Photon论文解读 : A Fast Query Engine for Lakehouse Systems
这篇论文是databricks公司首次将内部的基于c++的native执行引擎细节发表在SIGMOD 2022,作者公共23人,论文地址:
https://www-cs.stanford.edu/~matei/papers/2022/sigmod_photon.pdfwww-cs.stanford.edu/~matei/papers/2022/sigmod_photon.pdf
本文不是对论文的翻译,而是将论文中详细的设计和细节拿出来记录。
简介:
论文首先阐述了lakehouse的作用。首先,企业会将大量数据存储在弹性、可扩展的data lake上比如amazon s3、azure data lake storage,google cloud storage等,这些数据可能是以apache parquet、orc、delta lake等open file format存储的raw、uncurated datasets,客户/用户可以通过presto,spark等计算引擎访问,工作负载包括BI,ml等。
其次,为了获取更高的性能、数据治理,企业会通过ETL把部分数据从data lake上传输到data warehouse(比如apache hive)中,实际这是一个两层的存储架构,这样带来的成本显而易见。
所以,出现了所以lakehouse(databrick的产品就是Delta Lake)基于对象存储构建了data warehouse的能力,比如统一的数据访问、数据治理、SQL支持等,这样的单层架构对于用户访问数据非常友好。为了更好的查询performance,delta lake做了不少的优化,比如transactions和time travel,data clustering和data skipping indeices等。但是仅仅在存储层努力是不够的,还需要在query engine 这层努力,这就是本论文要阐述的photon。
Photon主要的挑战:
1)与传统的data warehouse上的执行引擎不同,photon需要解决新问题,就是raw、uncurated data(可以理解为不规则数据),其特性是:可能存在是highly irregular datasets,poor physical layout,large fields,no useful clustering or data statistics,string来代表date或者int,数据缺失值不一定用NULL填充而是默认值等等。
这个其实就是在机器学习、深度学习的场景,样本数据就是上面提到的raw uncurated data,比如展现字段通常比较大,点击数据也比较稀疏,feature log dump的数据也比较大等等。对比之前的非常规整的交易数据,DL场景的数据会更加不规则和缺少统计信息,因此对于计算引擎并不友好。
为了解决这个问题,photon是使用vectorized-interpreted model,而不是code generation(spark基于code generation) 。
所谓vectorized-interpreted,就是monetdb/x100的执行模型,内存列存格式和批处理,这样可以很方便利用CPU SIMD等指令,减少单次处理数据带来的IO overhead,减少虚函数调用次数等额外开销等等有诸多好处。
2)希望支持已有的spark,并且语义兼容,表现在SQL兼容和dataframe API兼容,也就是说对于上层用户来讲是透明的。
这点是为了留住客户,如果说这套引擎不兼容spark api和sql,那么可想而知,客户反馈肯定是非常差的。所以为了解决这个问题,photon是整合到了spark框架中的,与已有的spark api和sql完全兼容。大体来说,Databricks有一个从apache spark fork的一个databricks runtime(DBR),加入了更多的优化和改进。photon从算子层面重写然后fit into DBR,作为query plan的执行者,这样即使有部分算子photon不支持可以fall back to DBR。从这点来说,photon只是在算子级别实现了vectorized query engine,外层的DBR依然是已有的架构,DBR实现了query optimization,memory manager,IO,monitoring,photon需要与这些组件交互。
这点当然也限制了photon的发挥,因为spark是row-based处理数据,那么中间必然有row到column的相互转换,而且内存管理部分也需要与JVM交互, 增加了实现复杂度。
3)性能更好,spark基于JVM,集群负载是cpu bounding,因此转向c++实现。
这毫无疑问,随着硬件发展目前计算引擎已经从早期的io bounding转向了cpu bounding,我们的集群也是如此,因此如果重构必然要基于c++重写,另外一个例证是presto也在基于c++做native query engine。现在的趋势就是基于c++或者rust构建native的执行引擎,未来jvm的执行引擎可能会逐渐淡出历史舞台完成其历史使命,在大数据早期因为受限于磁盘或者网络,整个系统的瓶颈往往在IO,因此jvm构建是合适的,可以更快的构建出产品比如hadoop spark presto等。
目前网络普遍在20Gbps甚至50G/100G,RDMA技术,磁盘也从早期的HDD发展到SSD,傲腾等带宽更大、延迟更低,加上软件上的异步预取、cache、并行计算等技术,IO瓶颈已经基本消除。CPU重新成为瓶颈。
另外一方面,c++、rust、llvm等语言和工具链更加成熟,所以,在大数据领域出现类似impala、clickhouse、datafusion等native的执行引擎,未来会逐步扩大其scope,成为更加高效的解决方案。
总体来说,photon是基于c++实现的vectorized query engine,语义和内存管理兼容spark,并且在raw, uncurated data上做了大量优化。
背景
Databricks的Lakehouse整体架构
总体上存算分离,分为4个部分,
1· raw data storage,允许用户选择独立的low cost storage,比如S3,ADLS,GCS,主要是防止客户data lock-in和昂贵的迁移成本,databricks提供各种connector来访问不同的底层存储,数据本身的格式也可能有多种,比如parquet,orc等等。
2.automatic data management,这层就是Delta Lake,基于云对象存储实现了数仓的特性,ACID,time travel,audit logging,fast metadata over tabular datasets,DetaLake的data 和metadata 都是基于parquet格式存储,实现了auto data clustering,cacheing等。
3.弹性执行层,下图展示了执行层架构,这层逻辑上实现了“数据面”,所有的数据处理都在这层完成,包括internal query,比如auto data-clustering metadata access,还有客户的queries,比如ETL,SQL,ML等。每天大概有EB的数据被处理,可以看出databricks的客户挺多的,这层需要弹性、可靠性高、性能好。Photon就是通过处理单线层的query执行on each partition of data迁入到执行层中。执行层是跑在云厂商提供的VM上,这个就是spark的典型架构了,包括driver,负责协调,若干executor负责read and process data,driver和executor组成了DBR。

Lakehouse整体架构
4.UI层,不解释。
The Databricks Runtime(DBR)
DBR是在开源的apache spark上进行了改进和优化,photon是DBR的lowest level,处理single thread task with in the context of DBR's multi-threaded shared-nothing execution model.
下面是简单的DBR任务提交过程,跟spark一样,简单重复下。提交到DBR的应用被称为jobs,每个job按照宽依赖被分层stages,stage被换分层tasks,每个task对应数据的一个分区partition。stages之间blocking,串行执行,下游stage读取上有的数据输出,按照stage进行容错或者自适应执行(spark3里的AQE)。DBR用单节点的driver进行调度,query planning,以及其他中央化的工作,driver管理1到多个executor node,每个node运行多个task,每个task进行数据读取、变化、输出。
SQL query也是使用DBR这套架构,driver负责对SQL文本或者使用dataframe API生成的dataframe object转换成query plan。Query plan就是tree of SQL operators(比如filter, project, shuffle) that maps to a lists of stages.在query planning之后,driver就提交task执行各个stages,每个task运行in-memory execution engine来处理数据集。Photon就是类似的执行引擎。
Phonton的设计要点
总体上,photon是用c++实现的一个列式、批处理也就是vectorized query engine,以shared lib迁入到DBR,run as part of single-threaded task in DBR within an executor's JVM process. 类似DBR,photon也是把SQL用tree of operator来表示,每个op实现HasNext()/GetNext()接口,从每个child pull data,这个api也用来跟JVM上的operator通信。每个op内部使用列式、向量化(也就是批)来处理数据,这个与JVM的op以code generation的模式、row based是有差别的,因此在photon与JVM算子的边界上需要做数据格式的转换。下面详细展开。
- JVM vs Native execution
这个就简单说下上面已经说了不少,论文里也提到了目前集群都是cpu bounding,原因1是ssd cache,2是delta lake有很多IO优化,比如data clustering,3是新的工作负载数据本身是un-normalized,large strings,unstructured nested data,因此更看中性能。所有这些带来的后果是JVM base execution engine成为瓶颈。
JVM大内存GC->off heap op->code难维护,java code generation受限于generated method size, or code cache size,有可能fall back到far slower的volcano-style interpreted code path。
因此选择native实现,这点也可以理解,clickhouse已经在这块做的非常成功了,apache doris也发布了vectorized execution engine。
2. interpreted vectorization vs code-gen
这里的主要问题是计算框架采用向量化还是code gen?前者代表论文是monetdb/x100,后者代表论文是hyper。前者的实现代表是clickhouse,monetdb,后者是spark sql,hyper,impala等。前者优点是,可以利用批处理以弱化虚函数调用开销、SIMD指令、CPU pipeline和内存友好。后者是在volcano style基础上完全消除了虚拟函数开销。最终photon选择前者,他们基于weld作code-generation,做了POC验证,得出的结论是:
易于开发和scale,可观测性更强,易于适应changing data,specialization is still possible。具体就不展开了,可以去看论文。这两种方法其实是可以结合的,在clickhouse的blog中就有过阐述,也有一篇论文说这个事情,框架采用vectorization,具体到表达式计算可以采用code-gen,这样性能是最高的。
3. row vs column-oriented execution
phonton中采用了列存内存模型,而不是spark的行存模型,主要理由是列存方便使用SIMD指令处理、更高效的pipelining、序列化(传输or spill),数据源本身也是列存模型,比如parquet等,维护内存字典优化内存等。
4.partial roll out
这个要解决的点是如何在不影响已有workload的情况下透明上线,因为databricks上面跑了很多客户的sql或者是dataframe api的代码。photon需要做到的是如果部分算子还没有实现,那么需要能fallback到老的代码,不影响query的执行,接下来的重点是如何与jvm base的DBR整合以实现这个目标,具体设计在下面。
Vectorized Execution in Photon
首先看下batched columnar data layout,典型的布局,如下图,

注意这里除了按照列去存储连续数据外,还增加了position list列,用来指示active rows(not filtered,也就是有效数据)。另外一种设计是设计一个bitmap来指示,但是论文说这种情况在某些场景下会导致整体性能下降。
Vectorized Execution Kernels
这就是计算图的实现,图的节点是operator,数据在图中流动,TensorFlow也是类似的设计,x100首先提出该思想,op的处理粒度是vector of data,也就是向量化的数据,下面有个kernel的实现感受下,

注意参数里的RESTRICT关键字,这意思是参数指针地址都不同,因此编译器可以做更多优化,在clickhouse里大概提升了平均20%的性能。
Filters和conditionals的实现是通过修改position list of a column batch。
Vectorized hash table,这里实现了vectorized access,查询氛围3步,1是基于batch数据算hash,2是一个probe kernel跟进hash value load pointer(指向value,注意这里的value是行存),3是跟左表的probe过程,这里也是向量化操作的。所以3步都是可以做向量化操作引入SIMD,性能很高。
自适应执行 Adaptive execution
在lakehouse中的一大挑战就是缺少统计信息,元信息,以及normalization,因此在此类数据集上的高效执行是个挑战。Phonton的解决方法是支持batch level adaptivity,也就是说在batch size data的小数据上实现数据统计,元信息构建以此来优化kernel执行。
内存管理,photon实现内存池,这里是基操了,对于定长数据做了most-recentaly-used cache,变长数据独立处理,这里主要思想是跟进数据大小、模式分级精细化管理。而且要与spark框架集成。下面重点讨论如何与DBR集成。
Integration with DBR
Photon必须要与DBR进行集成,这里主要讨论的是query planner and memory management。
首先讨论对spark sql的支持,这里做的事就是convert spark plans to photon plans,具体做法是在catalyst里面加入转换规则,规则处理如下:1是walk the input plan bottom up,然后map spark的node到Photon node。如果一个node在photon中不支持的话就插入一个transition node负责将列批数据转换成row-wise format这个legacy系统是在DBR里执行的,需要注意的是要避免过多的此类转换,否则代价太高了。2是在file scan和first photon node间插入一个adaptor node用来将文件读取的数据转成列存数据,这里用了zero copy技术,因为parquet本身也是列存的。下图是个例子:

Executing Phonton Plans
在做完query planning后,DBR会启动tasks按照stages执行plan,photon执行结点首先将photon part 到一个PB消息中,通过JNI传输到photon c++ lib,后者反序列化PB消息并执行,执行的过程跟JVM的过程类似,每个算子实现HasNext()/GetNext()接口,父节点以列批pull data from 子节点。对于plan中有data exchange的点,photon会按照spark shuffle格式写一份数据,并把metadata传递给spark。spark框架执行shuffle,然后启动新的photon task来读数据,这里注意的是数据序列化和反序列化一致性。
Adapter node to read scan data。photon的leaf node总是adapter node,这个node拿到spark的scan node获取的列存数据(因为数据源是列存的格式比如parquet),adapter node的GetNext()函数就是调用JNI从spark的OffheapColumnVecto中拿数据,这里传递了2个pointer,1是列存数据,2是NULL数组,每次JNI的调用代价大概是c++虚拟函数调用代价23ns per call。这样也就实现了上文提到的数据读取做到zero copy。
Transition node to pass photon data to spark。photon的last node是transition node,必须将列批数据转成row-wise格式供spark算子后续处理。注意的是这里的转换是成本很大的,所以不能做太多,photon后续还会持续改进这里。
Unified Memory Management
因为photon是以share lib方式迁入到JVM进程中,因此必须要hooks into apache spark的内存管理。为了解决这个问题,photon团队将memory reservation和memory allocation分开处理。memory reservation是向spark unified memory management要求内存,这个操作可能引发spill,也就是spark会向memory consumer释放内存以满足新的要求,这个动作会导致data spill。photon也是在这套体系中的,也就是说可能引发self spill。在photon内部也是依据已有的策略来确定哪个memory consumer spill,思路是比如要reserve N bytes,按照consumer的memory size从小到大排序,最后选择第一个大于N bytes的consumer来spill,原因是尽量减少consumer的spill次数,从而提升整体性能。一旦photon reserve内存成功,就可以成功进行内存的开辟无需spill。
所以在photon spilling operator比如hash join,group by等,对于输入数据的处理分为2个阶段,第一阶段是内存的reservation,第二阶段是allocation阶段,这样再第二阶段不会发生spill,这样就保证了当前op的高效处理,photon团队也强调这样的策略很关键,因为在context中数据量经常很大如果说在处理当前op经常会发生spill的话,整个流程就又卡磁盘IO了,并不能发挥出向量化执行引擎优势。
Managing On-heap vs Off-heap memory
spark有个静态的max offheap size的配置用来限制每个节点可以分配的堆外内存,photon主要使用堆外内存,因此不会被GC影响,但是有个场景是broadcast(比如broadcast hash join),photon还是需要依赖框架的broadcast机制,这样需要photon堆外内存copy到堆内存,这里可能引发OOM,photon做法是增加1个listener在query执行结束后清理部分自身的state来释放内存。
与其他部分的融合与兼容性
最后讨论下photon与DBR和开源的spark结合问题。因为photon只是对plan部分进行了改变,所以spark框架上做的很多事情依然可以复用,比如AQE,还有就是photon的metrics也与已有的兼容,可观测性比较好 。
在语义兼容方面,为了做到与spark和DBR完全兼容,photon使用unit tests,end to end tests,fuzz tests来综合保证。
效果评估
得益于:列存格式、向量化、SIMD指令、runtime adaptivity,photon的主要加速场景是cpu heavy的,比如,join,aggregation,expression evaluation,另外还可以加速其他场景比如写parquet文件,对于network io 或者disk io bounding场景加速其实不明显。下图是各种测试,
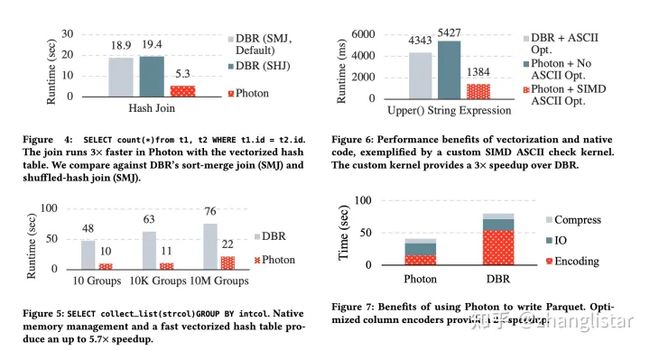

注意photon目前只支持shuffle hash join,不支持sort merge join。spark的shuffle hash join也是不支持spill的,因为spill会带来大量随机IO,所以spark会用sort merge join来应对大量数据join。
关于JVM的转换代价,photon团队也做了测试,从内存的列存int类型数据读,整体执行时间0.06%损耗在JNI-internal methods,0.2%损耗在adapter node。总体看JNI或者转换没有太大代价。
相比DBR,photon另外一块比较优势的点就是runtime adaptivity:1)adapting to sparse batches
有些场景下有很多数据是比较稀疏的,比如ML,photon会在每个batch上track列数据的稀疏性,在做join probe的时候在稀疏列上会进行compact增加内存吞吐,还有如果不做compact会比DBR差,因为稀疏数据导致了high overhead,然而DBR因为通过code-gen方式消除了虚函数调用开销尽管是tuple at time。这也是需要针对稀疏数据进行compact的原因。效果如下图:

2)adaptive string encoding,
shuffle是性能杀手,所以photon进行了优化来减少shuffle数据大小,手段主要是1)缩小uuid数据宽度,默认uuid是36B,优化到128bit表示,类似ML里的量化,
2)在shuffle写前加lz4压缩,另外压缩也会导致内存占用较小从而避免spill,当然代价是多耗费一点cpu。下图是效果:

总结
photon团队从现实出发,实现了spark的向量化处理、微批adaptivity,与已有DBR和spark兼容,在cpu heavy的场景提升非常明显,国内也有一些公司做了类似的尝试比如阿里云、第四范式等,从效果看非常不错。工作量可以看到不小,论文是Matei领衔23人完成,需要一个工程能力很强的团队。
从计算引擎的角度看,photon未必是state-of-art,受限于现实原因,photon必须要嵌入到DBR中,大量与JVM交互,数据格式也需要列与行互转,带来一定的overhead。
另外一条路,个人认为是基于clickhouse/doris来演进,首先实现与hive数仓或者数据湖的整合,其次,支持shuffle和spill,再次通过写checkpoint或者其他技术增强容错能力。无论哪条路工程量都是巨大。