用python获取一个网页里面表格的数据
demo1
比如我想要这个网址 https://zh.wikipedia.org/zh-cn/ISO_3166-1 下的国际地区代码列表
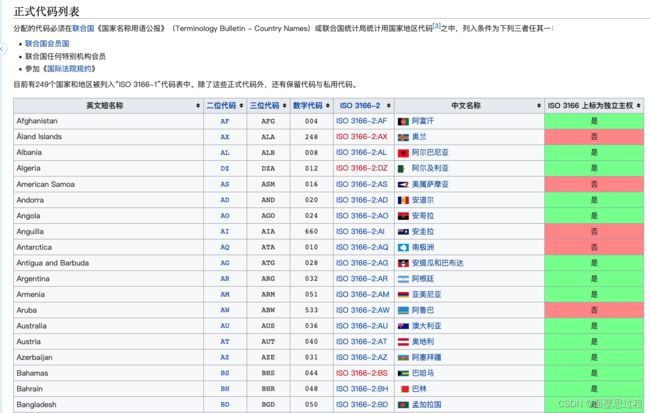
第一步F12查看这个部分的结构。结构如下 是一个table>tr>td

py代码如下
import requests
from bs4 import BeautifulSoup
url = "https://zh.wikipedia.org/zh-cn/ISO_3166-1"
# 发送请求并获取响应内容
response = requests.get(url)
html_content = response.text
# 使用BeautifulSoup库解析HTML内容
soup = BeautifulSoup(html_content, 'html.parser')
# 查找表格元素
table = soup.find('table')
# 获取所有行
rows = table.find_all('tr')
# 创建空列表来存储数据
data = []
# 遍历所有行,并将每行的所有单元格的文本添加到列表中
for row in rows:
cells = row.find_all('td')
if len(cells) > 1:
row_data = [cell.text.strip() for cell in cells]
# data.append(row_data)
data.append({
"en": row_data[0],
"short": row_data[1],
"shortLen3": row_data[2],
"numberCode": row_data[3],
"iso": row_data[4],
"name": row_data[5],
"isTndependent": row_data[6],
})
# 输出列表
print(data)返回的结构是这样的
[
{
"en": "Afghanistan",
"short": "AF",
"shortLen3": "AFG",
"numberCode": "004",
"iso": "ISO 3166-2:AF",
"name": "阿富汗",
"isTndependent": "是"
},
{
"en": "Åland Islands",
"short": "AX",
"shortLen3": "ALA",
"numberCode": "248",
"iso": "ISO 3166-2:AX",
"name": "奥兰",
"isTndependent": "否"
},
....省略其他
]demo2
下面网址是国际电话区号列表
https://zh.wikivoyage.org/zh-cn/%E5%9B%BD%E9%99%85%E7%94%B5%E8%AF%9D%E5%8C%BA%E5%8F%B7%E5%88%97%E8%A1%A8
同样的方法查看结构
py代码如下
import requests
from bs4 import BeautifulSoup
url = "https://zh.wikivoyage.org/zh-cn/%E5%9B%BD%E9%99%85%E7%94%B5%E8%AF%9D%E5%8C%BA%E5%8F%B7%E5%88%97%E8%A1%A8"
# 发送请求并获取响应内容
response = requests.get(url)
html_content = response.text
# 使用BeautifulSoup库解析HTML内容
soup = BeautifulSoup(html_content, 'html.parser')
# 查找表格元素
table = soup.find('table')
# 获取所有ul
rows = table.find_all('ul')
# 获取所有li
lis=table.find_all('li')
# 创建空列表来存储数据
data = []
# 遍历所有li,并将每行的所有单元格的文本添加到列表中
# for li in lis:
# if len(li) > 1:
# data.append(li.text.strip())
# 简写方法
data = [li.text.strip() for li in lis]
# 输出列表
print(data)返回的结果是这样的
['也门 967', '赞比亚 260', '津巴布韦 263',.....省略]具体应用根据自己想要的数据格式获取就行