javaWeb详细教程
javaWeb
javaWeb简介
Java Web是使用Java技术解决相关Web互联网领域的技术栈,开发一个完整的Java Web项目涉及到静态Web资源、动态Web资源的编写以及项目的部署。在Java Web中,静态Web资源开发技术包括HTML、CSS、JavaScript、XML等;动态Web资源开发技术包括JSP/Servlet等。
XML
XML是EXtensible Markup Language的缩写,它是一种类似于HTML的标记语言,称为可扩展标记语言。XML用于提供数据描述格式,适用于不同应用程序之间的数据交换,而且这种交换不以预先定义的一组数据结构为前提,增强了可扩展性。
XML与HTML的比较
- HTML用于显示数据,XML用于传输和储存数据
- HTML标签不区分大小写,而XML标记严格区分大小写
- HTML可以有多个根元素,而格式良好的XML有且只能有一个根元素
- HTML中,空格是自动过滤的,而在XML中,空格不能自动过滤
- HTML中的标签是预定义的标签,而XML中的标记可以根据需要自己定义,并且可扩展。
XML语法
version:用于指定遵循XML规范的版本号。在XML声明中必须包含version属性,且该属性必须放在XML声明中其他属性之前。
encoding:用来指定XML文档所使用的编码集。
注释
<student name="张三" age="18">
在XML文档中,可以为元素定义属性。属性是对元素的进一步描述和说明。在一个元素中,可以自定义多个属性,属性是依附于元素存在的,并且每个属性都有自己的名称和取值.
需要注意的是,在XML文档中,属性的命名规范与元素相同,属性值必须要用双引号("")或者单引号('')引起来,否则被视为错误。
student>
DTD约束
什么是XML约束:
XML文档中的标签是可以随意定义的,同一本书出现了两种售价,如果仅根据标签名称区分哪个是原价,哪个是会员价,这是很难实现的。为此,在XML文档中,定义了一套规则对文档中的内容进行约束,这套规则称为XML约束。对XML文档进行约束时,同样需要遵守一定的语法规则,这种语法规则就形成了XML约束语言。
什么是DTD约束:
DTD约束是早期出现的一种XML约束模式语言,根据它的语法创建的文件称为DTD文件。在一个DTD文件中,可以包含元素的定义、元素之间关系的定义、元素属性的定义以及实体和符号的定义。
DTD的引入:
外部引入:
第一种:引入本地的DTD文件
第二种:引入公共的DTD文件
"-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN"
"http://java.sun.com/dtd/web-app_2_3.dtd">
内嵌:
第三种:
]>
DTD语法结构:
DOCTYPE persons[
<!ELEMENT persons (person+)>
<!ELEMENT person (name,age)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
]>
<persons>
<person>
<name>张三name>
<age>18age>
person>
<person>
<name>张三name>
<age>18age>
person>
persons>
元素内容:
1)#PCDATA:表示元素中嵌套的内容是普通文本字符串,其中关键字PCDATA是Parsed Character Data的简写。
2)子元素:说明元素包含其他元素。通常用一对小括号()将元素中要嵌套的一组子元素括起来。
3)混合内容:表示元素既可以包含字符数据,也可以包含子元素。混合内容必须被定义零个或多个。
4)EMPTY:表示该元素既不包含字符数据,也不包含子元素,是一个空元素。如果在文档中元素本身已经表明了明确的含义,就可以在DTD中用关键字EMPTY表明空元素。
5)ANY:表示该元素可以包含任何字符数据和子元素。
注意:
在定义元素时,元素内容可以包含一些符号,不同的符号具有不同的作用,下面介绍一些常见的符号。
问号[?]:表示该对象可以出现0次或1次。
星号[*]:表示该对象可以出现0次或多次。
加号[+]:表示该对象可以出现1次或多次。
竖线[|]:表示列出的对象中选择1个。
逗号[,]:表示对象必须按照指定的顺序出现。
括号[()]:用于给元素进行分组。
Schema约束
Schema约束是基于xml语法格式,比DTD约束更加高效。
Schema文档,以xsd作为后缀名,以xs:schema作为根元素,表示模式定义的开始。
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="persons">
xs:element>
xs:schema>
名称空间
一个XML文档可以引入多个约束文档,但是,由于约束文档中的元素或属性都是自定义的,所以在XML文档中,极有可能出现代表不同含义的同名元素或属性,导致名称发生冲突。为此,在XML文档中,提供了名称空间,它可以唯一标识一个元素或者属性。这就好比打车去小营,由于北京有两个地方叫小营,为了避免司机走错,我们就会说“去亚运村的小营”或者“去清河的小营”。这时的亚运村或者清河就相当于一个名称空间。
声明格式:
<元素名 xmlns:prefixname="URI">
名称空间的声明就是在XML文档中为某个模式文档的名称空间指定一个临时名称,它通过一系列的保留属性来声明,这种属性的名字必须是以“xmlns”或者以“xmlns:”作为前缀。它与其他任何XML属性一样,都可以通过直接或者使用默认的方式给出。
注意:元素名指的是在哪一个元素上声明名称空间,在这个元素上声明的名称空间适用于声明它的元素和属性,以及该元素中嵌套的所有元素及其属性。xmlns:prefixname指的是该元素的属性名,它所对应的值是一个URI引用,用来标识该名称空间的名称。需要注意的是,如果有两个URI并且其组成的字符完全相同,就可以认为它们标识的是同一个名称空间。
引入Schema文档
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="https://www.itheima.com"
>
<xs:element name="persons">
xs:element>
xs:schema>
-
使用名称空间引入XML Schema文档
在使用名称空间引入XML Schema文档时,需要通过属性xsi:schemaLocation来声明名称空间的文档,xsi:schemaLocation属性是在标准名称空间“http://www.w3.org/2001/XMLSchema-instance”中定义的,在该属性中,包含了两个URI,这两个URI之间用空白符分隔。其中,第一个URI是名称空间的名称,第二个URI是文档的位置。
<persons xmlns="https://www.itheima.com" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="https://www.itheima.com person.xsd" > persons> -
通过xsi:noNamespaceSchemaLocation属性直接指定
通过xsi:noNamespaceSchemaLocation属性直接指定,noNamespaceSchemaLocation属性也是在标准名称空间“http://www.w3.org/2001/XMLSchema-instance”中定义的,它用于定义指定文档的位置。
<persons xmlns="https://www.itheima.com" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="person.xsd" > persons>
Schema语法
Schema和DTD一样,都可以定义XML文档中的元素。在Schema文档中,元素定义的语法格式:
<xs:element name="名称" type="类型"/>
element用于声明一个元素,名称指的是元素的名称,类型指元素的数据类型。
在XML Schema 中有很多内建的数据类型,其中最常用的有以下几种:
xs:string:表示字符串类型
xs:decimal:表示小数类型
xs:integer:表示整数类型
xs:boolean:表示布尔类型
xs:date:表示日期类型
xs:time:表示时间类型
简单类型和复杂类型
在XML Schema文档中,只包含字符数据的元素都是简单类型的。简单类型使用 xs:simpleType元素来定义。如果想对现有元素内容的类型进行限制,则需要使用xs:restriction元素。
在定义复杂类型时,需要使用xs:complexContent元素来定义。复杂类型的元素可以包含子元素和属性,这样的元素称为复合元素。在定义复合元素时,如果元素的开始标签和结束标签之间只包含字符数据内容,那么这样的内容是简易内容,需要使用xs:simpleContent元素来定义。反之,元素的内容都是复杂内容,需要使用xs:complexContent元素来定义。
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="https://www.itheima.com"
elementFormDefault="qualified"
>
<xs:element name="persons">
<xs:complexType>
<xs:sequence>
<xs:element name="person">
<xs:complexType>
<xs:sequence>
<xs:element name="name" type="xs:string">xs:element>
<xs:element name="age" type="xs:integer">xs:element>
xs:sequence>
xs:complexType>
xs:element>
xs:sequence>
xs:complexType>
xs:element>
xs:schema>
Tomcat
Tomcat简介
Tomcat是Apache组织的Jakarta项目中的一个重要子项目,它是Sun公司(已被Oracle收购)推荐的运行Servlet和JSP的容器(引擎),其源代码是完全公开的。Tomcat不仅具有Web服务器的基本功能,还提供了数据库连接池等许多通用组件功能。
Tomcat运行稳定、可靠、效率高,不仅可以和目前大部分主流的Web服务器(如Apache、IIS服务器)一起工作,还可以作为独立的Web服务器软件。
Tomcat的安装和启动
Tomcat的目录
Tomcat安装目录中包含不同子目录,这些子目录分别用于存放不同功能的文件。
(1)bin:用于存放Tomcat的可执行文件和脚本文件(扩展名为bat的文件。
(2)conf:用于存放Tomcat的各种配置文件,如web.xml、server.xml。
(3)lib:用于存放Tomcat服务器和所有Web应用程序需要访问的JAR文件。
(4)logs:用于存放Tomcat的日志文件。
(5)temp:用于存放Tomcat运行时产生的临时文件。
(6)webapps:Web应用程序的主要发布目录,通常将要发布的应用程序放到这个目录下。
(7)work:Tomcat的工作目录,JSP编译生成的Servlet源文件和字节码文件放到这个目录下。
启动步骤
Tomcat服务器启动
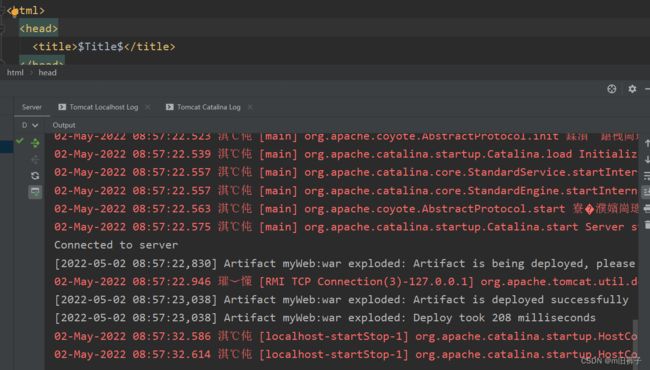
双击bin目标中的startup.bat文件,便会启动Tomcat服务器,此时,可以在弹出的命令行看到一些启动信息。
TomcatWeb端启动
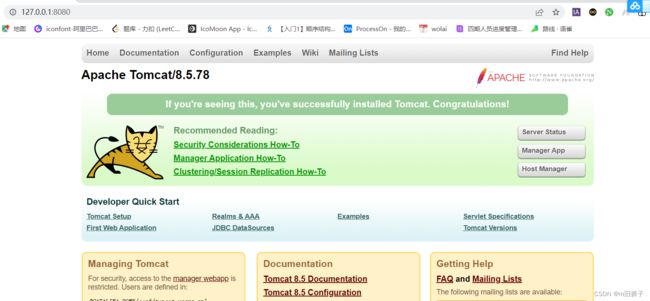
在idea中配置Tomcat
-
新建一个javaWeb项目
-
添加Tomcat本地配置

-
设置本地配置
-
启动
HTTP 协议
HTTP概述
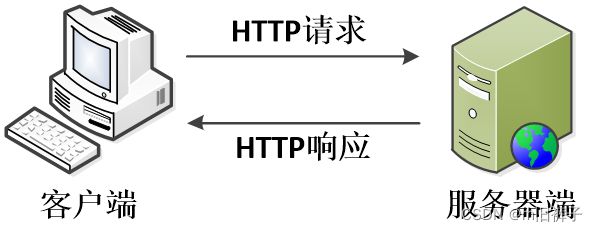
HTTP是HyperText Transfer Protocol的缩写,即超文本传输协议。它是一种请求/响应式的协议,客户端在与服务器建立连接后,就可以向服务器发送请求,这种请求被称作HTTP请求,服务器接收到请求后会做出响应,称为HTTP响应。
特点
(1)HTTP协议支持客户端(浏览器就是一种Web客户端)/服务器模式。
(2)简单快速,客户端向服务器请求服务时,只需传送请求方式和路径。常用的请求方式有GET、POST等,不同的请求方式规定的客户端与服务器联系的类型也不同。HTTP比较简单,使得HTTP服务器的程序规模小,因而通信速度很快。
(3)灵活,HTTP允许传输任意类型的数据,正在传输的数据类型由Content-Type加以标记。
(4)无状态,HTTP是无状态协议。无状态是指协议对于事务处理没有记忆能力,如果后续处理需要前面的信息,则必须重新传输,这样可能导致每次连接传送的数据量增大。
HTTP1.0和HTTP1.1
HTTP1.0:
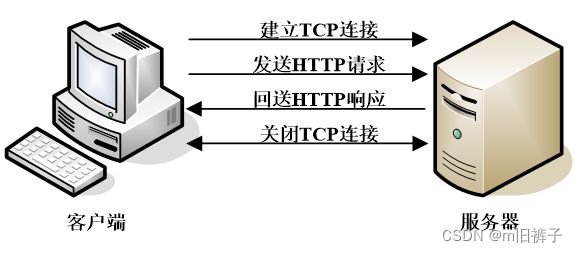
基于HTTP 1.0协议的客户端与服务器在交互过程中需要经过建立连接、发送请求信息、回送响应信息、关闭连接4个步骤。
缺陷:
<html>
<body>
<img src="/image01.jpg">
<img src="/image02.jpg">
<img src="/image03.jpg">
body>
html>
当客户端访问这些图片时,需要发送三次请求,并且每次请求都需要与服务器重新建立连接。如此一来,必然导致客户端与服务器交互耗时,影响网页的访问速度。
HTTP1.1:
为了克服上述HTTP 1.0客户端与服务器交互耗时的缺陷,HTTP 1.1版本应运而生,它支持持久连接,也就是说在一个TCP连接上可以传送多个HTTP请求和响应,从而减少了建立和关闭连接的消耗和延时。
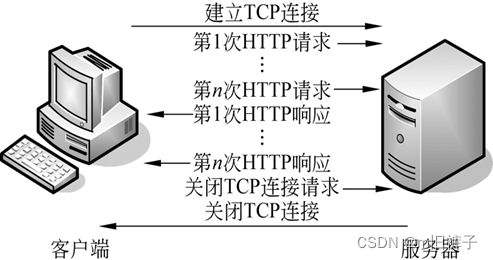
当客户端与服务器建立连接后,客户端可以向服务器发送多个请求,并且在发送下个请求时,无需等待上次请求的返回结果,服务器会按照客户端发送的请求先后顺序依次返回响应结果,以保证客户端能够区分出每次请求的响应内容。HTTP 1.1不仅继承了HTTP 1.0的优点,而且有效解决了HTTP 1.0的性能问题,显著地减少了浏览器与服务器交互所需要的时间。
HTTP请求行
HTTP请求行位于请求消息的第一行,它包括三个部分,它包括三个部分,分别是请求方式、资源路径、以及所使用的HTTP版本。
GET/index.html/1.1
GET是请求方式,index.html是请求资源路径,HTTP/1.1是通信使用的协议版本。
请求行中的每个部分需要用空格分隔,最后要以回车换行结束。
HTTP请求方式
| 请求方式 | 含义 |
|---|---|
| GET | 请求获取请求行的URI所标识的资源 |
| POST | 向指定资源提交数据,请求服务器进行处理(如提交表单或者上传文件) |
| HEAD | 请求获取由URI所标识资源的响应消息头 |
| PUT | 将网页放置到指定URL位置(上传/移动) |
| DELETE | 请求服务器删除URI所标识的资源 |
| TRACE | 请求服务器回送收到的请求信息,主要用于测试或诊断 |
| CONNECT | 保留将来使用 |
| OPTIONS | 请求查询服务器的性能,或者查询与资源相关的选项和需求 |
HTTP请求方式-GET方法
当用户在浏览器地址栏中直接输入某个URL地址或者单击网页上的一个超链接时,浏览器将使用GET方式发送请求。如果将网页上的form表单的method属性设置为“GET”或者不设置method属性(默认值是GET),当用户提交表单时,浏览器也将使用GET方式发送请求。
如果浏览器请求的URL中有参数部分,在浏览器生成的请求消息中,参数部分将附加在请求行中的资源路径后面。先来看一个URL地址,具体如下:
http://www.itcast.cn/javaForum?name=lee&psd=hnxy
“?”后面的内容为参数信息。参数是由参数名和参数值组成的,并且中间使用等号(=)进行连接。如果URL地址中有多个参数,参数之间用“&”分隔。
使用GET方式传送的数据量有限,最多不能超过2KB
HTTP请求方式-POST方法
如果网页上form表单的method属性设置为“POST”,当用户提交表单时,浏览器将使用POST方式提交表单内容,并把form表单的元素及数据作为HTTP消息的实体内容发送给服务器,而不是作为URL地址的参数传递。另外,在使用POST方式向服务器传递数据时,Content-Type消息头会自动设置为“application/x-www-form-urlencoded”,Content-Length消息头会自动设置为实体内容的长度,具体示例如下:
POST /javaForum HTTP/1.1
Host: www.itcast.cn
Content-Type: application/x-www-form-urlencoded
Content-Length: 17
name=lee&psd=hnxy
在实际开发中,通常都会使用POST方式发送请求,原因主要有以下两个:
(1)POST传输数据大小无限制
由于GET请求方式是通过请求参数传递数据的,因此最多可传递2KB的数据。而POST请求方式是通过实体内容传递数据的,因此可以传递数据的大小没有限制。
(2)POST比GET请求方式更安全
由于GET请求方式的参数信息都会在URL地址栏明文显示,而POST请求方式传递的参数隐藏在实体内容中,用户是看不到的,因此POST比GET请求方式更安全。
HTTP请求头
在HTTP请求消息中,请求行之后便是若干请求头。请求头主要用于向服务器传递附加消息,例如,客户端可以接收的数据类型、压缩方法、语言以及发送请求的超链接所属页面的URL地址等信息,具体示例如下所示:
Host: localhost:8080
Accept: image/gif, image/x-xbitmap, *
Referer: http://localhost:8080/itcast/
Accept-Language: zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate
Content-Type: application/x-www-form-urlencoded
User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 10.0; GTB6.5; CIBA)
Connection: Keep-Alive
Cache-Control: no-cache
请求头中可以看出,每个请求头都是由头字段名称和值构成,头字段名称和值之间用冒号(:)和空格分隔,每个请求头之后使用一个回车换行符标志结束。需要注意的是,头字段名称不区分大小写,但习惯上将单词的第一个字母大写。
| 头字段 | 说明 |
|---|---|
| Accept | Accept头字段用于指出客户端程序(通常是浏览器)能够处理的MIME(Multipurpose Internet Mail Extension)类型 |
| Accept-Charset | Accept-Charset头字段用于告知服务器客户端所使用的字符集 |
| Accept-Encoding | Accept-Encoding头字段用于指定客户端能够进行解码的数据编码方式,这里的编码方式通常指的是某种压缩方式 |
| Accept-Language | Accept-Language头字段用于指定客户端期望服务器返回哪个国家语言的文档 |
| Authorization | 当客户端访问受口令保护的网页时,Web服务器会发送401响应状态码和WWW-Authenticate响应头,要求客户端使用Authorization请求头来应答 |
| Proxy-Authorization | Proxy-Authorization头字段的作用与用法与Authorization头字段基本相同,只不过Proxy-Authorization请求头是服务器向代理服务器发送的验证信息 |
| Host | Host头字段用于指定资源所在的主机名和端口号 |
| If-Match | 当客户机再次向服务器请求这个网页文件时,可以使用If-Match头字段附带以前缓存的实体标签内容,这个请求被视为一个条件请求 |
| If-Modified-Since | If-Modified-Since请求头的作用和If-Mach类似,只不过它的值为GMT格式的时间 |
| Range | 用于指定服务器只需返回文档中的部分内容及内容范围,这对较大文档的断点续传非常有用 |
| Max-Forward | 指定当前请求可以途经的代理服务器数量,每经过一个代理服务器,此数值就减1 |
| Referer | Referer头字段非常有用,常被网站管理人员用来追踪网站的访问者是如何导航进入网站的。同时Referer头字段还可以用于网站的防盗链 |
| User-Agent | User-Agent中文名为用户代理,简称 UA,它用于指定浏览器或者其他客户端程序使用的操作系统及版本、浏览器及版本、浏览器渲染引擎、浏览器语言等,以便服务器针对不同类型的浏览器而返回不同的内容 |
HTTP响应状态行
HTTP响应状态行位于响应消息的第一行,它包括3个部分,分别是HTTP版本、一个表示成功或错误的整数代码(状态码)和对状态码进行描述的文本信息。HTTP响应状态行具体示例如下:
HTTP/1.1 200 OK
HTTP/1.1是通信使用的协议版本,200是状态码,OK是状态描述,说明客户端请求成功。需要注意的是,请求行中的每个部分需要用空格分隔,最后要以回车换行结束。
状态代码由3位数字组成,表示请求是否被理解或被满足。HTTP响应状态码的第一个数字定义了响应的类别,后面两位没有具体的分类。第一个数字有5种可能的取值。
| 状态码 | 说明 |
|---|---|
| 200 | 表示服务器成功处理了客户端的请求。客户端的请求成功,响应消息返回正常的请求结果 |
| 302 | 表示请求的资源临时从不同的URI响应请求,但请求者应继续使用原有位置来进行以后的请求。例如,在请求重定向中,临时URI应该是响应的Location头字段所指向的资源 |
| 304 | 如果客户端有缓存的文档,它会在发送的请求消息中附加一个If-Modified-Since请求头,表示只有请求的文档在If-Modified-Since指定的时间之后发生过更改,服务器才需要返回新文档。状态码304表示客户端缓存的版本是最新的,客户端应该继续使用它。否则,服务器将使用状态码200返回所请求的文档 |
| 404 | 表示服务器找不到请求的资源。例如,访问服务器不存在的网页经常返回此状态码 |
| 500 | 表示服务器发生错误,无法处理客户端的请求。大部分情况下,是服务器的CGI、ASP、JSP等程序发生了错误,一般服务器会在相应消息中提供具体的错误信息 |
HTTP响应头
在HTTP响应消息中,第一行为响应状态行,紧接着是若干响应头,服务器通过响应头向客户端传递附加信息,包括服务程序名、被请求资源需要的认证方式、客户端请求资源的最后修改时间、重定向地址等信息。HTTP响应头的具体示例如下所示:
Server: Apache-Coyote/1.1
Content-Encoding: gzip
Content-Length: 80
Content-Language: zh-cn
Content-Type: text/html; charset=GB2312
Last-Modified: Mon, 06 Jul 2020 07:47:47 GMT
Expires: -1
Cache-Control: no-cache
Pragma: no-cache
| 头字段 | 说明 |
|---|---|
| Accept-Range | 用于说明服务器是否接收客户端使用Range请求头字段请求资源 |
| Age | 用于指出当前网页文档可以在客户端或代理服务器中缓存的有效时间,设置值为一个以秒为单位的时间数 |
| Etag | 用于向客户端传送代表实体内容特征的标记信息,这些标记信息称为实体标签,每个版本的资源的实体标签是不同的,通过实体标签可以判断在不同时间获得的同一资源路径下的实体内容是否相同 |
| Location | 用于通知客户端获取请求文档的新地址,其值为一个使用绝对路径的URL地址 |
| Retry-After | 可以与503状态码配合使用,告诉客户端在什么时间可以重新发送请求。也可以与任何一个3xx状态码配合使用,告诉客户端处理重定向的最小延时时间。Retry-After头字段的值可以是GMT格式的时间,也可是一个以秒为单位的时间数 |
| 头字段 | 说明 |
|---|---|
| Server | 用于指定服务器软件产品的名称 |
| Vary | 用于指定影响了服务器所生成的响应内容的那些请求头字段名 |
| WWW-Authenticate | 当客户端访问受口令保护的网页文件时,服务器会在响应消息中回送01(Unauthrized)响应状态码和WWW-Authoricate响应头,指示客户端应该在Authorization请求头中使用WWW-Authoricate响应头指定的认证方式提供用户名和密码信息 |
| Proxy-Authenticate | Proxy-Authenticate头字段是针对代理服务器的用户信息验证,用法与WWW-Authenticate头字段类似 |
| Refresh | 用于告诉浏览器自动刷新页面的时间,它的值是一个以秒为单位的时间数 |
| Content-Disposition | 如果服务器希望浏览器不是直接处理响应的实体内容,而是让用户选择将响应的实体内容保存到一个文件中,这需要使用Content-Disposition头字段 |
Servlet
servlet基础
概念
Servlet是运行在Web服务器端的Java应用程序,它使用Java语言编写。与Java程序的区别是,Servlet 对象主要封装了对HTTP请求的处理,并且它的运行需要Servlet容器的支持。在Java Web应用方面,Servlet 的应用占有十分重要的地位,它在Web请求的处理功能方面也非常强大。
Servlet容器
Servlet由Servlet容器提供,Servlet容器是指提供了Servlet 功能的服务器(这里指Tomcat)。Servlet容器将Servlet动态地加载到服务器上。与HTTP 协议相关的Servlet使用HTTP请求和HTTP响应与客户端进行交互。因此,Servlet容器支持所有HTTP协议的请求和响应。
Servlet应用程序的体系结构
Servlet的请求首先会被HTTP服务器(如Apache)接收,HTTP服务器只负责静态HTML页面的解析,对于Servlet的请求转交给Servlet容器,Servlet容器会根据web.xml文件中的映射关系,调用相应的Servlet,Servlet将处理的结果返回给Servlet容器,并通过HTTP服务器将响应传输给客户端。

特点
-
功能强大
Servlet采用Java语言编写,它可以调用Java API中的对象及方法,此外,Servlet对象对Web应用进行了封装,提供了Servlet对Web应用的编程接口,还可以对HTTP请求进行相应的处理,如处理提交数据、会话跟踪、读取和设置HTTP头信息等。由于Servlet既拥有Java 提供的API,而且还可以调用Servlet封装的Servlet API编程接口,所以,它在业务功能方面十分强大。
-
可移植
java语言是跨平台的
-
性能高效
Servlet对象在Servlet容器启动时被初始化,当Servlet对象第一次被请求时,Servlet 容器将Servlet对象实例化,此时Servlet对象驻存于内存中。如果存在多个请求,Servlet 不会再被实例化,仍然由第一次被实例化的Servlet对象处理其他请求。每一个请求是一个线程,而不是一个进程。
-
安全性高
Servlet使用了Java的安全框架,同时Servlet容器还可以为Servlet提供额外的安全功能,它的安全性是非常高的。
-
可扩展
Java语言是面向对象的编程语言, Servlet由Java语言编写,所以它具有面向对象的优点。在业务逻辑处理中,可以通过封装、继承等特性扩展实际的业务需要。
接口
| 方法声明 | 功能描述 |
|---|---|
| void init(ServletConfig config) | Servlet实例化后,Servlet容器调用该方法完成初始化工作 |
| ServletConfig getServletConfig() | 用于获取Servlet对象的配置信息,返回Servlet的ServletConfig对象 |
| String getServletInfo() | 返回一个字符串,其中包含关于Servlet的信息,例如,作者、版本和版权等信息 |
| void service(ServletRequest request,ServletResponse response) | 负责响应用户的请求,当容器接收到客户端访问Servlet对象的请求时,就会调用此方法。容器会构造一个表示客户端请求信息的ServletRequest对象和一个用于响应客户端的ServletResponse对象作为参数传递给service()方法。在service()方法中,可以通过ServletRequest对象得到客户端的相关信息和请求信息,在对请求进行处理后,调用ServletResponse对象的方法设置响应信息 |
| void destroy() | 负责释放Servlet对象占用的资源。当服务器关闭或者Servlet对象被移除时,Servlet对象会被销毁,容器会调用此方法 |
Servlet接口的实现类
针对Servlet接口,SUN公司提供了两个默认的接口实现类:GenericServlet和HttpServlet。GenericServlet是一个抽象类,该类为Servlet接口提供了部分实现,它并没有实现HTTP请求处理。HttpServlet是GenericServlet的子类,它继承了GenericServlet的所有方法,并且为HTTP请求中的POST、GET等类型提供了具体的操作方法。
HttpServlet类的常用方法及功能
| 方法声明 | 功能描述 |
|---|---|
| protected void doGet(HttpServletRequest req, HttpServletResponse resp) | 用于处理GET类型的Http请求的方法 |
| protected void doPost(HttpServletRequest req, HttpServletResponse resp) | 用于处理POST类型的Http请求的方法 |
| protected void doPut(HttpServletRequest req, HttpServletResponse resp) | 用于处理PUT类型的Http请求的方法 |
Servlet的配置
web.xml配置Servlet
把Servlet映射到URL地址,使用标签进行映射,使用子标签指定要映射的Servlet名称,名称要和之前在标签下注册的相同;使用子标签映射URL地址,地址前必须加“/”,否则访问不到。
<servlet>
<servlet-name>servletDemo2servlet-name>
<servlet-class>com.cong.servlet.ServletDemo2servlet-class>
servlet>
<servlet-mapping>
<servlet-name>servletDemo2servlet-name>
<url-pattern>/servletDemo2url-pattern>
servlet-mapping>
@WebServlet注解属性
@WebServlet 注解用于代替web.xml文件中的等标签,该注解将会在项目部署时被容器处理,容器将根据具体的属性配置将相应的类部署为Servlet。为此,@WebServlet注解提供了一些属性。
| 属性声明 | 功能描述 |
|---|---|
| String name | 指定Servlet的name属性,等价于。如果没有显式指定,则该 Servlet的取值即为类的全限定名。 |
| String[] value | 该属性等价于urlPatterns属性。urlPatterns和value属性不能同时使用。 |
| String[] urlPatterns | 指定一组Servlet的URL匹配模式。等价于标签。 |
| int loadOnStartup | 指定Servlet的加载顺序,等价于标签。 |
| WebInitParam[] | 指定一组Servlet初始化参数,等价于标签。 |
| boolean asyncSupported | 声明Servlet是否支持异步操作模式,等价于 标签。 |
| String description | Servlet的描述信息,等价于标签。 |
| String displayName | Servlet的显示名,通常配合工具使用,等价于 标签。 |
@WebServlet注解可以标注在任意一个继承了HttpServlet类的类之上,属于类级别的注解。下面使用@WebServlet注解标注ActionServlet类。

@WebServlet(name = "HelloServlet",urlPatterns = "/HelloServlet")
public class HelloServlet extends HttpServlet{
//处理GET方法请求的方法
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {}
//处理POST方法请求的方法
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {}
}
使用@WebServlet注解将HelloServlet类标注为一个Servlet。@WebServlet注解中的name属性值用于指定servlet的name属性,等价于,如果没有设置@WebServlet的name属性,其默认值是Servlet的类完整名称。urlPatterns属性值用于指定一组servlet的url的匹配模式,等价于标签。如果需要在@WebServlet注解中设置多个属性,属性之间用逗号隔开。通过@WebServlet注解能极大地简化了Servlet的配置步骤,降低了开发人员的开发难度。
Servlet的生命周期
初始阶段,运行阶段和销毁阶段
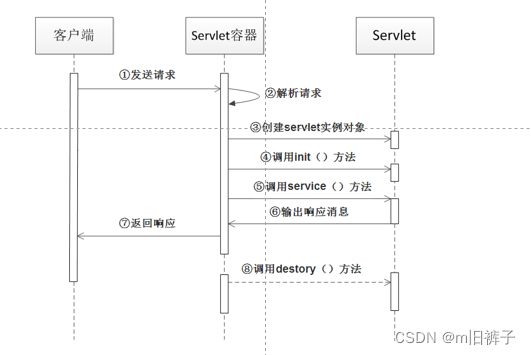
初始化阶段(init)
当客户端向Servlet容器发出HTTP请求访问Servlet时,Servlet容器首先会解析请求,检查内存中是否已经有了该Servlet对象,如果有,直接使用该Servlet对象;如果没有,就创建Servlet实例对象,然后通过调用init()方法完成Servlet的初始化。需要注意的是,在Servlet的整个生命周期内,它的init()方法只被调用一次。
运行阶段(service)
这是Servlet生命周期中最重要的阶段,在这个阶段,Servlet容器会为客户端请求创建代表HTTP请求的ServletRequest对象和代表HTTP响应的ServletResponse对象,然后将它们作为参数传递给Servlet的service()方法。service()方法从ServletRequest对象中获得客户端请求信息并处理该请求,通过ServletResponse对象生成响应结果。在Servlet的整个生命周期内,对于Servlet的每一次访问请求,Servlet容器都会调用一次Servlet的service()方法,并且创建新的ServletRequest和ServletResponse对象,也就是说,service()方法在Servlet的整个生命周期中会被调用多次。
销毁阶段(destroy)
当服务器关闭或web应用被移除出容器时,Servlet随着web应用的销毁而销毁。在销毁Servlet之前,Servlet容器会调用Servlet的destroy()方法,以便让Servlet对象释放它所占用的资源。在Servlet的整个生命周期中,destroy()方法也只被调用一次。
需要注意的是,Servlet对象一旦创建就会驻留在内存中等待客户端的访问,直到服务器关闭,或web应用被移除出容器时Servlet对象才会销毁。

ServletConfig接口
在Servlet运行期间,经常需要一些配置信息,例如,文件使用的编码等,这些信息都可以在@WebServlet注解的属性中配置。当Tomcat初始化一个Servlet时,会将该Servlet的配置信息封装到一个ServletConfig对象中,通过调用init(ServletConfig config)方法将ServletConfig对象传递给Servlet。ServletConfig定义了一系列获取配置信息的方法。
| 方法说明 | 功能描述 |
|---|---|
| String getInitParameter(String name) | 根据初始化参数名返回对应的初始化参数值 |
| Enumeration getInitParameterNames() | 返回一个Enumeration对象,其中包含了所有的初始化参数名 |
| ServletContext getServletContext() | 返回一个代表当前Web应用的ServletContext对象 |
| String getServletName() | 返回Servlet的名字 |
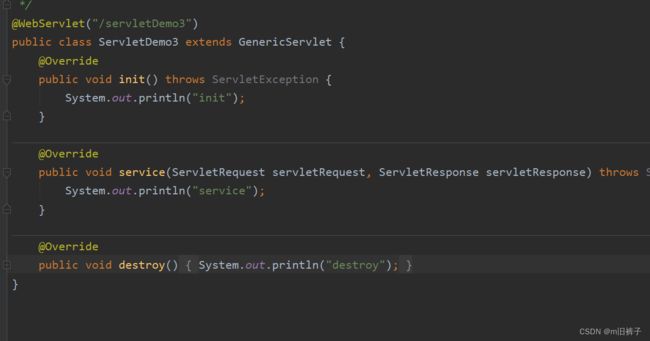
@WebServlet(urlPatterns="/servletDemo4",
initParams = {@WebInitParam(name="encoding", value="utf-8")}
)
public class servletDemo4 extends HttpServlet {
/*ServletConfig
随着 servlet实例的创建而创建
通过init(ServletConfig config) 当成参数传递给servlet
封装着servlet的配置信息
出场设置:servert的名字 servletContext
后期配置的:initParameter 获取
*/
@Override
protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
ServletConfig servletConfig=this.getServletConfig();
String servletName = servletConfig.getServletName();//获取到servlet的名字
ServletContext servletContext = servletConfig.getServletContext();//获取到servletContext配置
String encoding = servletConfig.getInitParameter("encoding");
resp.getWriter().write(servletName+"\n"+servletContext+"\n"+encoding);
}
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
doGet(req,resp);
}
}
ServletContext接口
当Servlet容器启动时,会为每个Web应用创建一个唯一的ServletContext对象代表当前Web应用。ServletContext对象不仅封装了当前Web应用的所有信息,而且实现了多个Servlet之间数据的共享。
获取Web应用程序的初始化参数
<context-param>
<param-name>参数名</param-name>
<param-value>参数值</param-value>
</context-param>
<!-- 配置servletContext 接口中的信息-->
<context-param>
<param-name>companyName</param-name>
<param-value>cong</param-value>
</context-param>
<context-param>
<param-name>city</param-name>
<param-value>xinxiang</param-value>
</context-param>
<context-param>
<param-name>course</param-name>
<param-value>java</param-value>
</context-param>
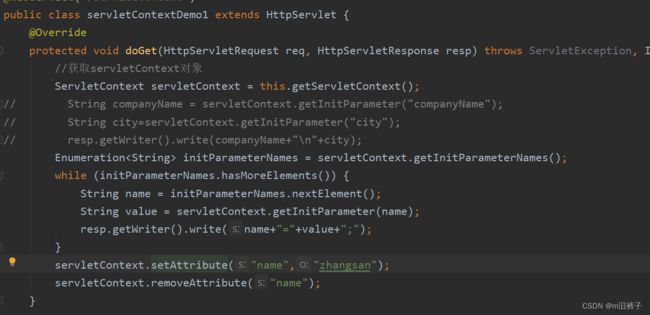
//获取servletContext对象
ServletContext servletContext = this.getServletContext();
// String companyName = servletContext.getInitParameter("companyName");
// String city=servletContext.getInitParameter("city");
// resp.getWriter().write(companyName+"\n"+city);
//得到包含所有初始化参数名的Enumeration对象
Enumeration<String> initParameterNames = servletContext.getInitParameterNames();
while (initParameterNames.hasMoreElements()) {
String name = initParameterNames.nextElement();
String value = servletContext.getInitParameter(name);
resp.getWriter().write(name+"="+value+";");
}
实现多个Servlet对象共享数据
由于一个Web应用中的所有Servlet共享同一个ServletContext对象,所以ServletContext对象的域属性可以被该Web应用中的所有Servlet访问。ServletContext接口中定义了用于增加、删除、设置ServletContext域属性的四个方法。
| 方法说明 | 功能描述 |
|---|---|
| Enumeration getAttributeNames() | 返回一个Enumeration对象,该对象包含了所有存放在ServletContext中的所有域属性名 |
| Object getAttibute(String name) | 根据参数指定的属性名返回一个与之匹配的域属性值 |
| void removeAttribute(String name) | 根据参数指定的域属性名,从ServletContext中删除匹配的域属性 |
| void setAttribute(String name,Object obj) | 设置ServletContext的域属性,其中name是域属性名,obj是域属性值 |
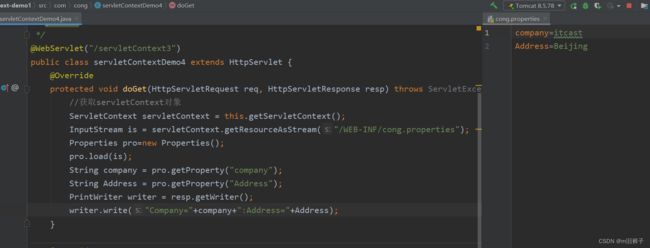
读取Web应用下的资源文件
ServletContext接口定义了一些读取Web资源的方法,这些方法是依靠Servlet容器来实现的。Servlet容器根据资源文件相对于Web应用的路径,返回关联资源文件的IO流、资源文件在文件系统的绝对路径等。
| 方法说明 | 功能描述 |
|---|---|
| Set getResourcePaths(String path) | 返回一个Set集合,集合中包含资源目录中子目录和文件的路径名称。参数path必须以正斜线(/)开始,指定匹配资源的部分路径 |
| String getRealPath(String path) | 返回资源文件在服务器文件系统上的真实路径(文件的绝对路径)。参数path代表资源文件的虚拟路径,它应该以正斜线(/)开始,“/”表示当前Web应用的根目录,如果Servlet容器不能将虚拟路径转换为文件系统的真实路径,则返回null |
| URL getResource(String path) | 返回映射到某个资源文件的URL对象。参数path必须以正斜线(/)开始,“/”表示当前Web应用的根目录 |
| InputStream getResourceAsStream(String path) | 返回映射到某个资源文件的InputStream输入流对象。参数path传递规则和getResource()方法完全一致 **** |
发送状态码的相关的方法
当Servlet向客户端回送响应消息时,需要在响应消息中设置状态码,状态码代表着客户端请求服务器的结果。为此,HttpServletResponse接口定义了3个发送状态码的方法。
HttpServletResponse接口
setStatus(int status)方法
setStatus(int status)方法用于设置HTTP响应消息的状态码,并生成响应状态行。由于响应状态行中的状态描述信息直接与状态码相关,而HTTP版本由服务器确定,所以,只要通过setStatus(int status)方法设置了状态码,即可实现状态行的发送。例如,正常情况下,Web服务器会默认产生一个状态码为200的状态行。
sendError(int sr)方法
sendError(int sc)方法用于发送表示错误信息的状态码,例如,404状态码表示找不到客户端请求的资源。
sendError(int code, String message)方法
sendError(int code, String message)方法除了设置状态码,还会向客户端发出一条错误信息。服务器默认会创建一个HTML格式的错误服务页面作为响应结果,其中包含参数message指定的文本信息,这个HTML页面的内容类型为“text/html”,保留cookies和其他未修改的响应头信息。如果一个对应于传入的错误码的错误页面已经在web.xml中声明,那么这个声明的错误页面会将优先建议的message参数服务于客户端。
发送响应头相关的方法
| 方法说明 | 功能描述 |
|---|---|
| void addHeader(String name, String value) | 这两个方法都是用来设置HTTP协议的响应头字段,其中,参数name用于指定响应头字段的名称,参数value用于指定响应头字段的值。不同的是,addHeader()方法可以增加同名的响应头字段,而setHeader()方法则会覆盖同名的头字段 |
| void setHeader(String name, String value) | |
| void addIntHeader(String name, int value) | 这两个方法专门用于设置包含整数值的响应头。避免了调用addHeader()与setHeader()方法时,需要将int类型的设置值转换为String类型的麻烦 |
| void setIntHeader(String name, int value) | |
| void setContentLength(int len) | 该方法用于设置响应消息的实体内容的大小,单位为字节。对于HTTP协议来说,这个方法就是设置Content-Length响应头字段的值 |
| 方法说明 | 功能描述 |
|---|---|
| void setContentType(String type) | 该方法用于设置Servlet输出内容的MIME类型,对于HTTP协议来说,就是设置Content-Type响应头字段的值。例如,如果发送到客户端的内容是jpeg格式的图像数据,就需要将响应头字段的类型设置为“image/jpeg”。需要注意的是,如果响应的内容为文本,setContentType()方法的还可以设置字符编码,如:text/html;charset=UTF-8 |
| void setLocale(Locale loc) | 该方法用于设置响应消息的本地化信息。对HTTP来说,就是设置Content-Language响应头字段和Content-Type头字段中的字符集编码部分。需要注意的是,如果HTTP消息没有设置Content-Type头字段,setLocale()方法设置的字符集编码不会出现在HTTP消息的响应头中,如果调用setCharacterEncoding()或setContentType()方法指定了响应内容的字符集编码,setLocale()方法将不再具有指定字符集编码的功能 |
| void setCharacterEncoding(String charset) | 该方法用于设置输出内容使用的字符编码,对HTTP 协议来说,就是设置Content-Type头字段中的字符集编码部分。如果没有设置Content-Type头字段,setCharacterEncoding方法设置的字符集编码不会出现在HTTP消息的响应头中。setCharacterEncoding()方法比setContentType()和setLocale()方法的优先权高,setCharacterEncoding()方法的设置结果将覆盖setContentType()和setLocale()方法所设置的字符码表 |
发送响应消息的相关方法
getOutputStream()方法所获取的字节输出流对象为ServletOutputStream类型。由于ServletOutputStream是OutputStream的子类,它可以直接输出字节数组中的二进制数据。所以,要想输出二进制格式的响应正文,就需要调用getOutputStream()方法。
getWriter()方法所获取的字符输出流对象为PrintWriter类型。由于PrintWriter类型的对象可以直接输出字符文本内容,所以,要想输出内容为字符文本的网页文档,需要调用getWriter()方法。
//方式一 get Writer()
PrintWriter writer = resp.getWriter();
writer.write("welcome to servlet");
//方式二 getOutputStream()
ServletOutputStream os = resp.getOutputStream();
String str ="welcome to servlet";
os.write(str.getBytes());
os.print(str);
HttpServletResponse对象
sentRedirect()方法实现重定向
在某些情况下,针对客户端的请求,一个Servlet类可能无法完成全部工作。这时,可以使用请求重定向来完成。所谓请求重定向,指的是Web服务器接收到客户端的请求后,可能由于某些条件限制,不能访问当前请求URL所指向的Web资源,而是指定了一个新的资源路径,让客户端重新发送请求。
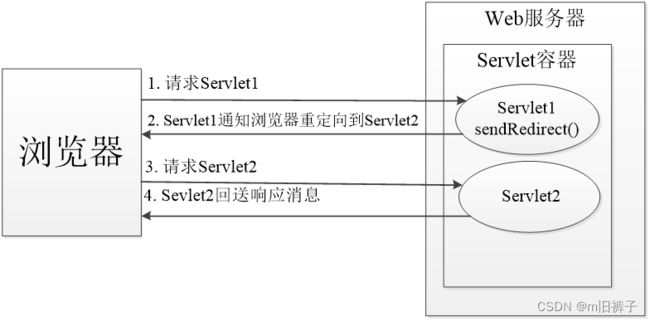

解决中文乱码的两种方式
由于计算机中的数据都是以二进制形式存储的,所以,当传输文本时,就会发生字符和字节之间的转换。字符与字节之间的转换是通过查码表完成的,将字符转换成字节的过程称为编码,将字节转换成字符的过程称为解码,如果编码和解码使用的码表不一致,就会导致乱码问题。
String data="中国";
resp.getWriter().write(str);
//在页面中就会显示两个问号,这就是发生了乱码
浏览器的显示内容没有出现乱码,说明通过修改浏览器的编码方式可以解决乱码。但是,这样的做法仍然是不可取的,因为不能让用户每次都设置浏览器编码。为此,HttpServletResponse接口提供了两种解决乱码的方案,具体如下。
一、
resp.setContentType("text/html;charset=utf-8");
String str="中国";
resp.getWriter().write(str);
二、
resp.setCharacterEncoding("utf-8");
resp.setHeader("Content-Type","text/html;charset=utf-8");
String str="中国";
resp.getWriter().write(str);
HttpServletRequest对象
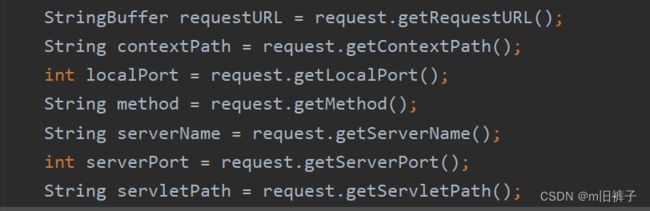
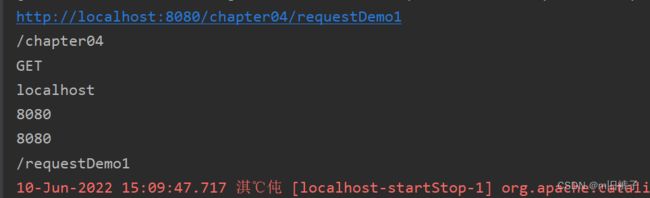
获取请求行的相关方法
| 方法声明 | 功能描述 |
|---|---|
| String getMethod( ) | 该方法用于获取HTTP请求消息中的请求方式(如GET、POST等) |
| String getRequestURI( ) | 该方法用于获取请求行中资源名称部分,即位于URL的主机和端口之后、参数部分之前的数据 |
| String getQueryString( ) | 该方法用于获取请求行中的参数部分,也就是资源路径后面问号(?)以后的所有内容 |
| String getProtocol( ) | 该方法用于获取请求行中的协议名和版本,例如HTTP/1.0或HTTP/1.1 |
| String getContextPath( ) | 该方法用于获取请求URL中属于Web应用程序的路径,这个路径以“/”开头,表示相对于整个Web站点的根目录,路径结尾不含“/”。如果请求URL属于Web站点的根目录,那么返回结果为空字符串(“”) |
| String getServletPath( ) | 该方法用于获取Servlet的名称或Servlet所映射的路径 |
| String getRemoteAddr( ) | 该方法用于获取请求客户端的IP地址,其格式类似于“192.168.0.3” |
| String getRemoteHost( ) | 该方法用于获取请求客户端的完整主机名,其格式类似于“pc1.itcast.cn”。需要注意的是,如果无法解析出客户机的完整主机名,该方法将会返回客户端的IP地址 |
| 方法声明 | 功能描述 |
|---|---|
| int getRemotePort() | 该方法用于获取请求客户端网络连接的端口号 |
| String getLocalAddr() | 该方法用于获取Web服务器上接收当前请求网络连接的IP地址 |
| String getLocalName() | 该方法用于获取Web服务器上接收当前网络连接IP所对应的主机名 |
| int getLocalPort() | 该方法用于获取Web服务器上接收当前网络连接的端口号 |
| String getServerName() | 该方法用于获取当前请求所指向的主机名,即HTTP请求消息中Host头字段所对应的主机名部分 |
| int getServerPort() | 该方法用于获取当前请求所连接的服务器端口号,即如果HTTP请求消息中Host头字段所对应的端口号部分 |
| String getScheme() | 该方法用于获取请求的协议名,例如http、https或ftp |
| StringBuffer getRequestURL() | 该方法用于获取客户端发出请求时的完整URL,包括协议、服务器名、端口号、资源路径等信息,但不包括后面的查询参数部分。注意,getRequestURL()方法返回的结果是StringBuffer类型,而不是String类型,这样更便于对结果进行修改 |
获取请求头的相关方法
| 方法声明 | 功能描述 |
|---|---|
| String getHeader(String name) | 该方法用于获取一个指定头字段的值,如果请求消息中没有包含指定的头字段,getHeader()方法返回null;如果请求消息中包含有多个指定名称的头字段,getHeader()方法返回其中第一个头字段的值 |
| Enumeration getHeaders(String name) | 该方法返回一个Enumeration集合对象,该集合对象由请求消息中出现的某个指定名称的所有头字段值组成。在多数情况下,一个头字段名在请求消息中只出现一次,但有时候可能会出现多次 |
| Enumeration getHeaderNames() | 该方法用于获取一个包含所有请求头字段的Enumeration对象 |
| int getIntHeader(String name) | 该方法用于获取指定名称的头字段,并且将其值转为int类型。需要注意的是,如果指定名称的头字段不存在,返回值为-1;如果获取到的头字段的值不能转为int类型,将发生NumberFormatException异常 |
| long getDateHeader(String name) | 该方法用于获取指定头字段的值,并将其按GMT时间格式转换成一个代表日期/时间的长整数,这个长整数是自1970年1月1日0点0分0秒算起的以毫秒为单位的时间值 |
| String getContentType() | 该方法用于获取Content-Type头字段的值,结果为String类型 |
| int getContentLength() | 该方法用于获取Content-Length头字段的值,结果为int类型 |
| String getCharacterEncoding() | 该方法用于返回请求消息的实体部分的字符集编码,通常是从Content-Type头字段中进行提取,结果为String类型 |
//根据指定的name获取请求头的值
String accept = request.getHeader("Accept");
//当请求头的key有多个时,可以获取
Enumeration<String> values = request.getHeaders("Accept");
while (values.hasMoreElements()){
String value = values.nextElement();
System.out.println(value);
}
// System.out.println(accept);
System.out.println("==================================");
Enumeration<String> names = request.getHeaderNames();
while (names.hasMoreElements()){
String name = names.nextElement();
String value = request.getHeader(name);
System.out.println(name+":"+value);
}
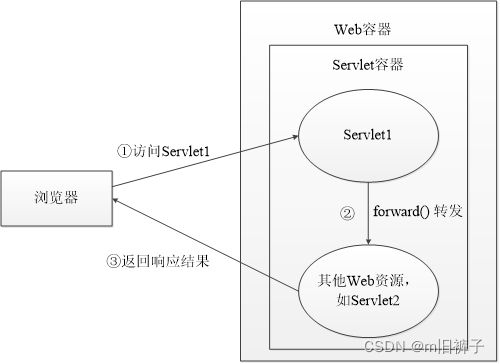
请求转发
Servlet之间可以相互跳转,利用Servlet的跳转可以很容易地把一项任务按模块分开,例如,使用一个Servlet实现用户登录,然后跳转到另外一个Servlet实现用户资料修改。Servlet的跳转要通过RequestDispatcher接口的实例对象实现。HttpServletRequest接口提供了getRequestDispatcher()方法用于获取RequestDispatcher对象,getRequestDispatcher()方法的具体格式如下所示。
RequestDispatcher requestDispatcher = request.getRequestDispatcher("/WEB-INF/forward.html");
获取到RequestDispatcher对象后,如果当前 Web 资源不想处理请求,RequestDispatcher接口提供了一个forward()方法,该方法可以将当前请求传递给其他 Web 资源对这些信息进行处理并响应给客户端,这种方式称为请求转发。forward()方法的具体格式如下所示。
requestDispatcher.forward(request,resp);
forward()方法用于将请求从一个 Servlet 传递给另一个 Web 资源。在 Servlet 中,可以对请求做一个初步处理,然后通过调用forward()方法,将请求传递给其他资源进行响应。需要注意的是,该方法必须在响应提交给客户端之前被调用,否则将抛出 IllegalStateException 异常。
获取请求参数
| 方法声明 | 功能描述 |
|---|---|
| String getParameter(String name) | 该方法用于获取某个指定名称的参数值,如果请求消息中没有包含指定名称的参数,getParameter()方法返回null;如果指定名称的参数存在但没有设置值,则返回一个空串;如果请求消息中包含有多个该指定名称的参数,getParameter()方法返回第一个出现的参数值 |
| String[] getParameterValues(String name) | 该方法用于返回一个String类型的数组,HTTP请求消息中可以有多个相同名称的参数(通常由一个包含有多个同名的字段元素的form表单生成),如果要获得HTTP请求消息中的同一个参数名所对应的所有参数值,那么就应该使用getParameterValues()方法 |
| Enumeration getParameterNames() | 该方法用于返回一个包含请求消息中所有参数名的Enumeration对象,在此基础上,可以对请求消息中的所有参数进行遍历处理 |
| Map getParameterMap() | 该方法用于将请求消息中的所有参数名和值装入进一个Map对象中返回 |
<form action="/chapter04/RequestParamsServlet" method="POST">
用户名:<input type="text" name="username"><br />
密 码:<input type="password" name="password">
<br/>
爱好:
<input type="checkbox" name="hobby" value="sing">唱歌
<input type="checkbox" name="hobby" value="dance">跳舞
<input type="checkbox" name="hobby" value="football">足球<br />
<input type="submit" value="提交">
form>
String username = request.getParameter("username");
String password = request.getParameter("password");
String[] hobbies = request.getParameterValues("hobby");
for (String hobby:hobbies){
System.out.println(hobby);
}
Request对象传递数据
setAttribute()方法用于将一个对象与一个name关联后存储进ServletRequest对象中,其完整声明定义如下。
public void setAttribute(String name,Object o);
request.setAttribute("username","zhangsan");
setAttribute()方法的参数列表的第一个参数接收的是一个String类型的name,第二个参数接收的是一个Object类型的对象o。需要注意的是,如果ServletRequest对象中已经存在指定名称的属性,setAttribute()方法将会先删除原来的属性,然后再添加新的属性。如果传递给setAttribute()方法的属性值对象为null,则删除指定名称的属性,这时的效果等同于removeAttribute()方法。
getAttribute()方法用于从ServletRequest对象中返回指定名称的属性对象,其完整声明如下:
public Object getAttribute(String name);
String username = (String) request.getAttribute("username");
removeAttribute()方法用于从ServletRequest对象中删除指定名称的属性,其完整声明如下:
public void removeAttribute(String name);
getAttributeNames()方法用于返回一个包含ServletRequest对象中的所有属性名的Enumeration对象,在此基础上,可以对ServletRequest对象中的所有属性进行遍历处理。getAttributeNames()方法声明如下:
public Enumeration getAttributeNames();
解决请求参数的中文乱码问题
在HttpServletRequest接口中,提供了一个setCharacterEncoding()方法,该方法用于设置request对象的解码方式,接下来,对RequestParamsServlet类进行修改,修改后的主要代码如下所示。该方法用于返回请求消息的实体部分的字符集编码。
public class RequestParamsServlet extends HttpServlet {
public void doGet(HttpServletRequest request,
HttpServletResponse response)throws ServletException, IOException {
request.setCharacterEncoding("utf-8");
String name = request.getParameter("username");
String password = request.getParameter("password");
System.out.println("用户名:" + name);
System.out.println("密 码:" + password);
//获取参数名为“hobby”的值
String[] hobbys = request.getParameterValues("hobby");
System.out.print("爱好:");
for (int i = 0; i < hobbys.length; i++) {
System.out.print(hobbys[i] + ", ");
}
}
会话与会话技术
当用户通过浏览器访问Web应用时,通常情况下,服务器需要对用户的状态进行跟踪。例如,用户在网站结算商品时,Web服务器必须根据请求用户的身份,找到该用户所购买的商品。在Web开发中,服务器跟踪用户信息的技术称为会话技术。
在日常生活中,从拨通电话到挂断电话之间的一连串的你问我答的过程就是一个会话。在打电话过程中,通话双方会有通话内容,同样,在客户端与服务器交互的过程中,也会产生一些数据。例如,用户甲和乙分别登录了购物网站,甲购买了一个iPhone手机,乙购买了一个iPad,当这两个用户结账时,Web服务器需要对用户甲和乙的信息分别进行保存。为了保存会话过程中产生的数据,Servlet提供了两个用于保存会话数据的对象,分别是Cookie和Session。
Cookie概念
在现实生活中,当顾客在购物时,商城经常会赠送顾客一张会员卡,卡上记录用户的个人信息(姓名,手机号等)、消费额度和积分额度等。顾客一旦接受了会员卡,以后每次光临该商场时,都可以使用这张会员卡,商场也将根据会员卡上的消费记录计算会员的优惠额度和累加积分。在Web应用中,Cookie的功能类似于会员卡,当用户通过浏览器访问Web服务器时,服务器会给客户端发送一些信息,如用户信息和商品信息,这些信息都保存在Cookie中。这样,当该浏览器再次访问服务器时,会在请求头中将Cookie发送给服务器,方便服务器对浏览器做出正确地响应。
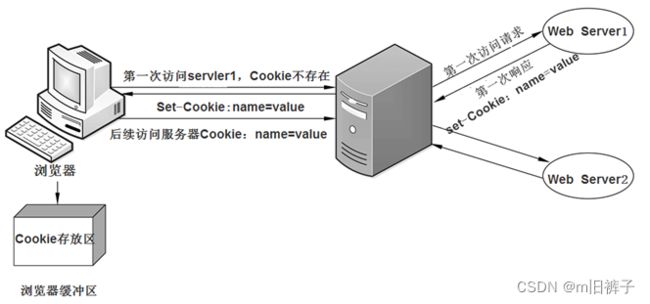
当用户第一次访问服务器时,服务器会在响应消息中增加Set-Cookie头字段,将用户信息以Cookie的形式发送给浏览器。一旦用户浏览器接受了服务器发送的Cookie信息,就会将它保存在浏览器的缓冲区中,这样,当浏览器后续访问该服务器时,都会在请求消息中将用户信息以Cookie的形式发送给服务器,从而使服务器分辨出当前请求是由哪个用户发出的。
Cookie API
构造方法:
public Cookie(java.lang.String name,java.lang.String value);
// name 用于指定Cookie的名称 value 用于指定Cookie的值
//创建cookie
Cookie cookie=new Cookie("username","zhangsan");
//添加到响应对象中,并响应给客户端
resp.addCookie(cookie);
Cookie[] cookies = req.getCookies();
for (Cookie cookie:cookies) {
//获取每一个cookie的名称 name
String name = cookie.getName();
if ("username".equals(name)) {
//获取username所对应的value
String value = cookie.getValue();
//在浏览器展示
resp.getWriter().write("username:"+value);
}
| 方法声明 | 功能描述 |
|---|---|
| String getName() | 用于返回Cookie的名称 |
| void setValue(String newValue) | 用于为Cookie设置一个新的值 |
| String getValue() | 用于返回Cookie的值 |
| void setMaxAge(int expiry) | 用于设置Cookie在浏览器客户机上保持有效的秒数 |
| int getMaxAge() | 用于返回Cookie在浏览器客户机上保持有效的秒数 |
| void setPath(String uri) | 用于设置该Cookie项的有效目录路径 |
| String getPath() | 用于返回该Cookie项的有效目录路径 |
| void setDomain(String pattern) | 用于设置该Cookie项的有效域 |
| String getDomain() | 用于返回该Cookie项的有效域 |
| void setVersion(int v) | 用于设置该Cookie项采用的协议版本 |
| int getVersion() | 用于返回该Cookie项采用的协议版本 |
| void setComment(String purpose) | 用于设置该Cookie项的注解部分 |
| String getComment() | 用于返回该Cookie项的注解部分 |
| void setSecure(boolean flag) | 用于设置该Cookie项是否只能使用安全的协议传送 |
| boolean getSecure() | 用于返回该Cookie项是否只能使用安全的协议传送 |
setMaxAge(int expiry)方法和getMaxAge方法
setMaxAge(int expiry)和getMaxAge()方法分别用于设置和返回Cookie在浏览器上保持有效的秒数。如果设置的值为一个正整数,浏览器会将Cookie信息保存在本地硬盘中。从当前时间开始,在没有超过指定的秒数之前,这个Cookie都保持有效,并且同一台计算机上运行的该浏览器都可以使用这个Cookie信息。如果设置值为负整数,浏览器会将Cookie信息保存在浏览器的缓存中,当浏览器关闭时,Cookie信息会被删除。如果设置值为0,则浏览器会立即删除这个Cookie信息。
//设置cookie的有效存活时间
cookie.setMaxAge(15);
setPath(String uri)方法和getPath()方法
setPath(String uri)方法和getPath()方法是针对Cookie的Path属性的。如果创建的某个Cookie对象没有设置Path属性,那么该Cookie只对当前访问路径所属的目录及其子目录有效。如果想让某个Cookie项对站点的所有目录下的访问路径都有效,应调用Cookie对象的setPath()方法将其Path属性设置为“/”。
//设置Path属性
cookie.setPath("/");
setDomain(String pattern)方法和getDomain()方法
setDomain(String pattern)方法和getDomain()方法是针对Cookie的domain属性的。domain属性用于指定浏览器访问的域。例如,传智播客的域为“itcast.cn”。设置domain属性时,其值必须以“.”开头,如domain=.itcast.cn。默认情况下,domain属性的值为当前主机名,浏览器在访问当前主机下的资源时,都会将Cookie信息发送给服务器(当前主机)。需要注意的是,domain属性的值不区分大小写。
Session对象
当人们去医院就诊时,就诊病人需要办理医院的就诊卡,就诊卡上只有卡号,没有其他信息。但病人每次去该医院就诊时,只要出示就诊卡,医务人员便可根据卡号查询到病人的就诊信息。Session技术类似医院办理就诊卡和医院为每个病人保留病历档案的过程。当浏览器访问Web服务器时,Servlet容器就会创建一个Session对象和ID属性, Session对象就相当于病历档案,ID就相当于就诊卡号。当客户端后续访问服务器时,只要将ID传递给服务器,服务器就能判断出该请求是哪个客户端发送的,从而选择与之对应的Session对象为其服务。
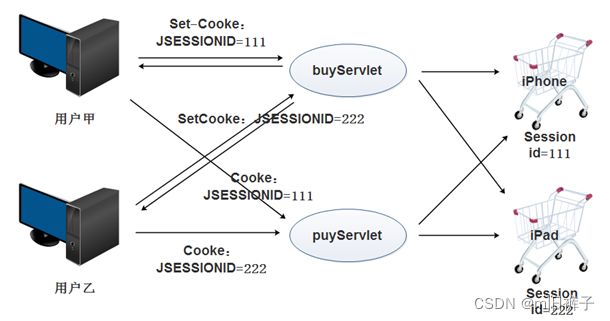
Session还具有更高的安全性,它将关键数据保存在服务器。cookie则是将数据存在客户端的浏览器中。因此cookie是较为危险的,若客户端遭遇黑客攻击,cookie信息容易被窃取,数据也可能被篡改,而运用Session可以有效避免这种情况的发生。
HttpSession API
Session是与每个请求消息紧密相关的,为此,HttpServletRequest定义了用于获取Session对象的getSession()方法,该方法有两种重载形式,具体如下:
public HttpSession getSession(boolean create)//第一个
public HttpSession getSession()//第二个
第一个getSession()方法根据传递的参数判断是否创建新的HttpSession对象,如果参数为true,则在相关的HttpSession对象不存在时创建并返回新的HttpSession对象,否则不创建新的HttpSession对象,而是返回null。
第二个getSession()方法相当于第一个方法参数为true时的情况,在相关的HttpSession对象不存在时总是创建新的HttpSession对象。需要注意的是,由于getSession()方法可能会产生发送会话标识号的Cookie头字段,所以必须在发送任何响应内容之前调用getSession()方法。
| 方法声明 | 功能描述 |
|---|---|
| String getId() | 用于返回与当前HttpSession对象关联的会话标识号 |
| long getCreationTime() | 用于返回Session创建的时间,这个时间是创建Session的时间与1970年1月1日00:00:00之间时间差的毫秒表示形式 |
| long getLastAccessedTime() | 用于返回客户端最后一次发送与Session相关请求的时间,这个时间是发送请求的时间与1970年1月1日00:00:00之间时间差的毫秒表示形式 |
| void setMaxInactiveInterval(int interval) | 用于设置当前HttpSession对象可空闲的以秒为单位的最长时间,也就是修改当前会话的默认超时间隔 |
| boolean isNew() | 判断当前HttpSession对象是否是新创建的 |
| void invalidate() | 用于强制使Session对象无效 |
| ServletContext getServletContext() | 用于返回当前HttpSession对象所属于的Web应用程序对象,即代表当前Web应用程序的ServletContext对象 |
| void setAttribite(String name,Object value) | 用于将一个对象与一个名称关联后存储到当前的HttpSession对象中 |
| String getAttribute() | 用于从当前HttpSession对象中返回指定名称的属性对象 |
| void removeAttribute(String name) | 用于从当前HttpSession对象中删除指定名称的属性 |
//获取session
HttpSession session = request.getSession();
//调用session对象api方法
String id = session.getId();
int maxInactiveInterval = session.getMaxInactiveInterval();
long creationTime = session.getCreationTime();
long lastAccessedTime = session.getLastAccessedTime();
ServletContext servletContext = session.getServletContext();
boolean aNew = session.isNew();
PrintWriter writer = response.getWriter();
writer.write(id+"\n");
writer.write(maxInactiveInterval+"\n");
writer.write(creationTime+"\n");
writer.write(lastAccessedTime+"\n");
writer.write(servletContext+"\n");
writer.write(aNew+"\n");
Session的生命周期
Web服务器采用“超时限制”判断客户端是否还在继续访问。在一定时间内,如果某个客户端一直没有请求访问,那么,Web服务器就会认为该客户端已经结束请求,并且将与该客户端会话所对应的HttpSession对象变成垃圾对象,等待垃圾收集器将其从内存中彻底清除。反之,如果浏览器超时后,再次向服务器发出请求访问,那么,Web服务器会创建一个新的HttpSession对象,并为其分配一个新的ID属性。
HttpSession session = request.getSession();
session.invalidate();//注销该request的所有session
有时默认的Session失效时间并不能满足我们的需求。这时我们需要自定义Session的失效时间,自定义Session的失效时间有3种:
1、在项目中的web.xml文件中配置Session的失效时间(默认单位为分钟)

2、在Servlet程序中手动设置Session的失效时间(默认单位为秒)
session.setMaxInactiveInterval(30 * 60);//设置单位为秒,设置为-1永不过期
3、在
<session-config>
<session-timeout>30</session-timeout>
</session-config>
在上述代码的配置信息中,设置的时间值是以分钟为单位的,即Tomcat服务器的默认会话超时间隔为30分钟。如果将元素中的时间值设置成0或负数,则表示会话永不超时。需要注意的是
JSP
JSP全名是Java Server Pages,即Java服务器页面。它是Servlet更高级别的扩展。在JSP文件中,HTML代码与Java代码共同存在,其中,HTML代码用来实现网页中静态内容的显示,Java代码用来实现网页中动态内容的显示。最终,JSP文件会通过Web服务器的Web容器编译成一个Servlet,用来处理各种请求。
在使用JSP技术开发Web应用时,可以将界面的开发与应用程序的开发分离开。开发人员使用HTML设计界面,使用JSP标签和脚本动态生成页面上的内容。在服务器端(本书中指Tomcat),JSP容器负责解析JSP标签和脚本程序,生成所请求的内容,并将执行结果以HTML页面的形式返回给浏览器。
JSP运行原理
JSP的工作模式是请求/响应模式,客户端首先发出HTTP请求,JSP程序收到请求后进行处理并返回处理结果。一个JSP文件第一次被请求时,JSP容器把该JSP文件转换成为一个Servlet,而这个容器本身也是一个Servlet。
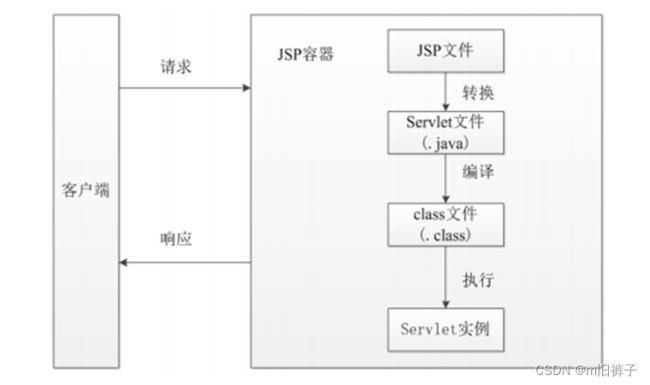
1、客户端发出请求,请求访问JSP文件
2、JSP容器先将JSP文件转换成一个Java源文件(Java Servlet源程序),在转换过程中,如果发现JSP文件中存在任何语法错误,则中断转换过程,并向服务端和客户端返回出错信息。
3、如果转换成功,则JSP容器将生成的Java源文件编译成相应的字节码文件*.class。该class文件就是一个Servlet,Servlet容器会像处理其他Servlet一样来处理它。
4、由Servlet容器加载转换后的Servlet类(.class文件)创建一个该Servlet(JSP页面的转换结果)的实例,并执行Servlet的jspInit()方法完成初始化。jspInit()方法在Servlet的整个生命周期中只会执行一次。
5、JSP容器执行jspService()方法处理客户端的请求。对于每一个请求,JSP容器都会创建一个新的线程来处理它。如果多个客户端同时请求该JSP文件,则JSP容器会创建多个线程,使得每一个客户端请求都对应一个线程。
JSP运行过程中采用的这种多线程的执行方式可以极大地降低对系统资源的消耗,提高系统的并发量并缩短响应时间。需要注意的是,由于第 4 步生成的Servlet实例是常驻内存的,所以响应速度非常快。
6、如果JSP文件被修改了,则服务器将根据新的设置决定是否对该文件进行重新编译。如果需要重新编译,则使用重新编译后的结果取代内存中常驻的Servlet实例,并继续上述处理过程。
7、虽然JSP效率很高,但在第一次调用的时候往往由于需要转换和编译,会产生一些轻微的延迟。此外,由于系统资源不足等原因,JSP容器可能会以某种不确定的方式将Servlet实例从内存中移除,发生这种情况时,JSP容器首先会调用jspDestroy()方法,然后Servlet实例会被加入“垃圾收集”处理。
8、当请求处理完成后,响应对象由JSP容器接收,并将HTML格式的响应信息发送回客户端。
JSP基本构成
一个JSP页面可以包括指令标识、HTML代码、JavaScript代码、嵌入的Java代码、注释和JSP动作标识等内容。
JSP脚本元素
JSP Scriptlets
JSP Scriptlets 是一段代码片段。所谓代码片段,就是在JSP页面中嵌入的Java代码或脚本代码。代码片段将在页面请求的处理期间被执行,通过Java代码可以定义变量或流程控制语句等;而脚本代码可以应用JSP的内置对象在页面输出内容、处理请求和访问session会话等。JSP Scriptlets的语法格式如下所示:
<% java 代码(变量、方法、表达式等)%>
<%
int a=1;
int b=2;
//通过jsp内置对象调用api完成输出
out.print(a+b);
%>
JSP声明标识
在JSP Scriptlets中可以进行属性的定义,也可以输出内容,但是它不可以进行方法的定义。如果想在脚本元素中定义方法,可以使用声明标识。声明标识用于在JSP页面中定义全局变量或方法,它以“<%!”开始,以“%>”结束。通过声明标识定义的变量和方法可以被整个JSP页面访问,所以通常使用该标识定义整个JSP页面需要引用的变量或方法。
声明标识的语法格式如下所示:
<%!
定义变量或方法等
%>
<%-- 声明标识--%>
<%!
int c=1;
public int add(int a,int b) {
return a+b;
}
%>
<%
out.print(add(1,6));
%>
JSP表达式
JSP表达式(expression)用于向页面输出信息,它以“<%=”开始,以“%>”结束,其基本的语法格式如下所示:
<%= expression %>
<%-- 声明标识--%>
<%!
int c=1;
int b=3;
%>
<%-- jsp表达式--%>
<%= c+b %>
上述语法格式中,参数expression可以是任何Java语言的完整表达式,该表达式的最终运算结果将被转换成一个字符串。
JSP注释
代码片段中注释和java中注释一样
JSP提供了隐藏注释,浏览器页面中看不到,HTML源码中也看不到
<%-- 注释内容--%>
网页源代码只显示出了HTML注释,而没有显示JSP的注释信息。这是因为Tomcat编译JSP文件时,会将HTML注释当成普通文本发送到客户端,而JSP页面中格式为“<%-- 注释信息 --%>”的内容则会被忽略,不会发送到客户端。
<%-- 这个是JSP注释 --%>
JSP指令
page指令
<%@ page 属性名1= "属性值1" 属性名2= "属性值2" ...%>
page用于声明指令名称,属性用来指定JSP页面的某些特性。page指令还提供了一系列与JSP页面相关的属性。
| 属性名称 | 取值范围 | 描述 |
|---|---|---|
| language | java | 指定JSP页面所用的脚本语言,默认为Java |
| import | 任何包名、类名 | 指定在JSP页面翻译成的Servlet源文件中导入的包或类。import是唯一可以声明多次的page指令属性。一个import属性可以引用多个类,中间用英文逗号隔开 |
| session | true、false | 指定该JSP内是否内置Session对象,如果为true,则说明内置Session对象,可以直接使用,否则没有内置Session对象。默认情况下,session属性的值为true。需要注意的是,JSP 容器自动导入以下4个包: java.lang.* javax.servlet.* javax.servlet.jsp.* javax.servlet.http.* |
| isErrorPage | true、false | 指定该页面是否为错误处理页面,如果为true,则该JSP内置有一个Exception对象的exception,可直接使用。默认情况下,isErrorPage的值为false |
| 属性名称 | 取值范围 | 描述 |
|---|---|---|
| errorPage | 某个JSP页面的相对路径 | 指定一个错误页面,如果该JSP程序抛出一个未捕捉的异常,则转到errorPage指定的页面。errorPage指定页面的isErrorPage属性为true,且内置的exception对象为未捕捉的异常 |
| contentType | 有效的文档类型 | 指定当前JSP页面的MIME类型和字符编码,例如: HTML格式为text/html 纯文本格式为text/plain JPG图像为image/jpeg GIF图像为image/gif Word文档为application/msword |
| pageEnCoding | 当前页面 | 指定页面编码格式 |
page指令的常见属性中除了import属性外,其他的属性都只能出现一次,否则会编译失败。page指令对整个页面都有效,而与其书写的位置无关,但是习惯上把page指令写在JSP页面的最前面。
include指令
在实际开发时,有时需要在JSP页面中包含另一个JSP页面,这时,可以通过include指令实现,include指令的具体语法格式如下所示:
<%@ include file="被包含的文件地址"%>
<%
Date date = new Date();
SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String today=sdf.format(date);
%>
当前时间:<%=today%>
在下面引入被包含的页面
<%@include file="date.jsp"%>
(1)被引入的文件必须遵循JSP语法,其中的内容可以包含静态HTML、JSP脚本元素和JSP指令等普通JSP页面所具有的一切内容。
(2)除了指令元素之外,被引入的文件中的其他元素都被转换成相应的Java源代码,然后插入进当前JSP页面所翻译成的Servlet源文件中,插入位置与include指令在当前JSP页面中的位置保持一致。
(3)file属性的设置值必须使用相对路径,如果以“/”开头,表示相对于当前Web应用程序的根目录(注意不是站点根目录);否则,表示相对于当前文件。需要注意的是,这里的file属性指定的相对路径是相对于文件(file),而不是相对于页面(page)。
(4)在应用include指令进行文件包含时,为了使整个页面的层次结构不发生冲突,建议在被包含页面中将,等标签删除,因为在包含页面的文件中已经指定了这些标签。
taglib指令
在JSP文件中,可以通过taglib指令标识该页面中所使用的标签库,同时引用标签库,并指定标签的前缀。在页面中引用标签库后,就可以通过前缀来引用标签库中的标签。taglib指令的具体语法格式如下:
<%@ taglib prefix="tagPrefix" uri="tagURI" %>
prefix:用于指定标签的前缀,该前缀不能命名为jsp、jspx、java、sun、servlet和sunw。
uri:用于指定标签库文件的存放位置。
<%@ taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %>
JSP动作元素
JSP动作元素
包含文件元素jsp:include
page:用于指定被引入文件的相对路径。例如,指定属性值为top.jsp,则表示将当前JSP文件相同文件夹下的top.jsp文件引入到当前JSP页面中。
flush:用于指定是否将当前页面的输出内容刷新到客户端,默认情况下,flush属性的值为false。
使用include指令时,被包含的文件内容会原封不动地插入到包含页中,然后JSP编译器再将合成后的文件最终编译成一个Java文件;使用jsp:include动作元素包含文件时,当该元素被执行时,程序会将请求转发到被包含的页面,并将执行结果输出到浏览器中,然后返回包含页,继续执行后面的代码。因为服务器执行的是多个文件,所以如果一个页面包含了多个文件,JSP编译器会分别对被包含的文件进行编译。
请求转发元素jsp:forward
jsp:forward动作元素可以将当前请求转发到其他Web资源(HTML页面、JSP页面和Servlet等),执行请求转发之后,当前页面将不再执行,而是执行该元素指定的目标页面。jsp:forward具体语法格式如下所示:
page属性用于指定请求转发到的资源的相对路径,该路径的目标文件必须是当前应用中的内部资源。
JSP隐式对象
| 名称 | 类型 | 描述 |
|---|---|---|
| out | javax.servlet.jspJspWriter | 用于页面输出 |
| request | javax.servlet.http.HttpServletRequest | 得到用户请求信息 |
| response | javax.servlet.http.HttpServletResponse | 服务器向客户端的回应信息 |
| config | javax.servlet.ServletConfig | 服务器配置,可以取得初始化参数 |
| session | javax.servlet.http.HttpSession | 用来保存用户的信息 |
| application | javax.servlet.ServletContext | 所有用户的共享信息 |
| page | java.lang.Object | 指当前页面转换后的Servlet类的实例 |
| pageContext | javax.servlet.jsp.PageContext | JSP的页面容器 |
| exception | java.lang.Throwable | 表示JSP页面所发生的异常,在错误页中才起作用 |
out对象
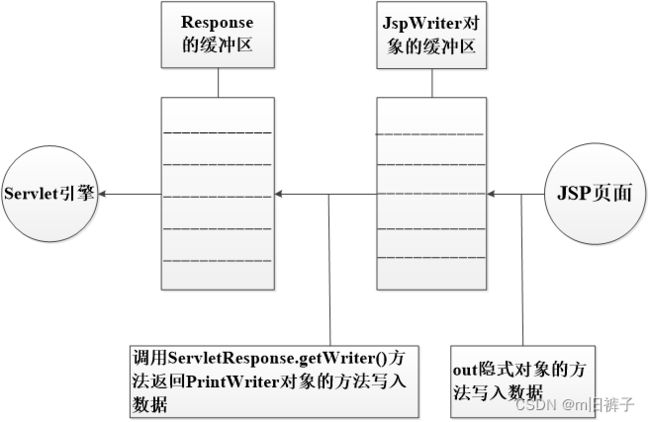
在JSP页面中,经常需要向客户端发送文本内容,向客户端发送文本内容可以使用out对象实现。out对象是javax.servlet.jsp.JspWriter类的实例对象,它的作用与ServletResponse.getWriter()方法返回的PrintWriter对象非常相似,都是用来向客户端发送文本形式的实体内容。不同的是,out对象的类型为JspWriter,它相当于带缓存功能的PrintWriter。
<%@ page contentType="text/html;charset=UTF-8" language="java" buffer="8kb" %>
$Title$
<%
out.print("111");
PrintWriter writer = response.getWriter();
writer.write("2222");
%>
//页面展示为 2222 111
<%@ page contentType="text/html;charset=UTF-8" language="java" buffer="0kb" %>
$Title$
<%
out.print("111");
PrintWriter writer = response.getWriter();
writer.write("2222");
%>
//页面展示为 111 2222
pageContext对象
在JSP页面中,使用pageContext对象可以获取JSP的其他8个隐式对象。pageContext对象是javax.servlet.jsp.PageContext类的实例对象,它代表当前JSP页面的运行环境,并提供了一系列用于获取其他隐式对象的方法。
| 方法名 | 功能描述 |
|---|---|
| JspWriter getOut() | 用于获取out隐式对象 |
| Object getPage() | 用于获取page隐式对象 |
| ServletRequest getRequest() | 用于获取request隐式对象 |
| ServletResponse getResponse() | 用于获取response隐式对象 |
| HttpSession getSession() | 用于获取session隐式对象 |
| Exception getException() | 用于获取exception隐式对象 |
| ServletConfig getServletConfig() | 用于获取config隐式对象 |
| ServletContext getServletContext() | 用于获取application隐式对象 |
| 方法名 | 功能描述 |
|---|---|
| void setAttribute(String name,Object value,int scope) | 用于设置pageContext对象的属性 |
| Object getAttribute(String name,int scope) | 用于获取pageContext对象的属性 |
| void removeAttribute(String name,int scope) | 用于删除指定范围内名称为name的属性 |
| void removeAttribute(String name) | 用于删除所有范围内名称为name的属性 |
| Object findAttribute(String name) | 用于从4个域对象中查找名称为name的属性 |
需要注意的是,当调用findAttribute()方法查找名称为name的属性时,会按照page、request、session和application的顺序依次进行查找,如果找到,则返回属性的名称,否则返回null。
<%
//页面中存值
pageContext.setAttribute("str","java");
//页面中取值
String str = (String) pageContext.getAttribute("str");
//请求域中存值
ServletRequest request1 = pageContext.getRequest();
request1.setAttribute("str","javaWrb");
//请求域中取值
String str1 = (String) request1.getAttribute("str");
%>
<%
out.print("page范围:"+str+"
");
out.print("page范围:"+str1+"
");
%>
exception对象
在JSP页面中,经常需要处理一些异常信息,处理异常信息可以通过exception对象实现。exception对象是java.lang.Exception类的实例对象,它用于封装JSP中抛出的异常信息。需要注意的是,exception对象只有在错误处理页面才可以使用,即page指令中指定了属性<%@ page isErrorPage=“true”%>的页面。
<%@ page contentType="text/html;charset=UTF-8" language="java" errorPage="error.jsp" %>
Title
<%
int a=1;
int b=0;
int c=a/b;
%>
<%@ page contentType="text/html;charset=UTF-8" language="java" isErrorPage="true" %>
Title
<%=exception.getMessage()%>
JavaBean
概念
使HTML代码与Java代码相分离,将Java代码单独封装成为一个处理某种业务逻辑的类,然后在JSP页面中调用此类,可以降低HTML代码与Java代码之间的耦合度,简化JSP页面。提高Java程序代码的重用性及灵活性。这种与HTML代码相分离,而使用Java代码封装的类,就是一个JavaBean组件。在Java Web开发中,可以使用JavaBean组件完成业务逻辑的处理。应用JavaBean与JSP整合的开发模式如下图所示。
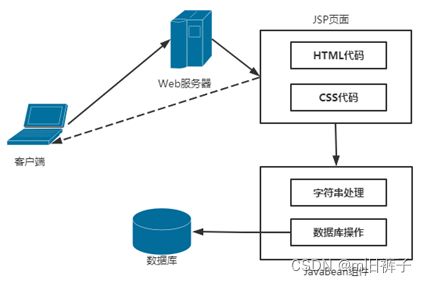
JavaBean是一个遵循特定写法的Java类,它是为了和JSP页面传输数据、简化交互过程而产生的。JavaBean通常具有如下特点:
(1)JavaBean必须具有一个无参的构造函数。
(2)属性必须私有化。
(3)私有化的属性必须通过public类型的方法暴露给其他程序,并且方法的命名也必须遵
守一定的命名规范。
JSP开发模型
JSP Model1
JSP Model1采用JSP+JavaBean的技术,将页面显示和业务逻辑分开。其中,JSP实现流程控制和页面显示,JavaBean对象封装数据和业务逻辑。JSP Model1的工作原理如下图所示。
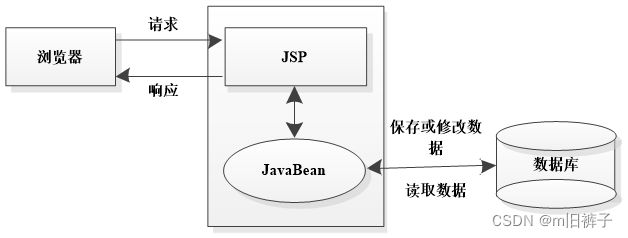
JSP Model1虽然将数据和部分的业务逻辑从JSP页面中分离出去,但是JSP页面仍然需要负责流程控制和显示用户界面,对于一个业务流程复杂的大型应用程序来说,在JSP页面中依旧会嵌入大量的Java代码,这样会给项目管理带来很大的麻烦。
JSP Model2
JSP Model2架构模型采用JSP+Servlet+ JavaBean的技术,此技术将原本JSP页面中的流程控制代码提取出来,封装到Servlet中,实现了页面显示、流程控制和业务逻辑的分离。实际上JSP Model2模型就是MVC(Model-View-Controller,模型-视图-控制器)设计模式,其中控制器的角色由Servlet实现,视图的角色由JSP页面实现,模型的角色是由JavaBean实现。JSP Model2的工作原理如下图所示。
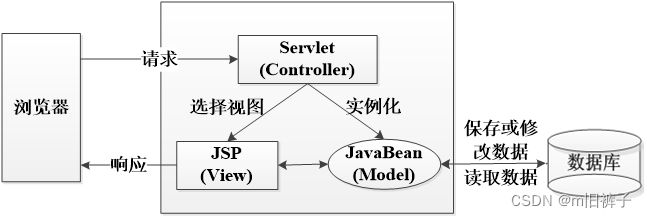
由上图可知,Servlet充当了控制器的角色,它首先接收浏览器发送的请求,然后根据请求信息实例化JavaBean对象,由JavaBean对象完成数据库操作并将操作结果进行封装,最后选择相应的JSP页面将响应结果显示在浏览器中
MVC设计模式
MVC设计模式是施乐帕克研究中心在20世纪80年代为编程语言Smalltalk-80发明的一种软件设计模式,提供了一种按功能对软件进行模块划分的方法。MVC设计模式将软件程序分为三个核心模块:模型(Model)、视图(View)和控制器(Controller)。
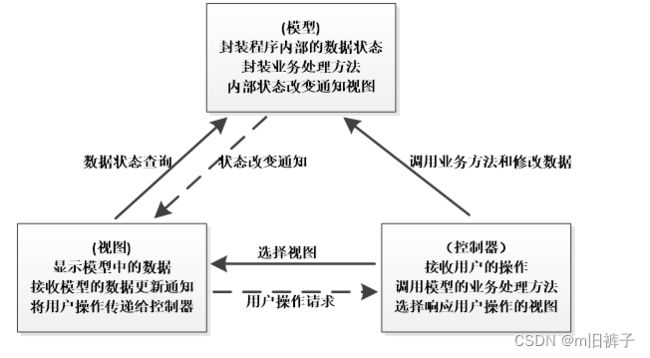
在上图中,当控制器接收到用户的请求后,会根据请求信息调用模型组件的业务方法,对业务方法处理完毕后,再根据模型的返回结果选择相应的视图组件显示处理结果和模型中的数据。
Filter
概念
在Servlet高级特性中,Filter被称为过滤器,Filter基本功能就是对Servlet容器调用Servlet的过程进行拦截,它位于客户端和处理程序之间,能够对请求和响应进行检查和修改。Filter就好比现实中的污水净化设备,专门用于过滤污水杂质。

Filter除了可以实现拦截功能,还可以提高程序的性能,在Web开发时,不同的Web资源中的过滤操作可以放在同一个Filter中完成,这样可以不用多次编写重复代码,从而提高了程序的性能。
Filter相关API
| 方法声明 | 功能描述 |
|---|---|
| init(FilterConfig filterConfig) | init()方法是Filter的初始化方法,创建Filter实例后将调用init()方法。该方法的参数filterConfig用于读取Filter的初始化参数。 |
| doFilter(ServletRequest request,ServletResponse response,FilterChain chain) | doFilter()方法完成实际的过滤操作,当客户的请求满足过滤规则时,Servlet容器将调用过滤器的doFilter()方法完成实际的过滤操作。doFilter()方法有多个参数,其中,参数request和response为Web服务器或Filter链中的上一个Filter传递过来的请求和响应对象;参数chain代表当前Filter链的对象。 |
| destroy() | 该方法用于释放被Filter对象打开的资源,例如关闭数据库和 IO流。destroy()方法在Web服务器释放Filter对象之前被调用。 |
| 方法声明 | 功能描述 |
|---|---|
| String getFilterName() | 返回Filter的名称 |
| ServletContext getServletContext() | 返回FilterConfig对象中封装的ServletContext对象 |
| String getInitParameter(String name) | 返回名为name的初始化参数值 |
| Enumeration getInitParameterNames() | 返回Filter所有初始化参数的枚举 |
FilterChain接口的doFilter()方法用于调用过滤器链中的下一个过滤器,如果这个过滤器是链上的最后一个过滤器,则将请求提交给处理程序或将响应发给客户端。
生命周期
与servlet生命周期类似。
@WebFilter注解的常用属性
| 属性名 | 类型 | 描述 |
|---|---|---|
| filterName | String | 指定过滤器的名称。默认是过滤器类的名称。 |
| urlPatterns | String[] | 指定一组过滤器的URL匹配模式。 |
| value | String[] | 该属性等价于urlPatterns属性。urlPatterns和value属性不能同时使用。 |
| servletNames | String[] | 指定过滤器将应用于哪些Servlet。取值是 @WebServlet 中的 name 属性的取值。 |
| dispatcherTypes | DispatcherType | 指定过滤器的转发模式。具体取值包括: ERROR、FORWARD、INCLUDE、REQUEST。 |
| initParams | WebInitParam[] | 指定过滤器的一组初始化参数。 |
Filter映射
Filter拦截的资源需要在Filter实现类中使用注解@WebFilter进行配置,这些配置信息就是Filter映射。Filter的映射方式可分为两种:使用通配符“*”拦截用户所有请求和拦截不同访问方式的请求。
urlPatterns = "*"
@WebFilter注解有一个特殊的属性dispatcherTypes,它可以指定过滤器的转发模式,dispatcherTypes属性有4个常用值,REQUEST、INCLUDE、FORWARD和ERROR。
@WebFilter(filterName="ForwardFilter",urlPatterns = "/first.jsp",dispatcherTypes = DispatcherType.FORWARD)
REQUEST
过滤器设置dispatcherTypes属性值为REQUEST时,如果用户通过RequestDispatcher对象的include()方法或forward()方法访问目标资源,那么过滤器不会被调用。除此之外,该过滤器会被调用。
INCLUDE
过滤器设置dispatcherTypes属性值为INCLUDE时,如果用户通过RequestDispatcher对象的include()方法访问目标资源,那么过滤器将被调用。除此之外,该过滤器不会被调用。
FORWARD
过滤器设置dispatcherTypes属性值为FORWARD时,如果通过RequestDispatcher对象的forward()方法访问目标资源,那么过滤器将被调用。除此之外,该过滤器不会被调用。
ERROR
过滤器设置dispatcherTypes属性值为ERROR时,如果通过声明式异常处理机制调用目标资源,那么过滤器将被调用。除此之外,过滤器不会被调用。
Filter链
在一个Web应用程序中可以注册多个Filter,每个Filter都可以针对某一个URL的请求进行拦截。如果多个Filter都对同一个URL的请求进行拦截,那么这些Filter就组成一个Filter链。Filter链使用FilterChain对象表示,FilterChain对象提供了一个doFilter()方法,该方法的作用是让Filter链上的当前过滤器放行,使请求进入下一个Filter。

浏览器访问Web服务器中的资源时需要经过两个过滤器Filter1和Filter2,首先Filter1会对这个请求进行拦截,在Filter1过滤器中处理好请求后,通过调用Filter1的doFilter()方法将请求传递给Filter2,Filter2将用户请求处理后同样调用doFilter()方法,最终将请求发送给目标资源。当Web服务器对这个请求做出响应时,响应结果也会被过滤器拦截,拦截顺序与之前相反,最终响应结果被发送给客户端。
Listener概述
在Web程序开发中,经常需要对某些事件进行监听,以便及时作出处理,如监听鼠标单击事件、监听键盘按下事件等。为此,Servlet提供了监听器(Listener),专门用于监听Servlet事件。Listener在监听过程中会涉及几个重要组成部分,具体如下。
(1)事件:用户的一个操作,如单击一个按钮、调用一个方法、创建一个对象等。
(2)事件源:产生事件的对象。
(3)事件监听器:负责监听发生在事件源上的事件。
(4)事件处理器:监听器的成员方法,当事件发生的时候会触发对应的处理器(成员方法)。
注意:当用户执行一个操作触发事件源上的事件时,该事件会被事件监听器监听到,当监听器监听到事件发生时,相应的事件处理器就会对发生的事件进行处理。
| 类型 | 描述 |
|---|---|
| ServletContextListener | 用于监听ServletContext对象的创建与销毁过程 |
| HttpSessionListener | 用于监听HttpSession对象的创建和销毁过程 |
| ServletRequestListener | 用于监听ServletRequest对象的创建和销毁过程 |
| ServletContextAttributeListener | 用于监听ServletContext对象中的属性变更 |
| HttpSessionAttributeListener | 用于监听HttpSession对象中的属性变更 |
| ServletRequestAttributeListener | 用于监听ServletRequest对象中的属性变更 |
| HttpSessionBindingListener | 用于监听JavaBean对象绑定到HttpSession对象和从HttpSession对象解绑的事件 |
| HttpSessionActivationListener | 用于监听HttpSession中对象活化和钝化的过程 |
Listener中的8种Servlet事件监听器可以分为三类,具体如下。
(1)用于监听域对象创建和销毁的监听器:ServletContextListener接口、HttpSessionListener接口和ServletRequestListener接口。
(2)用于监听域对象属性增加和删除的监听器:ServletContextAttributeListener接口、HttpSessionAttributeListener接口和ServletRequestAttributeListener接口。
(3)用于监听绑定到HttpSession域中某个对象状态的事件监听器:HttpSessionBindingListener接口和HttpSessionActivationListener接口。
public class MyListener implements ServletContextListener, ServletRequestListener, HttpSessionListener {
@Override
public void contextInitialized(ServletContextEvent servletContextEvent) {
System.out.println(111);
}
@Override
public void contextDestroyed(ServletContextEvent servletContextEvent) {
System.out.println(222);
}
@Override
public void requestDestroyed(ServletRequestEvent servletRequestEvent) {
}
@Override
public void requestInitialized(ServletRequestEvent servletRequestEvent) {
}
@Override
public void sessionCreated(HttpSessionEvent httpSessionEvent) {
}
@Override
public void sessionDestroyed(HttpSessionEvent httpSessionEvent) {
}
数据库连接池
概念
为了避免频繁的创建数据库连接,数据库连接池技术应运而生。数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用现有的数据库连接,而不是重新建立。简单地说,数据库连接池就是为数据库建立的一个“缓冲池”。预先在“缓冲池”中放入一定数量的连接,当需要建立数据库连接时,只需要从“缓冲池”中取出一个,使用完毕后再放回“缓冲池”即可。

数据库连接池在初始化时将创建一定数量的数据库连接放到连接池中,当应用程序访问数据库时并不是直接创建Connection,而是向连接池“申请”一个Connection。如果连接池中有空闲的Connection,则返回一个链接给应用程序,否则应用程序需要创建新的Connection。使用完毕后,连接池会将Connection回收,重新放入连接池以供其他的线程使用,从而减少创建和断开数据库连接的次数,提高数据库的访问效率。
DataSource接口
为了获取数据库连接对象(Connection),JDBC提供了javax.sql.DataSource接口,javax.sql.DataSource接口负责与数据库建立连接,并定义了返回值为Connection对象的方法,具体如下。
Connection getConnection() 。
Connection getConnection(String username, String password)。
//上述两个重载的方法,都能用来获取Connection对象。不同的是,第一个方法是通过无参的方式建立与数据库的连接,第二个方法是通过传入登录信息的方式建立与数据库的连接。
DBCP
DBCP即数据库连接池(DataBase Connection Pool),是Apache组织下的开源连接池实现,也是Tomcat服务器使用的连接池组件。使用DBCP数据库连接池时,需要在应用程序中导入commons-dbcp2.jar和commons-pool2.jar两个JAR包。
commons-dbcp2.jar包是DBCP数据库连接池的实现包,包含所有操作数据库连接信息和数据库连接池初始化信息的方法,并实现了DataSource接口的getConnection()方法。
commons-dbcp2.jar包含两个核心类,分别是BasicDataSourceFactory和BasicDataSource,它们都包含获取DBCP数据库连接池对象的方法。
BasicDataSource类
| 方法名称 | 功能描述 |
|---|---|
| void setDriverClassName(String driverClassName) | 设置连接数据库的驱动名称 |
| void setUrl(String url) | 设置连接数据库的路径 |
| void setUsername(String username) | 设置数据库的登录账号 |
| void setPassword(String password) | 设置数据库的登录密码 |
| void setInitialSize(int initialSize) | 设置数据库连接池初始化的连接数目 |
| void setMinIdle(int minIdle) | 设置数据库连接池最小闲置连接数目 |
| Connection getConnection() | 从连接池中获取一个数据库连接 |
BasicDataSource对象的常用方法中setDriverClassName()、setUrl()、setUsername()、setPassword()等方法都是设置数据库连接信息的方法;setInitialSize()、setMinIdle()等方法都是设置数据库连接池初始化值的方法;getConnection()方法可以从DBCP数据库连接池中获取一个数据库连接。
BasicDataSourceFactory工厂类
BasicDataSourceFactory是创建BasicDataSource对象的工厂类,它包含一个返回值为BasicDataSource类型的方法createDataSource(),该方法通过读取配置文件的信息生成数据源对象并返回给调用者。把数据库的连接信息和数据源的初始化信息提取出来写进配置文件,这样让代码看起来更加简洁,思路也更加清晰。
#连接设置
driverClassName=com.mysql.cj.jdbc.Driver
url=jdbc:mysql://localhost:3306/jdbc?serverTimezone=GMT%2B8
username=root
password=root
#初始化连接
initialSize=5
#最大空闲连接
maxIdle=10
C3P0数据库连接池
C3P0是目前最流行的开源数据库连接池之一,它实现了DataSource数据源接口,支持JDBC2和JDBC3的标准规范,易于扩展并且性能优越,著名的开源框架Hibernate和 Spring都支持该数据库连接池。在使用C3P0数据库连接池开发时,需要了解C3P0中DataSource接口的实现类ComboPooledDataSource,它是C3P0的核心类,提供了数据源对象的相关方法。
ComboPooledDataSource类
| 方法名称 | 功能描述 |
|---|---|
| void setDriverClass() | 设置连接数据库的驱动名称 |
| void setJdbcUrl() | 设置连接数据库的路径 |
| void setUser() | 设置数据库的登录账号 |
| void setPassword() | 设置数据库的登录密码 |
| void setMaxPoolSize() | 设置数据库连接池最大连接数目 |
| void setMinPoolSize() | 设置数据库连接池最小连接数目 |
| void setInitialPoolSize() | 设置数据库连接池初始化的连接数目 |
| Connection getConnection() | 从数据库连接池中获取一个连接 |
当使用C3P0数据库连接池时,首先需要创建数据源对象,创建数据源对象可以通过调用ComboPooledDataSource类的构造方法实现。ComboPooledDataSource类有两个构造方法,分别是ComboPooledDataSource()和ComboPooledDataSource(String configName)。
使用c3p0配置文件应该注意:
(1)配置文件名称必须为c3p0-config.xml或者c3p0.properties,并且位于该项目的src根目录下。
(2)当传入的configName值为空或者不存在时,使用默认配置信息创建数据源。
DBUtils类
DBUtils类主要提供了加载JDBC驱动、关闭资源等方法,DBUtils类中的方法一般为静态方法,可以直接使用类名进行调用。
常用方法
| 方法名称 | 功能描述 |
|---|---|
| void close(Connection conn) | 当连接不为NULL时,关闭连接 |
| void close(Statement stat) | 当声明不为NULL时,关闭声明 |
| void close(ResultSet rs) | 当结果集不为NULL时,关闭结果集 |
| void closeQuietly(Connection conn) | 当连接不为NULL时,关闭连接,并隐藏一些在程序中抛出的SQL异常 |
| void closeQuietly(Statement stat) | 当声明不为NULL时,关闭声明,并隐藏一些在程序中抛出的SQL异常 |
| void closeQuietly(ResultSet rs) | 当结果集不为NULL时,关闭结果集,并隐藏一些在程序中抛出的SQL异常 |
| void commitAndCloseQuietly( Connection conn) | 提交连接后关闭连接,并隐藏一些在程序中抛出的SQL异常 |
| Boolean loadDriver(String driveClassName) | 装载并注册JDBC驱动程序,如果成功就返回true |
QueryRunner类
QueryRunner类简化了执行SQL语句的代码,它与ResultSetHandler配合就能完成大部分的数据库操作,大大减少了编码量。QueryRunner类提供了带有一个参数的构造方法,该方法以javax.sql.DataSource的实例对象作为参数传递到QueryRunner的构造方法中来获取Connection对象。针对不同的数据库操作,QueryRunner类提供不同的方法。
| 方法名称 | 功能描述 |
|---|---|
| Object query(Connection conn,String sql,ResultSetHandler rsh,Object[] params) | 执行查询操作,传入的Connection对象不能为空 |
| Object query (String sql, ResultSetHandler rsh,Object[] params) | 执行查询操作 |
| Object query (Connection conn,String sql, ResultSetHandler rsh) | 执行一个不需要置换参数的查询操作 |
| int update(Connection conn, String sql, ResultSetHandler rsh) | 执行一个更新(插入、删除、更新)操作 |
| int update(Connection conn, String sql) | 执行一个不需要置换参数的更新操作 |
| int batch(Connection conn,String sql, Object[] []params) | 批量添加、修改、删除 |
| int batch(String sql, Object[][] params) | 批量添加、修改、删除 |
ResultSetHandler接口中的常见实现类
ResultSetHandler接口用于处理ResultSet结果集,它可以将结果集中的数据转换为不同的形式。根据结果集中不同的数据类型,ResultSetHandler提供了几种常见的实现类。
BeanHandler:将结果集中的第一行数据封装到一个对应的JavaBean实例中。
BeanListHandler:将结果集中的每一行数据都封装到一个对应的JavaBean实例中,并存放到List里。
ColumnListHandler:将某列属性的值封装到List集合中。
ScalarHandler:将结果集中某一条记录的某一列数据存储成Object对象。
实战项目
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cLYdNPMg-1665042140946)(C:\Users\wanglicong\AppData\Roaming\Typora\typora-user-images\image-20220705144106110.png)]
ent stat) | 当声明不为NULL时,关闭声明,并隐藏一些在程序中抛出的SQL异常 |
| void closeQuietly(ResultSet rs) | 当结果集不为NULL时,关闭结果集,并隐藏一些在程序中抛出的SQL异常 |
| void commitAndCloseQuietly( Connection conn) | 提交连接后关闭连接,并隐藏一些在程序中抛出的SQL异常 |
| Boolean loadDriver(String driveClassName) | 装载并注册JDBC驱动程序,如果成功就返回true |
QueryRunner类
QueryRunner类简化了执行SQL语句的代码,它与ResultSetHandler配合就能完成大部分的数据库操作,大大减少了编码量。QueryRunner类提供了带有一个参数的构造方法,该方法以javax.sql.DataSource的实例对象作为参数传递到QueryRunner的构造方法中来获取Connection对象。针对不同的数据库操作,QueryRunner类提供不同的方法。
| 方法名称 | 功能描述 |
|---|---|
| Object query(Connection conn,String sql,ResultSetHandler rsh,Object[] params) | 执行查询操作,传入的Connection对象不能为空 |
| Object query (String sql, ResultSetHandler rsh,Object[] params) | 执行查询操作 |
| Object query (Connection conn,String sql, ResultSetHandler rsh) | 执行一个不需要置换参数的查询操作 |
| int update(Connection conn, String sql, ResultSetHandler rsh) | 执行一个更新(插入、删除、更新)操作 |
| int update(Connection conn, String sql) | 执行一个不需要置换参数的更新操作 |
| int batch(Connection conn,String sql, Object[] []params) | 批量添加、修改、删除 |
| int batch(String sql, Object[][] params) | 批量添加、修改、删除 |
ResultSetHandler接口中的常见实现类
ResultSetHandler接口用于处理ResultSet结果集,它可以将结果集中的数据转换为不同的形式。根据结果集中不同的数据类型,ResultSetHandler提供了几种常见的实现类。
BeanHandler:将结果集中的第一行数据封装到一个对应的JavaBean实例中。
BeanListHandler:将结果集中的每一行数据都封装到一个对应的JavaBean实例中,并存放到List里。
ColumnListHandler:将某列属性的值封装到List集合中。
ScalarHandler:将结果集中某一条记录的某一列数据存储成Object对象。