CV常用注意力机制总结
本文总结了近几年CV领域常用的注意力机制,包括:SE(Squeeze and Excitation)、ECA(Efficient Channel Attention)、CBAM(Convolutional Block Attention Module)、CA(Coordinate attention for efficient mobile network design)
一、SE
目的是给特征图中不同的通道赋予不同的权重,步骤如下:
- 对特征图进行Squeeze,该步骤是通过全局平均池化把特征图从大小为(N,C,H,W)转换为(N,C,1,1),这样就达到了全局上下文信息的融合
- Excitation操作,该步骤使用两个全连接层,其中第一个全连接层使用ReLU激活函数,第二个全连接层采用Sigmoid激活函数,目的是将权重中映射到(0,1)之间。值得注意的是,为了减少计算量进行降维处理,将第一个全连接的输出采用输入的1/4或者1/16
- 通过广播机制将权重与输入特征图相乘,得到不同权重下的特征图

代码实现如下,
import torch
import torch.nn as nn
class Se(nn.Module):
def __init__(self, in_channel, reduction=16):
super(Se, self).__init__()
self.pool = nn.AdaptiveAvgPool2d(output_size=1)
self.fc = nn.Sequential(
nn.Linear(in_features=in_channel, out_features=in_channel//reduction, bias=False),
nn.ReLU(),
nn.Linear(in_features=in_channel//reduction, out_features=in_channel, bias=False),
nn.Sigmoid()
)
def forward(self,x):
out = self.pool(x)
out = self.fc(out.view(out.size(0),-1))
out = out.view(x.size(0),x.size(1),1,1)
return out*x二、ECA
可参考《注意力机制 ECA-Net 学习记录_eca注意力机制_chen_zn95的博客-CSDN博客》
ECA也是一个通道注意力机制,该算法是在SE的基础上做出了一定的改进,首先ECA作者认为SE中的全连接降维可以降低模型的复杂度,但这也破坏了通道与其权重之间的直接对应关系,先降维后升维,这样权重和通道的对应关系是间接的。为了解决以上问题,作者提出一维卷积的方法,避免了降维对数据的影响,步骤如下:
- 对特征图进行Squeeze,该步骤是通过全局平均池化把特征图从大小为(N,C,H,W)转换为(N,C,1,1),这样就达到了全局上下文信息的融合(与SE的步骤1相同)
- 计算自适应卷积核的大小,
 ,其中,C:输入通道数,b=1,γ=2;对经过步骤一处理的特征进行一维卷积操作(获得局部跨通道信息),再采用Sigmoid激活函数将权重映射在0到1之间
,其中,C:输入通道数,b=1,γ=2;对经过步骤一处理的特征进行一维卷积操作(获得局部跨通道信息),再采用Sigmoid激活函数将权重映射在0到1之间 - 通过广播机制将权重与输入特征图相乘,得到不同权重下的特征图

代码实现如下,
import torch
import torch.nn as nn
import math
class ECA(nn.Module):
def __init__(self, in_channel, gamma=2, b=1):
super(ECA, self).__init__()
k = int(abs((math.log(in_channel,2)+b)/gamma))
kernel_size = k if k % 2 else k+1
padding = kernel_size//2
self.pool = nn.AdaptiveAvgPool2d(output_size=1)
self.conv = nn.Sequential(
nn.Conv1d(in_channels=1, out_channels=1, kernel_size=kernel_size, padding=padding, bias=False),
nn.Sigmoid()
)
def forward(self,x):
out=self.pool(x)
out=out.view(x.size(0), 1, x.size(1))
out=self.conv(out)
out=out.view(x.size(0), x.size(1), 1, 1)
return out*x三、CBAM
CBAM是一种将通道与空间注意力机制相结合的算法,输入特征图先进行通道注意力机制再进行空间注意力机制操作,这样从通道和空间两个方面达到了强化感兴趣区域的目的

通道注意力机制的实现步骤如下:
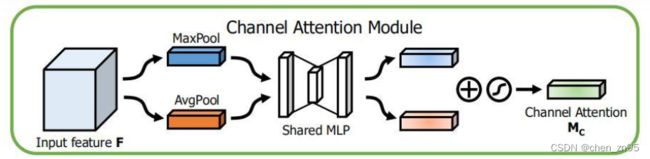
- 对特征图进行Squeeze,该步骤分别采用全局平均池化和全局最大池化把特征图从大小为(N,C,H,W)转换为(N,C,1,1),这样就达到了全局上下文信息的融合
- 分别将全局最大池化和全局平均池化结果进行MLP操作,MLP在这里定义与SE的全连接层操作一样,为两层全连接层,中间采用ReLU激活,最后将两者相加后利用Sigmoid函数激活
- 通过广播机制将权重与输入特征图相乘,得到不同权重下的特征图
空间注意力机制的实现步骤如下:
- 将上述通道注意力操作的结果,分别在通道维度上进行最大池化和平均池化,即将经过通道注意力机制的特征图从(N,C,H,W)转换为(N,1,H,W),融合不同通道的信息,然后在通道维度上将最大池化与平均池化的结果concat起来
- 将叠加后2个通道的结果做卷积运算,输出通道为1,卷积核大小为7,最后将输出结果进行Sigmoid处理
- 通过广播机制将权重与输入特征图相乘,得到不同权重下的特征图

代码实现如下,
import torch
import torch.nn as nn
import math
class CBAM(nn.Module):
def __init__(self, in_channel, reduction=16, kernel_size=7):
super(CBAM, self).__init__()
# 通道注意力机制
self.max_pool = nn.AdaptiveMaxPool2d(output_size=1)
self.avg_pool = nn.AdaptiveAvgPool2d(output_size=1)
self.mlp = nn.Sequential(
nn.Linear(in_features=in_channel, out_features=in_channel//reduction, bias=False),
nn.ReLU(),
nn.Linear(in_features=in_channel//reduction, out_features=in_channel,bias=False)
)
self.sigmoid = nn.Sigmoid()
# 空间注意力机制
self.conv = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=kernel_size , stride=1, padding=kernel_size//2, bias=False)
def forward(self,x):
# 通道注意力机制
max_out = self.max_pool(x)
max_out = self.mlp(max_out.view(maxout.size(0), -1))
avg_out = self.avg_pool(x)
avg_out = self.mlp(avg_out.view(avgout.size(0), -1))
channel_out = self.sigmoid(max_out+avg_out)
channel_out = channel_out.view(x.size(0), x.size(1),1,1)
channel_out = channel_out*x
# 空间注意力机制
max_out, _ = torch.max(channel_out, dim=1, keepdim=True)
mean_out = torch.mean(channel_out, dim=1, keepdim=True)
out = torch.cat((max_out, mean_out), dim=1)
out = self.sigmoid(self.conv(out))
out = out*channel_out
return out四、CA
SE对提升模型性能具有显著的有效性,但它们通常忽略了位置信息。CA利用x、y两个方向的全局池化,分别将垂直和水平方向上的输入特征聚合为两个独立的方向感知特征映射,将输入Feature Map的位置信息嵌入到通道注意力的聚合特征向量。这两个嵌入方向特定信息的特征图被分别编码到两个注意图中,然后通过乘法将这两种注意图应用于输入特征图,加强感兴趣区域的表示。实现步骤如下:
- 沿着x、y方向对输入特征图分别进行自适应池化操作,将特征图大小从(N,C,H,W)变为(N,C,H,1)、(N,C,1,W),对大小为(N,C,1,W)的特征进行permute操作,使得该特征大小变为(N,C,W,1),再沿着(dim=2)对这两个特征进行concat,得到大小为(N,C,H+W,1)的特征图
- 对步骤一处理后的特征进行1*1卷积操作(目的是降维),随后再经过BN和h_swish激活函数
- 沿着dim=2对步骤二处理后的特征进行分割操作(torch.split),将特征分为(N,C/r,H,1)、(N,C/r,W,1),其中r为通道降维因子。随后对大小为(N,C/r,W,1)的特征进行permute操作,变为(N,C/r,1,W)。最后对以上两个特征进行1*1卷积操作(目的是改变特征图的通道数)并经Sigmoid处理
- 通过广播机制将步骤三的两个特征先后与输入特征图相乘(out = identity * a_w * a_h),得到不同权重下的特征图

【下图有点小问题,应该是对1D Global Avg Pool(W)特征进行permute操作】

代码实现如下,
import torch
import torch.nn as nn
import math
import torch.nn.functional as F
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n,c,h,w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out