【论文阅读20】Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference
论文相关
- 论文标题:Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference(利用完形填空进行零样本文本分类和自然语言推理)
- 发表时间:2021
- 领域:自然语言处理-提示学习经典论文
- 发表期刊:EACL2021(A级学术会议)
- 相关代码:https://github.com/timoschick/pet.
- 数据集:
摘要
一些NLP任务可以通过提供一个具有自然语言中的“任务描述”的预先训练好的语言模型,以一种完全无监督的方式来解决。虽然这种方法的性能逊于其有监督的对应方法,但我们在这项工作中表明,这两种想法可以结合起来:我们引入了模板开发训练(PET),这是一种半监督的训练程序,它将输入的示例重新定义为完形填空式的短语,以帮助语言模型理解给定的任务。然后,这些短语被用来为大量未标记的示例分配软标签。最后,对所得到的训练集进行标准的监督训练。对于几种任务和语言,PET在低资源设置下的表现大大优于监督训练和强半监督方法。
1.引言
从实例中学习是许多自然语言处理任务的主要方法,一个模型在一组有标记的例子上进行训练,然后再将其推广到看不见的数据。由于大量的语言、域和任务以及注释数据的成本,在现实世界的NLP使用中,通常只有少量标记的示例,使得学习很少 这是一个非常重要的研究领域。不幸的是,将标准的监督学习应用于小的训练集通常表现得很差;仅仅从几个例子来看,许多问题都很难理解。例如,假设我们得到了以下的文本片段:
- T1: This was the best pizza I’ve ever had.
- T2: You can get better sushi for half the price.
- T3: Pizza was average. Not worth the price

图1:PET用于情感分类(1)创建了许多编码某种形式的任务描述的模板,将训练示例转换为完形填空问题;对于每个模式,都一个预先训练的语言模型。(2)训练过的模板的集成会对未标记的数据进行注释。(3)在所得到的软标记数据集上训练一个分类器。
此外,想象我们被告知 T 1 T_1 T1和 T 2 T_2 T2的标签是l和l’,并且我们被要求推断出T3的正确标签。仅基于这些例子,这是不可能的,因为对于l和l‘都可以找到合理的理由。然而,如果我们知道潜在的任务是确定文本中是否提到了价格,我们就可以很容易地将l’分配给 T 3 T_3 T3。这说明,当我们也有一个任务描述时,仅从几个例子解决任务就变得容易得多,也就是说,一个文本解释,帮助我们理解任务的内容。
随着预训练语言模型(PLMs)的兴起,如GPT、BERT和RoBERTa等,使得在神经结构中,提供任务描述的想法已经变得可行:我们可以简单地用自然语言将这些描述添加到一个输入中,并且让PLM预测解决任务地连续性。到目前为止,这个想法大多是在根本没有训练数据的零样本场景中考虑的。
在这项工作中,我们证明了提供任务描述可以成功地与标准监督学习在少样本中设置:我们引入了模板开发训练(PET),这是一种半监督的训练程序,它使用自然语言模式将输入的示例重新表述成完型填空式的短语。如图1所示,PET的工作原理分为三个步骤:
- 首先,对于每个模板,在一个小的训练集T上细化一个单独的PLM。
- 然后,所有模型的集成用软标签标注一个大的未标记数据集D。
- 最后,在软标记数据集上训练一个标准的分类器。
我们还设计了iPET,一个PET的迭代变体,其中这个过程随着训练集的大小的增加而重复。
在多种语言的不同任务集上,我们表明,给定一个小到中等数量的有标记的例子,PET和iPET大大优于无监督方法、监督训练和强半监督基线。
2.相关工作
- Radford等人(2019年)以自然语言模式的形式提供了提示,用于零样本学习的具有挑战性的任务,如阅读理解和问题回答(QA)。这一想法已被应用于无监督文本分类(Puri和Catanzaro,2019年)、常识性知识挖掘(Davison et al.,2019年)和争论关系分类(Opitz,2019年)。
- Srivastava等人(2018)使用任务描述进行零样本分类,但需要一个语义解析器。
- 对于关系提取,Bouraoui等人(2020)自动识别表达给定关系的模式。
- McCann等人(2018)将一些任务重新定义为QA问题。
- Raffel等人(2020)将各种问题框架为语言建模任务,但它们的模式只是松散地类似于自然语言,不适合零样本学习。
另一项最近的工作使用完形填空的短语来探究plm在训练前过程中获得的知识;这包括探索事实、常识知识、语言能力、对罕见词语的理解和执行符号推理的能力。考虑一下如何找到表达给定任务的最佳模式的问题。
NLP中的其他零样本学习方法包括利用相关任务中的例子和使用数据增强;后者通常依赖于反向翻译,需要大量的并行数据。使用文本类描述符的方法通常假设类的子集有大量的示例。相比之下,我们的方法不需要额外的标记数据,并提供了一个直观的界面来利用特定于任务的人类知识。
iPET背后的想法——在前几代标记的数据上训练多代模型——与消除词义模糊、关系提取、分词、机器翻译和序列生成的自我训练和引导方法相似。
3.模板运用训练
设M是一个具有词汇表V和掩码标记____∈V的掩码语言模型,并设L是我们的目标分类任务A的一组标签.我们写成一个短语序列 X = ( s 1 , s 1 , . . . . . s k ) X=(s_1,s_1,.....s_k) X=(s1,s1,.....sk)作为任务A地输入,其中 s i ∈ V ∗ s_i∈V^* si∈V∗;例如,k=2,如果A是文本推理。我们将一个模板定义为一个函数P,它以x作为输入,并输出一个恰好包含一个掩码标记的短语或句子 P ( x ) ∈ V ∗ P (x)∈V^∗ P(x)∈V∗,也就是说,它的输出可以看作是一个完形填空问题。此外,我们将一个语言表达器定义为一个内射函数v: L→v,它将每个标签映射到M的词汇表中的一个单词。我们将(P、v)称为模板-语言表达器对(PVP)。
使用PVP(P,v)使我们能够解决任务A如下:给定一个输入x,我们应用P包含一个输入表示P (x),然后由M处理,以确定标签y∈L是最有可能掩码替代结果过v(y)。例如,考虑确定两个句子a和b是否相互矛盾(标签 y 0 y_0 y0)或是否相互一致( y 1 y_1 y1)的任务。对于这个任务,我们可以选择模板P(a,b)= a?___, b.结合一个将 y 0 y_0 y0映射到“yes”和 y 1 y_1 y1映射到“no”的表达器v。给定一个示例输入对:
x = (Mia likes pie, Mia hates pie)
现在的任务必须分配一个没有固有意义的标签,到回答是否最可能选择的掩码位置:
P(x) = Mia likes pie? , Mia hates pie.
是“yes”还是“no”
3.1 PVP训练和推理
设p =(P,v)是一个PVP。我们假设有一个小的训练集T和一个(通常更大的)未标记的例子D。对于每个序列 z ∈ V ∗ z∈V^∗ z∈V∗,它只包含一个掩码标记和w∈V,我们用M(w | z)表示语言模型在掩码位置分配给w的非标准化分数。给定一些输入x,我们将标签l∈L的分数定义为:
s p ( l ∣ x ) = M ( v ( l ) ∣ P ( x ) ) s_p(l | x) = M(v(l) | P(x)) sp(l∣x)=M(v(l)∣P(x))
并使用softmax得到标签上的概率分布:
q p ( l ∣ x ) = e s p ( l ∣ x ) ∑ l ′ ∈ L e s ( l ′ ∣ x ) q_p(l | x)=\frac{e^{s_p(l|x)}}{\sum_{l'∈L}^{} e^s(l'|x)} qp(l∣x)=∑l′∈Les(l′∣x)esp(l∣x)
在 q p ( l ∣ x ) q_p(l|x) qp(l∣x)和训练样本(x,l)的真实分布之间,对所有(x,l)∈T求和,使用交叉熵对p的微调M的损失。
3.2 辅助语言建模
在我们的应用程序场景中,只有少数的训练示例可用,并且可能会发生灾难性的遗忘。由于对一些PVP的PLM进行微调仍然是一个语言模型的核心,我们通过使用语言建模作为辅助任务来解决这个问题。用 L C E L_{CE} LCE表示交叉熵损失和 L M L M L_{MLM} LMLM语言建模损失,我们计算最终损失为
L = ( 1 − α ) ∗ L C E + α ⋅ L M L M L=(1- \alpha)*L_{CE}+\alpha·L_{MLM} L=(1−α)∗LCE+α⋅LMLM
最近,Chronopoulou等人(2019年)在一个数据丰富的场景中应用了这一想法。由于 L M L M L_{MLM} LMLM通常比 L C E L_{CE} LCE大得多,在初步实验中,我们发现α= 1 0 − 4 10^{−4} 10−4的值很小,可以始终能得到良好的结果,所以我们在所有的实验中都使用它。为了获得用于语言建模的句子,我们使用了未标记的句子集D。然而,我们并不是直接在每个x∈D上训练,而是在P (x)上训练,其中我们从不要求语言模型预测mask槽的任何东西。
3.3 结合PVP
我们的方法面临的一个关键挑战是,在缺乏大型开发集的情况下,很难确定哪些pvp表现良好。为了解决这个问题,我们使用了一种类似于知识蒸馏的策略.首先,我们定义了一组PVPs的直观意义的P。然后我们使用这些PVPs如下:
1)如第3.1节所述,我们为每个p∈P微调了一个单独的语言模型Mp。由于T很小,这种微调即使是对大量的pvp的代价都是很小的。
2) 我们使用精细模型的集成 M = M p ∣ p ∈ P M = {M_p | p∈P} M=Mp∣p∈P来注释来自D的例子。我们首先将每个例子x∈D的非标准化类分数合并为:
S M ( l ∣ x ) = 1 Z ∑ p ∈ P w ( p ) ⋅ s p ( l ∣ x ) S_M(l|x)=\frac{1}{Z}{\sum_{p∈P}w(p)·s_p{(l|x)}} SM(l∣x)=Z1p∈P∑w(p)⋅sp(l∣x)
其中, Z = ∑ p ∈ P w ( p ) Z=\sum{p∈P}^{w(p)} Z=∑p∈Pw(p)和 w(p)是 p v p s pvp_s pvps的加权项。我们用这个权重项的两种不同的实现进行实验:要么我们简单地将所有的p设置为w (p) = 1,要么我们将w (p)设置为训练前在训练集上使用p获得的精度。我们将这两个变体称为统一的和加权的。Jiang等人(2020)在零样本学习设置中使用了类似的想法。
我们使用softmax将上述分数转换为概率分布q。继Hinton等人(2015)之后,我们使用T = 2的温度来获得适当的软分布。所有的对(x、q)都被收集在一个(软标记的)训练集 T C T_C TC中。
3)我们在 T C T_C TC上找到了一个具有标准序列分类头的PLM C。
精细的模型C作为A的类定义符。上面描述的所有步骤都如图2所示;图1中显示了一个示例。
3.4 迭代PET(iPET)
将所有单个模型的知识提炼成一个单一的分类器C意味着它们不能相互学习。由于某些模板的表现(可能会如此)比其他模板更差,因此,我们最终模型的训练集 T C T_C TC可能包含许多错误标记的例子。
为了弥补这个缺点,我们设计了iPET,一个PET的迭代变体。iPET的核心思想是在规模不断增大的数据集上训练几代模型。为此,我们首先扩大原始数据集T,通过使用训练过的PET模型的随机子集来标记从D中选择的例子来扩大原始数据集T(图2a)。然后,我们在放大的数据集(b)上训练新一代的PET模型;这个过程重复了几次©.
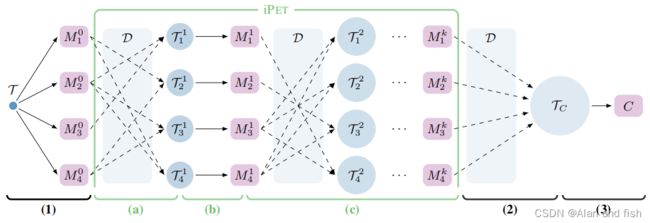
图2: P E T ( 1 − 3 ) P_{ET}(1-3) PET(1−3)和 i P E T ( a − c ) iP_{ET}(a-c) iPET(a−c)的示意图表示。(1)利用初始训练集来微调PLMs的集合。(a)对于每个模型,其他模型的随机子集通过标记D的例子生成一个新的训练集。(b)一套新的PET模型使用更大的、特定于模型的数据集进行训练。©前两个步骤重复k次,每次将生成的训练集的大小增加d倍。(2)最后一组模型用于创建一个软标签数据集TC。(3)在这个数据集上训练了一个分类器C。
更正式地说,让 M 0 = M 1 0 , … … , M n 0 M^0 = {M_1^0,……,M^0_n} M0=M10,……,Mn0是在T上微调的PET模型的初始集合,其中每个 M i 0 M_i^0 Mi0都被训练成一些 P V P p i PVP p_i PVPpi。我们训练k代模型 M 1 , … , M k M^1,…,M^k M1,…,Mk,其中 M j = M 1 j , … , M n j M^j = {M ^j _1,…,M^j_n} Mj=M1j,…,Mnj,每个 M j i M^i _j Mji在它自己的训练集 T i j T^j_i Tij上训练 p i p_i pi。在每次迭代中,我们将训练集的大小乘以一个固定的常数d∈N,同时保持原始数据集的标签比率。也就是说,用 c 0 ( l ) c_0(l) c0(l)表示T中带有标签为l的示例数,每个 T i j T^j_i Tij包含带有标签为l的 c j ( l ) = d ⋅ c j − 1 ( l ) c_j (l) = d·c_{j−1(l)} cj(l)=d⋅cj−1(l)示例。这是通过生成以下每个 T j i T^i_j Tji来实现的:
1.我们从选择上一代中选择一个超参数λ,λ∈(0,1],随机选择 λ·(n-1)个模型得到 N ⊂ M j − 1 N⊂M^{j−1} N⊂Mj−1 或 M i j − 1 {M_i^{j−1}} Mij−1。
2.使用这个子集,我们创建了一个有标记的数据集

对于每个l∈L,我们随机从含有标签l的样本中选择 c j ( l ) − c 0 ( l ) c_j ^{(l)}−c_0^{(l)} cj(l)−c0(l)例子,标签l来自于 T N T_N TN。为了避免用错误标记的数据训练后代,我们更喜欢模型集合对其预测有信心的例子。潜在的直觉是,即使没有校准,标签被预测具有高可信度的例子通常更有可能被正确分类。因此,当从 T N T_N TN中提取时,我们设置每个(x,y)的概率与 s N ( l ∣ x ) s_N(l | x) sN(l∣x)成比例。
3.我们定义了 T j i = T ∪ S l ∈ L T N ( l ) T^i_ j = T∪S_{l∈L}T_N(l) Tji=T∪Sl∈LTN(l)。由于很容易验证,这个数据集包含 c j ( l ) c_j (l) cj(l)个示例,每个l∈L。
在训练了k代的PET模型后,我们使用 M k M^k Mk来创建 T C T_C TC,并像在基础的PET中那样训练C。
只要稍加调整,iPET甚至就可以用于零样本设置。为此,我们将M0定义为未经训练的模型集,以及c1(l)=10/|L|,以便M1在均匀分布在所有标签上的10个例子上进行训练。因为对于一些标签l而言,TN可能没有中可能没有足够的样本,因此我们创建所有的TN(l)是从100个样本X中采样得到,x∈D,即是 l ≠ a r g m a x l ∈ L S N ( l ∣ x ) l≠arg max_{l∈L}SN(l|x) l=argmaxl∈LSN(l∣x),其中sN(l|x)是最高的.对于每一代,我们完全按照基本iPET进行。
4.实验
我们在四个英语数据集上评估了PET:Yelp Reviews,AG’s News,Yahoo Questions和 MNLI。此外,我们使用x-stantes来研究PET对其他语言的作用如何。对于所有的英语实验,我们使用RoBERTa large作为语言模型;对于所有的英语实验,我们使用RoBERTa large(Liu et al.,2019)作为语言模型;我们调查了不同训练集大小下的PET和所有基线的性能;每个模型使用不同的种子进行训练三次,并报告平均结果。
当我们考虑少样本设置时,我们假设无法访问可以优化超参数的大型开发集。因此,我们对超参数的选择是基于在以前的工作中所做的选择和实际的考虑。我们使用的学习率为1·10−5,批量大小为16,最大序列长度为256。除非另有说明,否则我们总是使用带有辅助语言建模的PET的加权变体。对于iPET,我们设置λ=为0.25和d=为5;也就是说,我们选择所有模型中的25%来标记下一代示例,并在每次迭代中将训练示例的数量增加五倍。我们训练新一代,直到每个模型都训练了至少1000个例子,即,我们设置了 k = [ l o g d ( 1000 / ∣ T ∣ ) ] k = [log_d(1000/|T |)] k=[logd(1000/∣T∣)]。由于我们总是重复训练三次,n个PVPs的集成M(orM0)包含3n个模型。n个PVPs的集成M(或者 M 0 M^0 M0)包含3n个模型。
4.1 模板
我们现在描述用于所有任务的模式和语言器。我们使用两个竖条(||)来标记文本段之间的边界。
Yelp 为Yelp评论全星数据集,这项任务是根据顾客的评论文本来估计他们对一家餐馆的1到5星的评分。我们为输入文本a定义了以下模板:

我们为所有模式定义一个单一的表达器v为:
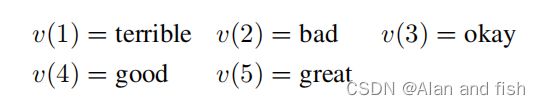
AG’s News AG’s News是一个新闻分类数据集,如果给定一个标题a和正文b,新闻必须被归类为属于World (1), Sports (2), Business (3)或者 Science/Tech (4)当中的一个。对于x =(a,b),我们定义了以下模板:

我们使用一个语言工具,分别将1-4映射到“World”,“Sports”, “Business” and “Tech”, respectively.
Yahoo Yahoo Questions是文本分类数据集。给定一个问题a和一个答案b,必须分配十个可能的类别中的一个。我们使用与AG’s News相同的模板,但我们将 P 5 P5 P5中的“news”替换为“quesion”。我们定义了一个将类别1-10映射到“Society”,“Science”, “Health”, “Education”, “Computer”,“Sports”, “Business”, “Entertainment”, “Relationship” and “Politics”.
MNLI MNLI数据集由文本对x =(a,b)组成。这个任务是查明a是否意味着b (0)、a和b是否相互矛盾(1)或两者都不矛盾(2)。我们定义

并考虑两种不同的语言表达器v1和v2:

将这两种模式与两个语言表达器相结合,总共得到4个pvp。
X-Stance x-stance数据集是一个多语言姿态检测数据集,其中有德语、法语和意大利语的例子。每个示例x =(a,b)由一个关于一些政治问题的问题a和一个评论b组成;这个任务是用于判断作者是(0)否(1)支持问题。我们使用了两个简单的模式:

定义一个英语语言器,映射0到“是”和1到“否” 以及法语(德语)表达器 V F r ( v D e ) V_{Fr}(v_{De}) VFr(vDe),将“Yes”和“No”替换为“Oui”和“Non”(“Ja”和“Nein”)。我们没有定义意大利语,因为x-stant不包含任何意大利训练例子。
4.2 实验结果

**表1:在Yelp上的RoBERTa(大)的平均精度和标准偏差, Yelp, AG’s News, Yahoo and MNLI (m:匹配/mm:不匹配)五个训练集的大小为|T| **
英文数据集 表1为英语文本分类和语言理解任务的结果;我们报告了三次训练运行的平均准确性和标准偏差。第1-2行(L1-L2)显示了无监督的性能,即,未经任何训练的个人pvp。我们给出了所有PVPs的平均结果(avg),以及在测试集上最有效的PVP的结果(max)。两行之间的巨大差异突出了应对这样一个事实的重要性,即在不查看测试集的情况下,我们就没有方法来评估哪些pvp表现良好。零样本的iPET明显优于所有数据集的无监督基线;在 AG’s News数据集上,它甚至比有1000个例子(L3 vs L13)的标准监督训练表现得更好。只有10个训练例子,标准的监督学习的表现不会高于概率(L4)。相比之下,PET(L5)比完全无监督基线(L1-L2);使用iPET(L6)训练多代人可以得到一致的改进。随着我们增加了训练集的大小,PET和iPET的性能提高变得更小,但对于50和100个例子。PET继续显著优于标准的监督训练(L8 vs L7,L11 vs L10),而iPET(L9,L12)仍然能提供持续的改善。对于|T | = 1000,PET在AG的任务上没有优势,但仍然提高了所有其他任务的准确性(L14 vs L13)。
与SotA比较 我们比较了PET与UDA和MixText,这两种最先进的半监督学习方法。PET要求一个任务可以用模式来表达,并且可以找到这样的模式,而UDA和MixText都使用反向翻译,因此需要数千个有标记的示例来训练一个机器翻译模型。我们使用RoBERTa(基础)来进行比较,因为MixText是需要一个12层的transformer。Xie等人(2020年)和Chen等人(2020年)都使用大型开发集来优化训练步骤的数量。相反,我们直接在测试集上尝试了这两种方法的几个值,并且只报告所获得的最佳结果。尽管如此,表2显示,PET和iPET在所有任务上都大大优于这两种方法,这清楚地证明了以pvp的形式整合人类知识的好处。
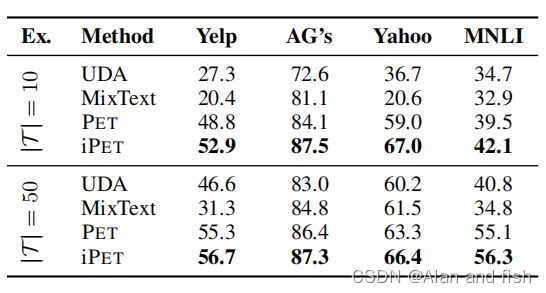
表2:使用RoBERTa(基础)的PET与两种最先进的半监督方法的比较
X-Stance 我们评估x-sante,以调查(i)它是否适用于英语以外的语言,(ii)当训练集具有中等大小时,它是否也会带来改进。与Vamvas和Sennrich(2020)相比,我们没有在dev上执行任何超参数优化,而是使用更短的最大序列长度(256 vs 512)来加速训练和评估。
为了调查PET是否能带来好处,我们考虑的训练集的大小分别为1000、2000和4000;对于这些配置,我们分别微调了法语和德语模型,以允许对训练数据进行更直接的降采样。此外,我们在整个法国(|TFr| = 11 790)和德国(|TDe| = 33 850)训练集上对模型进行训练。在这种情况下,我们没有任何额外的未标记数据,所以我们简单地设置了D = T。对于法国模型,我们使用 v E n v_{En} vEn和 v F r v_{Fr} vFr作为语言,对于德语 v E n v_{En} vEn和 v D e v_{De} vDe(第4.1节)。最后,我们还研究了使用 v E n v_{En} vEn、 v F r v_{Fr} vFr和 v D e v_{De} vDe在法国和德国数据( ∣ T F r + T D e ∣ = 45640 |T_{Fr} + T_{De}| = 45 640 ∣TFr+TDe∣=45640)上联合训练的模型的性能。

表3:在TDe和TFr子集上训练的XLM-R(基础)和在所有数据(TDe +联合训练)的目标内结果。(*):在Vamvas和Sennrich中报道的mBERT的最佳结果(2020年)。
结果如表3所示;以下是Vamvas和 Sennrich (2020),我们报告了标签0和标签1的F1分数的宏观平均值,平均超过三次运行。对于意大利语(列“It”栏),我们报告了德语和法语模型的平均零样本跨语言表现,因为没有意大利语训练的例子。我们的研究结果表明,PET在所有语言中都带来了巨大的改进,即使是在训练超过一千个例子的时候;它还大大提高了零镜头的跨语言性能。
5.分析
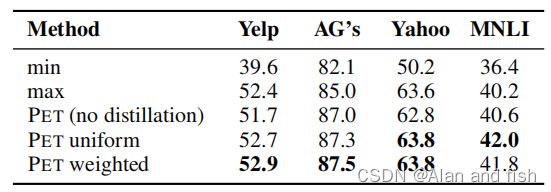
表4:基于单个PVPs以及有知识蒸馏和无知识蒸馏的模型的最小(最小)和最大(最大)精度的PET精度(|T | = 10)。
Combining PVPs 我们首先调查PET是否能够处理一些PVPs表现差的情况。对于|T | = 10,表4比较了PET的性能与微调后的最佳和最差表现模式的性能;我们还包括使用没有知识蒸馏对应的 P V P s PVP_s PVPs的结果。即使经过微调,最佳模式和最坏模式之间的差距也很大,特别是对于Yelp。然而,PET不仅能够弥补这一点,而且甚至比在所有任务中只使用表现最好的模式提高了准确性。蒸馏法给整体结构带来了持续的改进;它显著地减小了最终分类器的大小。我们发现PET的均匀变量和加权变量之间没有明显的差异。
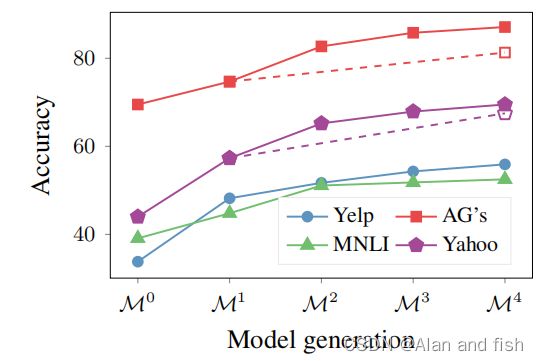
图4:在零样本设置下,使用iPET的每一代模型的平均精度。在AG’s News和Yahoo上,跳过第二代和第三代的准确性通过虚线表示。
辅助语言建模 分析了辅助语言建模任务对PET性能的影响。图3显示了为四种训练集大小添加语言建模任务后的性能改进。我们看到,当只训练10个例子时,辅助任务是非常有价值的。有了更多的数据,它就变得不那么重要了,有时甚至会导致更糟糕的性能。只有对于MNLI,我们发现语言建模始终有帮助。

图5:监督学习的准确性(补充)和PET在Yelp上的预训练(PT)
迭代PET 为了检查iPET是否能够在多个代过程中改进模型,图4显示了在零样本设置下所有代模型的平均性能。每一次额外的迭代都确实进一步提高了集成的性能。我们没有调查继续这个过程进行更多的迭代是否会有进一步的改进。另一个自然的问题是,通过更积极地增加训练集的大小,是否可以通过更少的迭代获得类似的结果。为了回答这个问题,我们跳过了AG’s News和Yahoo的第2代和第3代,对于这两个任务,我们直接让集成KaTeX parse error: Expected 'EOF', got '&' at position 2: M&̲^1为 M 4 M^4 M4注释了 10 ⋅ 5 4 10·5^4 10⋅54 个例子.如图4通过虚线所示,这显然导致了更差的性能,突出了仅逐渐增加训练集大小的重要性。我们推测这是事实,因为过早地注释太多的示例会导致很大一部分错误标记的训练示例。
域内预训练
与我们的监督基线不同,PET使用了额外的未标记数据集D。因此,至少有一些PET对监督基线的性能提高可能来自于这些额外的域内数据。为了验证这一假设,我们只是在域内数据上对RoBERTa进行预训练,这是一种提高文本分类精度的常用技术.由于语言模型预训练在GPU使用方面是昂贵的,所以我们只对Yelp数据集这样做。图5显示了有和没有这种顽强的预训练的监督学习和PET的结果。虽然预训练确实提高了监督训练的准确性,但监督模型的表现仍然明显比PET更差,这表明我们的方法的成功并不仅仅是由于使用了额外的未标记数据。有趣的是,领域内的预训练也有助于PET,这表明PET以一种与标准掩蔽语言模型的预训练明显不同的方式利用了未标记的数据。
6.总结
我们已经证明,为预先训练好的语言模型提供任务描述可以与标准的监督训练相结合。我们提出的方法,PET,包括定义对的问题模式和语言,帮助利用预先训练的语言模型中包含的知识用于下游任务。我们对所有模式-表达器对进行微调模型,并使用它们来创建大型注释数据集,并可以在其上训练标准分类器。准监督训练和强半监督方法有很大的改进。