用强化学习来玩Atari游戏(基于Tensorflow的深度Q学习模型)
在之前的博客用Tensorflow Agents实现强化学习DQN_gzroy的博客-CSDN博客中,我用TF-Agents实现了一个深度Q学习模型,并且对小车上山这个环境进行了训练。那么更进一步,我们可以看看能否用深度Q学习解决一些更复杂的问题,例如我们是否能训练一个模型,可以玩Atari的游戏,并取得比人类更好的成绩。
在2015年,DeepMind发表的论文《Human-level control through deep reinforcement learning》,提出了用带经验回放和目标网络的深度Q学习算法,直接从游戏界面中学习。本文将基于论文中提到的算法,来实现对Atari游戏进行学习。
首先加载Atari的环境,这里选择的是Pong这个游戏。环境名称中的deterministic表示每次调用Step的时候会得到4帧后的观测,返回的是这4帧的总奖励值。V4表示执行某个动作后,下一个动作没有限定要和上个动作相同。如果是V0则表示有25%的机率下一个动作和上一个动作相同。
from tf_agents.environments import suite_gym
from tf_agents.environments import tf_py_environment
from tf_agents.networks import q_network
from tf_agents.replay_buffers import tf_uniform_replay_buffer
from tf_agents.trajectories import trajectory
from tf_agents.trajectories import Trajectory
from tf_agents.trajectories import time_step, TimeStep
from tf_agents.specs import tensor_spec
from tqdm import trange
from tf_agents.policies.q_policy import QPolicy
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras.initializers import GlorotUniform
from tf_agents.networks.q_network import QNetwork
from tf_agents.agents.dqn import dqn_agent
from tf_agents.utils import common
from tf_agents.policies import random_tf_policy
from tf_agents.drivers import dynamic_step_driver
import random
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib notebook
import os
env_name = 'PongDeterministic-v4'
train_py_env = suite_gym.load(env_name, max_episode_steps=0)
eval_py_env = suite_gym.load(env_name, max_episode_steps=0)
train_env = tf_py_environment.TFPyEnvironment(train_py_env)
eval_env = tf_py_environment.TFPyEnvironment(eval_py_env)加载环境后,我们可以用随机策略试玩一下,看看这个游戏是怎样的
import imageio
import base64
import IPython
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
'''.format(b64.decode())
return IPython.display.HTML(tag)
def create_policy_eval_video(policy, filename, num_episodes=1, fps=30):
filename = filename + ".mp4"
with imageio.get_writer(filename, fps=fps) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_py_env.render())
images = []
while not time_step.is_last():
time_step = eval_env.step(random.randint(action_min,action_max))
video.append_data(eval_py_env.render())
return embed_mp4(filename)
create_policy_eval_video(agent.policy, "trained-agent-pong_random")视频如下:
trained-agent-pong_random
为了能理解游戏界面,需要设计一个卷积神经网络来提取图形的特征。这里需要把游戏最近的4帧灰度画面作为输入,因为这样网络才能理解物体运动的信息。整个神经网络的结构如下:
以下代码定义了一个DQNAgent,这里需要修改原有环境的Timestep的spec,因为现在网络的输入是需要最近的4帧画面,所以输入的维度是110*84*4
input_shape = (110, 84, 4)
target_network_update_freq = 4000
learning_rate = 0.001
gamma = 0.99
time_step_spec = train_env.time_step_spec()
new_observation_spec = tensor_spec.BoundedTensorSpec(input_shape, tf.uint8, 0, 255, 'observation')
new_time_step_spec = time_step.TimeStep(
time_step_spec.step_type,
time_step_spec.reward,
time_step_spec.discount,
new_observation_spec)
q_net = q_network.QNetwork(
new_observation_spec,
train_env.action_spec(),
preprocessing_layers=tf.keras.layers.Rescaling(scale=1./127.5, offset=-1),
conv_layer_params=[(32,8,4), (64,4,2), (64,3,1)],
fc_layer_params=(512,))
global_step = tf.compat.v1.train.get_or_create_global_step()
agent = dqn_agent.DqnAgent(
new_time_step_spec,
train_env.action_spec(),
q_network=q_net,
target_update_tau=1./target_network_update_freq,
target_update_period=1,
gamma=gamma,
epsilon_greedy=0.,
td_errors_loss_fn=common.element_wise_squared_loss,
optimizer=tf.keras.optimizers.RMSprop(learning_rate, 0.95, momentum=0.95, epsilon=0.01),
train_step_counter=global_step)
agent.initialize()定义一个replay buffer用于存储和回放历史经验,这里注意的是在dataset里面需要设置num_steps=2,因为对于深度Q学习,每次需要用两条相邻的经验来进行学习。
replay_memory_size = 100000
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
agent.collect_data_spec,
batch_size=train_env.batch_size,
max_length=replay_memory_size)
dataset = replay_buffer.as_dataset(
num_parallel_calls=3,
sample_batch_size=batch_size,
num_steps=2).prefetch(3)
iterator = iter(dataset)定义一个函数来评估模型的性能,以及用图表描绘模型的训练过程:
def compute_avg_return(environment, policy, num_episodes=10):
total_return = 0.0
for _ in range(num_episodes):
time_step = environment.reset()
episode_return = 0.0
step = 0
images = []
while not time_step.is_last():
step += 1
images, observation = get_observation(images, time_step.observation)
step_type = tf.squeeze(time_step.step_type)
time_step = TimeStep(
time_step.step_type,
time_step.reward,
time_step.discount,
tf.expand_dims(observation, axis=0))
if random.random()<=0.05 or step<=random_initial_steps:
action = random.randint(action_min, action_max)
else:
action = policy.action(time_step).action
time_step = environment.step(action)
episode_return += time_step.reward
total_return += episode_return
avg_return = total_return / num_episodes
return avg_return.numpy()[0]
class Chart:
def __init__(self):
self.fig, self.ax = plt.subplots(figsize = (8, 6))
def plot(self, data, x_name, y_name, hue_name):
self.ax.clear()
sns.lineplot(data=data, x=data[x_name], y=data[y_name], hue=data[hue_name], ax=self.ax)
self.fig.canvas.draw()因为整个模型的训练非常耗时,因此需要定义checkpointer saver来定期保存训练结果以及replay buffer的数据
checkpoint_dir = os.path.join('./', 'checkpoint')
train_checkpointer = common.Checkpointer(
ckpt_dir=checkpoint_dir,
max_to_keep=1,
agent=agent,
policy=agent.policy,
replay_buffer=replay_buffer,
global_step=global_step
)之后我们就可以训练和评估模型了,这里设置了在头10个回合,只搜集经验但不进行训练。10个回合之后,每个回合的头30步采用随机动作,这样可以避免模型记住某些特定的开局。在训练开始epsilon设置为1,然后逐步递减,直到epsilon减少为0.1为止。在训练的时候,需要保存前3帧的图像,并和当前帧一起叠加后,输入到模型中。代码如下:
batch_size = 128
update_freq = 4 # 训练网络的间隔
epsilon = 1. # 初始探索率
min_epsilon = 0.1 # 最终探索率
epsilon_decrease = 9e-7 # 探索减小速度
replay_start_episode = 10 # 开始训练前的经验数
random_initial_steps = 30 # 每个回合开始时随机步数
train_episodes = 400
test_episodes = 2 # 每次验证智能体的回合数
start_episode = 0
end_episode = start_episode+train_episodes
action_min = agent.collect_data_spec.action.minimum
action_max = agent.collect_data_spec.action.maximum
rewards_df = pd.DataFrame(data=None, columns=['episode','reward','type'])
loss_df = pd.DataFrame(data=None, columns=['episode','loss','type'])
chart_reward = Chart()
chart_loss = Chart()
def get_observation(images, observation):
image = tf.squeeze(observation)
image = tf.image.rgb_to_grayscale(image)
image = tf.image.resize(image, [input_shape[0],input_shape[1]])
image = tf.cast(image, tf.uint8)
image = tf.squeeze(image)
if len(images)==0:
images = [image, image, image, image]
images = images[1:]
images.append(image)
observation = tf.stack(images)
observation = tf.transpose(observation, perm=[1,2,0])
return images, observation
for episode in trange(start_episode, end_episode):
time_step = train_env.reset()
step = 0
images = []
episode_reward = 0
total_loss = 0
while not time_step.is_last():
step += 1
images, observation = get_observation(images, time_step.observation)
step_type = tf.squeeze(time_step.step_type)
time_step = TimeStep(time_step.step_type, time_step.reward, time_step.discount, tf.expand_dims(observation, axis=0))
if step<=random_initial_steps:
action = random.randint(action_min, action_max)
action = tf.convert_to_tensor(action, dtype=tf.int64)
else:
epsilon = max(epsilon-epsilon_decrease, min_epsilon)
if random.random()=replay_start_episode and step%update_freq==0:
experience, unused_info = next(iterator)
train_loss = agent.train(experience).loss
total_loss += train_loss
episode_reward += time_step.reward.numpy()[0]
if episode>replay_start_episode:
rewards_df = rewards_df.append({'episode':episode, 'reward':episode_reward, 'type':'train'}, ignore_index=True)
loss_df = loss_df.append({'episode':episode, 'loss':total_loss.numpy()/step, 'type':'train'}, ignore_index=True)
if (episode-replay_start_episode)%test_episodes==0:
avg_return = compute_avg_return(eval_env, agent.policy, test_episodes)
rewards_df = rewards_df.append({'episode':episode, 'reward':avg_return, 'type':'eval'}, ignore_index=True)
chart_reward.plot(rewards_df, 'episode', 'reward', 'type')
chart_loss.plot(loss_df, 'episode', 'loss', 'type')
train_checkpointer.save(global_step) 训练非常花时间,在训练了460回合后,我们可以看一下效果,修改一下之前生成video的代码:
def create_policy_eval_video(policy, filename, num_episodes=1, fps=30):
filename = filename + ".mp4"
with imageio.get_writer(filename, fps=fps) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_py_env.render())
images = []
while not time_step.is_last():
images, observation = get_observation(images, time_step.observation)
step_type = tf.squeeze(time_step.step_type)
time_step = TimeStep(
time_step.step_type,
time_step.reward,
time_step.discount,
tf.expand_dims(observation, axis=0))
action_step = policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_py_env.render())
return embed_mp4(filename)
create_policy_eval_video(agent.policy, "trained-agent-pong_1")视频如下:
trained-agent-pong
从视频中可以见到模型已经学习到了一些技巧,可以获得一些分数。
当继续训练到800回合左右时,我们可以看到模型的每个回合的回报已经去到了21,表明已经取得了最好的成绩了:

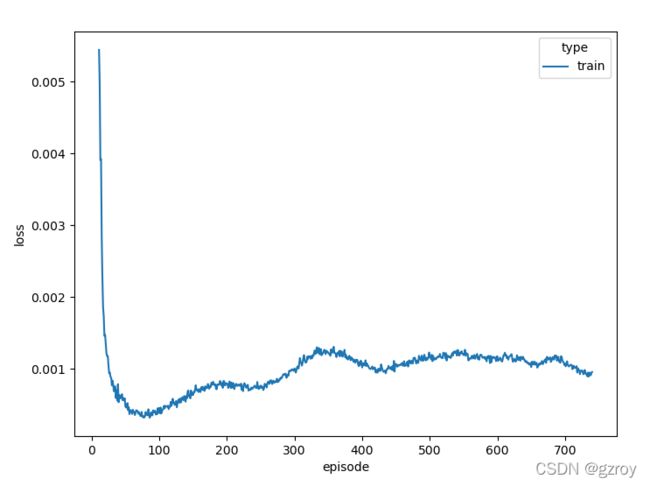 我们可以把评估结果输出为视频看一下,如下:
我们可以把评估结果输出为视频看一下,如下:
trained-agent-pong_862