【机器学习】scikit-plot机器学习可视化图表基本使用
文章目录
- 前言
- 一、Scikit-Plot是什么?
- 二、安装
- 三、使用
-
- 1.混淆矩阵
- 2.ROC曲线
- 3.学习曲线
- 4.特征重要性
- 5.多模型比较
- 6.KMeans分类K值选择
- 总结
前言
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
一、Scikit-Plot是什么?
Scikit-Plot是一个基于Scikit-Learn的Python库,旨在简化机器学习模型的评估和可视化过程。它提供了一组易于使用的函数,能够生成各种常见的图表,如混淆矩阵、ROC曲线、学习曲线等,以帮助我们更好地理解模型的性能和行为。
二、安装
1.下载
pip install scikit-plot
2.导入
import scikitplot as skplt
三、使用
1.混淆矩阵
import matplotlib.pyplot as plt
from sklearn import datasets, model_selection
from sklearn.linear_model import LogisticRegression
# 加载数据集
data = datasets.load_iris()
X = data.data
y = data.target
# 创建模型
model = LogisticRegression()
# 拟合模型
model.fit(X, y)
# 生成混淆矩阵图表
skplt.metrics.plot_confusion_matrix(y_true=y, y_pred=model.predict(X),normalize=True)
plt.show()

其中在对0类别的表现比较好,其次是1类别,
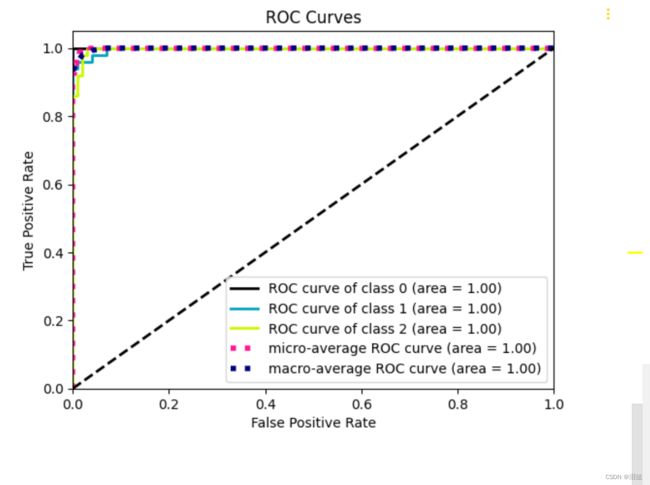
2.ROC曲线
# 生成ROC曲线图表
skplt.metrics.plot_roc(y_true=y, y_probas=model.predict_proba(X))
plt.show()
3.学习曲线
skplt.estimators.plot_learning_curve(model,X,y)
plt.show()

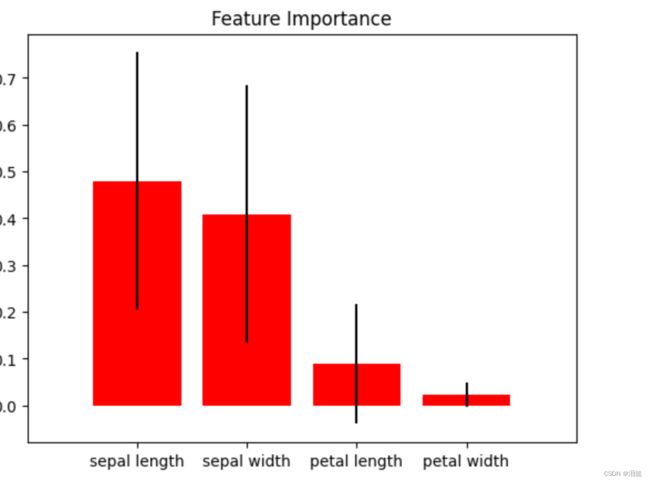
4.特征重要性
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier()
rf.fit(X, y)
skplt.estimators.plot_feature_importances(
rf,
feature_names=['petal length', 'petal width',
'sepal length', 'sepal width'])
plt.show()
5.多模型比较
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
from sklearn.datasets import load_digits,make_classification,make_circles
from sklearn.model_selection import train_test_split
X,y=make_classification(n_samples=200,n_classes=2,random_state=42)
X_train,X_text,y_train,y_test=train_test_split(X,y,train_size=0.3)
rf=RandomForestClassifier(random_state=42)
lf=LogisticRegression(multi_class='auto')
sf=SVC(kernel='rbf')
tf=DecisionTreeClassifier()
modals=[rf,lf,sf,tf]
modals=[i.fit(X_train,y_train) for i in modals]
#%%
rf_probas=rf.predict_proba(X_text)
lf_probas=lf.predict_proba(X_text)
sf_probas=sf.decision_function(X_text)
tf_probas=tf.predict_proba(X_text)
probas_list=[rf_probas,lf_probas,sf_probas,tf_probas]
clf_names=[
"RandomForestClassifier",
"LogisticRegression",
"SVC",
"tf"
]
skplt.metrics.plot_calibration_curve(
y_test,
probas_list,
clf_names
)
plt.show()

Fraction of positives(正类样本比例)和Mean predicted value(平均预测值)是与二分类模型相关的两个指标。
Fraction of positives指的是在二分类问题中,预测结果中被标记为正类别的样本占总样本数的比例。它可以用来衡量模型在预测中正类别的相对比例。通常表示为一个介于0和1之间的值。
Fraction of positives可以提供关于模型预测结果中正类别的相对数量的信息。较高的Fraction of positives表示模型倾向于将更多的样本预测为正类别,而较低的Fraction of positives表示模型更倾向于将更多的样本预测为负类别。这个指标对于理解模型的分类倾向性和对不同类别的偏好有一定的启示作用。
Mean predicted value指的是模型对于预测结果中正类别的平均置信度或概率值。在二分类模型中,每个样本都会被预测为正类别或负类别,并且通常会有一个与之相关的置信度或概率值。
Mean predicted value计算了模型在预测结果中所有正类别样本的置信度或概率值的平均值。它可以用来衡量模型对于正类别预测的整体置信度或概率水平。通常表示为一个介于0和1之间的值。
较高的Mean predicted value表示模型对于正类别的预测更加确信或置信度更高,而较低的Mean predicted value表示模型对于正类别的预测置信度较低。
这两个指标可以在评估二分类模型的性能时提供一些关键信息。Fraction of positives可以帮助我们理解模型的分类偏好,而Mean predicted value则提供了模型对于正类别的整体预测置信度的信息。综合考虑这两个指标可以帮助我们评估模型的分类性能和置信水平。
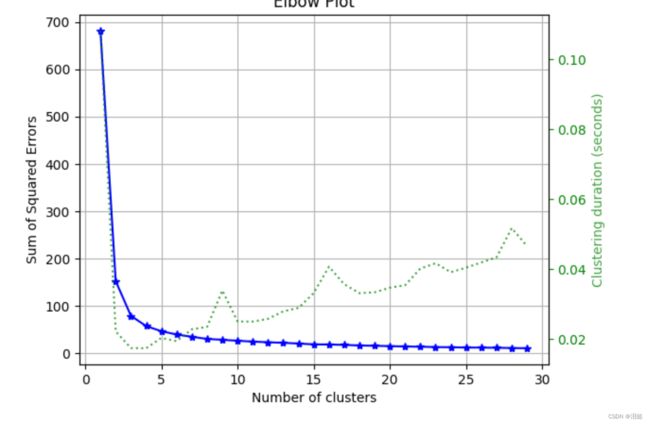
6.KMeans分类K值选择
from sklearn.cluster import KMeans
kmeans=KMeans()
skplt.cluster.plot_elbow_curve(kmeans,X,cluster_ranges=range(1,30))
plt.show()
总结
Scikit-Plot是一个非常实用的Python库,它简化了机器学习模型的评估和可视化过程。本教程详细介绍了Scikit-Plot的基本用法,并演示了如何使用该库生成常见的模型评估图表。通过利用Scikit-Plot,我们可以更好地理解模型的性能和行为,并作出更准确的决策。
希望大家多多支持,后续分享更多有趣的内容