Hadoop期末复习—必备知识
第一章*
大数据:
1:什么是大数据:
一种规模大到获取,存储,管理,分析都大大超过了传统数据库软件工具的能力范围的数据集合
2:特点:
数据量大,类型繁多,处理速度快,价值密度低
3:在零售行业的应用:
精准定位零售行业市场;支持行业收益管理;挖掘零售行业新需求;
Hadoop:
1:Hadoop优势:
- 高效率
- 可靠性
- 成本低
- 扩容能力强
- 高容错性
2:Hadoop生态系统:
- 分布式文件系统、分布式存储系统(HDFS)
- 分布式计算框架(MapReduce)
- 资源管理平台(Yarn)
- 数据迁移工具(sqoop)
- 数据挖掘算法库(Mahout)
- 分布式数据库(HBase)
- 分布式协调服务(Zookeeper)
- Hive基于Hadoop的数据仓库
- 日志收集工具(Flume)
3:hadoop 1.X与Hadoop2.X区别:
Hadoop1.X的内核主要有:HDFS(分布式存储系统)和MapReduce(分布式计算框架)
Hadoop2.X的内核主要有:HDFS(分布式存储系统)和MapReduce(分布式计算框架)以及Yarn(资源管理平台)和其他工作机制的改变(Others)
Hadoop1.X中
1:HDFS由一个Namenode和多个Datanode组成,(注意:一个Datanode上存储的数据块不可以有相同的),其中Datanode负责存储数据,但是具体数据存储在哪一个Datanode上由Namenode决定。
2:MapReduce由一个Jobtracker和多个Tasktraker组成,Jobtraker负责接收计算任务,分配给Tasktraker执行,跟踪,并对其进行任务执行状况监控。
缺点:
1:HDFS中Namenode与Secondary Namenode单点故障,风险较大。其次Namenode内存受限不好扩展。且只有一个Namenode需要负责观理所有Datanode.
2:MapReduce中Jobtracker职责过多,访问压力太大,会影响系统稳定,并且MapReduce难以支持出自身外的框架。
Hadoop2.X:
1:可以同时启动多个Namenode,其中一个处于工作状态,一个处于随时待命的状态,(Hadoop HA=Hadoop 高可用),当一个Namenode宕机,可以在数据不丢失的情况下,自动切换到另一个Namenode持续提供服务。
2:将Jobtraker中的资源管理和作业控制分开,分别由ResourceManager(负责所有应用程序资源分配)和ApplicationMaster(负责管理一个应用程序)实现,其实就是引入了Yarn(资源管理平台,可以为各类应用程序进行资源管理和调度),可以实现个不同计算模型和各种应用之间的交互,使集群得到高效利用。
3:MapRuduce是运行在Yarn上的离线处理框架,运行环境不在是Jobtracker和Tasktrake等服务组成,而是变成通用资源管理Yarn和作业控制进程ApplicationMaster,提升了Mapreduce的速度和可用性。
第二章
1:Hadoop安装
(一)启动与关闭Hadoop:
单节点逐个启动:
- 在主节点上启动HDFS namenode进程:
hadoop-daemon.sh start namenode- 在从节点上使用指令启动 HDFS DataNode进程 :
hadoop-daemon.sh start DataNode- 在主节点上使用指令启动Yarn RecourseManager进程:
yarn-daemon.sh start recoursemanager- 在每个节点上从节点上使用指令启动Yarn nodemanager进程:
yarn-daemon.sh start nodemanager- 在规划节点Hadoop02使用指令启动SecondaryNameNode:
hadoop-daemon.sh start secondarynamenode
脚本一键启动和关闭:- 在主节点Hadoop上使用指令启动所有HDFS服务进程:
start-dfs.sh- 在主节点Hadoop01上使用指令启动所有Yarn服务进程:
start-yarn.sh
将以上指令start改为stop就为关闭服务命令
2:通过UI查看Hadoop运行状态:
在Hadoop集群开放后默认开放了端口:
- 50070:监控HDFS集群主要为:namenode
- 8088:监控Yarn集群
3:Hadoop集群配置文件:
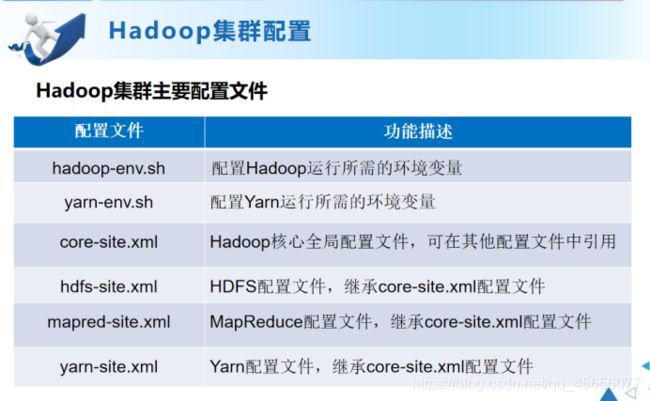
配置集群主节点:
- 修改hadoop-env.sh文件:配置Hadoop运行环境下所需的JDK环境变量
- 修改core-site.xml文件:配置HDFS地址,端口号以及临时文件(HDFS的主进程NameNode运行主机,也就是Hadoop集群的主节点,同时配置Hadoop运行是所生成数据的临时目录)
- 修改hdfs-site.xml文件:配置HDFS上的NameNodo和DataNode量大进程。(配置了HDFS数据块的副本数量集群备份数量(默认为3),并根据需要设置了SecondaryNameNode所在服务的HTTP协议地址)
- 修改mapred-site.xml文件:用于指定MapReduce运行时的框架
- 修改yarn-site.xml文件:配置Yarn运行RecourseManager运行主机号和NodeManager运行时的附属服务需要配置为MapReduce-shuffle才能正常运行MapReduce默认程序
- 修改slaves文件。打开该配置文件,先删除里面的内容(默认localhost):记录Hadoop集群所有从节点的主机名(HDFS的DataNode和Yarn的NodeManager)
将集群主节点的配置文件分发到其他子节点:
完成Hadoop集群主节点hadoop01的配置后,还需要将系统环境配置文件、JDK安装目录和Hadoop安装目录分发到其他子节点hadoop02和hadoop03上,具体指令:
$ scp /etc/profile hadoop02:/etc/profile
$ scp /etc/profile hadoop03:/etc/profile
$ scp -r /export/ hadoop02:/
$ scp -r /export/ hadoop03:/
4:

5:Hadoop安装步骤:
- 下载安装包
- 解压安装Hadoop
- 配置Hadoop环境变量
- 验证Hadoop环境
6:Hadoop安装目录
- bin:存放操作Hadoop相关服务的脚本
- sbin:存放Hadoop相关管理脚本
- etc:存放Hadoop配置文件(Hadoop2.X新增yarn-site.xml)
- include:Hadoop对外编程库头文件
- lib:hadoop 对外编程动态库和静态库
- libexec:Hadoop服务对用的shell配置文件所在目录
- shave:Hadoop各个模块编译后的jar包所在的目录
- src:Hadoop源码包
7:虚拟机安装
过程:
- 下载安装
- 创建虚拟机:(操作系统选择—虚拟机命名—处理器配置—虚拟机内存—指定磁盘容量—-创建完成)
- 虚拟机初始化:(镜像文件配置—-磁盘格式化—主机名配置—网络配置—-时区配置—系统用户名配置—-磁盘格式化)
8:虚拟机克隆
- 完整克隆:是对原始虚拟机的完全独立的一个复制,它不和虚拟机共享任何资源,可以完全脱离虚拟机独立使用。
- 链接克隆:需要和原始虚拟机共享同一虚拟磁盘文件,不能脱离原始虚拟机独立运行。但是,采用共同磁盘文件可以为创建虚拟机的节省时间,同时还节省物理磁盘空间。
完全克隆的虚拟机文件相对独立并且安全,在实际开发中应用广泛。
9:
命令:
- 加载环境变量配置文件需要使用:
source /etc/profile- 格式化HDFS集群命令:
hadoop namenode -format- shell命令方式:
hadoop fs(适用于任何不同文件系统,例如本地文件系统和HDFS)hadoop dfs 和 hdfs dfs(都只适用于HDFS文件系统)
第三章
1:HDFS的读写原理:
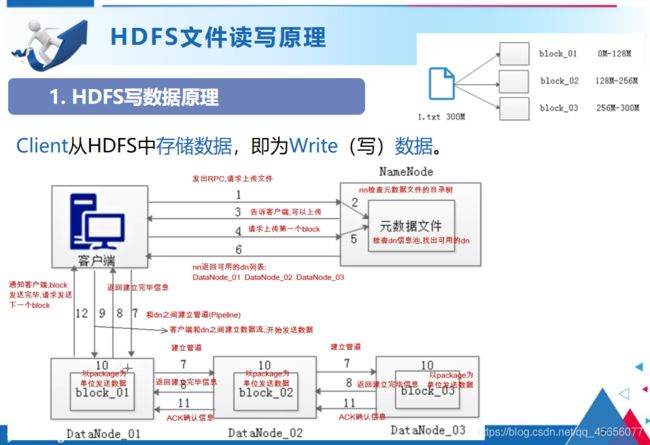
HDFS写数据原理:
- 客户端发起文件上传请求,通过RPC(远程过程调用)与NameNode建立通讯
- NameNode检查元数据文件的系统目录树
- 若系统目录树的父目录不存在该文件相关信息,返回客户端可以上传文件
- 客户端请求上传第一个Block数据块以及数据块副本的数量
- NameNode检测元数据文件中DataNode信息池,找到可用的数据节点
- NameNode检查元数据文件的系统目录树
- 若系统目录树的父目录不存在该文件相关信息,返回客户端可以上传文件
- 客户端与DataNode之间建立Pipeline后,逐个返回建立完毕信息
- 客户端与DataNode建立数据传输流,开始发送数据包
- 客户端向DataNode_01上传第一个Block数据块,当DataNode_01收到一个Packet就会传给DataNode_02,DataNode_02传给DataNode_03,DataNode_01每传送一个Packet都会放入一个应答队列等待应答。
- 数据被分割成一个个Packet数据包在Pipeline上依次传输,而在Pipeline反方向上,将逐个发送Ack,最终由Pipeline中第一个DataNode节点DataNode_01将Pipeline的 Ack信息发送给客户端。
- DataNode返回给客户端,第一个Block块传输完成。客户端则会再次请求NameNode上传第二个Block块和第三块到服务器上,重复上面的步骤,直到3个Block都上传完毕。
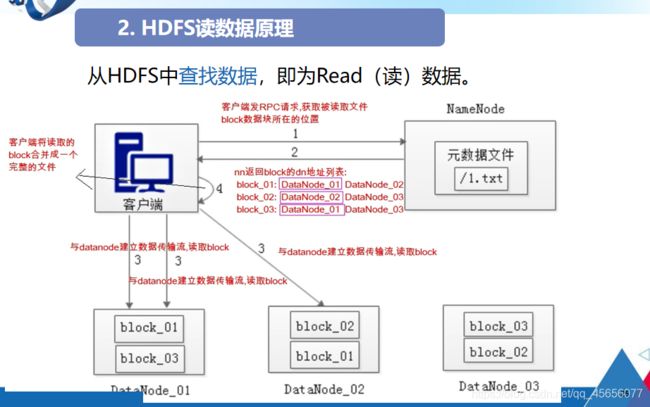
HDFS读数据原理:
- 客户端向NameNode发起RPC请求,来获取请求文件Block数据块所在的位置。
- NameNode检测元数据文件,会视情况返回Block块信息或者全部Block块信息,对于每个Block块,NameNode都会返回含有该Block副本的DataNode地址。
- 客户端会选取排序靠前的DataNode来依次读取Block块,每一个Block都会进行CheckSum若文件不完整,则客户端会继续向NameNode获取下一批的Block列表,直到验证读取出来文件是完整的,则Block读取完毕。
- 客户端会把最终读取出来所有的Block块合并成一个完整的最终文件(例如:1.txt)。
2:HDFS的演变:
传统文件系统—分布式文件系统雏形–HDFS文件系统雏形–HDFS
3:HDFS基本概念:
- NameNode:维护系统下所有的文件系统和目录相关信息,主要以元数据的形式进行管理存储,用于维护文件系统名称和管理客户端对文件的访问namenode包含两部分(Fsimage镜像文件(勇于存储整个文件系统命名空间信息)和Editlog日志文件(勇于持久化记录文件系统元数据发生的变化))
- DataNode:存储真实数据块,以文件形式存储在磁盘中,包括两个文件一个是数据本身,二:每个数据块对应的元数据文件(数据长度,时间戳,块数据校验和)DataNode是HDFS集群中的从服务器,通常称为数据节点。文件系统存储文件的方式是将文件切分成多个数据块,这些数据块实际上是存储在DataNode节点中的,因此DataNode机器需要配置大量磁盘空间。它与NameNode保持不断的通信,DataNode在客户端或者NameNode的调度下,存储并检索数据块,对数据块进行创建、删除等操作,并且定期向NameNode发送所存储的数据块列表。
- Block:每个磁盘都有默认的数据块大小,这是磁盘进行数据读/写的最小单位,HDFS同样也有块(block)的概念,它是抽象的块,而非整个文件作为存储单元,在Hadoop2.x版本下,默认大小是128M,且备份3份,每个块尽可能地存储于不同的DataNode中。按块存储的好处主要是屏蔽了文件的大小,提供数据的容错性和可用性。
- Rack:Rack是用来存放部署Hadoop集群服务器的机架,不同机架之间的节点通过交换机通信,HDFS通过机架感知策略,使NameNode能够确定每个DataNode所属的机架ID,使用副本存放策略,来改进数据的可靠性、可用性和网络带宽的利用率。
- Matadata:维护文件和目录信息,记录文件内容,存储目录信息,记录HDFS中所有DataNode信息,用于DataNode管理
4:HDFS特点:
优点

缺点

5:HDFS的存储架构

6:HDFS的shell操作:
shell在计算机科学中俗称“壳”,是提供给使用者使用界面的进行与系统交互的软件,通过接收用户输入的命令执行相应的操作,Shell分为图形界面Shell和命令行式Shell。



hadoop fs -ls

hadoop fs -mkdir -p/itcast/hadoop

3. hadoop fs -put -f install.log /



7:Hadoop的java API操作:
HDFS Shell本质上就是对Java API的应用,通过编程的形式操作HDFS,其核心是使用HDFS提供的Java API构造一个访问客户端对象,然后通过客户端对象对HDFS上的文件进行操作(增、删、改、查)。

在Java中操作HDFS,创建一个客户端实例主要涉及以下两个类:
Configuration:该类的对象封装了客户端或者服务器的配置,Configuration实例会自动加载HDFS的配置文件core-site.xml,从中获取Hadoop集群的配置信息。
FileSystem:该类的对象是一个文件系统对象

案例——使用Java API操作HDFS
-
搭建项目环境
创建一个项目名为“HadoopDemo”,包名为“com.itcast”的Maven项目,并在项目的pom.xml文件中引入hadoop-common、hadoop-hdfs、hadoop-client以及单元测试junit的依赖。

-
初始化客户端对象
首先在项目src文件夹下创建com.itcast.hdfsdemo包,并在该包下创建HDFS_CRUD.java文件,编写Java测试类,构建Configuration和FileSystem对象,初始化一个客户端实例进行相应的操作。 -
上传文件到HDFS
由于采用Java测试类来实现JavaApi对HDFS的操作,因此可以在HDFS_CRUD.java文件中添加一个testAddFileToHdfs()方法来演示本地文件上传到HDFS的示例。

-
从HDFS下载文件到本地
在HDFS_CRUD.java文件中添加一个testDownloadFileToLocal()方法,来实现从HDFS中下载文件到本地系统的功能。

-
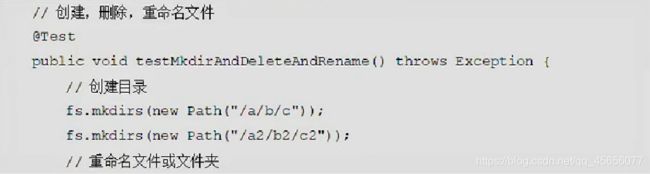
目录操作
在HDFS_CRUD.java文件添加一个testMkdirAndDeleteAndRename()方法,实现目录的创建、删除、重命名的功能。
-
查看目录中的文件信息
在HDFS_CRUD.java文件中添加一个testListFiles()方法,实现查看目录中所有文件的详细信息的功能。
第四章
1:MapReduce核心思想:
分而治之:就是把一个复杂的问题,按照一定的“分解”方法分为等价的规模较小的若干部分,然后逐个解决,分别找出各部分的结果,把各部分的结果组成整个问题的结果
MapReduce是Hadoop系统核心组件之一,它是一种可用于大数据并行处理的计算模型、框架和平台,主要解决海量数据的计算,是目前分布式计算模型中应用较为广泛的一种
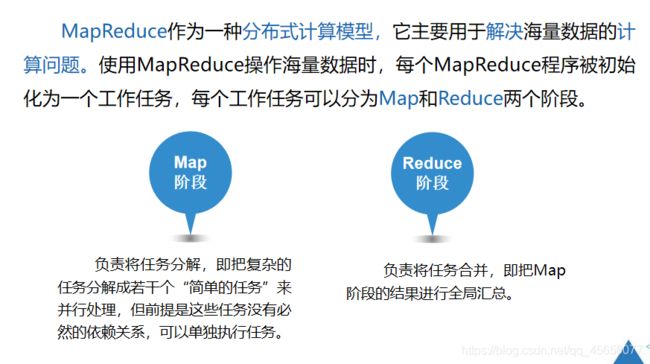
Map阶段:勇于对原始数据进行处理
Reduce阶段:对map阶段数据进行汇总
部分任务不一定需要reduce阶段可能只有map阶段,map阶段产生的数据直接写入HDFS中

有map产生相关key的输出都会集中在到Reduce中处理,reduce是最终的处理过程,其结果不会进行二次处理。
2:MapReduce工作过程
- 分片、格式化数据源
- 执行MapTask
- 执行Shuffle过程
- 执行ReduceTask
- 写入文件
ReduceTask工作原理:
ReduceTask的工作过程主要经历了5个阶段,分别是Copy阶段、Merge阶段、Sort阶段、Reduce阶段和Write阶段。
MapTask工作原理:
MapTask作为MapReduce工作流程前半部分,它主要经历5个阶段,分别是Read阶段、Map阶段、Collect阶段、Spill阶段和Combiner阶段
Shuffle工作原理:
Shuffle是MapReduce的核心,它用来确保每个reducer的输入都是按键排序的。它的性能高低直接决定了整个MapReduce程序的性能高低,map和reduce阶段都涉及到了shuffle机制。