LVS+Keepalived群集
Keepalived是一个基于ARRP协议来实现的LVS服务高可用方案,可以解决静态路由出现的单点故障问题。
在一个LVS服务群集中通常有主服务器(Master)和备份服务器(Backup)两种角色的服务器,但是对外表现为一个虚拟IP,主服务器会发送VRRP通告信息给备份服务器。当备份服务器收不到VRRP消息的时候,即主服务器异常的时候,备份服务器就会接管虚拟IP,继续提供服务,从而保证了高可用性。
案例分析
企业应用中,单台服务器承担应用存在单点故障的危险;
单点故障一旦发生,企业服务将发生中断,造成极大危害。
只有一种报文:Advertisement报文(通告报文);其目 的IP地址是224.0.0.18,协议号是112。
常见的通告报文:
- ARP(Address Resolution Protocol)请求/应答报文:用于将IP地址映射到MAC地址。
- ICMP(Internet Control Message Protocol)报文:用于网络诊断、错误报告和路由器发现等操作。
- OSPF(Open Shortest Path First)链路状态通告(LSA)报文:用于向其他路由器通告链路状态信息,以维护路由表。
- BGP(Border Gateway Protocol)通告报文:用于将自治系统(AS)内的路由信息通告给其他AS。
- DHCP(Dynamic Host Configuration Protocol)通告报文:用于向客户端分配IP地址、子网掩码、网关和DNS服务器等信息。
- STP(Spanning Tree Protocol)BPDU(Bridge Protocol Data Unit)报文:用于交换机之间的拓扑发现和冗余拓扑计算。
一个健康的集群的特点:
1)能实现负载均衡
2)能实现健康检查(调度器,节点服务器):探针 心跳消息(ping)、tcp端口检查(三次握手)、HTTP URL检查
判断LVS负载调度器,节点服务器的可用性,当master主机出现故障及时切换到backup节点保证业务正常,当master故障主机回复后将其重新加入集群并且业务重新切换回master节点。
3)能实现故障切换
底层采用的是VRRP热备份协议,实现Linux服务器的多机热备功能
VRRP(虚拟路由冗余协议)是针对路由器的一种备份解决方案
- 有多台路由器组成一个热备组,通过公用的虚拟IP地址对外提供服务(VIP)
- 每个热备组内同时只有一台主路由器提供服务,其他路由器处于荣誉状态。
- 若当前在线的路由器失效,则其他路由器会根据设置的优先级自动接替虚拟IP地址,继续提供服务。
(若优先级一样,根据IP地址,谁的大,谁优先)
双击热备的故障切换是由虚拟IP地址的漂移来实现,适用于各种应用服务器。
实现基于Web服务的双机热备
Keepalived体系主要模块及作用
Keepalived体系架构中主要有三个模块:core、check和vrrp
- core模块:为keepalived的核心,负责主进程的启动、维护及全局配置文件的加载和解析
- vrrp模块:是来实现VRRP协议的
- check模块:负责健康检查,常见的方式有端口检查及URL检查
---------------------LVS 部署-------------------------
1.配置负载调度器(主、备相同)
systemctl stop firewalld.service
setenforce 0
yum -y install ipvsadm keepalived
modprobe ip_vs
cat /proc/net/ip_vs
(1)配置keeplived(主、备DR 服务器上都要设置)
cd /etc/keepalived/
cp keepalived.conf keepalived.conf.bak
vim keepalived.conf
主:
! Configuration File for keepalived
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id LVS_01
}
vrrp_instance VI_1 {
state MASTER
interface ens33
virtual_router_id 51
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.179.188
}
}
virtual_server 192.168.179.188 80 {
delay_loop 6
lb_algo rr
lb_kind DR
persistence_timeout 0
protocol TCP
real_server 192.168.179.22 80 {
weight 1
TCP_CHECK {
connect_port 80
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
real_server 192.168.179.23 80 {
weight 1
TCP_CHECK {
connect_port 80
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
~ 备:修改MASTER为BACKUP,修改router_id
! Configuration File for keepalived
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id LVS_02
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 51
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.179.188
}
}
virtual_server 192.168.179.188 80 {
delay_loop 6
lb_algo rr
lb_kind DR
persistence_timeout 0
protocol TCP
real_server 192.168.179.22 80 {
weight 1
TCP_CHECK {
connect_port 80
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
real_server 192.168.179.23 80 {
weight 1
TCP_CHECK {
connect_port 80
connect_timeout 3
nb_get_retry 3
delay_before_retry 3
}
}
}
systemctl start keepalived
ip addr #查看虚拟网卡vip
主: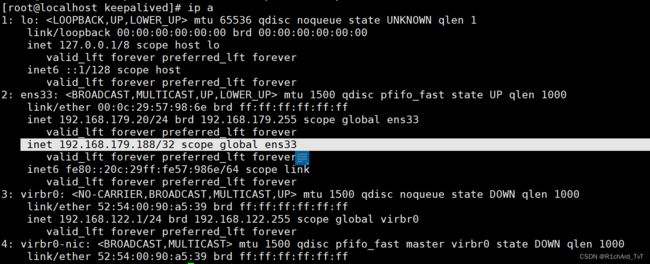
备: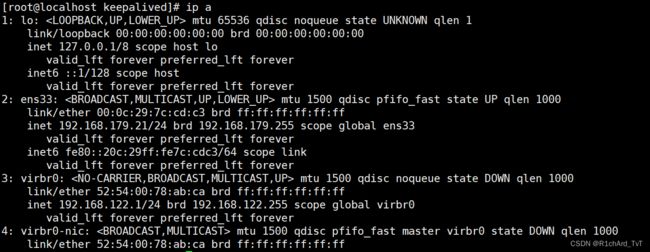
(2)启动 ipvsadm 服务
--192.168.179.20---
ipvsadm-save > /etc/sysconfig/ipvsadm #不然会报错
systemctl start ipvsadm
ipvsadm -ln
#如没有VIP 的分发策略,则重启 keepalived 服务,systemctl restart keepalived
--192.168.179.21---
ipvsadm-save > /etc/sysconfig/ipvsadm
systemctl start ipvsadm
ipvsadm -ln
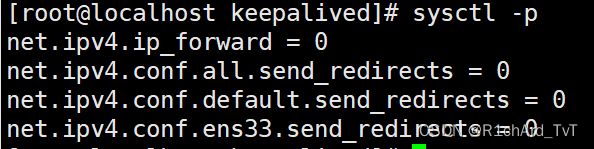
(3)调整 proc 响应参数,关闭Linux 内核的重定向参数响应
vim /etc/sysctl.conf
net.ipv4.ip_forward = 0
net.ipv4.conf.all.send_redirects = 0
net.ipv4.conf.default.send_redirects = 0
net.ipv4.conf.ens33.send_redirects = 0
sysctl -p
-----------------在Web服务器下载nginx---------------
cd /usr/share/nginx/html
mkdir test
echo 'this is nginx 1 test web!' > /test/test.html
scp -r test 192.168.179.21:`pwd`配置网卡
vim /etc/sysconfig/network-scripts/ifcfg-lo:0
DEVICE=lo:0
ONBOOT=yes
IPADDR=192.168.179.188
NETMASK=255.255.255.255
service network restart 或 systemctl restart network或systemctl restart --now network
ifup lo:0
ifconfig lo:0
route add -host 192.168.80.188 dev lo:0
route -n 查看
vim /etc/sysctl.conf
net.ipv4.conf.lo.arp_ignore = 1
net.ipv4.conf.lo.arp_announce = 2
net.ipv4.conf.all.arp_ignore = 1
net.ipv4.conf.all.arp_announce = 2
sysctl -p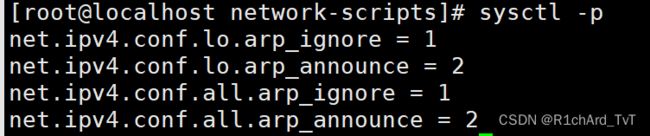
3.测试验证
在客户端访问 http://192.168.179.188/
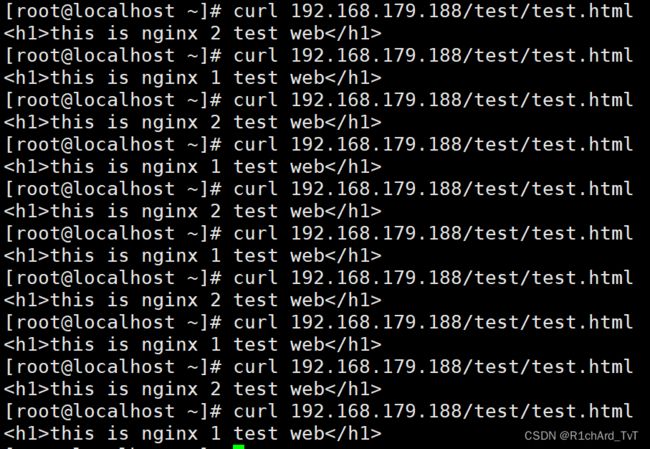

再在主服务器关闭 keepalived 服务后再测试, systemctl stop keepalived
Keepealived最常见的问题是会出现脑裂现象:
排查思路:网卡:通过tcpdump抓包,网卡有没有接收到数据包。如果收到,问题在服务器端;
Master一直发送心跳消息给backup主机,如果中间的链路突然断掉,backup主机将无法收到master主机发送过来的心跳消息(也就是vrrp报文),backup这时候会立即抢占master的工作,但其实这时候的master是正常工作的,此时就会出现脑裂的现象。
预防:1.使用shell脚本对这两个主机之间的连通性进行监测,如果发现有问题,就会立即关闭keepalived服务来防止脑裂的产生。
2.增加一条链路作为备用链路,即使主链路挂掉了,备用链路也会顶上来,master主机可以继续给backup主机发送心跳消息。
3.使用监控软件的方法,这边主要是采用的zabbix来监控的,主要就是创建监控项,创建触发器来测试关闭keepalived服务。
判断进程是否存在
ps -ef | grep nginx | egrep -cv "grep|$$"
ss -lntp | grep nginx
netstat -lntp | grep nginx
killall -0 nginx echo $?