BERT论文解读
1. Introduction
1.1 相关链接
论文下载链接:https://arxiv.org/pdf/1810.04805.pdf
Google中文BERT预训练大模型下载链接:GitHub - ymcui/Chinese-BERT-wwm: Pre-Training with Whole Word Masking for Chinese BERT(中文BERT-wwm系列模型)
-
在该页面上,可以找到BERT-wwm-ext的预训练模型文件(chinese_wwm_ext_L-12_H-768_A-12.zip)。
-
点击下载链接下载该文件,解压缩后可以得到模型的checkpoint文件和config文件。
-
您可以使用TensorFlow或PyTorch等深度学习框架加载模型,以进行各种自然语言处理任务的微调。

1.2 背景介绍
之前,基于预训练的自然语言处理任务包括两类:
-
句子层面的任务,对句子情绪的识别,or 两个句子之间的关系;
-
实体命名识别,需要细粒度的词元层面的输出;
在使用预训练模型对下游任务进行特征表示,一般有两类策略:
-
基于特征;代表作ELMo,对每个下游任务构造一个RNN;在预训练好的模型,它作为额外的特征一起输入到模型里。
-
基于微调;代表作GPT,训练好的模型,对于下游任务的特定数据进行微调一下;
但是,这两个都是单向的,不能做到告诉你上句话和下句话是啥,来猜中间的是啥;
1.3 摘要
BERT(Bidirectional Encoder Representations from Transformers)是由Google提出的一种预训练语言模型,它是目前自然语言处理领域最成功的模型之一。BERT的设计基于Transformer模型,该模型是Google于2017年提出的一种序列到序列模型,它使用了自注意力机制,能够更好地捕捉文本序列中的上下文关系。与传统的循环神经网络(RNN)和卷积神经网络(CNN)不同,Transformer模型能够并行处理文本序列中的每一个位置,从而加速训练过程。
-
BERT is designed to pretrain deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers
说明:BERT与GPT的区别,GPT是单向的,从左侧往右侧,预测未来;然而BERT是双向的;
-
the pre-trained BERT model can be finetuned with just one additional output layer to create state-of-the-art models for a wide range of tasks
说明:BERT与ELMo的区别,ELMo是基于RNN架构的,它应用于下游应用时,需要对整体架构(上层部分)做些调整,然而BERT只需要对输出层做些修改即可;
BERT模型的主要贡献在于提出了一种“预训练+微调”的方法,通过在大规模无标注语料库上进行预训练,将模型的泛化能力提高到一个新的水平。BERT的预训练任务包括:(英语的完形填空)
-
Masked Language Modeling(MLM):随机将输入文本中一部分单词替换成一个特殊的标记[MASK],让模型预测被替换的单词是什么。
-
Next Sentence Prediction(NSP):给定两个句子A和B,让模型预测句子B是否是句子A的下一句。
预训练完成后,BERT模型可以用于各种自然语言处理任务,包括文本分类、情感分析、命名实体识别(NER)、文本摘要、问答等任务。在微调过程中,BERT模型的权重可以通过有标注数据进行微调,以适应特定的任务。微调过程中,通常将BERT模型的一个额外的输出层作为任务特定的输出层,以适应不同的任务要求。
BERT模型有多个变体,包括BERT-Base、BERT-Large、BERT-Mini等。BERT-Base模型包含12个Transformer编码器层,110M个参数,适合于小规模的自然语言处理任务。BERT-Large模型包含24个Transformer编码器层,340M个参数,适合于大规模的自然语言处理任务。BERT-Mini是一种更小的模型,只有4个Transformer编码器层,27M个参数,适合于资源有限的设备和小规模的自然语言处理任务。
BERT贡献总结:
-
展示了双向信息的重要性;
-
假设有预训练比较好的模型,只需要进行微调就可以得到很好的结果;
-
使用非监督的预训练模型是比较好的
2. 模型架构
BERT主要的步骤分为 预训练 + 微调
预训练:模型在没有标号的数据上进行训练的;
微调:所有的权重在微调的时候都会参与训练,用的是有标号的数据;
每一个下游的应用任务都会创建一个BERT模型。

BERT基础架构使用的是transformer的encoder,双向encoder;多个encoder堆叠在一起,BERT-Base 12层encoder,BERT-Large 24层encoder。
Transfomer的blocks的个数作为L,隐藏层的大小为H,注意力机制的头的个数为A
In this work, we denote the number of layers (i.e., Transformer blocks) as L, the hidden size as H, and the number of self-attention heads as A.3 We primarily report results on two model sizes: BERTBASE(L=12, H=768, A=12, Total Parameters=110M) and BERTLARGE(L=24, H=1024, A=16, Total Parameters=340M)
如何计算参数数量?
模型可学习的:1. embedding;2. transformer块
Embedding层:输入为30k的字典的大小, 输出为隐藏单元的块为H,然后输入到transformer块
Transformer块:自注意力机制 + MLP
多头注意力:所有进入头的K(key),V(value),Q(query)分别做一次投影,即H=A*64
投影矩阵合并:3*H*H,拿到输出后还要H*H,总共4*H*H
MLP有两个全连接层:1. 输入是H,输出为4*H;2.输入是4*H,输出为H
一个transformer块里的:(4*H*H+2*4*H*H)
Embedding为30*K*H + (Transformer块为12*H*H)*L
2.1 Encoder输入部分
transformer是6个encoder,6个decoder,下图是transformer的基本架构图
训练的时候是一个序列对,编码和解码分别输入一个序列;

BERT只有一个编码器,为了处理两个句子的情况,就需要把两个句子并成一个序列;
如果按照空格切词,一个word作为一个token;当数据量比较大的话,会导致词典大小特别大,导致所有可学习参数都在embedding上面;
用WordPiece进行切词,核心思想:如果一个词出现概率不大,切开看子序列,很可能是个词根,如果子序列出现概率比较大,就保留;可以利用3w的词典就可以表示比较大的文本;
Input = token emb + segment emb + position emb
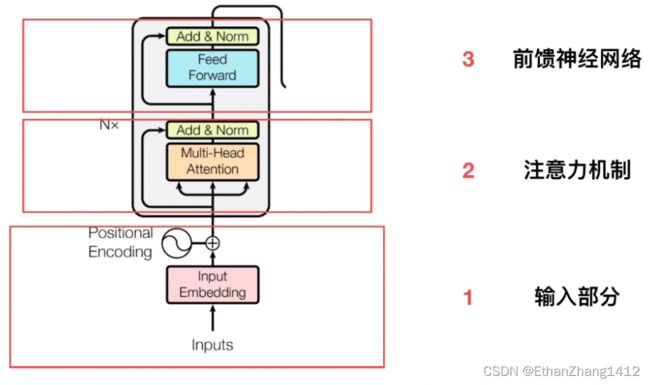
CLS为NSP(Next Sentence Prediction)二分类任务,判断两个句子之间的关系

Token Embeddings:对每个词元输出一个token向量;
Segment Embeddings:判断属于第一个句子,还是第二个句子;输入其实就是2,A or B,得到相应的向量;
Position Embeddings:输入大小为序列的最长值,输入为每个词元在这个序列里面的位置信息,得到对应位置的向量;
2.2 预训练
MLM(Mask Language Model)+ NSP(Next Sentence Prediction)
2.2.1 MLM —— 掩码语言模型
AR:autoregressive,自回归模型;只考虑单侧的信息,典型的就是GPT
P(我爱吃饭) = P(我) P(爱|我) P(吃|我爱) P(饭|我爱吃)
自监督目标函数
AE:autoencoding,自编码模型;从损坏的输入数据中预测重建原始建模。可使用上下文的信息,典型的就是BERT
mask之后:【我爱mask饭】
P(我爱吃饭|我爱mask饭)= P(mask=吃|我爱饭)
缺点:
mask之后:【我爱maskmask】
P(我爱吃饭|我爱mask mask)=P(吃|我爱)P(饭|我爱)
这里,吃和饭,这两个字不是完全独立的,是有一定关联的。
mask的概率问题
问题:微调不会进行mask,会导致训练和微调的数据会有不一样。
解决方法:随机mask15%的单词,这其中10%替换成其他,10%原封不动,80%替换成mask
2.2.2 NSP —— 下一个句子的预测
QA问题有两个句子,问答对;
如何分配正负例样本?
-
从训练语料库中取出两个连续的段落作为正样本(同一个主题,两个连续的,顺序没有倒)
-
从不同的文档中随机创建一对段落作为负样本
最好利用文本级别的数据集
缺点:主题预测(非常容易)和连贯性预测合并为一个单项任务
2.3 微调
2.3.1 概念
利用某几个输出进行finetune

2.3.2 如何微调
四步骤:
-
在大量通用语料上训练一个Language Model(Pretrain)—— 中文谷歌BERT(一般不做)
-
在相同领域上继续训练LM(Domain transfer)—— 在大量微博文本上继续训练这个BERT
-
在任务相关的小数据上继续训练LM(Task transfer)—— 在微博情感文本上(有的文本不属于情感分析的范畴)
-
在任务相关数据上做具体任务(Fine-tune)
总结:先Domain tranfer,再进行Task transfer,最后Fine-tune性能是最好的,提高1到3个点左右
如何在相同领域数据中进行further pre-training
-
动态mask:就是每次epoch去训练之前,做一次mask,而不是整个训练过程一直使用同一个。
-
n-gram mask:比如ERNIE和SpanBert都是类似于做了实体词的mask
-
参数设置:
(1)Batch size:16,32,64 ——影响不大,根据机器配置来;
(2)Learning rate(Adam):5e-5,3e-5,2e-5,尽可能小一点,避免灾难性遗忘
(3)Number of epochs:3,4(微调部分epoch本来就不会太多,文章里是3,最好再多些)
(4)Weighted decay修改后的Adam,使用warmup,搭配线性衰减
(5)数据增强/自蒸馏/外部知识(知识图谱,实体词信息)的融入
2.3.3 局限性
因为他是双向的encoder,不像transformer那样有编解码器,不能做机器翻译的任务,类似于Seq2Seq的任务。
简单来说,BERT没有解码器,所以就不能做机器翻译的任务。
参考学习链接:
BERT从零详细解读,通俗易懂!!_哔哩哔哩_bilibili
BERT 论文逐段精读【论文精读】_哔哩哔哩_bilibili