动手学深度学习——softmax回归的从零开始(代码详解)
目录
- 1. softmax回归的从零开始实现
-
- 1.1 初始化模型参数
- 1.2 定义softmax操作
- 1.3 定义模型
- 1.4 定义损失函数
- 1.5 分类精度
- 1.6 训练
- 1.7 预测
- 1.8 小结
1. softmax回归的从零开始实现
引入Fashion-MNIST数据集, 并设置数据迭代器的批量大小为256。
import torch
from IPython import display
from d2l import torch as d2l
# 随机读取256张图片
batch_size = 256
# 返回训练集和测试集的迭代器
# load_data_fashion_mnist函数是在图像分类数据集中定义的一个函数,可以返回batch_size大小的训练数据集和测试数据集
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
| 步骤 | 函数 |
|---|---|
| 载入数据集 | |
| 初始化模型参数 | |
| 定义softmax操作 |  |
| 定义模型 |  |
| 定义损失函数 |  |
| 分类精度 |    |
| 训练 |   |
| 预测 |  |
1.1 初始化模型参数
- 样本固定长度向量表示,原始数据集每个样本都是28×28的图像
- 现在将展平每个图像,把它们看作长度为784的向量
- 在softmax回归中,我们的输出与类别一样多。 因为我们的数据集有10个类别,所以网络输出维度为10
- 权重将构成一个784×10的矩阵, 偏置将构成一个1×10的行向量
num_inputs = 784 #展平长度为784的向量
num_outputs = 10 #10输出,也对应10类别
# 权重w:均值为0,标准差为0.01,数量size为输入输出的数量
# size=(num_inputs, num_outputs):行数为输入的个数,列数等于输出的个数
# requires_grad=True表明要计算梯度
W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)
b = torch.zeros(num_outputs, requires_grad=True)
1.2 定义softmax操作
sum运算符:给定一个矩阵X,我们可以对所有元素求和(默认情况下)。 也可以只求同一个轴上的元素,即同一列(轴0)或同一行(轴1)。

一般实现softmax由三个步骤组成:
- 对每个项求幂(使用exp);
- 对每一行求和(小批量中每个样本是一行),得到每个样本的规范化常数;
- 将每一行除以其规范化常数,确保结果的和为1。
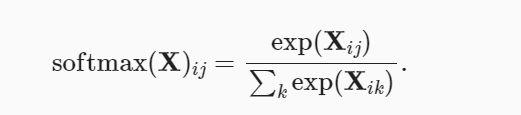
# 定义softmax函数
def softmax(X):
X_exp = torch.exp(X) # 对每个元素做指数运算
partition = X_exp.sum(1, keepdim=True) # 对每行进行求和
return X_exp / partition # 这里应用了广播机制
正如上述代码,对于任何随机输入,我们将每个元素变成一个非负数。 此外,依据概率原理,每行总和为1。
1.3 定义模型
- 定义softmax操作后,我们可以实现softmax回归模型。
- 将数据传递到模型之前,我们使用reshape函数将每张原始图像展平为向量。
reshape(-1,1):这里的-1被理解为unspecified value,意思是未指定为给定的。只需要特定的列数,行数多少无所谓,用-1代替(-1可以理解为一个正整数通配符,它代替任何整数)。shape[0]:表示矩阵的行数。
对于图像来说:image.shape[0]——图片高度;image.shape[1]——图片宽度;image.shape[2]——图片通道数。
对于矩阵来说:shape[0]:表示矩阵的行数;shape[1]:表示矩阵的列数。
def net(X):
# 权重为784×10的矩阵,这里将原始图像的列数大小转换为权重w矩阵的行数大小
# 模型简单看来为:softmax(wx' + b)
return softmax(torch.matmul(X.reshape((-1, W.shape[0])), W) + b)
1.4 定义损失函数
目前分类问题的数量远远超过回归问题的数量,这里采用交叉熵损失函数,交叉熵采用真实标签的预测概率的负对数似然。
- 创建数据样本y_hat,包括2个样本在3个类别的概率,以及对应的标签y。
- 通过y知道第一个样本中第一类是正确的预测,第二个样本中第三类是正确的预测。
- 将y作为y_hat的索引,选择第一个样本第一类的概率和第二个样本第三类的概率。

实现交叉熵损失函数

len(x):获取x的长度range(x):生成从0开始,小于参数x的整数序列
# 定义交叉熵损失函数
def cross_entropy(y_hat, y):
return - torch.log(y_hat[range(len(y_hat)), y])
cross_entropy(y_hat, y)

1.5 分类精度
给定预测概率分布y_hat,当我们必须输出硬预测(hard prediction)时, 我们通常选择预测概率最高的类。
- 当预测与标签分类y一致时,即是正确的。
- 分类精度即正确预测数量与总预测数量之比。
y_hat是矩阵,假定第二个维度存储每个类的预测分数。- 使用
argmax获得每行中最大元素的索引来获得预测类别。- 将预测类别与真实
y元素进行比较。- 通过"
=="比较,结果为包含0(错)和1(对)的张量,求和得到正确预测的数量。
argmax():返回的是最大数的索引.argmax有一个参数axis,默认是0,表示第几维的最大值。
def accuracy(y_hat, y): #@save
"""计算预测正确的数量"""
# len是查看矩阵的行数
# y_hat.shape[1]就是去列数
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
# 第2个维度为预测标签,取最大元素
y_hat = y_hat.argmax(axis=1)
# #将y_hat转换为y的数据类型然后作比较,cmp函数存储bool类型
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum()) #将正确预测的数量相加
y_hat和y分别作为预测的概率分布和标签。- 第一个样本的预测类别是2(该行的最大元素为0.6,索引为2),这与实际标签0不一致。第二个样本的预测类别是2(该行的最大元素为0.5,索引为2),这与实际标签2一致。 因此,这两个样本的分类精度率为0.5。

对于任意数据迭代器data_iter可访问的数据集, 我们可以评估在任意模型net的精度。
with torch.no_grad():不使用时,此时有grad_fn=属性,表示计算的结果在一计算图当中,可以进行梯度反传等操作。使用时,表明当前计算不需要反向传播,使用之后,强制后边的内容不进行计算图的构建。isinstance():python中的一个内置函数,作用:判断一个函数是否是一个已知类型,类似type()。
isinstance (object , classinfo)判断两个类型是否相同。
- object:实例对象;
- classinfo:可以是直接或间接类名、基本类型或由它们组成的元组;
- 返回值:如果对象的类型与参数二(classinfo)的类型相同返回true,否则false。
torch.nn.Module():它是所有的神经网络的根父类, 神经网络必然要继承。net.eval():pytorch中用来将神经网络设置为评估模型的方法。
- 评估模式下,网络的参数不会被更新,dropout和batch normalization层的行为也会有所不同,以便模型更好地进行预测。
- 评估模式下计算图不会被跟踪,这样可以节省内存使用,提升性能。
y.numel():Python中的张量计算方法,用于存储新的张量并存储在内存中。可以通过指定形状的shape属性来访问张量的形状。
def evaluate_accuracy(net, data_iter): #@save
"""计算在指定数据集上模型的精度"""
# 判断模型是否为深度学习模型
if isinstance(net, torch.nn.Module):
net.eval() # 将模型设置为评估模式
metric = Accumulator(2) # metric:度量,累加正确预测数、预测总数
# 梯度不需要反向传播
with torch.no_grad():
# 每次从迭代器中拿出一个X和y
for X, y in data_iter:
# metric[0, 1]分别为网络预测正确的数量和总预测的数量
# nex(X):X放在net模型中进行softmax操作
# numel()函数:返回数组中元素的个数,在此可以求得样本数
metric.add(accuracy(net(X), y), y.numel())
# # metric[0, 1]分别为网络预测正确数量和总预测数量
return metric[0] / metric[1]
定义一个实用程序类Accumulator,用于对多个变量进行累加,Accumulator实例中创建了2个变量, 分别用于存储正确预测的数量和预测的总数量。
__init__():创建一个类,初始化类实例时就会自动执行__init__()方法。该方法的第一个参数为self,表示的就是类的实例。self后面跟随的其他参数就是创建类实例时要传入的参数。reset();重新设置空间大小并初始化。__getitem__():接收一个idx参数,这个参数就是自己给的索引值,返回self.data[idx],实现类似数组的取操作。
class Accumulator: #@save
"""在n个变量上累加"""
# 初始化根据传进来n的大小来创建n个空间,全部初始化为0.0
def __init__(self, n):
self.data = [0.0] * n
# 把原来类中对应位置的data和新传入的args做a + float(b)加法操作然后重新赋给该位置的data,从而达到累加器的累加效果
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
# 重新设置空间大小并初始化。
def reset(self):
self.data = [0.0] * len(self.data)
# 实现类似数组的取操作
def __getitem__(self, idx):
return self.data[idx]
由于我们使用随机权重初始化net模型, 因此该模型的精度应接近于随机猜测。 例如在有10个类别情况下的精度为0.1。
1.6 训练
- 定义一个函数来训练一个迭代周期。
- updater是更新模型参数的常用函数,它接受批量大小作为参数。 它可以是d2l.sgd函数,也可以是框架的内置优化函数。
def train_epoch_ch3(net, train_iter, loss, updater): #@save
"""训练模型一个迭代周期(定义见第3章)"""
# 判断net模型是否为深度学习类型,将模型设置为训练模式
if isinstance(net, torch.nn.Module):
net.train() # 要计算梯度
# Accumulator(3)创建3个变量:训练损失总和、训练准确度总和、样本数
metric = Accumulator(3)
for X, y in train_iter:
# 计算梯度并更新参数
y_hat = net(X)
l = loss(y_hat, y)
# 判断updater是否为优化器
if isinstance(updater, torch.optim.Optimizer):
# 使用PyTorch内置的优化器和损失函数
updater.zero_grad() #把梯度设置为0
l.mean().backward() #计算梯度
updater.step() #自更新
else:
# 使用定制的优化器和损失函数
# 自我实现的话,l出来是向量,先求和再求梯度
l.sum().backward()
updater(X.shape[0])
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
# 返回训练损失和训练精度,metric的值由Accumulator得到
return metric[0] / metric[2], metric[1] / metric[2]
定义一个在动画中绘制数据的实用程序类Animator
class Animator: #@save
"""在动画中绘制数据"""
def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,
ylim=None, xscale='linear', yscale='linear',
fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,
figsize=(3.5, 2.5)):
# 增量地绘制多条线
if legend is None:
legend = []
d2l.use_svg_display()
self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)
if nrows * ncols == 1:
self.axes = [self.axes, ]
# 使用lambda函数捕获参数
self.config_axes = lambda: d2l.set_axes(
self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)
self.X, self.Y, self.fmts = None, None, fmts
def add(self, x, y):
# 向图表中添加多个数据点
if not hasattr(y, "__len__"):
y = [y]
n = len(y)
if not hasattr(x, "__len__"):
x = [x] * n
if not self.X:
self.X = [[] for _ in range(n)]
if not self.Y:
self.Y = [[] for _ in range(n)]
for i, (a, b) in enumerate(zip(x, y)):
if a is not None and b is not None:
self.X[i].append(a)
self.Y[i].append(b)
self.axes[0].cla()
for x, y, fmt in zip(self.X, self.Y, self.fmts):
self.axes[0].plot(x, y, fmt)
self.config_axes()
display.display(self.fig)
display.clear_output(wait=True)
- 实现一个训练函数,它会在
train_iter访问到的训练数据集上训练一个模型net。 - 该训练函数将会运行多个迭代周期(由
num_epochs指定)。
assert():断言函数,当表达式为真时,程序继续往下执行,只是判断,不做任何处理;当表达式为假时,抛出AssertionError错误,并将 [参数] 输出
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): #@save
"""训练模型(定义见第3章)"""
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc'])
# num_epochs:训练次数
for epoch in range(num_epochs):
# train_epoch_ch3:训练模型,返回准确率和错误度
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
# 在测试数据集上评估精度
test_acc = evaluate_accuracy(net, test_iter)
animator.add(epoch + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc
- 使用小批量随机梯度下降来优化模型的损失函数,设置学习率为0.1。
lr = 0.1
def updater(batch_size):
return d2l.sgd([W, b], lr, batch_size)
- 训练模型10个迭代周期,其中迭代周期(num_epochs)和学习率(lr)都是可调节的超参数。
num_epochs = 10
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, updater)

1.7 预测
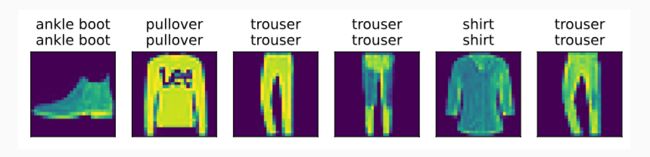
训练已完成的模型可以来对准备好图像进行分类预测,给定一系列图像,我们将比较它们的实际标签(文本输出的第一行)和模型预测(文本输出的第二行)。
def predict_ch3(net, test_iter, n=6): #@save
"""预测标签(定义见第3章)"""
for X, y in test_iter:
break
trues = d2l.get_fashion_mnist_labels(y) # 实际标签
preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1)) 预测标签,取最大化概率
titles = [true +'\n' + pred for true, pred in zip(trues, preds)]
d2l.show_images(
X[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])
predict_ch3(net, test_iter)
1.8 小结
- 借助softmax回归,我们可以训练多分类的模型。
- 训练softmax回归循环模型与训练线性回归模型非常相似:先读取数据,再定义模型和损失函数,然后使用优化算法训练模型。大多数常见的深度学习模型都有类似的训练过程。
参考资料:
[1]动手学深度学习:http://zh-v2.d2l.ai/index.html
[2]跟李沐学AI:https://space.bilibili.com/1567748478