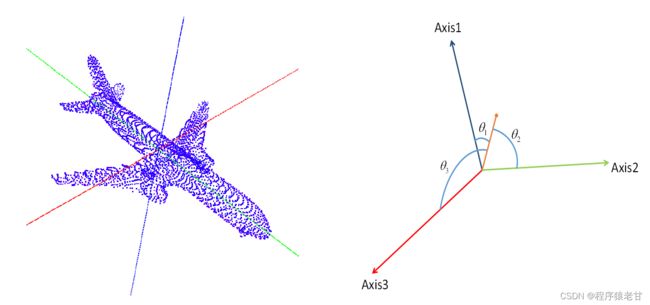
几乎出于完全相同的想法,Li[2]等提出旋转不变的点云分析,通过主成分分析,获得点云的主方向,并依据获取的主方向,选择一个合适的姿态。该方法直接通过主方向对准,实现了对点云姿态影响的消除。实例如下图所示。

三. 插值增强
这里的插值增强主要涉及两个方向,一类是以模型为单位,通过插值生成新的模型,以丰富样本数据;还有一类是通过点插值或密度调整,来生成一些模型副本,以增强点云深度学习模型对于不同点分布数据的学习能力。前边我们已经提到,三维点云的数据集规模不足以支持类似文本图像那类泛化性学习任务。为了能够尽可能的增加点云数据集的样本数,一些研究者提出通过插值的方法生成一些新的模型。假设目前已有的点云数据,对应真实世界模型点分布的一个覆盖区域,那么通过合理插值方法生成的模型应该同样在对应的覆盖区域内,即有语义的新模型。这种数据增强的方式,其难点在于设计合理的插值方法。Chen[4]等提出一种基于推土机距离的模型插值算法,使得插值生成的模型能够对应两个源模型的最短路径,如下图:
另外一种就是向每个点云内部进行点插值或者改变其局部的点分布来生成副本,使得网络能够学习各类点分布对于模型语义判断的规律。代表性的工作包括[5]和[6]。下面两幅图是对点云数据的可视化表达,可以看到通过调整点密度获取的点数。
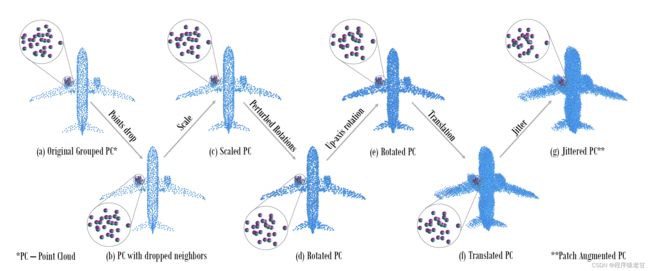
四. 学习增强
除了通过模型生成,来进行直接数据增强外,还有一类方法是通过对学习模型进行两层判定,以实现简间接的数据增强。这类方法的想法是,如果通过训练数据获取的网络结构,不能在测试数据上取得好的结果,那么这些有偏差的结果本身就需要引入到模型的训练中,以指导模型做出对新的分布的估计。代表方法包括[3]和[7]。下图是对两个方法的主干结构说明:
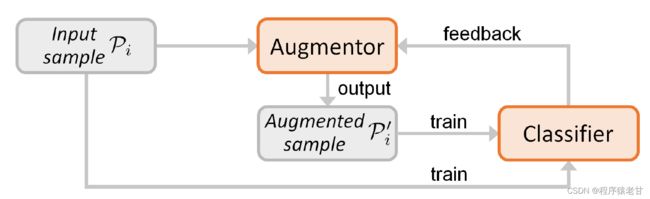
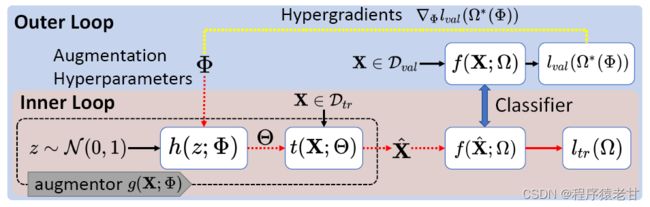
可以看到这两个方法有一个共同的特点,就是在训练分类后,需要加入一个反馈循环,以将分类结果作为二次学习的输入,进行迭代。这样,可被视为对分类器自身的一个反馈式数据增强。
总结
整体来说,基于旋转以及点插值或分布调整的数据增强,在实际使用中的应用更广。基于模型插值的方法,由于仅仅是基于一个全局距离,而忽略了局部语义的对应关系,使得新获取的模型,自身的语义信息被显著的破坏。这种数据增强仅能在有条件的前提下使用。基于学习的数据增强,其最大的问题在于过拟合。因为类似像方法[7],将测试数据与训练数据混合使用,来强化网络,这必然导致其one-shot的性能存在巨大的不确定性。
参考文献
[1] Sun X, Lian Z, Xiao J. Srinet: Learning strictly rotation-invariant representations for point cloud classification and segmentation[C]. Proceedings of the 27th ACM International Conference on Multimedia. 2019: 980-988.
[2] Li F, Fujiwara K, Okura F, et al. A closer look at rotation-invariant deep point cloud analysis[C]. Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 16218-16227.
[3] Li R, Li X, Heng P A, et al. Pointaugment: an auto-augmentation framework for point cloud classification[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020: 6378-6387.
[4] Chen Y, Hu V T, Gavves E, et al. Pointmixup: Augmentation for point clouds[C]//Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part III 16. Springer International Publishing, 2020: 330-345.
[5] Choi J, Song Y, Kwak N. Part-aware data augmentation for 3d object detection in point cloud[C]//2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2021: 3391-3397.
[6] Sheshappanavar SV, Singh VV, Kambhamettu C. Patchaugment: Local neighborhood augmentation in point cloud classification[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 2118-2127.
[7] Zhang W, Xu X, Liu F, et al. On automatic data augmentation for 3D point cloud classification[J]. arXiv preprint arXiv:2112.06029, 2021.