Rust系列(一) 所有权和生命周期
一、rust基石
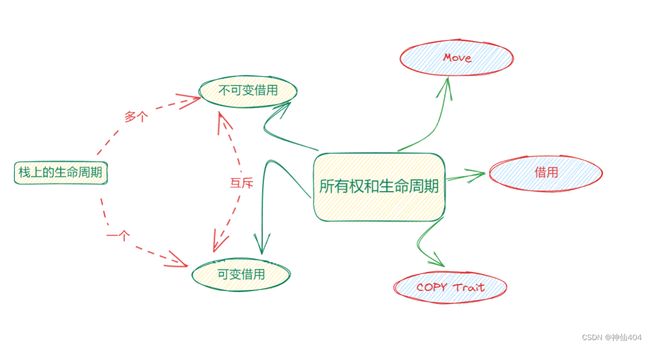
● 一个值在同一时刻只有一个所有者。当所有者离开作用域,其拥有的值会被丢弃。赋值或者传参会导致值 Move,所有权被转移,一旦所有权转移,之前的变量就不能访问。
● 如果值实现了 Copy trait,那么赋值或传参会使用 Copy 语义,相应的值会被按位拷贝(浅拷贝),产生新的值。
● 一个值可以有多个只读引用。
● 一个值可以有唯一一个活跃的可变引用。可变引用(写)和只读引用(读)是互斥的关系,就像并发下数据的读写互斥那样。
● 引用的生命周期不能超出值的生命周期。
二、智能指针
2.1 设计原因
rust 的基石是基于值的单一所有权进行内存管理。但规则总会有例外,对于需要共享的内存必须有一种方式可以绕过静态检查,以在运行时进行动态检查,rust 提供的方式就是智能指针。
2.2 Rc引用计数
std::rc::Rc
use std::rc::Rc;
fn main() {
let five = Rc::new(5);
let five1 = five.clone();
let five2 = five.clone();
// 5, 5, 5
println!("{}, {}, {}", five, five1, five2);
// 0x1d756ecf760, 0x1d756ecf760, 0x1d756ecf760
println!("{:p}, {:p}, {:p}", five, five1, five2);
}
对某个数据结构 T,我们可以创建引用计数 Rc,使其有多个所有者,Rc 会把对应的数据结构创建在堆上,后续可以通过 clone() 方法创建更多的所有者。
对一个 Rc 结构进行 clone(),不会将其内部的数据复制,只会增加引用计数。而当一个 Rc 结构离开作用域被 drop() 时,也只会减少其引用计数,直到引用计数为零,才会真正清除对应的内存。这个规则正好和上面示例中输出的结果相似。
问:为什么智能指针创建的内存不受到单一所有权的约束?在栈生命周期结束之后堆上的内存仍旧存在?
本质就是为什么引用计数可以跨越栈的生命周期存在的问题
可以先看一下下面这段 Rc::new函数的源码,虽然现在我还看不懂,
#[cfg(not(no_global_oom_handling))]
#[stable(feature = "rust1", since = "1.0.0")]
pub fn new(value: T) -> Rc<T> {
// There is an implicit weak pointer owned by all the strong
// pointers, which ensures that the weak destructor never frees
// the allocation while the strong destructor is running, even
// if the weak pointer is stored inside the strong one.
unsafe {
Self::from_inner(
Box::leak(Box::new(RcBox { strong: Cell::new(1), weak: Cell::new(1), value }))
.into(),
)
}
}
但我们可以看到,代码中使用了Box::leak方法,这个方法的主要作用是:该方法创建的对象,会从堆内存上泄漏出去,不受栈内存控制,是一个自由的、生命周期可以大到和整个进程的生命周期一致的对象。基于此,引用计数才能够像其他语言那样去动态的管理和使用内存。
2.3 基于Rc实现有向无环图(树)
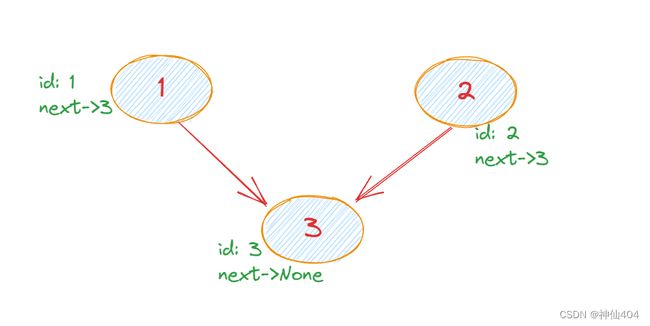
让我们从比较简单的一个例子出发,先创建一个具有如图所示关系的三个节点:
use std::rc::Rc;
#[derive(Debug)]
struct Node {
id: usize,
next: Option<Rc<Node>>,
}
impl Node {
pub fn new(id: usize) -> Self {
Self {
id,
next: None,
}
}
pub fn set_next(&mut self, next: Rc<Node>) {
self.next = Some(next);
}
pub fn get_next(&self) -> Option<Rc<Node>> {
let res = self.next.as_ref().map(|m| m.clone());
res
}
}
fn main() {
let mut node1 = Node::new(1);
let mut node2 = Node::new(2);
let mut node3 = Node::new(3);
// node1 and node2 都指向 node3
node1.set_next(Rc::new(node3));
node2.set_next(node1.get_next().unwrap());
// 查看node1和node2的值
// node1: Node { id: 1, next: Some(Node { id: 3, next: None }) }, node2: Node { id: 2, next: Some(Node { id: 3, next: None }) }
println!("node1: {:?}, node2: {:?}", node1, node2);
// 查看node1和node2的next的值
// 0x18693ac01f0, 0x18693ac01f0
println!("{:p}, {:p}", node1.get_next().unwrap(), node2.get_next().unwrap());
}
在上面的代码中我们根据上图所示的关系创建了三个节点,并输出了 node1 和 node2 的值,发现他们都指向 node3, 符合预期。同时我们打印出 node1 和 node2的 next 的值的地址发现他们也都指向相同的地址,这和我们对 Rc 智能指针的期盼作用一致。
2.4 RefCell解决Rc的局限性
上面的代码看起来好像没什么问题,但假如现在要通过 node2 指向的next指针修改 node3 的值,此时会发生什么情况?
可以将下面这段代码加入到上面 main 函数的末尾,
let mut node4 = Node::new(4);
let node3_ = node2.get_next().unwrap();
node3_.set_next(Rc::new(node4));
println!("{:?}", node3_);
然后你会发现编译器提示:Cannot borrow immutable local variable node3_ as mutable 。这是因为 Rc 是一个只读的引用计数器,你无法拿到 Rc 结构内部数据的可变引用,来修改这个数据。此时就需要用到 RefCell,和 Rc 类似,RefCell 也绕过了 Rust 编译器的静态检查,允许我们在运行时,对某个只读数据进行可变借用。
RefCell的根基:内部可变性

内部可变性指的是,有时候希望可以绕开编译器的外部可变性检查,对于未声明成 mut 的值或者引用,也可以进行修改。即在编译器的眼里,值是只读的,但是在运行时,这个值可以得到可变借用,从而修改内部的数据。下面是一个使用示例:
use std::cell::RefCell;
fn main() {
let data = RefCell::new(1);
{
// 使用{},提前结束RefCell可变借用的生命周期的原因是:
// 不允许在同一生命周期同时存在可变借用和不可变借用,避免下面的data.borrow()报错
let mut v = data.borrow_mut();
println!("{:?}", v); // 1
*v += 1;
println!("{:?}", v); // 2
}
// 2
println!("{:?}", data.borrow());
}
RefCell重构DAG的代码
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
struct Node {
id: usize,
next: Option<Rc<RefCell<Node>>>,
}
impl Node {
pub fn new(id: usize) -> Self {
Self {
id,
next: None,
}
}
pub fn set_next(&mut self, next: Rc<RefCell<Node>>) {
self.next = Some(next);
}
pub fn get_next(&self) -> Option<Rc<RefCell<Node>>> {
let res = self.next.as_ref().map(|m| m.clone());
res
}
}
fn main() {
let mut node1 = Node::new(1);
let mut node2 = Node::new(2);
let mut node3 = Node::new(3);
// node1 and node2 都指向 node3
node1.set_next(Rc::new(RefCell::new(node3)));
node2.set_next(node1.get_next().unwrap());
// 查看node1和node2的值
// node1: Node { id: 1, next: Some(RefCell { value: Node { id: 3, next: None } }) }, node2: Node { id: 2, next: Some(RefCell { value: Node { id: 3, next: None } }) }
println!("node1: {:?}, node2: {:?}", node1, node2);
// 查看node1和node2的next的值
// 0x20764c2ffe0, 0x20764c2ffe0
println!("{:p}, {:p}", node1.get_next().unwrap(), node2.get_next().unwrap());
// 校验内部可变性
let mut node4 = Node::new(4);
let node3_ = node2.get_next().unwrap();
node3_.borrow_mut().set_next(Rc::new(RefCell::new(node4)));
// RefCell { value: Node { id: 3, next: Some(RefCell { value: Node { id: 4, next: None } }) } }
println!("{:?}", node3_);
}
编译通过,通过使用Rc这样的嵌套结构,DAG 可以正常修改了。
2.5 Arc 和 Mutex/RwLock
Rc和RefCell在线程独占内存的情况下,实现引用计数和内部可变性,使得 rust 的内存使用像其他语言一样灵活。但是它们都不是线程安全的,即 Rc不是线程安全的引用计数器,RefCell也不能线程安全的使用内部可变性。好在 rust 为我们提供了解决方案。
线程安全的引用计数-Arc
Arc 内部的引用计数使用了 Atomic Usize ,而非普通的 usize。从名称上也可以感觉出来,Atomic Usize 是 usize 的原子类型,它使用了 CPU 的特殊指令,来保证多线程下的安全。如果对原子类型感兴趣,可以看 std::sync::atomic 的文档。
线程安全的Mutex 和 RwLock
如果我们要在多线程中,使用内部可变性,Rust 提供了 Mutex 和 RwLock。Mutex 和 RwLock 都用在多线程环境下,对共享数据访问的保护上。刚才构建的 DAG 如果要用在多线程环境下,需要把 Rc 替换为 Arc 或者 Arc。
三、生命周期标注
这一块的内容算是 rust 所服务于单一所有权的独特设计了,我试图在 cpp/java 中寻找类似的概念,但没有发现。

rust 要求对于函数的返回值在编译期间就确定生命周期,默认情况下,编译器会为我们自动标注生命周期,其规则如下:
● 所有引用类型的参数都有独立的生命周期 'a 、'b 等。
● 如果只有一个引用型输入,它的生命周期会赋给所有输出。
● 如果有多个引用类型的参数,其中一个是 self,那么它的生命周期会赋给所有输出。
但是当一个函数有多个引用类型的参数,且输出依赖于输入的时候(即输出可能是输入的借用,而不是新建的值的时候),如这段代码所示:
fn main() {
let s1 = String::from("Lindsey");
let s2 = String::from("Rosie");
let result = max(&s1, &s2);
println!("bigger one: {}", result);
}
fn max(s1: &str, s2: &str) -> &str {
if s1 > s2 {
s1
} else {
s2
}
}
此时编译器无法确定输出值的生命周期是s1还是s2的生命周期,所以需要人工介入进行标注,将上面的代码修改为下面这样既可以通过编译:
fn main() {
let s1 = String::from("Lindsey");
let s2 = String::from("Rosie");
let result = max(&s1, &s2);
println!("bigger one: {}", result);
}
fn max<'a>(s1: &'a str, s2: &'a str) -> &'a str {
if s1 > s2 {
s1
} else {
s2
}
}
3.1 函数标注规则
如 fn max<'a>(s1: &'a str, s2: &'a str) -> &'a str 所示
3.2 结构体标注规则
如下,需要注意标注数据结构时,数据结构自身的生命周期,需要小于等于其内部字段的所有引用的生命周期。
struct Employee<'a, 'b> {
name: &'a str,
title: &'b str,
age: u8,
}
下一篇:Rust系列(二) 内存管理