链表3 分析最优链表结构:带头双向循环链表
目录
(一)用途
1.链表定义:
2.应用场景:
(二) 结构优化的思想
(1)把能推理出的未知化成已知。
(2)统一。
(三)实现技巧
1.结构与图解
2.复用及源码剖析
【任意位置插入】
【任意位置删除】
3.实参与形参
1.对比单链表和双向带头循环链表结构特点。
2.传一级指针还是二级指针:看结构!!!
4.野指针问题
(1)野指针问题造成的根源:
(2)原理:
(3)一级指针在函数内置空效果:
(4)解决办法:
5.断言检查
1.场景:
2.介绍:
(四)源码实现
下面一起撸一个双向带头循环链表吧!!
1.首先在Dlist.h里设计一个基本框架
基本接口逻辑:
核心接口:插入和删除
常用接口
最后再补充一下测试部分test.c
(四)应用
C++STL中 list 的模拟实现,此处再下篇博客将会补充。
如有错误,请多多指正!
(一)用途
1.链表定义:
链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
2.应用场景:
带头双向循环链表对于链表的定义而言是最优的。单独使用一个链表,首选带头双向循环链表。它集三种性质于一身:带头,双向,循环。论及链表的种类,如果排列组合,可达八种。本文所介绍的就是最优的链表结构。
但论及应用范围往往就不是最优的。这时单链表的作用就发挥了,单链表可以作为图的邻接表,哈希桶等结构的子结构,虽然单一使用很麻烦,但是复合使用在很多方面都很便利。
(二) 结构优化的思想
(1)把能推理出的未知化成已知。
已知越少,求解未知经历的环节就越多。反之,已知越多,求解未知的环节就越少,所以解决问题就越容易。我们增添了prev指针,我们就减少单链表标记前驱节点所需要的遍历,化O(N)时间复杂度尾O(1)。再比如无头的单链表,导致我们每次操作完,都要重新转换头的地址。所以就设置了一个虚拟头。化不定为定。类似于使用二级结论
(2)统一。
只有一个节点的链表和有若干节点的链表是否能够统一。是看待角度的问题。哨兵头就是尾。头尾节点和普通节点是否能够统一。所以设置链表的循环结构统一了头尾。
(三)实现技巧
1.结构与图解
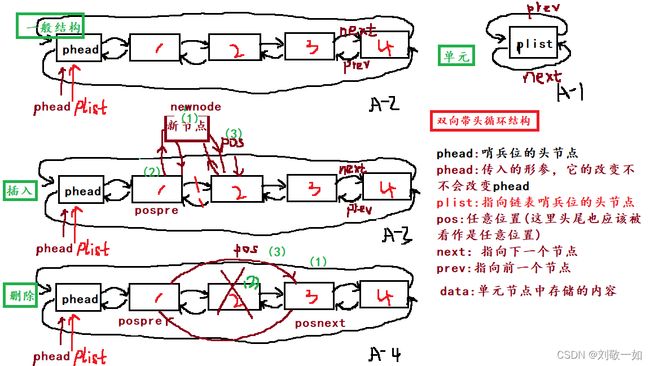
首先了解一下双向带头循环链表(下文中简称DHClist,只用于叙述简便)的结构单元:
如图A-1:节点的前指针和后指针都指向自己,有三个属性(data+prev+next)
如图A-2:a:这是一个一般的DHClist,我们在接口传参传入的plist是一个形参,可以看成一个灵活可变的phead的复制。这个我们叫它哨兵位的头节点,是我们定义的头。而真正的头节点是谁呢?是phead->next。
b:通过观察,我们发现哨兵位的头节点phead总是不变的,而且从哨兵位的下一个结点开始(才是真正意义上的第一个节点)每个结点的结构都是相同的,都通过pre和next与其他节点相连。正是因为每个节点的结构相同,所以头和尾可以也可看成是任意位置pos。那么头插和尾插也可看成是任意位置插入。头删和尾删可以看成任意位置删除。这就是可以实现复用的结构原因。
c:再观察,我们可以发现链表是一个特殊的环结构(从phead的next为例,顺着箭头看)phead是我们人为定义的链表的头。其实这个环就看作从phead开始,循环回到phead,那么链表的尾呢?从图上看phead->prev指向的是尾,这就很有意思,先记住这个小结论,就是说头的“上一个是尾,尾的下一个是头"。证明了该链表是环结构。在phead前插入也就是等同于尾插!
如图A-3:【任意位置插入】当我们在任意位置pos前插入一个节点时,(1)首先要新建一个节点
newnode(2)先处理pospre.pospre->next=newnode;然后newnode-prev=pospre;(3)再处理
pos. newnode->next=pos;然后 pos->prev=newnode;
如图A-4:【任意位置删除】要删除一个节点后,我们需要将待删除位置 pos,前一个结点和后一个
结点重新连接。所以我们(1)首先要重新标记.pos前结点为(pospre)和pos后结点(posnext)
(2)释放掉pos结点。free(pos); (3)处理前后节点关系。 pospre->next=posnext;
posnext->pre=pospre。(4)处理野指针问题。free(phead);在调用结束后添加plist=NULL;后面会详细说)
2.复用及源码剖析
下面我们来组织一下代码
【任意位置插入】
//在pos前插入
void ListInsert(ListNode* pos, DataType x)
{ //posprev newnode pos
assert(pos);
ListNode* newnode = SetNode(x);//标记
ListNode* posprev = pos->prev;
posprev->next = newnode;//处理posprev
newnode->prev = posprev;
newnode->next = pos;//处理pos
pos->prev = newnode;
}改写头插,尾插
//改写头插
void PushFront(ListNode* phead, DataType x)
{
assert(phead);
ListInsert(phead->next, x);//哨兵位节点下一个才是真正意义上的头
}
//改写尾插
void PushBack(ListNode* phead, DataType x)
{
assert(phead);
ListInsert(phead, x); //phead->pre就是尾
}通过上图我们再来回顾一下,单链表中头插和尾插
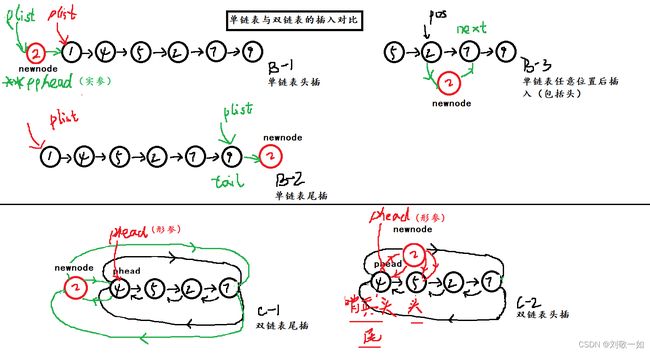
通过对比插入的异同,我们来总结一下,双向带头循环链表对问题的优化。
1.首先,双向带头链表能实现完全的复用,说明其结构特点的优势。(环链表的优势)
2.双向带头循环链表能不需要检查,链表为空的情况。因为初始化的时候链表中已经新建了一个节点。(体现哨兵头的作用)。但在单链表中,如果链表为空是要初始化的。(带头的优势)
3.删除时记录prev节点不需再重新遍历一次,而直接用前驱节点记录。(双向的优势)
下面来回顾一下代码吧
//尾插
void SListPushBack(SLTNode** pphead, SLTDataType x)
{
assert(pphead);
if (*pphead == NULL)//链表为空的情形
{
SLTNode* newnode = BuySListNode(x);
*pphead = newnode;
}
else
{
SLTNode* newnode = BuySListNode(x);
SLTNode* tail = *pphead;
while (tail->next != NULL)//找尾
{
tail = tail->next;
}
tail->next = newnode;//连接
}
}【任意位置删除】
//删除pos位置
void ListErase(LTNode* pos)
{
assert(pos);
//pospre pos posnext
ListNode* prev = pos->prev;
ListNode* next = pos->next;//标记pos前后节点
free(pos);
pos = NULL; //(1)此处多余,没必要置空
prev->next = next;//处理删后连接问题
next->prev = prev;
}通过对比分析删除与插入,我们来总结一下,双向带头循环链表不能优化的内存问题:
1.删除操作有两个注意的问题:空链表不能进行删除操作,要设置空链表报错。
处理新建节点的内存释放问题。要保证是释放实参,才能把内存还给系统。
2.双向带头循环链表在经历三个优化后,面对“删除操作”,与插入不同。还要处理1.中提到
的两个内存问题。即不能非法访问,不能内存泄漏。
简记:(检查),标记,释放,(置空),连接。
3.体现了效率问题往往可以通过优化结构和设计算法来解决,但内存问题的优化应该站在硬件的角度上考虑。这可能是另一个维度。
改写头删,尾删复用Erease的代码实现
//尾删复用
void PopBack(ListNode* phead)
{
assert(phead);
Erease(phead->prev);
}
//头删复用
void PopFront(ListNode* phead)
{
assert(phead);
Erease(phead->next);
}这里我们来对比一下单链表的头删和尾删。看看那些问题可以被结构优化?1.头尾节点分情况讨论可以被优化。2.不用遍历找头标记前节点。
//单链表尾删
void SListPopBack(SListNode** pphead)
{
assert(pphead);//检测地址
assert(*pphead);//*phead指向链表,检查是否节点
//尾删的时候有可能删除头节点,所以用二级指针
SListNode* cur = *pphead;//初始化
SListNode* prev = NULL;
while (cur->next)//找头
{
prev = cur;
cur = cur->next;
}
//删除头节点
if (cur == *pphead)
{
free(*pphead);
*pphead = NULL;
}
else//删除尾节点
{
free(cur);
cur = NULL;
prev->next = NULL;//在这里要注意还要处理prev的next指针
}
}
//单链表头删
void SListPopFront(SLTNode** pphead)
{
assert(pphead);
assert(*pphead);//检查
SLTNode* next = (*pphead)->next;//标记
free(*pphead);//释放
*pphead=NULL;//置空
*pphead = next;//连接
}3.实参与形参
1.对比单链表和双向带头循环链表结构特点。
单链表中头尾操作,传的是二级指针,是因为对头尾操作后,会更新为操作后新的头尾。对头的操作中,plist用于更新头,而对于删除,可能是对头节点操作。所以传二级指针。
想在函数内部改变外面的地址就得传二级指针。在外部操纵地址,传一级指针即可。而在双向带头循环链表中,我们的哨兵位头节点是不变的。所以只需传一级指针即可。
2.传一级指针还是二级指针:看结构!!!
(1)传二级指针的等效方法:C++里传引用,oj题里传返回值。虽说这些方法都可以,但是传二级指针的方式逻辑上更直接点。但是传一级指针可以保证接口的一致性但也要在功能都实现的前提下。这里再强调一下,传返回值的方法要记得去接收节点。
(2)取决于是否要改变实参。如果需要在函数内部改变外边地址,就得保证传参的时候传的是地址。可以通过办法引用,返回值等等。那为啥在函数操纵地址和在外边操纵地址不一样呢?因为给函数传参,是间接行为,参数要退化一层。这个在数组传参会退化是保持一致的!
4.野指针问题
(1)野指针问题造成的根源:
free/delete释放节点后,没把地址置空。展开来说就是实参的销毁问题。而形参的销毁往往伴随着栈帧的销毁而销毁了,不用特别处理。
(2)原理:
malloc/new,就是在堆上开辟一个空间,返回一个地址。那么对应的free/delete,也就是得把对应空间的地址释放掉。地址和指针的内容是两个概念,所以这也是传一级指针造成野指针问题的原因。
(3)一级指针在函数内置空效果:
指针内容为随机值,地址还在,但不能使用,也没还给系统。称之为野指针。即内存泄漏。
(4)解决办法:
传一级指针,在外部调用后置空。传二级,在函数内部置空。
5.断言检查
1.场景:
我们写的一个链表本质上也就是个小的应用项目,既然是交互型程序就要考虑的多一些,防止用户非法操作。我们就要人为添加断言。
2.介绍:
一般我们会添加两种断言:以尾删为例assert(pphead); 就是在检查传过来是不是空指针。空指针但指针地址不一定为空。 assert(*pphead);*pphead是指针解引用,指针指向链表的内容叫节点(也是指针),所以功能是检测链表中是否有节点。
(四)源码实现
下面一起撸一个双向带头循环链表吧!!
1.首先在Dlist.h里设计一个基本框架
//Dlist.h
#include
#include
#include
//结构体声明
typedef DataType;
typedef struct ListNode
{
struct ListNode* next;
struct ListNode* prev;
DataType data;
}ListNode;
//基本接口
ListNode* ListInit();
//遍历逻辑
ListNode* SetNode(DataType x);
void Destroy(ListNode* phead);
//查找
ListNode* ListFind(ListNode* phead, DataType x);
//打印
void ListPrint(ListNode* phead);
//在pos前插入
void ListInsert(ListNode* pos, DataType x);
void PushBack(ListNode* phead, DataType x);//尾插
void PushFront(ListNode* phead, DataType x);//头插
//删除pos位置
void Erease(ListNode* pos);
void PopBack(ListNode* phead);//尾删
void PopFront(ListNode* phead);//头删
//常见接口
size_t ListSize(ListNode* phead);
2.然后在Dlist.c中先把基本接口写一下比如:初始化链表,新建节点和与基本接口相关的其他接口:查找逻辑,删除链表。
基本接口逻辑:
初始化链表。当链表为空的时候,通过初始化建立一个哨兵位的头节点phead,这里的初始化就是对这个哨兵位的头节点操作。初始化简言之就是创建头节点并赋初值。创建一个节点,就是在堆上malloc一块空间,内存的表征是地址。所以这会返回一个地址。因为这是在函数内部对外部地址进行操作,故就要我们就要给函数传参传二级指针。或者返回一个地址。
新建节点。开辟空间,检查是否开辟成功,赋初值.
遍历逻辑:遍历在C语言中可以看成一个迭代for。包括:初始化,判断,调整,三个环节。
查找链表和删除链表的主逻辑就是"遍历".上文说到该链表是一个环结构。与无头单链表不同(phead,NULL),它是双向的,我们认为的给它设了一个哨兵头,但遍历是从真正的头开始的即phead->next,此链表其实是没设尾的,如果不设置终止的判断条件,遍历后将会到哨兵头,这就是一代,然后继续走向phead->next。总结:双向带头循环链表的一次遍历区间为(phead->next,phead)。通过这个类比,我们可以认为链表就是一个指针数组。
查找链表。查找区间(phead->next,phead);判断,节点值是否相等;调整:++操作
打印链表。查找区间(phead->next,phead);调整:设置打印格式
删除链表。遍历区间(phead->next,phead);判断,cur不为phead;调整:free();++操作
//初始化
ListNode* ListInit()
{
ListNode* phead = SetNode(9);
phead->next = phead;
phead->prev = phead;
phead->data = -1;
return phead;//malloc在堆上要返回一个地址
}
//新建节点
ListNode* SetNode(DataType x)
{
ListNode* node = (ListNode*)malloc(sizeof(ListNode));
if (node == NULL)
{
printf("malloc fail ");
exit(-1);
}
node->prev = NULL;
node->next = NULL;
node->data = x;
return node;
}
//查找
ListNode* ListFind(ListNode* phead, DataType x)
{
ListNode* cur = phead->next;//初始化
while (cur != phead)
{
if (cur->data == x)//判断
{
return cur;
}
cur = cur->next;//调整
}
return NULL;
}
//打印链表
void ListPrint(ListNode* phead)
{
assert(phead);
//初始化,判断条件,调整
ListNode* cur = phead->next;
while (cur != phead)
{
printf("%d ", cur->data);
cur = cur->next;
}
printf("\n");
}
//删除链表
void Destroy(ListNode* phead)
{
ListNode* cur = phead->next;//初始化
while (cur != phead)//判断
{
ListNode* curnext = cur->next;
free(cur);//调整
cur = curnext;
}
free(phead);
phead = NULL;//这里置空不置空都无所谓,因为出了函数作用
//域,没人能访问phead.其次就是phead形参的置空,不会影响外面的实参。
}核心接口:插入和删除
//在pos前插入
void ListInsert(ListNode* pos, DataType x)
{ //posprev newnode pos
assert(pos);
ListNode* newnode = SetNode(x);
ListNode* posprev = pos->prev;
posprev->next = newnode;
newnode->prev = posprev;
newnode->next = pos;
pos->prev = newnode;
}
//改写头插
void PushFront(ListNode* phead, DataType x)
{
assert(phead);
ListInsert(phead->next, x);
}
//改写尾插
void PushBack(ListNode* phead, DataType x)
{
assert(phead);
ListInsert(phead, x);
}//删除pos位置
void Erease(ListNode* pos)
{
ListNode* pospre = pos->prev;
ListNode* posnext = pos->next;
free(pos);
//pospre pos posnext
//处理pospre
pos = NULL;//置了也没啥用。
pospre->next = posnext;
posnext->prev = pospre;
}
//尾删
void PopBack(ListNode* phead)
{
assert(phead);
Erease(phead->prev);
}
//头删
void PopFront(ListNode* phead)
{
assert(phead);
Erease(phead->next);
}常用接口
//判空
size_t ListSize(ListNode* phead)
{
assert(phead);
int n = 0;
ListNode* cur = phead->next;
while (cur != phead)
{
++n;
cur = cur->next;
}
return n;
}最后再补充一下测试部分test.c
include "Dlist.h"
void test1()
{
ListNode* plist = ListInit();
PushBack(plist, 1);
PushBack(plist, 2);
PushBack(plist, 3);
ListPrint(plist); //检验尾插
ListNode* pos1 = ListFind(plist, 2);
if (pos1) {
ListInsert(pos1, 3);
}
ListPrint(plist);//检验查找和pos位置插入
PushFront(plist, 4);
PushFront(plist, 5);
ListPrint(plist);//检验头插
PopFront(plist);
ListPrint(plist);//检验头删
PopBack(plist);
ListPrint(plist);//检验尾删
ListNode* pos2 = ListFind(plist,1);
if (pos2)
{
Erease(pos2);
}
PushFront(plist, 4);
ListPrint(plist);//检验pos位置删除
printf("ListSize:%d\n", ListSize(plist));
Destroy(plist);
ListPrint(plist);//检验链表删除
plist = NULL;//手动置空,处理野指针问题。
}
int main()
{
test1();
return 0;
}源码gittee地址:带头双向链表(C语言版) · 刘敬一如/数据结构_blog1 - Gitee.comhttps://gitee.com/liu-jingyiru/data-structure-blog1/blob/master/%E5%B8%A6%E5%A4%B4%E5%8F%8C%E5%90%91%E9%93%BE%E8%A1%A8(C%E8%AF%AD%E8%A8%80%E7%89%88)