Historically hyperparameter determination has been a woefully forgotten aspect of machine learning. With the rise of neural nets - which require more hyperparameters, more precisely tuned than many other models - there has been a recent surge of interest in intelligent methods for selection; however, the average practitioner still seems to commonly use either default hyperparameters, grid search, random search, or (believe it or not) manual search.
For the readers who don’t know, hyperparameter selection boils down to a conceptually) simple problem: you have a set of variables (your hyperparameters) and an objective function (a measure of how good your model is). As you add hyperparameters, the search space of this problem explodes.
Grid Search is (often) Stupid
One method for finding optimal hyperparameters is grid search (divide the space into even increments and test them exhaustively).
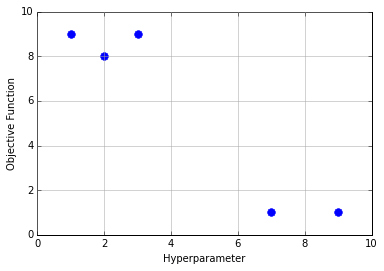
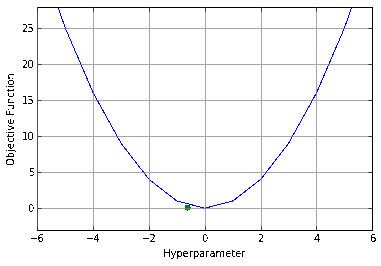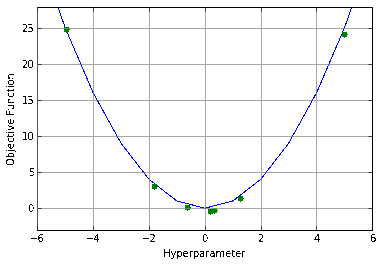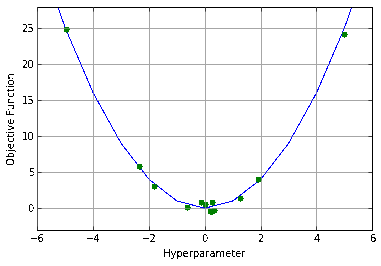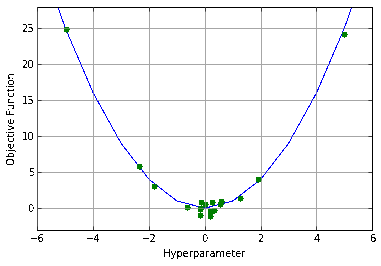
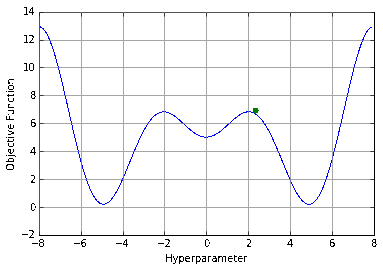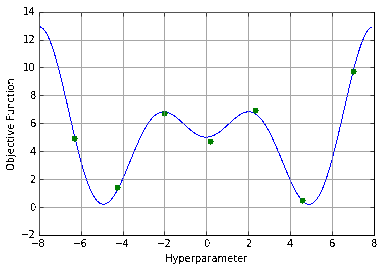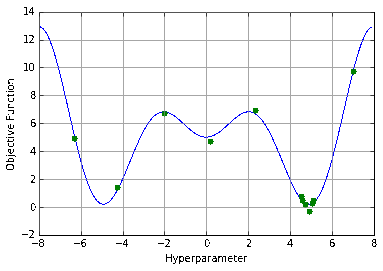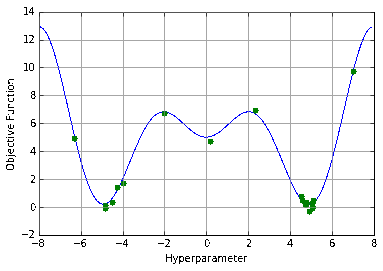
When presented with the above plot, a human would instinctively detect the pattern present, and, if looking for the lowest point, would be able to make an intelligent guess on where to begin. Most would not choose to evenly divide the space into a grid and test every point, yet this is precisely what grid search does. Humans have a fundamental intuition from looking at that image that there are areas the minimum is more likely to be. By exhaustively searching the space, you’re wasting your time on the areas where the function is obviously (excluding an improbable fluke) not going to be at its minimum and ignoring any information you have from the points you already know.
Random Search Isn’t Much Better
The next most common method is random search, which is exactly what it sounds like. Given the same plot, I doubt anybody would decide to pick random points. Random search is not quite stupid - anybody who has studied statistics knows the power of randomness from techniques like bootstrapping or monte carlo. In fact, randomly picking parameters often outperforms grid search. Random hyperparameters can find points that grid search would either skip over (if the granularity of the grid was too coarse) or cost a tremendous amount to find (as the grid becomes finer). It can similarly outperform manual search in some situations: a human will generally focus on the domain in which they have seen the lowest points, whereas random search finds new domains neglected by intuition.
A Different Kind of Optimization
Outside of cases where finding the absolute global minimum is required and an exhaustive search is necessary, grid search could only really reasonably be used in situations where the cost of evaluating the objective function is so low it could be considered to be non-existent, and even in those cases the only excuse for implementing it is laziness (i.e. it costs more to implement / run a sophisticated method than to perform grid search). In these cases grid search is preferred to random search because with a fine enough grid search you are guaranteed to find a near optimal point, whereas random search offers no such guarantee.
But what if you are in a situation where finding every point is too costly? Training models is often expensive, both in time and computational power, and this expense skyrockets with the increased data and model complexity. What we need is an intelligent way to traverse our parameter space while searching for a minimum.
Upon first impression, this might seem like an easy problem. Finding the minimum of an objective function is pretty much all we ever do in machine learning, right? Well here’s the rub: you don’t know this function. Fitting a regression you choose your cost function. Training a neural net you choose your activation function. If you know what these functions are, then you know their derivatives (assuming you picked differentiable functions); this means you know which direction points “down”. This knowledge is fundamental to most optimization techniques, like momentum or stochastic gradient descent.
There are other techniques, like binary search or golden ratio search, which don’t require the derivative directly but require the knowledge your objective is unimodal - any local, non-global minima have potential to make this search entirely ineffective. Yet other optimization methods do not depend upon any knowledge of the underlying function (simulated annealing, coordinate descent) but require a large number of samples from the objective function to find an approximate minimum.
So the question is, what do you do when the cost of evaluation is high? How do we intelligently guess where the minimums are likely to be in a high dimensional space? We need a method which doesn’t waste time on points where there isn’t expected return, but also won’t get caught in local minima.
Being Smart with Hyperparameters
So now that we know how bad grid search and random search are, the questions is how can we do better? Here we discuss one technique for intelligent hyperparameter search, known as bayesian optimization. We will now cover the concept of how this technique can be used to traverse hyperparameter space; there is an associated IPython Notebook which further illustrates the practice.
Bayesian Optimization on a Conceptual Level
The basic idea is this: you assume there is a smooth response surface (i.e. the curve of your objective function) connecting all your known hyperparameter-objective function points, then you model all of these possible surfaces. Averaging over these surfaces we acquire an expected objective function value for any given point and an associated variance (in more mathematical terms, we are modeling our response as a Gaussian Process). The lowest the variance on this surface dips is the point of highest ‘expected improvement’. This is a black-box model; we need no actual knowledge of the underlying process producing the response curve.
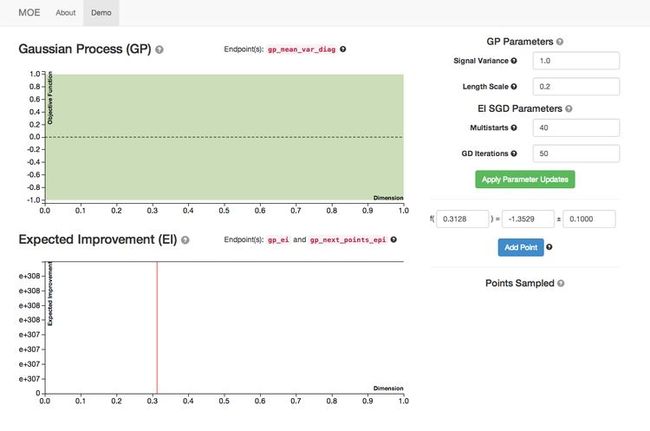
This concept is illustrated clearly in Yelp’s MOE documentation for the case of a single hyperparameter. On top, you see our objective function response surface when we have no previous data points. It is flat, as we don’t yet know anything. We can see that the variance (the shaded region) is also flat. In the bottom plot we see the maximum Expected Improvement (the lowest the variance dips). This plot is also flat, so our point of highest Expected Improvement is random.
Next we acquire a single data value, effectively pinning our expectation and collapsing its variance around a given point. Everywhere else the objective function remains unknown, but we are modeling the response surface as smooth. Additionally, you can see how the variance of our sample point can easily be incorporated into this model - the variance simply isn’t pinched quite as tightly.
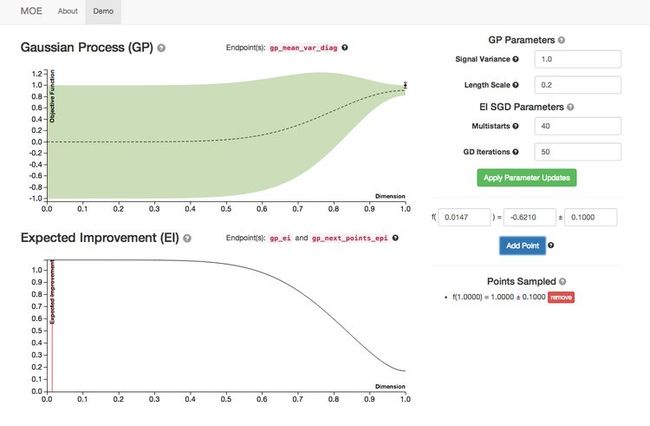
We can see that the objective function value for our acquired point is high (which for this example we will say is undesirable). We pick our next point to sample as far from here as possible.
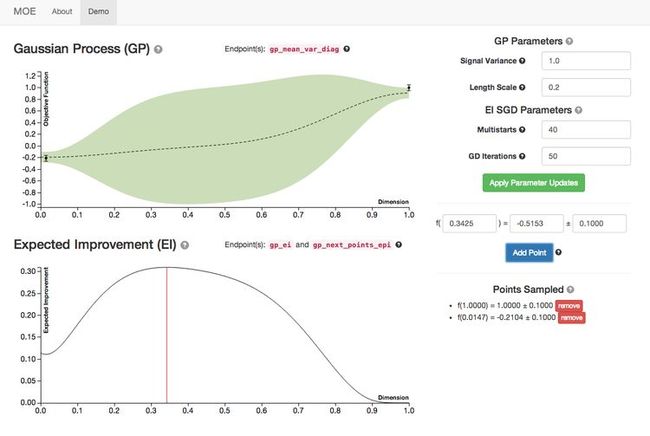
We’ve now ‘pinched’ our response curve on both sides, and begin to explore the middle. However, since the lower hyperparameter value had a lower objective value, we will favor towards lower hyperparameter values. The red line above shows the point of maximum expected improvement, i.e. our next point to sample.
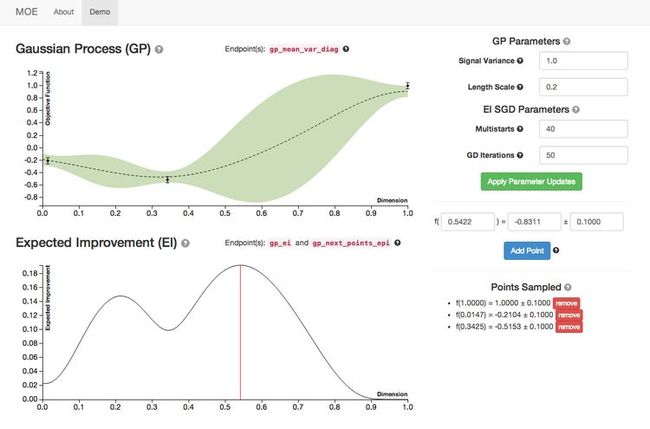
Now that we’ve pinched the middle of the curve, we have a choice to make - exploration or exploitation. You can see this trade-off is automatically made in our model - where the modeled variance dips the lowest is where our highest expected improvement point lies (the one dimensional example isn’t ideal for illustrating this, but you can imagine in more dimensions having large unexplored domains and the need to balance between exploiting better points near the low points you have and exploring these unknown domains).
If you have the capability to carry out multiple evaluations of the response curve in parallel (i.e. can train multiple models at once), a simple approach for sampling multiple points would be to assume the expected response curve value for your current point and sample a new point based upon that. When you get the actual values back, you update your model and keep sampling.
Our hyper-hyperparameter, the variance of the gaussian process, is actually very important in determining exploration vs. exploitation. Below you can see two examples of identical expected response surfaces where the variance magnitude (1 on the left, 5 on the right) which give different next points to sample (note that the scale of the y-axis has changed). The greater variance is set the more the model favors exploration and the lower it is set the more the model favors exploitation.
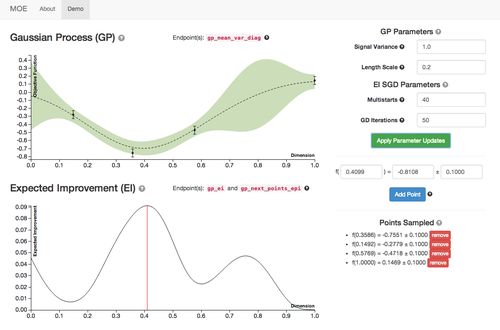
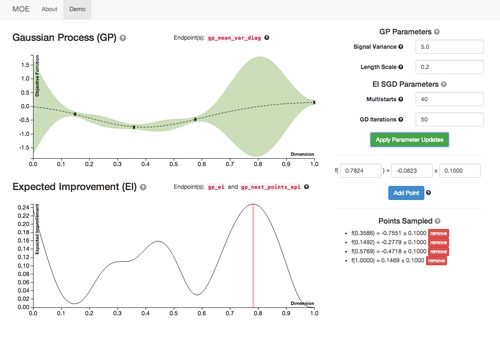
With bayesian optimization, in the worst case (when you have no history) you get random search. As you gain information, it becomes less random and more intelligent, picking points where the maximum improvement is expected, trading off between finding absolute minima around previously sampled points and exploring new domains.
There are two prominent open source packages which implement bayesian optimization: the above mentioned MOE (Metric Optimization Engine, produced by Yelp and the source of all of the pretty pictures featured above) and Spearmint (from the Harvard research group HIPS). These packages are so easy to use (see the attached IPython Notebook) that there’s practically no reason not to implement them on every hyperparameter search you perform (the argument that they take computing power to run themselves is valid; however, the computing cost of either is often negligible compared to that of training almost any non-toy model).
So don’t waste your time looking places which won’t yield results. And don’t search randomly when you can search intelligently.
A Note on Overfitting
As always, by tweaking based on a function of your data, there is a danger of overfitting. The two easiest ways to avoid overfitting your hyperparameters are to either tune your hyperparameters to an in-sample metric or to keep a third data split for final validation. Additionally, regularization can always be used to bound the potential complexity of your model.
Footnote: Animated plots of MOE exploring various objective functions to find the minimum