deeplabv3+源码之慢慢解析 第二章datasets文件夹(3)cityscapes.py--Cityscapes类
系列文章目录(更新中)
第一章deeplabv3+源码之慢慢解析 根目录(1)main.py–get_argparser函数
第一章deeplabv3+源码之慢慢解析 根目录(2)main.py–get_dataset函数
第一章deeplabv3+源码之慢慢解析 根目录(3)main.py–validate函数
第一章deeplabv3+源码之慢慢解析 根目录(4)main.py–main函数
第一章deeplabv3+源码之慢慢解析 根目录(5)predict.py–get_argparser函数和main函数
第二章deeplabv3+源码之慢慢解析 datasets文件夹(1)voc.py–voc_cmap函数和download_extract函数
第二章deeplabv3+源码之慢慢解析 datasets文件夹(2)voc.py–VOCSegmentation类
第二章deeplabv3+源码之慢慢解析 datasets文件夹(3)cityscapes.py–Cityscapes类
第二章deeplabv3+源码之慢慢解析 datasets文件夹(4)utils.py–6个小函数
第三章deeplabv3+源码之慢慢解析 metrics文件夹stream_metrics.py–[StreamSegMetrics类和AverageMeter类]
第四章deeplabv3+源码之慢慢解析 network文件夹(0)backbone文件夹(a)hrnetv2.py–[4个类,4个函数,1个主函数]
第四章deeplabv3+源码之慢慢解析 network文件夹(0)backbone文件夹(b)mobilenetv2.py–[3个类,3个函数]
第四章deeplabv3+源码之慢慢解析 network文件夹(0)backbone文件夹©resnet.py–[2个类,12个函数]
第四章deeplabv3+源码之慢慢解析 network文件夹(0)backbone文件夹(d)xception.py–[3个类,1个函数]
第四章deeplabv3+源码之慢慢解析 network文件夹(1)_deeplab.py–[7个类和1个函数]
第四章deeplabv3+源码之慢慢解析 network文件夹(2)modeling.py–[15个函数]
第四章deeplabv3+源码之慢慢解析 network文件夹(3)utils.py–[2个类]
第五章deeplabv3+源码之慢慢解析 utils文件夹(1)ext_transforms.py.py–[17个类]
第五章deeplabv3+源码之慢慢解析 utils文件夹(2)loss.py–[1个类]
第五章deeplabv3+源码之慢慢解析 utils文件夹(3)scheduler.py–[1个类]
第五章deeplabv3+源码之慢慢解析 utils文件夹(4)utils.py–[1个类,4个函数]
第五章deeplabv3+源码之慢慢解析 utils文件夹(5)visualizer.py–[1个类]
总结
文章目录
- 系列文章目录(更新中)
-
- 说明
- cityscapes.py导入
- Cityscapes类
说明
- voc.py的代码已经说完,本节讲述cityscapes.py。
- 从代码上看,cityscapes数据集处理方式比voc数据集简单。
- cityscapes.py中仅有一个类,其中包含7个小函数,从体量和难度上,可以一次说完。
- 思路上和voc.py有部分类似之处,大家可以边学习边对比。
cityscapes.py导入
#导入都是基本包,和之前相比要简单。
import json
import os
from collections import namedtuple
import torch
import torch.utils.data as data
from PIL import Image
import numpy as np
Cityscapes类
提示:可以对比前一节的VOCSegmentation类,多体会这种类的处理思路,以便处理自己的数据集。
class Cityscapes(data.Dataset):
"""Cityscapes Tips
1.相对VOCSegmentation类而言,Cityscapes类相对简单。
2. 补充cityscapes文件夹,可以看到对应文件夹,相对容易理解。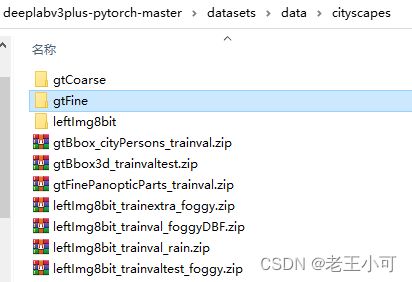
3. 对于具体文件压缩包,split参数对应的文件夹图。

4. datasets文件夹下的两个特定数据集代码已解析完毕。下一节介绍utils.py。