机器学习课程报告——基于机器学习的自动人脸识别研究
摘 要
生物特征识别技术使用了人体本身所固有的生物特征,与传统的身份识别方法完全不同,具有更高的安全性、可靠性、和有效性,越来越受到人们的重视。人脸识别技术作为生物特征识别技术的重要组成部分,在近三十年里得到了广泛的关注和研究,已经成为计算机视觉、模式识别领域的研究热点。人脸识别在公共安全、证件验证、门禁系统、视频监视等领域中都有着广泛的应用前景。
关键词:人脸识别,机器学习,主成分分析。
基于机器学习的自动人脸识别研究
一、针对研究内容采取的具体的技术方案
1.1、具体技术路线
具体的技术路线如下:
(1)读入人脸库;
(2)计算K-L变换的生成矩阵;
(3)利用SVD定理计算特征值和特征向量;
(4)把训练图像和测试图像投影到已得的特征空间中;
(5)比较测试图像和训练图像,确定待识别样本类别。
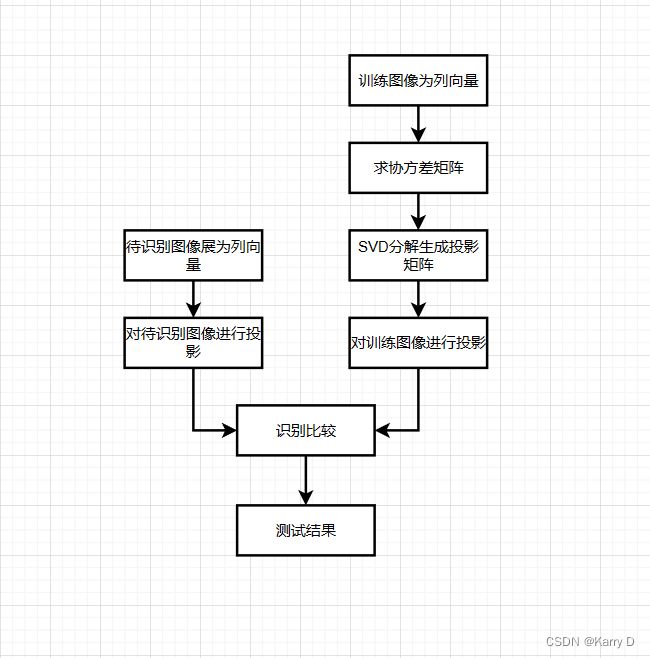
图 1 技术路线图
1.2、算法原理
主成分分析法(PCA)在人脸识别领域成功应用的一个重要理论基础是较好的解决了K.L变换后协方差矩阵的特征向量的求解问题。人脸识别是一个典型的高维小样本问题,即人脸图像向量的维数一般较高, 比如,实验用的人脸库的图像大小为112x92的人脸图像,其对应的图像向量特征空间高达10304维,在如此高维的图像空间内,按照通常的算法,计算样本的协方差矩阵的特征向量是异常耗时的。同时,在人脸识别问题中,由于客观条件的限制,训练样本的数目一般较小,通常,训练样本的总数远远小于人脸图像向量的维数。针对高维小样本的情况,求解特征向量所采取算法的基本思想是,将高维的问题转化为低维的问题加以解决。
主成分分析法(PCA)是模式识别判别分析中最常用的一种线性映射方法, 该方法是根据样本点在多维模式空间的位置分布,以样本点在空间中变化最大方向,即方差最大的方向,作为判别矢量来实现数据的特征提取与数据压缩。主成分分析法的原理如下:
(1)初始化,获得人脸图像的训练集并计算特征脸,定义为人脸空间,存储在模板库中,以便系统进行识别;
(2)输入新的人脸图像,将其映射到已得的特征空间中,得到-一组关于该人脸的特征数据;
(3)通过检查图像与人脸空间的距离判断它是否是人脸;
(4)若为人脸,根据权值判断它是否为数据库中的某个人,并做出具体。
1.3、代码及注释
# 导入库
import os
from numpy import *
#基础数据分析numpy包
import numpy as np
#计算机视觉库 opencv
import cv2
#图像处理库 plt
import matplotlib.pyplot as plt
#绘图库 mpl
from pylab import mpl
#运行配置参数中的字体(font)为黑体(SimHei)
mpl.rcParams['font.sans-serif'] = ['SimHei']
# 图片矢量化,返回图片矢量化后的值
def img2vector(image):
img = cv2.imread(image, 0) # 读取图片
rows, cols = img.shape # 定义变量
imgVector = np.zeros((1, rows * cols)) # 创建零数组
imgVector = np.reshape(img, (1, rows * cols)) # 数组变形
return imgVector # 返回图片矢量化后的值
# 图片数据集路径
orlpath = r"E:\machine learning lesson\bmp"
# 读入人脸库,每个人随机选择k张作为训练集,其余构成测试集
def load_orl(k):
'''
对训练数据集进行数组初始化,用0填充,每张图片尺寸都定为112*92,
现在共有40个人,每个人都选择k张,则整个训练集大小为40*k,112*92
'''
train_face = np.zeros((40 * k, 112 * 92)) # 共有40人,112*92为图像大小
train_label = np.zeros(40 * k) # [0,0,.....0](共40*k个0)
test_face = np.zeros((40 * (10 - k), 112 * 92))
test_label = np.zeros(40 * (10 - k))
# sample=random.sample(range(10),k)#每个人都有的10张照片中,随机选取k张作为训练样本(10个里面随机选取K个成为一个列表)
sample = random.permutation(10) + 1 # 随机排序1-10 (0-9)+1
for i in range(40): # 共有40个人
people_num = i + 1
for j in range(10): # 每个人都有10张照片
image = orlpath + '/s' + str(people_num) + '/' + str(sample[j]) + '.bmp'
# 读取图片并进行矢量化
img = img2vector(image)
if j < k:
# 构成训练集
train_face[i * k + j, :] = img
train_label[i * k + j] = people_num
else:
# 构成测试集
test_face[i * (10 - k) + (j - k), :] = img
test_label[i * (10 - k) + (j - k)] = people_num
return train_face, train_label, test_face, test_label
# 定义PCA算法
def PCA(data, r):
data = np.float32(np.mat(data)) # 处理数据
rows, cols = np.shape(data) # 取大小
data_mean = np.mean(data, 0) # 对列求平均值
A = data - np.tile(data_mean, (rows, 1)) # 将所有样例减去对应均值得到A
C = A * A.T # 得到协方差矩阵 A乘以A的转置
D, V = np.linalg.eig(C) # 求协方差矩阵的特征值和特征向量
V_r = V[:, 0:r] # 按列取前r个特征向量
V_r = A.T * V_r # 小矩阵特征向量向大矩阵特征向量过渡
for i in range(r):
V_r[:, i] = V_r[:, i] / np.linalg.norm(V_r[:, i]) # 特征向量归一化
final_data = A * V_r # 降维后的数据 A乘以归一化的特征向量
return final_data, data_mean, V_r #
# 步骤
# 得到训练集测试集--2DPCA()得到降维后的训练集,平均行,投影阵,--测试集去训练平均,结合投影阵得降维后的测试集
# --按与降维后的训练集的距离分类并统计识别率
# 人脸识别
def face_rec():
for r in range(10, 41, 10): # 最多降到40维,即选取前40个主成分(因为当k=1时,只有40维)
print("当降维到%d时" % (r))
x_value = [] # 绘图x轴 k取值
y_value = [] # 绘图y轴 识别率
for k in range(1, 10):
train_face, train_label, test_face, test_label = load_orl(k) # 得到数据集
# 利用PCA算法进行训练
data_train_new, data_mean, V_r = PCA(train_face, r) # 训练集采取PCA降维
num_train = data_train_new.shape[0] # 训练脸总数
num_test = test_face.shape[0] # 测试脸总数
temp_face = test_face - np.tile(data_mean, (num_test, 1)) # 测试脸与训练数据之间的距离
data_test_new = temp_face * V_r # 得到测试脸在特征向量下的数据
data_test_new = np.array(data_test_new) # 矩阵化
data_train_new = np.array(data_train_new) # 矩阵化
# 测试准确度
true_num = 0
for i in range(num_test):
testFace = data_test_new[i, :] # 取值
diffMat = data_train_new - np.tile(testFace, (num_train, 1)) # 训练数据与测试脸之间距离
sqDiffMat = diffMat ** 2 # 平方
sqDistances = sqDiffMat.sum(axis=1) # 按行求和
sortedDistIndicies = sqDistances.argsort() # 对向量从小到大排序,使用的是索引值,得到一个向量
indexMin = sortedDistIndicies[0] # 距离最近的索引
if train_label[indexMin] == test_label[i]: # 判断是否正确
true_num += 1 # 若正确则加1
else:
pass # 否则跳过
accuracy = float(true_num) / num_test # 正确值除以测试总值
x_value.append(k)
y_value.append(round(accuracy, 2))
print('当每个人选择%d张照片进行训练时,The classify accuracy is: %.2f%%' % (k, accuracy * 100)) # 输出准确值
# 绘图
if r == 10: # 判断
y1_value = y_value
plt.plot(x_value, y_value, marker="o", markerfacecolor="red")
for a, b in zip(x_value, y_value): # 同时遍历两个数组
plt.text(a, b, (a, b), ha='center', va='bottom', fontsize=10)
plt.title("降到10维时识别准确率", fontsize=14) # 标题"降到10维时识别准确率"
plt.xlabel("K值", fontsize=14) # x轴"K值"
plt.ylabel("准确率", fontsize=14) # y轴"准确率"
plt.show() # 绘图
if r == 20:
y2_value = y_value
plt.plot(x_value, y2_value, marker="o", markerfacecolor="red")
for a, b in zip(x_value, y_value):
plt.text(a, b, (a, b), ha='center', va='bottom', fontsize=10)
plt.title("降到20维时识别准确率", fontsize=14)
plt.xlabel("K值", fontsize=14)
plt.ylabel("准确率", fontsize=14)
plt.show()
if r == 30:
y3_value = y_value
plt.plot(x_value, y3_value, marker="o", markerfacecolor="red")
for a, b in zip(x_value, y_value):
plt.text(a, b, (a, b), ha='center', va='bottom', fontsize=10)
plt.title("降到30维时识别准确率", fontsize=14)
plt.xlabel("K值", fontsize=14)
plt.ylabel("准确率", fontsize=14)
plt.show()
if r == 40:
y4_value = y_value
plt.plot(x_value, y4_value, marker="o", markerfacecolor="red")
for a, b in zip(x_value, y_value):
plt.text(a, b, (a, b), ha='center', va='bottom', fontsize=10)
plt.title("降到40维时识别准确率", fontsize=14)
plt.xlabel("K值", fontsize=14)
plt.ylabel("准确率", fontsize=14)
plt.show()
# 各维度下准确度比较
L1, = plt.plot(x_value, y1_value, marker="o", markerfacecolor="red")
L2, = plt.plot(x_value, y2_value, marker="o", markerfacecolor="red")
L3, = plt.plot(x_value, y3_value, marker="o", markerfacecolor="red")
L4, = plt.plot(x_value, y4_value, marker="o", markerfacecolor="red")
# for a, b in zip(x_value, y1_value):
# plt.text(a,b,(a,b),ha='center', va='bottom', fontsize=10)
plt.legend([L1, L2, L3, L4], ["降到10维", "降到20维", "降到30维", "降到40维"], loc=4)
plt.title("各维度识别准确率比较", fontsize=14)
plt.xlabel("K值", fontsize=14)
plt.ylabel("准确率", fontsize=14)
plt.show()
if __name__ == '__main__':
face_rec()
二、实验及结果分析
2.1、实验数据
本次实验使用数据集为40个人的人脸,每个人共有10张人脸的照片。
2.2、实验环境
操作系统:Win10
调试软件名称:pycharm
Python解释器:conda python3.9
2.3、实验结果
当降维到10时
当每个人选择1张照片进行训练时,The classify accuracy is: 60.56%
当每个人选择2张照片进行训练时,The classify accuracy is: 79.69%
当每个人选择3张照片进行训练时,The classify accuracy is: 87.50%
当每个人选择4张照片进行训练时,The classify accuracy is: 84.17%
当每个人选择5张照片进行训练时,The classify accuracy is: 92.50%
当每个人选择6张照片进行训练时,The classify accuracy is: 96.88%
当每个人选择7张照片进行训练时,The classify accuracy is: 90.00%
当每个人选择8张照片进行训练时,The classify accuracy is: 93.75%
当每个人选择9张照片进行训练时,The classify accuracy is: 95.00%
当降维到20时
当每个人选择1张照片进行训练时,The classify accuracy is: 67.78%
当每个人选择2张照片进行训练时,The classify accuracy is: 82.81%
当每个人选择3张照片进行训练时,The classify accuracy is: 81.07%
当每个人选择4张照片进行训练时,The classify accuracy is: 88.75%
当每个人选择5张照片进行训练时,The classify accuracy is: 91.50%
当每个人选择6张照片进行训练时,The classify accuracy is: 95.00%
当每个人选择7张照片进行训练时,The classify accuracy is: 95.00%
当每个人选择8张照片进行训练时,The classify accuracy is: 95.00%
当每个人选择9张照片进行训练时,The classify accuracy is: 100.00%
当降维到30时
当每个人选择1张照片进行训练时,The classify accuracy is: 66.67%
当每个人选择2张照片进行训练时,The classify accuracy is: 75.31%
当每个人选择3张照片进行训练时,The classify accuracy is: 87.50%
当每个人选择4张照片进行训练时,The classify accuracy is: 92.08%
当每个人选择5张照片进行训练时,The classify accuracy is: 95.50%
当每个人选择6张照片进行训练时,The classify accuracy is: 93.75%
当每个人选择7张照片进行训练时,The classify accuracy is: 97.50%
当每个人选择8张照片进行训练时,The classify accuracy is: 98.75%
当每个人选择9张照片进行训练时,The classify accuracy is: 100.00%
当降维到40时
当每个人选择1张照片进行训练时,The classify accuracy is: 71.39%
当每个人选择2张照片进行训练时,The classify accuracy is: 75.31%
当每个人选择3张照片进行训练时,The classify accuracy is: 85.71%
当每个人选择4张照片进行训练时,The classify accuracy is: 91.25%
当每个人选择5张照片进行训练时,The classify accuracy is: 92.50%
当每个人选择6张照片进行训练时,The classify accuracy is: 97.50%
当每个人选择7张照片进行训练时,The classify accuracy is: 96.67%
当每个人选择8张照片进行训练时,The classify accuracy is: 100.00%
当每个人选择9张照片进行训练时,The classify accuracy is: 100.00%
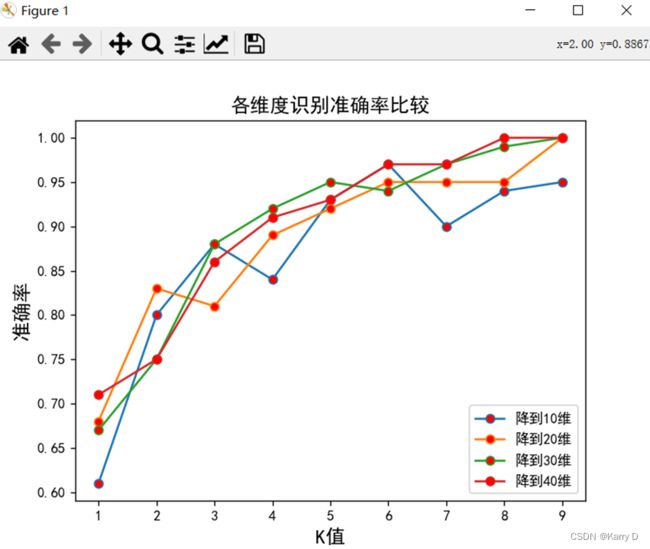
图 2 各维度识别准确率
2.4、实验分析
实验结果各维度识别准确率随着选择照片数量的增加而变大,最终准确率都大于90%。而所降维数之间比较,准确率随着下降维数的增加也有增加。
三、遇到的问题
3.1、寻找新的数据集
在网上搜索时发现了kaggle网站(机器学习、数据分析免费学习平台),从中可以免费下载到机器学习时需要用的数据集,不过由于是国外的网站,在通过Gmail邮箱注册,使用自己的邮箱注册会遇到无法显示人机验证码的问题,在通过搜索资料之后,通过安装浏览器插件Header Editor的方式解决了注册问题,同时下载到了数据集。
3.2、将新的数据集应用到我的模型之中
首先解决如何导入新的数据集,不仅更改图片数据集的路径,还得更改对应的人数,和对应人数图片数量的参数,在这里通过一个两人,每人五张图片的数据集进行一个小测试(仅针对导入数据集的前半部分代码)。如下图3所示。
图 3 测试正常运行图片
3.3、将后面代码补全后遇到的问题
IndexError: index 2 is out of bounds for axis 1 with size 2(索引超出了列表的长度)。如下图4所示。

图 4 运行所遇到的问题
3.4、解决问题
索引超出了列表的长度的问题,通过仔细查看后面的代码得出是在face_rec()函数中应用PCA算法时,索引超过了列表的长度,再经过修改参数之后可以运行如下图5所示
图 5 正常运行
3.5、替换为从网上下载的全部数据集
将数据集替换为从网上下载的全部数据集(经调整后为50人,每人10张照片)后运行,运行结果如图6所示。
替换数据集后的实验结果与之前的比较可得出类似结论:
各维度识别准确率随着选择照片数量的增加而变大,最终准确率都大于90%。而所降维数之间比较,准确率随着下降维数的增加也有增加。

图 6 正常运行
四、总结
人脸识别具有重大的理论意义和应用意义,它是一项结合了多学科,多领域知识方法的技术。长期以来,如何利用计算机进行准确,快速的人脸识别,一直是图像处理与模式识别的研究热点与难点。社会的发展促进了身份认证技术市场的急速扩大,人脸识别因其自身的优点,在身份认证中的使用日益频繁。人脸识别技术具有广泛的社会需求和市场前景。
本文介绍了针对人脸识别系统内容采取的具体的技术方案,对主成分分析方法作了详细介绍,并运用其设计出人脸识别程序。本文所做的主要工作归纳如下:
(1) 详细介绍了人脸识别的流程、主成分分析方法(PCA)以及其原理, 使用主成分分析方法设计出人脸识别程序。
(2)完整详细介绍了人脸识别的程序及代码。
(3)介绍了实验数据、实验环境、实验结果以及实验分析。
(4)介绍了本次实验中所遇到的问题以及解决问题的方法
(5) 介绍了尝试采用不同的数据集后的实验结果。
五、展望
传统的人脸识别技术主要是基于可见光图像的人脸识别,这也是人们最熟悉的识别方式,已有30多年的研发历史。但这种方式有着难以克服的缺陷,尤其在环境光照发生变化时,识别效果会急剧下降,无法满足实际系统的需要。解决光照问题的方案有三维图像,人脸识别,和热成像人脸识别。但目前这两种技术还远不成熟,识别效果不尽人意。
最近迅速发展起来的一种解决方案是基于主动近红外图像的多光源人脸识别技术。它可以克服光线变化的影响,已经取得了卓越的识别性能,在精度、稳定性和速度方面的整体系统性能超过三维图像人脸识别。这项技术在近两三年发展迅速,使人脸识别技术逐渐走向实用化。
六、自我评价
我认为此次学习设计充满挑战和机遇,就我自身而言,我认为我存在专业知识不够扎实,工作不够细致等不足之处,还需在实践中不断学习,不断进步。通过此次学习设计,我深刻的认识到了自己身上的不足之处,本身能力的不足,虽然这次活动确实充满乐趣,但我也深刻明白了发展自己才是硬道理的,我相信在我的脑袋里,如果有更加的多的知识时,我对这些设计更加得心应手。
参考文献
[1]倪世贵,白宝钢.基于PCA的人脸识别研究.现代计算机2011. 02
[2]齐怀峰.基于特征脸的人脸检测与识别、云南师范大学学报, 2005.
[3]张辉.K-L变换在人脸识别特征提取中的应用,学术交流,2008.
[4]黎奎,宋宇.基于特征脸和BP神经网络的人脸识别. 计算机应用研究.
[5]聂祥飞.人脸识别综述.重庆三峡学院学报,2009.
[6]朱金魁.人脸识别算法的研究.东北林业大学硕士论文.2009.
[7]王志良,孟秀燕.人脸工程学(第一版) .北京:机械工业出版社,2008.
[8]安贝.基于K-L变换的人脸识别方法、 四川大学硕士论文. 2005.
[9]邓迎宾.人脸识别关键技术研究.昆明理工大学硕士论文. 2007.
[10]于清澄.基于K-L变换的人脸识别算法研究.沈阳工业大学硕士论文. 2007.